 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Emotion Recognition In Persian Speech Using Deep Neural Networks
Apr 28, 2022
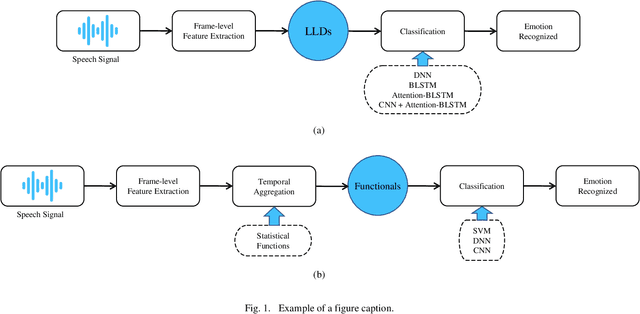
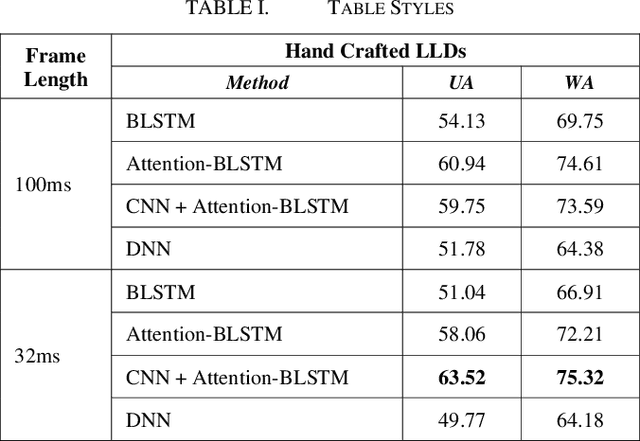
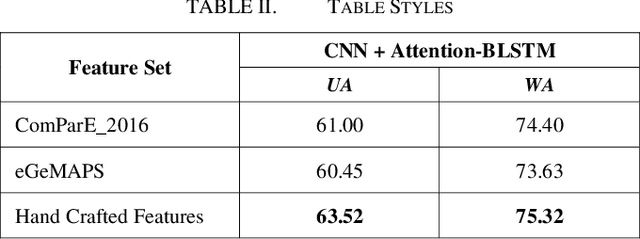
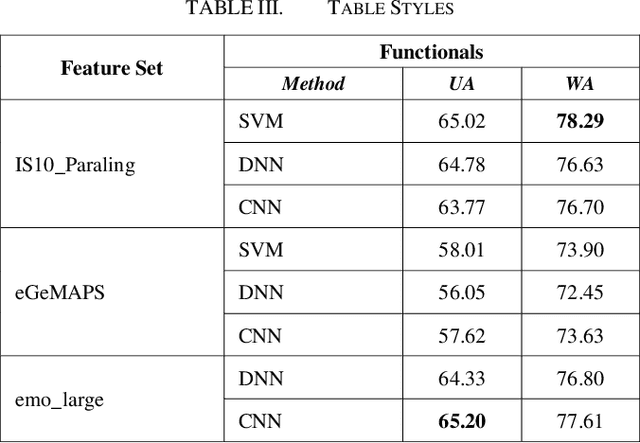
Speech Emotion Recognition (SER) is of great importance in Human-Computer Interaction (HCI), as it provides a deeper understanding of the situation and results in better interaction. In recent years, various machine learning and deep learning algorithms have been developed to improve SER techniques. Recognition of emotions depends on the type of expression that varies between different languages. In this article, to further study this important factor in Farsi, we examine various deep learning techniques on the SheEMO dataset. Using signal features in low- and high-level descriptions and different deep networks and machine learning techniques, Unweighted Average Recall (UAR) of 65.20 is achieved with an accuracy of 78.29.
* 4 pages, 1 figure, 3 tables
Auditory Model based Phase-Aware Bayesian Spectral Amplitude Estimator for Single-Channel Speech Enhancement
Feb 10, 2022
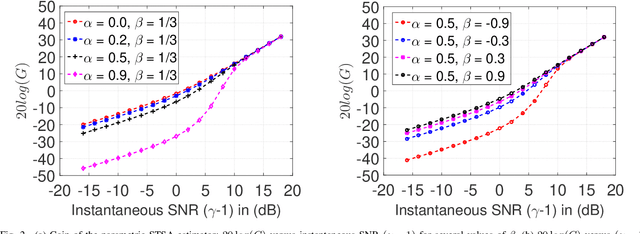
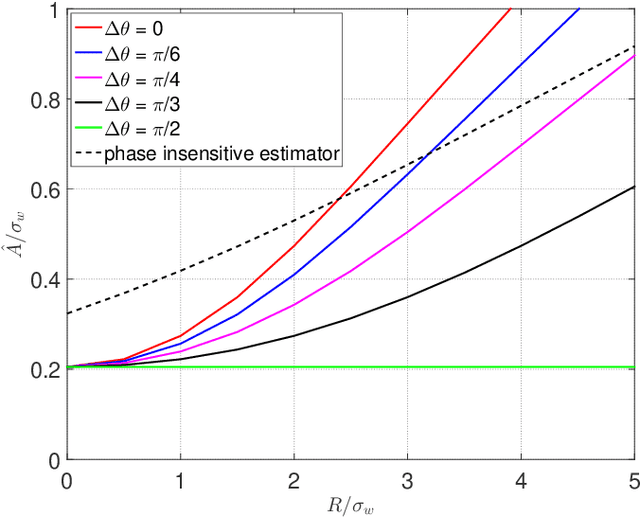
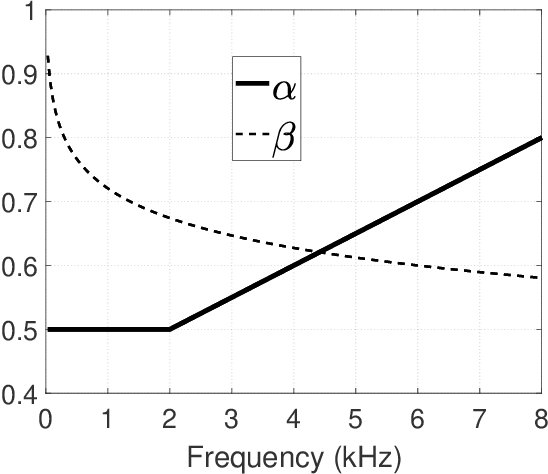
Bayesian estimation of short-time spectral amplitude is one of the most predominant approaches for the enhancement of the noise corrupted speech. The performance of these estimators are usually significantly improved when any perceptually relevant cost function is considered. On the other hand, the recent progress in the phase-based speech signal processing have shown that the phase-only enhancement based on spectral phase estimation methods can also provide joint improvement in the perceived speech quality and intelligibility, even in low SNR conditions. In this paper, to take advantage of both the perceptually motivated cost function involving STSAs of estimated and true clean speech and utilizing the prior spectral phase information, we have derived a phase-aware Bayesian STSA estimator. The parameters of the cost function are chosen based on the characteristics of the human auditory system, namely, the dynamic compressive nonlinearity of the cochlea, the perceived loudness theory and the simultaneous masking properties of the ear. This type of parameter selection scheme results in more noise reduction while limiting the speech distortion. The derived STSA estimator is optimal in the MMSE sense if the prior phase information is available. In practice, however, typically only an estimate of the clean speech phase can be obtained via employing different types of spectral phase estimation techniques which have been developed throughout the last few years. In a blind setup, we have evaluated the proposed Bayesian STSA estimator with different types of standard phase estimation methods available in the literature. Experimental results have shown that the proposed estimator can achieve substantial improvement in performance than the traditional phase-blind approaches.
Training Speech Enhancement Systems with Noisy Speech Datasets
May 26, 2021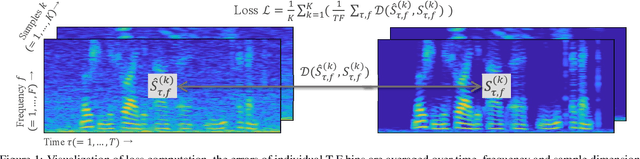
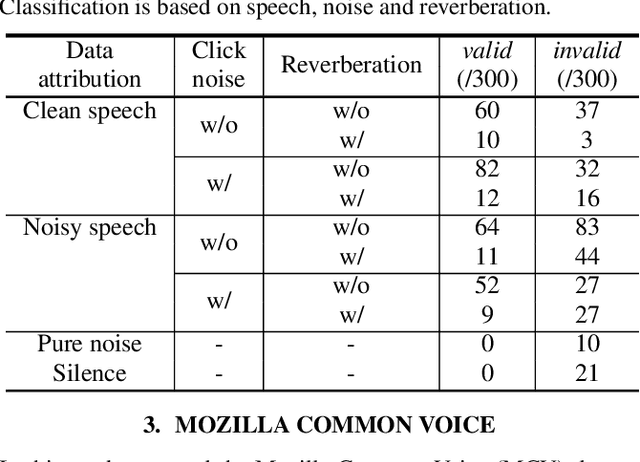
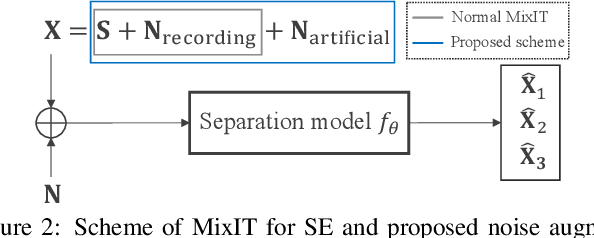

Recently, deep neural network (DNN)-based speech enhancement (SE) systems have been used with great success. During training, such systems require clean speech data - ideally, in large quantity with a variety of acoustic conditions, many different speaker characteristics and for a given sampling rate (e.g., 48kHz for fullband SE). However, obtaining such clean speech data is not straightforward - especially, if only considering publicly available datasets. At the same time, a lot of material for automatic speech recognition (ASR) with the desired acoustic/speaker/sampling rate characteristics is publicly available except being clean, i.e., it also contains background noise as this is even often desired in order to have ASR systems that are noise-robust. Hence, using such data to train SE systems is not straightforward. In this paper, we propose two improvements to train SE systems on noisy speech data. First, we propose several modifications of the loss functions, which make them robust against noisy speech targets. In particular, computing the median over the sample axis before averaging over time-frequency bins allows to use such data. Furthermore, we propose a noise augmentation scheme for mixture-invariant training (MixIT), which allows using it also in such scenarios. For our experiments, we use the Mozilla Common Voice dataset and we show that using our robust loss function improves PESQ by up to 0.19 compared to a system trained in the traditional way. Similarly, for MixIT we can see an improvement of up to 0.27 in PESQ when using our proposed noise augmentation.
Macro-block dropout for improved regularization in training end-to-end speech recognition models
Dec 29, 2022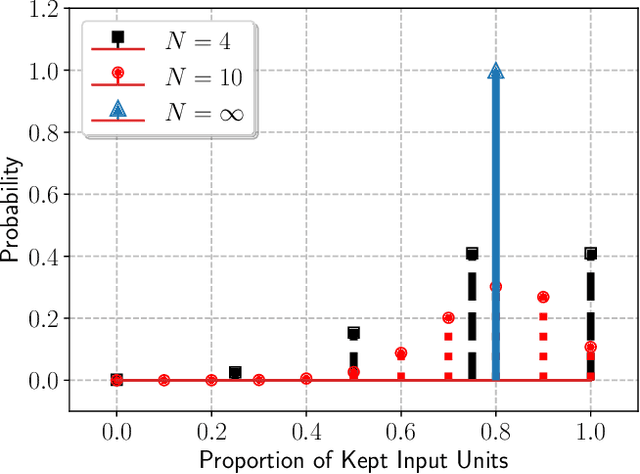


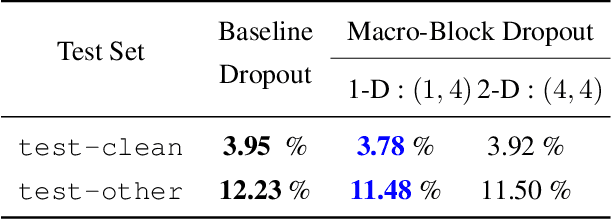
This paper proposes a new regularization algorithm referred to as macro-block dropout. The overfitting issue has been a difficult problem in training large neural network models. The dropout technique has proven to be simple yet very effective for regularization by preventing complex co-adaptations during training. In our work, we define a macro-block that contains a large number of units from the input to a Recurrent Neural Network (RNN). Rather than applying dropout to each unit, we apply random dropout to each macro-block. This algorithm has the effect of applying different drop out rates for each layer even if we keep a constant average dropout rate, which has better regularization effects. In our experiments using Recurrent Neural Network-Transducer (RNN-T), this algorithm shows relatively 4.30 % and 6.13 % Word Error Rates (WERs) improvement over the conventional dropout on LibriSpeech test-clean and test-other. With an Attention-based Encoder-Decoder (AED) model, this algorithm shows relatively 4.36 % and 5.85 % WERs improvement over the conventional dropout on the same test sets.
SA: Sliding attack for synthetic speech detection with resistance to clipping and self-splicing
Aug 27, 2022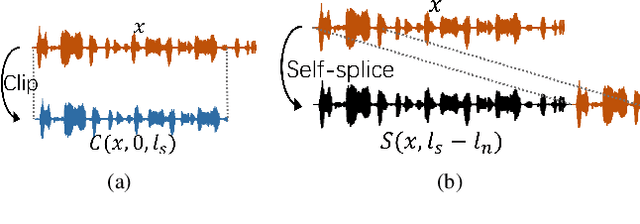
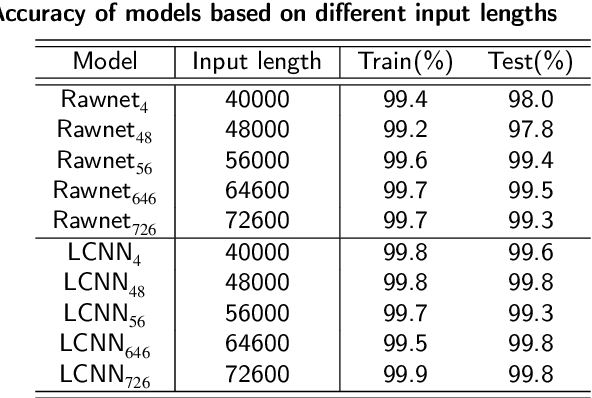
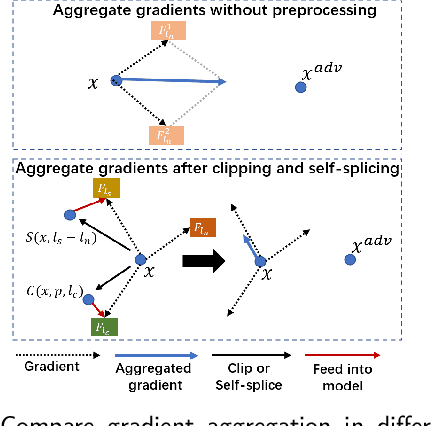
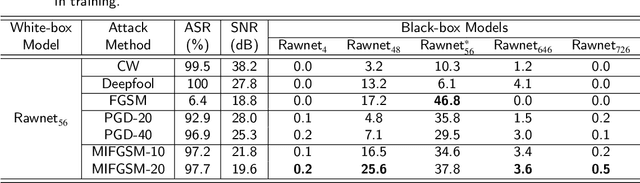
Deep neural networks are vulnerable to adversarial examples that mislead models with imperceptible perturbations. In audio, although adversarial examples have achieved incredible attack success rates on white-box settings and black-box settings, most existing adversarial attacks are constrained by the input length. A More practical scenario is that the adversarial examples must be clipped or self-spliced and input into the black-box model. Therefore, it is necessary to explore how to improve transferability in different input length settings. In this paper, we take the synthetic speech detection task as an example and consider two representative SOTA models. We observe that the gradients of fragments with the same sample value are similar in different models via analyzing the gradients obtained by feeding samples into the model after cropping or self-splicing. Inspired by the above observation, we propose a new adversarial attack method termed sliding attack. Specifically, we make each sampling point aware of gradients at different locations, which can simulate the situation where adversarial examples are input to black-box models with varying input lengths. Therefore, instead of using the current gradient directly in each iteration of the gradient calculation, we go through the following three steps. First, we extract subsegments of different lengths using sliding windows. We then augment the subsegments with data from the adjacent domains. Finally, we feed the sub-segments into different models to obtain aggregate gradients to update adversarial examples. Empirical results demonstrate that our method could significantly improve the transferability of adversarial examples after clipping or self-splicing. Besides, our method could also enhance the transferability between models based on different features.
Effect of noise suppression losses on speech distortion and ASR performance
Nov 23, 2021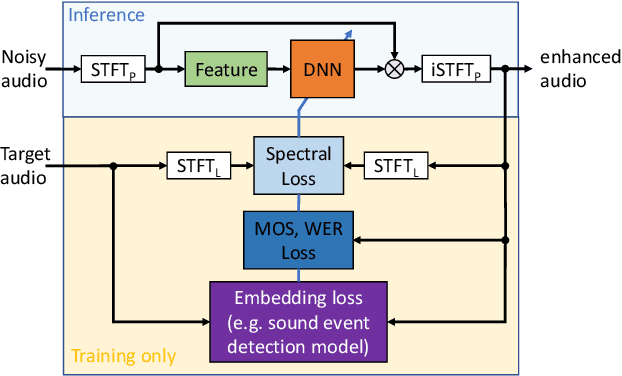
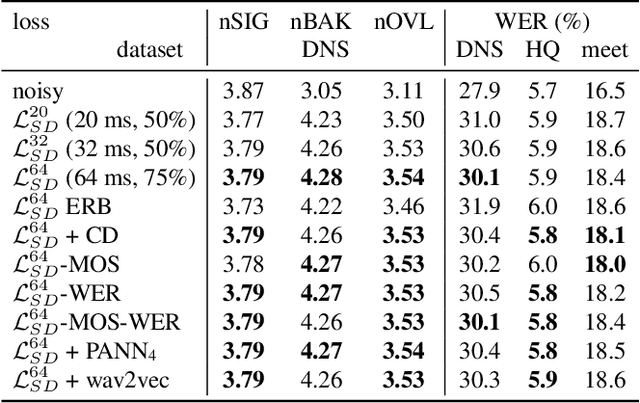
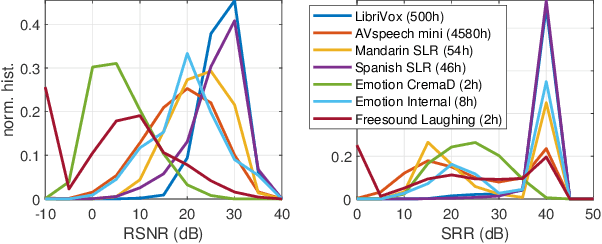
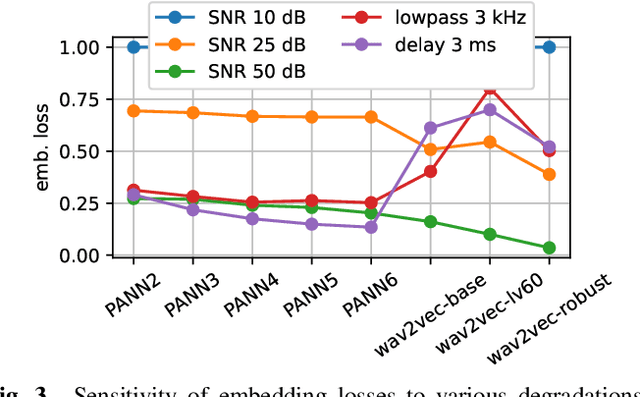
Deep learning based speech enhancement has made rapid development towards improving quality, while models are becoming more compact and usable for real-time on-the-edge inference. However, the speech quality scales directly with the model size, and small models are often still unable to achieve sufficient quality. Furthermore, the introduced speech distortion and artifacts greatly harm speech quality and intelligibility, and often significantly degrade automatic speech recognition (ASR) rates. In this work, we shed light on the success of the spectral complex compressed mean squared error (MSE) loss, and how its magnitude and phase-aware terms are related to the speech distortion vs. noise reduction trade off. We further investigate integrating pre-trained reference-less predictors for mean opinion score (MOS) and word error rate (WER), and pre-trained embeddings on ASR and sound event detection. Our analyses reveal that none of the pre-trained networks added significant performance over the strong spectral loss.
Speech Decomposition Based on a Hybrid Speech Model and Optimal Segmentation
May 04, 2021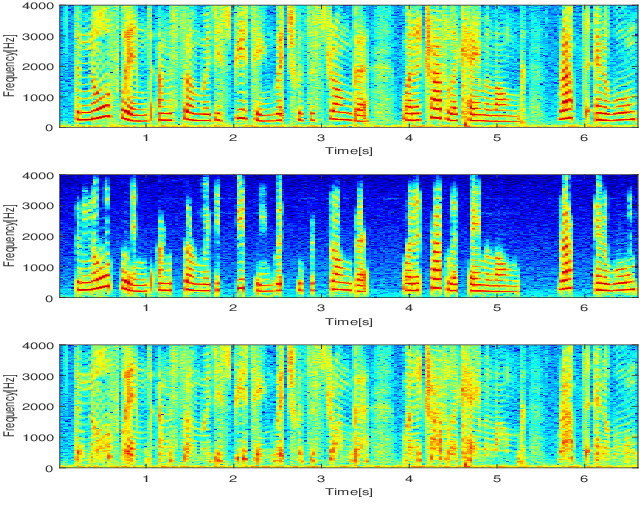
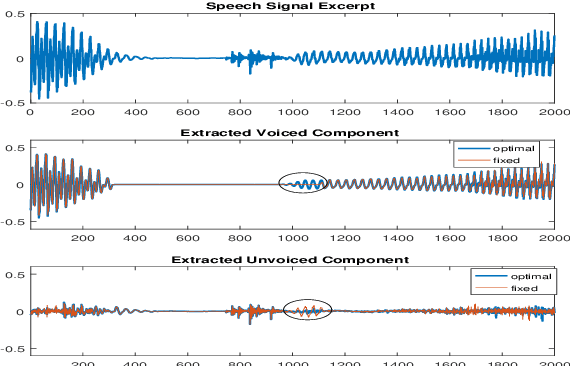
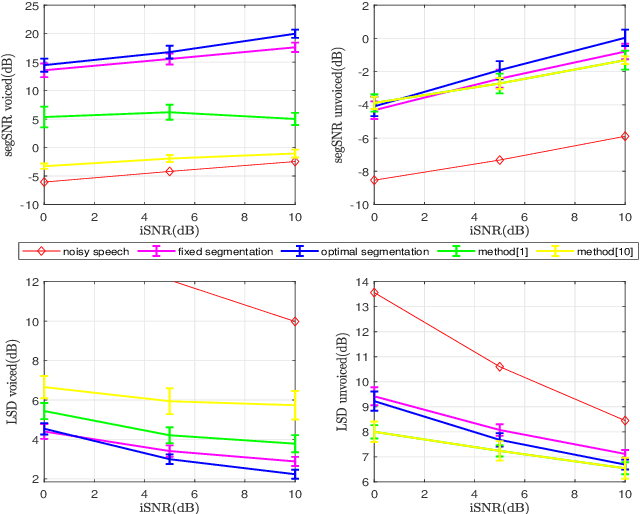
In a hybrid speech model, both voiced and unvoiced components can coexist in a segment. Often, the voiced speech is regarded as the deterministic component, and the unvoiced speech and additive noise are the stochastic components. Typically, the speech signal is considered stationary within fixed segments of 20-40 ms, but the degree of stationarity varies over time. For decomposing noisy speech into its voiced and unvoiced components, a fixed segmentation may be too crude, and we here propose to adapt the segment length according to the signal local characteristics. The segmentation relies on parameter estimates of a hybrid speech model and the maximum a posteriori (MAP) and log-likelihood criteria as rules for model selection among the possible segment lengths, for voiced and unvoiced speech, respectively. Given the optimal segmentation markers and the estimated statistics, both components are estimated using linear filtering. A codebook-based approach differentiates between unvoiced speech and noise. A better extraction of the components is possible by taking into account the adaptive segmentation, compared to a fixed one. Also, a lower distortion for voiced speech and higher segSNR for both components is possible, as compared to other decomposition methods.
Hate Speech Classifiers Learn Human-Like Social Stereotypes
Oct 28, 2021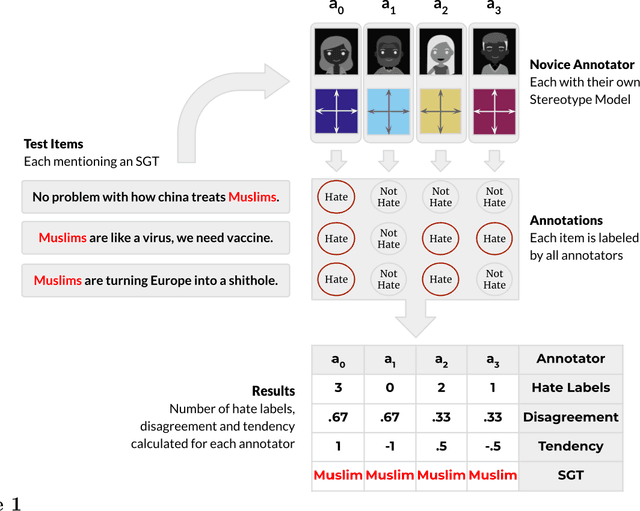
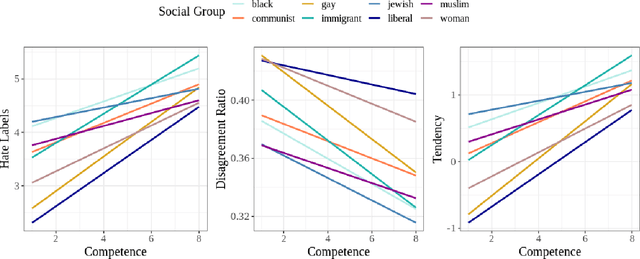
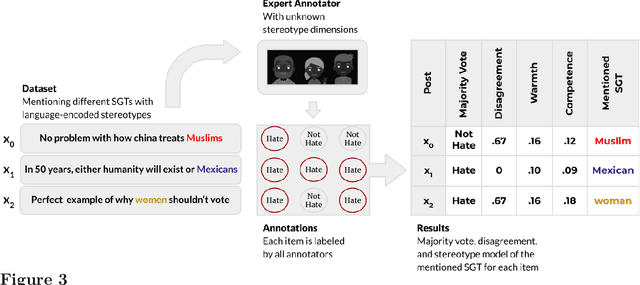
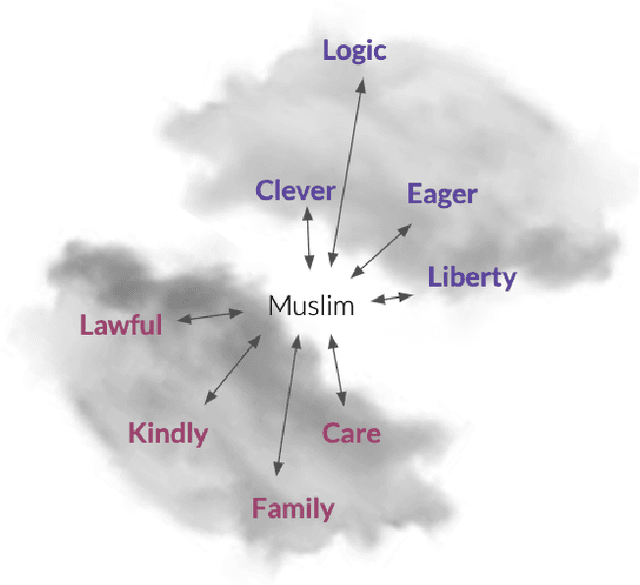
Social stereotypes negatively impact individuals' judgements about different groups and may have a critical role in how people understand language directed toward minority social groups. Here, we assess the role of social stereotypes in the automated detection of hateful language by examining the relation between individual annotator biases and erroneous classification of texts by hate speech classifiers. Specifically, in Study 1 we investigate the impact of novice annotators' stereotypes on their hate-speech-annotation behavior. In Study 2 we examine the effect of language-embedded stereotypes on expert annotators' aggregated judgements in a large annotated corpus. Finally, in Study 3 we demonstrate how language-embedded stereotypes are associated with systematic prediction errors in a neural-network hate speech classifier. Our results demonstrate that hate speech classifiers learn human-like biases which can further perpetuate social inequalities when propagated at scale. This framework, combining social psychological and computational linguistic methods, provides insights into additional sources of bias in hate speech moderation, informing ongoing debates regarding fairness in machine learning.
Tackling data scarcity in speech translation using zero-shot multilingual machine translation techniques
Jan 26, 2022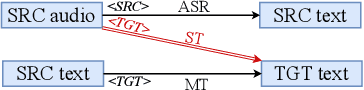
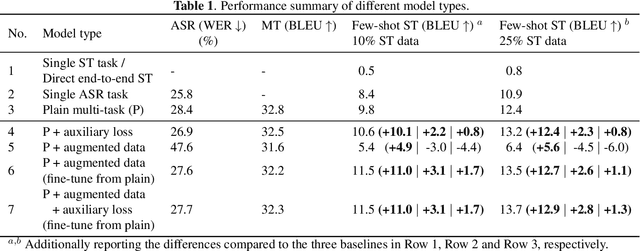

Recently, end-to-end speech translation (ST) has gained significant attention as it avoids error propagation. However, the approach suffers from data scarcity. It heavily depends on direct ST data and is less efficient in making use of speech transcription and text translation data, which is often more easily available. In the related field of multilingual text translation, several techniques have been proposed for zero-shot translation. A main idea is to increase the similarity of semantically similar sentences in different languages. We investigate whether these ideas can be applied to speech translation, by building ST models trained on speech transcription and text translation data. We investigate the effects of data augmentation and auxiliary loss function. The techniques were successfully applied to few-shot ST using limited ST data, with improvements of up to +12.9 BLEU points compared to direct end-to-end ST and +3.1 BLEU points compared to ST models fine-tuned from ASR model.
End-to-end model for named entity recognition from speech without paired training data
Apr 02, 2022
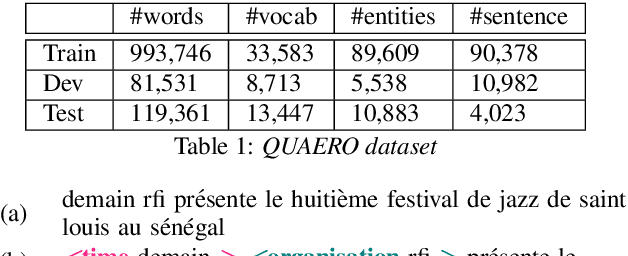


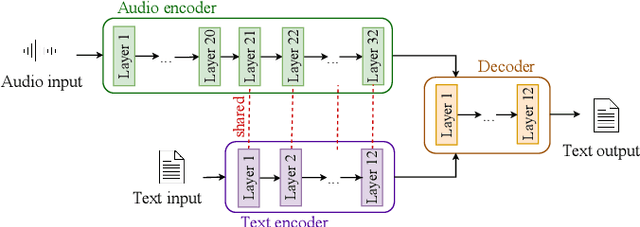
Recent works showed that end-to-end neural approaches tend to become very popular for spoken language understanding (SLU). Through the term end-to-end, one considers the use of a single model optimized to extract semantic information directly from the speech signal. A major issue for such models is the lack of paired audio and textual data with semantic annotation. In this paper, we propose an approach to build an end-to-end neural model to extract semantic information in a scenario in which zero paired audio data is available. Our approach is based on the use of an external model trained to generate a sequence of vectorial representations from text. These representations mimic the hidden representations that could be generated inside an end-to-end automatic speech recognition (ASR) model by processing a speech signal. An SLU neural module is then trained using these representations as input and the annotated text as output. Last, the SLU module replaces the top layers of the ASR model to achieve the construction of the end-to-end model. Our experiments on named entity recognition, carried out on the QUAERO corpus, show that this approach is very promising, getting better results than a comparable cascade approach or than the use of synthetic voices.