 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight, Block or Unit? Exploring Sparsity Tradeoffs for Speech Enhancement on Tiny Neural Accelerators
Paper and Code
Nov 09, 2021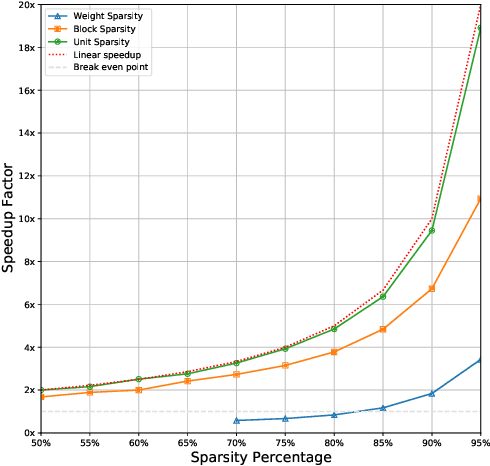
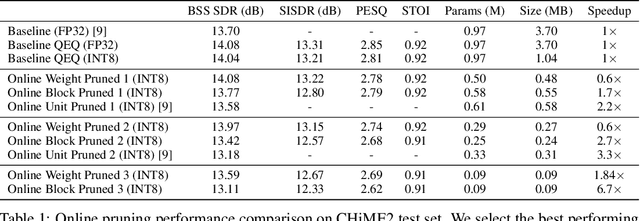
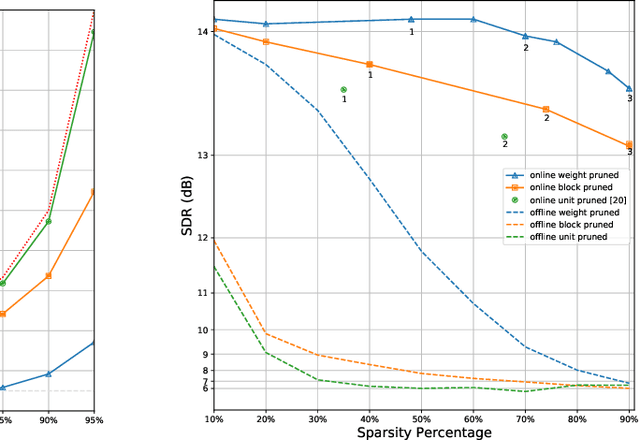

We explore network sparsification strategies with the aim of compressing neural speech enhancement (SE) down to an optimal configuration for a new generation of low power microcontroller based neural accelerators (microNPU's). We examine three unique sparsity structures: weight pruning, block pruning and unit pruning; and discuss their benefits and drawbacks when applied to SE. We focus on the interplay between computational throughput, memory footprint and model quality. Our method supports all three structures above and jointly learns integer quantized weights along with sparsity. Additionally, we demonstrate offline magnitude based pruning of integer quantized models as a performance baseline. Although efficient speech enhancement is an active area of research, our work is the first to apply block pruning to SE and the first to address SE model compression in the context of microNPU's. Using weight pruning, we show that we are able to compress an already compact model's memory footprint by a factor of 42x from 3.7MB to 87kB while only losing 0.1 dB SDR in performance. We also show a computational speedup of 6.7x with a corresponding SDR drop of only 0.59 dB SDR using block pruning.