 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Leveraging Semantic Information for Efficient Self-Supervised Emotion Recognition with Audio-Textual Distilled Models
May 30, 2023
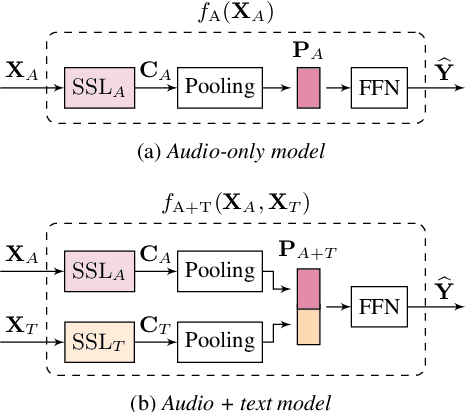
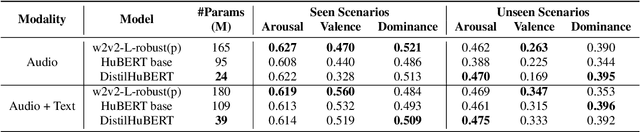
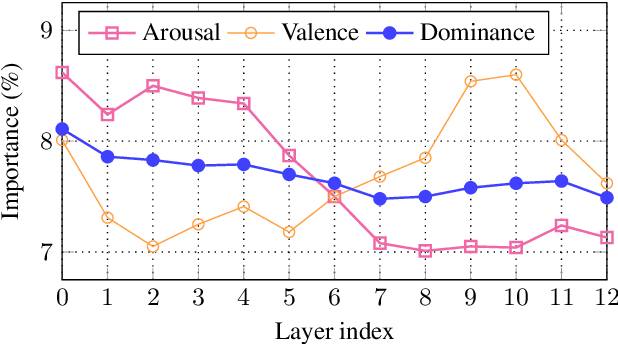

In large part due to their implicit semantic modeling, self-supervised learning (SSL) methods have significantly increased the performance of valence recognition in speech emotion recognition (SER) systems. Yet, their large size may often hinder practical implementations. In this work, we take HuBERT as an example of an SSL model and analyze the relevance of each of its layers for SER. We show that shallow layers are more important for arousal recognition while deeper layers are more important for valence. This observation motivates the importance of additional textual information for accurate valence recognition, as the distilled framework lacks the depth of its large-scale SSL teacher. Thus, we propose an audio-textual distilled SSL framework that, while having only ~20% of the trainable parameters of a large SSL model, achieves on par performance across the three emotion dimensions (arousal, valence, dominance) on the MSP-Podcast v1.10 dataset.
Perception and Semantic Aware Regularization for Sequential Confidence Calibration
May 31, 2023

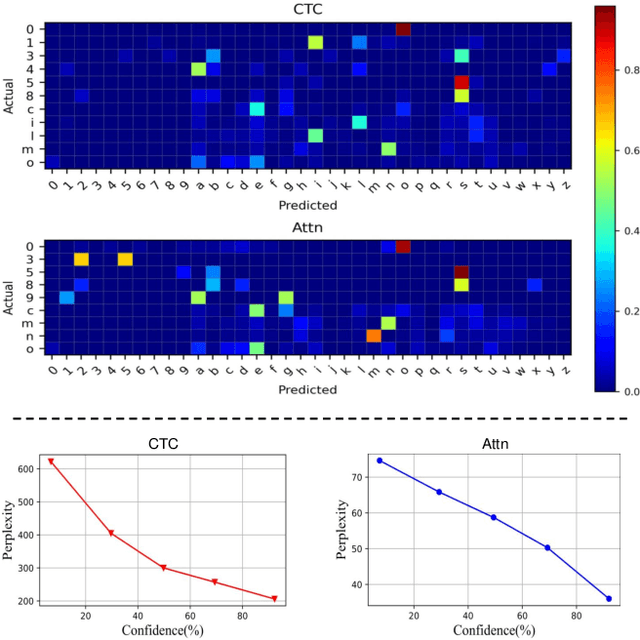
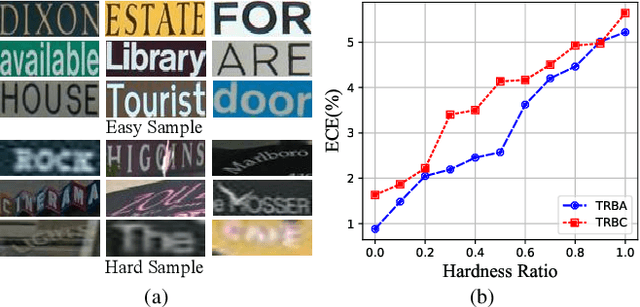
Deep sequence recognition (DSR) models receive increasing attention due to their superior application to various applications. Most DSR models use merely the target sequences as supervision without considering other related sequences, leading to over-confidence in their predictions. The DSR models trained with label smoothing regularize labels by equally and independently smoothing each token, reallocating a small value to other tokens for mitigating overconfidence. However, they do not consider tokens/sequences correlations that may provide more effective information to regularize training and thus lead to sub-optimal performance. In this work, we find tokens/sequences with high perception and semantic correlations with the target ones contain more correlated and effective information and thus facilitate more effective regularization. To this end, we propose a Perception and Semantic aware Sequence Regularization framework, which explore perceptively and semantically correlated tokens/sequences as regularization. Specifically, we introduce a semantic context-free recognition and a language model to acquire similar sequences with high perceptive similarities and semantic correlation, respectively. Moreover, over-confidence degree varies across samples according to their difficulties. Thus, we further design an adaptive calibration intensity module to compute a difficulty score for each samples to obtain finer-grained regularization. Extensive experiments on canonical sequence recognition tasks, including scene text and speech recognition, demonstrate that our method sets novel state-of-the-art results. Code is available at https://github.com/husterpzh/PSSR.
A Comparative Study of Pre-trained Speech and Audio Embeddings for Speech Emotion Recognition
Apr 22, 2023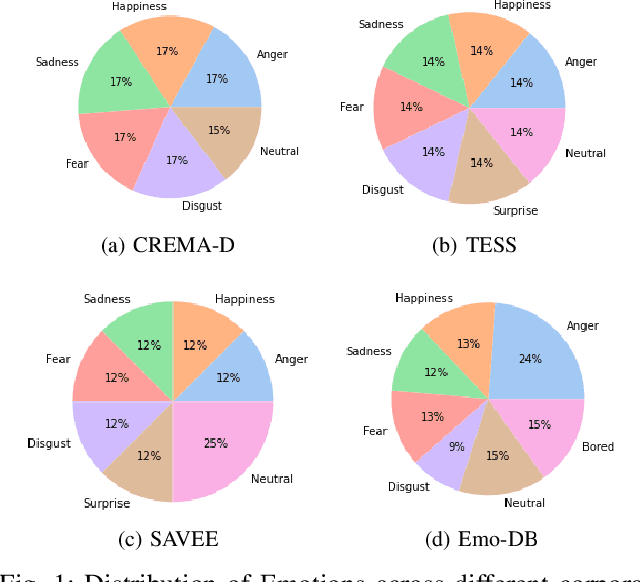
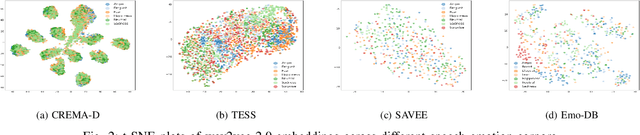

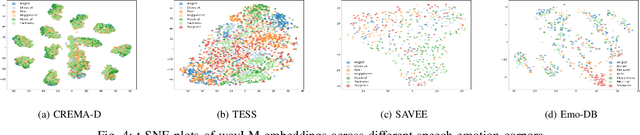
Pre-trained models (PTMs) have shown great promise in the speech and audio domain. Embeddings leveraged from these models serve as inputs for learning algorithms with applications in various downstream tasks. One such crucial task is Speech Emotion Recognition (SER) which has a wide range of applications, including dynamic analysis of customer calls, mental health assessment, and personalized language learning. PTM embeddings have helped advance SER, however, a comprehensive comparison of these PTM embeddings that consider multiple facets such as embedding model architecture, data used for pre-training, and the pre-training procedure being followed is missing. A thorough comparison of PTM embeddings will aid in the faster and more efficient development of models and enable their deployment in real-world scenarios. In this work, we exploit this research gap and perform a comparative analysis of embeddings extracted from eight speech and audio PTMs (wav2vec 2.0, data2vec, wavLM, UniSpeech-SAT, wav2clip, YAMNet, x-vector, ECAPA). We perform an extensive empirical analysis with four speech emotion datasets (CREMA-D, TESS, SAVEE, Emo-DB) by training three algorithms (XGBoost, Random Forest, FCN) on the derived embeddings. The results of our study indicate that the best performance is achieved by algorithms trained on embeddings derived from PTMs trained for speaker recognition followed by wav2clip and UniSpeech-SAT. This can relay that the top performance by embeddings from speaker recognition PTMs is most likely due to the model taking up information about numerous speech features such as tone, accent, pitch, and so on during its speaker recognition training. Insights from this work will assist future studies in their selection of embeddings for applications related to SER.
hierarchical network with decoupled knowledge distillation for speech emotion recognition
Mar 09, 2023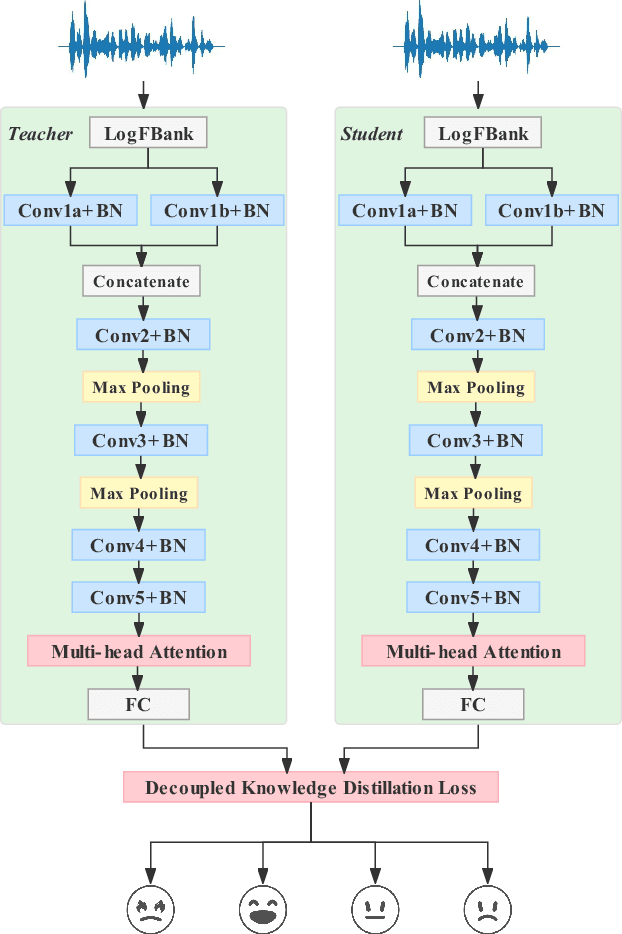
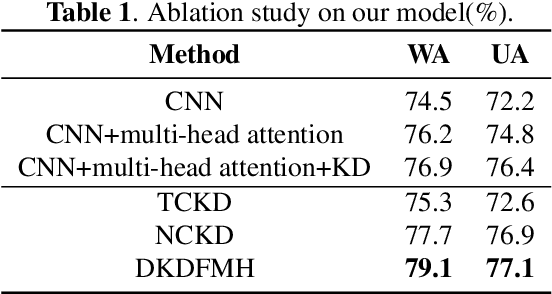
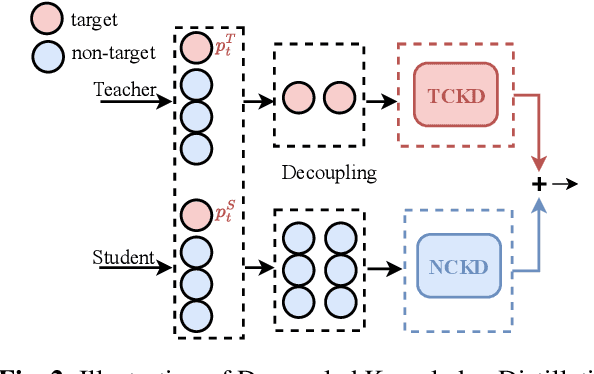
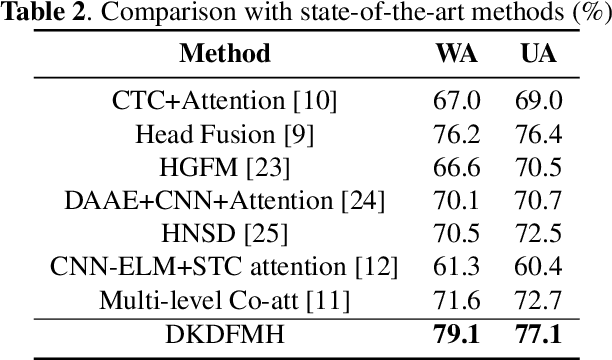
The goal of Speech Emotion Recognition (SER) is to enable computers to recognize the emotion category of a given utterance in the same way that humans do. The accuracy of SER is strongly dependent on the validity of the utterance-level representation obtained by the model. Nevertheless, the ``dark knowledge" carried by non-target classes is always ignored by previous studies. In this paper, we propose a hierarchical network, called DKDFMH, which employs decoupled knowledge distillation in a deep convolutional neural network with a fused multi-head attention mechanism. Our approach applies logit distillation to obtain higher-level semantic features from different scales of attention sets and delve into the knowledge carried by non-target classes, thus guiding the model to focus more on the differences between sentiment features. To validate the effectiveness of our model, we conducted experiments on the Interactive Emotional Dyadic Motion Capture (IEMOCAP) dataset. We achieved competitive performance, with 79.1% weighted accuracy (WA) and 77.1% unweighted accuracy (UA). To the best of our knowledge, this is the first time since 2015 that logit distillation has been returned to state-of-the-art status.
A Comparative Study on multichannel Speaker-attributed automatic speech recognition in Multi-party Meetings
Nov 01, 2022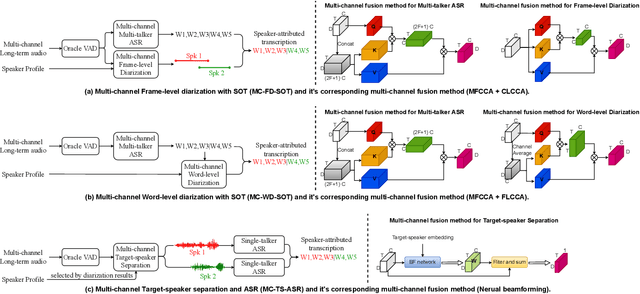


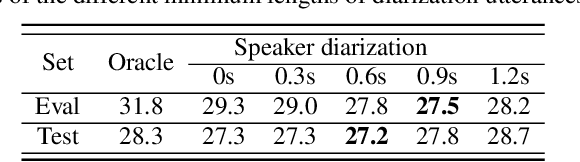
Speaker-attributed automatic speech recognition (SA-ASR) in multiparty meeting scenarios is one of the most valuable and challenging ASR task. It was shown that single-channel frame-level diarization with serialized output training (SC-FD-SOT), single-channel word-level diarization with SOT (SC-WD-SOT) and joint training of single-channel target-speaker separation and ASR (SC-TS-ASR) can be exploited to partially solve this problem. SC-FD-SOT obtains the speaker-attributed transcriptions by aligning the speaker diarization results with the ASR hypotheses, SC-WD-SOT uses word-level diarization to get rid of the alignment dependence on timestamps, and SC-TS-ASR jointly trains target-speaker separation and ASR modules, which achieves the best performance. In this paper, we propose three corresponding multichannel (MC) SA-ASR approaches, namely MC-FD-SOT, MC-WD-SOT and MC-TS-ASR. For different tasks/models, different multichannel data fusion strategies are considered, including channel-level cross-channel attention for MC-FD-SOT, frame-level cross-channel attention for MC-WD-SOT and neural beamforming for MC-TS-ASR. Experimental results on the AliMeeting corpus reveal that our proposed multichannel SA-ASR models can consistently outperform the corresponding single-channel counterparts in terms of the speaker-dependent character error rate (SD-CER).
SCRAPS: Speech Contrastive Representations of Acoustic and Phonetic Spaces
Jul 23, 2023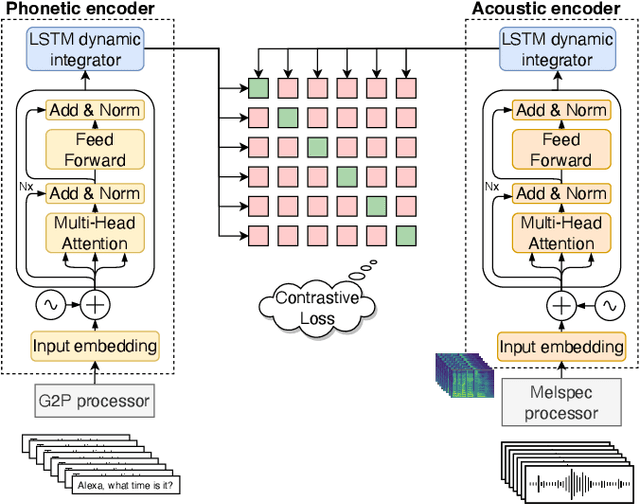
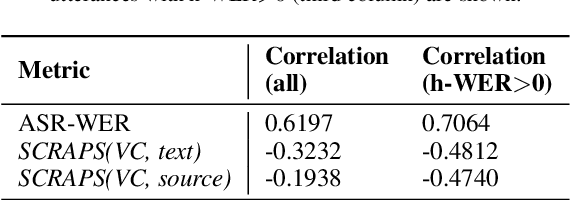
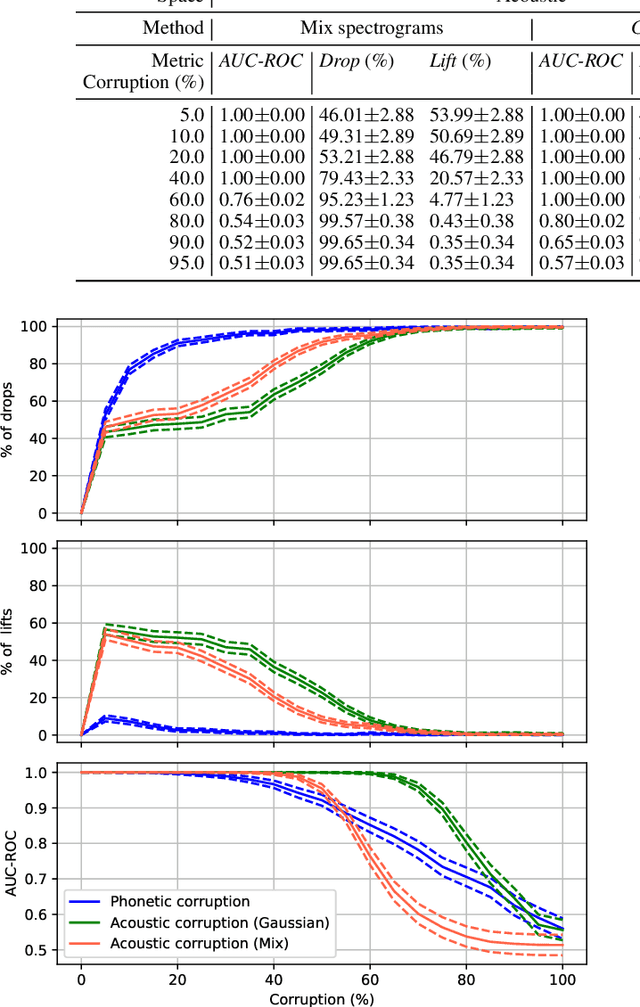
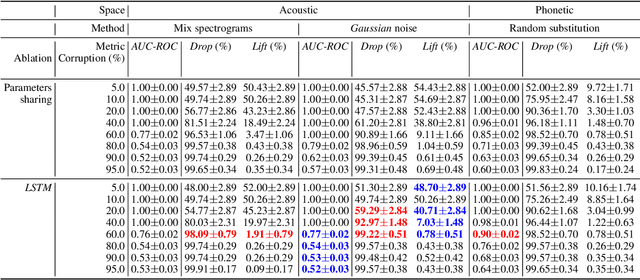
Numerous examples in the literature proved that deep learning models have the ability to work well with multimodal data. Recently, CLIP has enabled deep learning systems to learn shared latent spaces between images and text descriptions, with outstanding zero- or few-shot results in downstream tasks. In this paper we explore the same idea proposed by CLIP but applied to the speech domain, where the phonetic and acoustic spaces usually coexist. We train a CLIP-based model with the aim to learn shared representations of phonetic and acoustic spaces. The results show that the proposed model is sensible to phonetic changes, with a 91% of score drops when replacing 20% of the phonemes at random, while providing substantial robustness against different kinds of noise, with a 10% performance drop when mixing the audio with 75% of Gaussian noise. We also provide empirical evidence showing that the resulting embeddings are useful for a variety of downstream applications, such as intelligibility evaluation and the ability to leverage rich pre-trained phonetic embeddings in speech generation task. Finally, we discuss potential applications with interesting implications for the speech generation and recognition fields.
Accented Speech Recognition: A Survey
Apr 21, 2021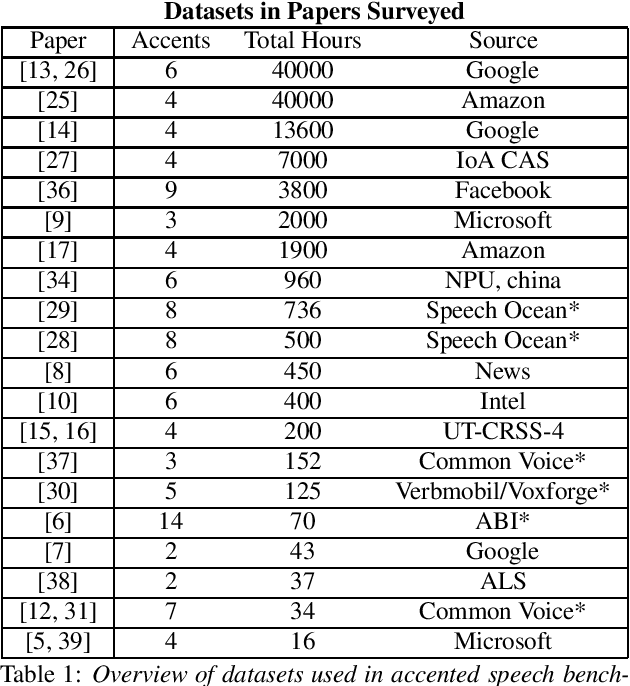
Automatic Speech Recognition (ASR) systems generalize poorly on accented speech. The phonetic and linguistic variability of accents present hard challenges for ASR systems today in both data collection and modeling strategies. The resulting bias in ASR performance across accents comes at a cost to both users and providers of ASR. We present a survey of current promising approaches to accented speech recognition and highlight the key challenges in the space. Approaches mostly focus on single model generalization and accent feature engineering. Among the challenges, lack of a standard benchmark makes research and comparison especially difficult.
Back Translation for Speech-to-text Translation Without Transcripts
May 15, 2023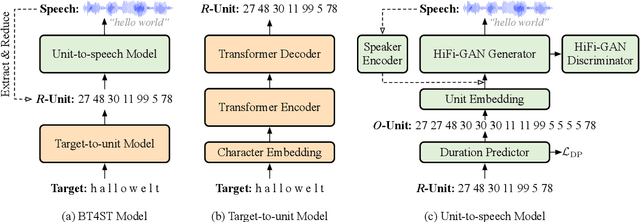
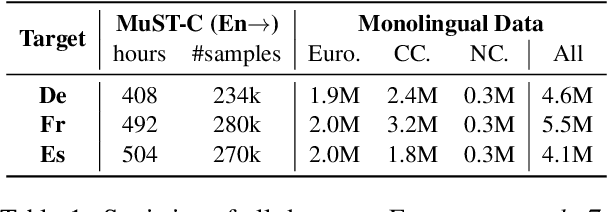
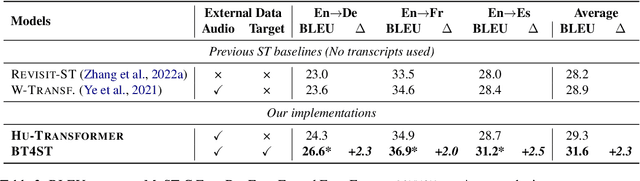
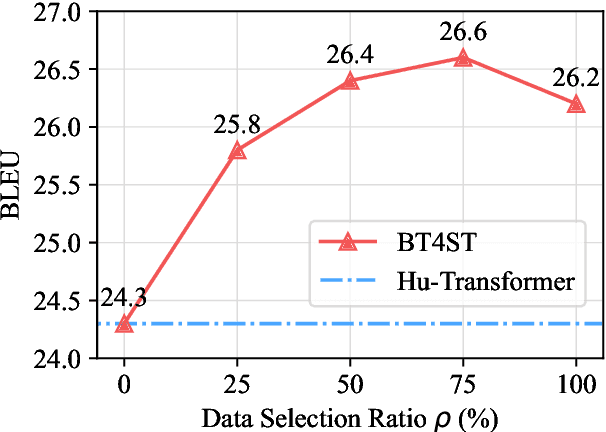
The success of end-to-end speech-to-text translation (ST) is often achieved by utilizing source transcripts, e.g., by pre-training with automatic speech recognition (ASR) and machine translation (MT) tasks, or by introducing additional ASR and MT data. Unfortunately, transcripts are only sometimes available since numerous unwritten languages exist worldwide. In this paper, we aim to utilize large amounts of target-side monolingual data to enhance ST without transcripts. Motivated by the remarkable success of back translation in MT, we develop a back translation algorithm for ST (BT4ST) to synthesize pseudo ST data from monolingual target data. To ease the challenges posed by short-to-long generation and one-to-many mapping, we introduce self-supervised discrete units and achieve back translation by cascading a target-to-unit model and a unit-to-speech model. With our synthetic ST data, we achieve an average boost of 2.3 BLEU on MuST-C En-De, En-Fr, and En-Es datasets. More experiments show that our method is especially effective in low-resource scenarios.
Improving Scheduled Sampling for Neural Transducer-based ASR
May 25, 2023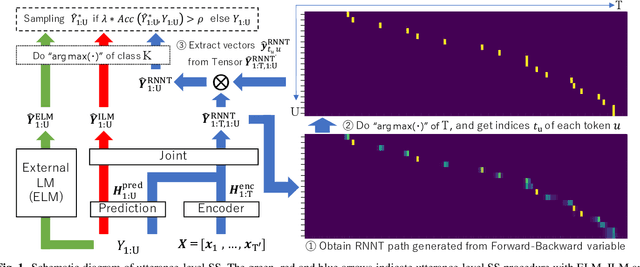
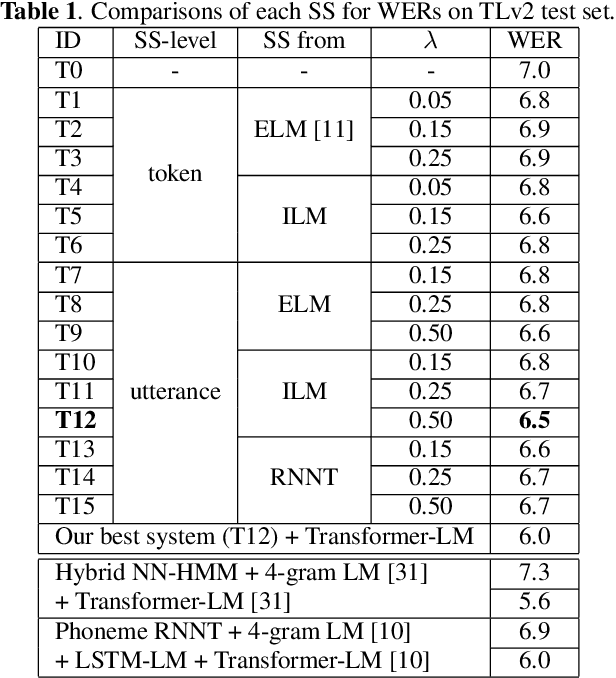
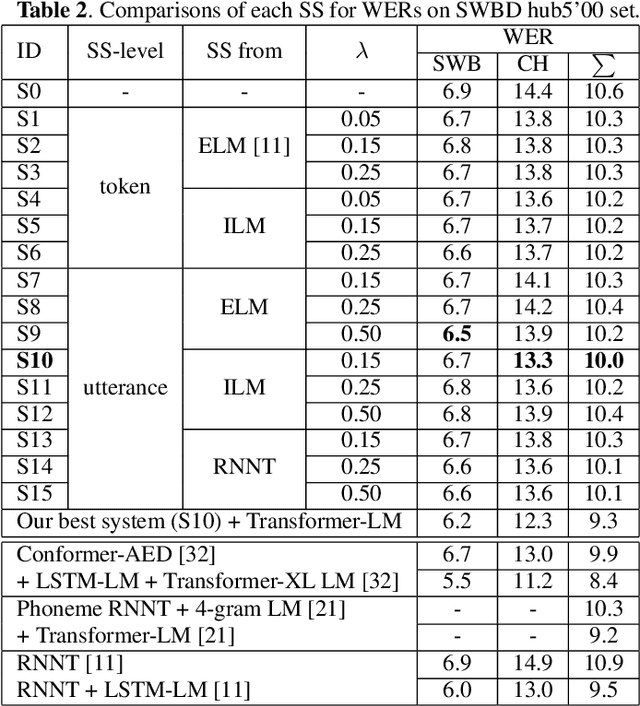
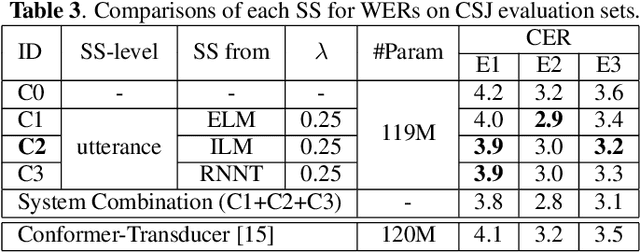
The recurrent neural network-transducer (RNNT) is a promising approach for automatic speech recognition (ASR) with the introduction of a prediction network that autoregressively considers linguistic aspects. To train the autoregressive part, the ground-truth tokens are used as substitutions for the previous output token, which leads to insufficient robustness to incorrect past tokens; a recognition error in the decoding leads to further errors. Scheduled sampling (SS) is a technique to train autoregressive model robustly to past errors by randomly replacing some ground-truth tokens with actual outputs generated from a model. SS mitigates the gaps between training and decoding steps, known as exposure bias, and it is often used for attentional encoder-decoder training. However SS has not been fully examined for RNNT because of the difficulty in applying SS to RNNT due to the complicated RNNT output form. In this paper we propose SS approaches suited for RNNT. Our SS approaches sample the tokens generated from the distiribution of RNNT itself, i.e. internal language model or RNNT outputs. Experiments in three datasets confirm that RNNT trained with our SS approach achieves the best ASR performance. In particular, on a Japanese ASR task, our best system outperforms the previous state-of-the-art alternative.
Exploration of Language Dependency for Japanese Self-Supervised Speech Representation Models
May 09, 2023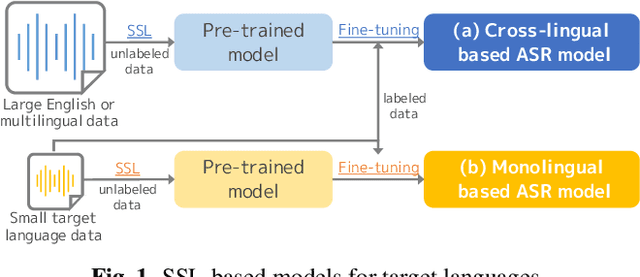
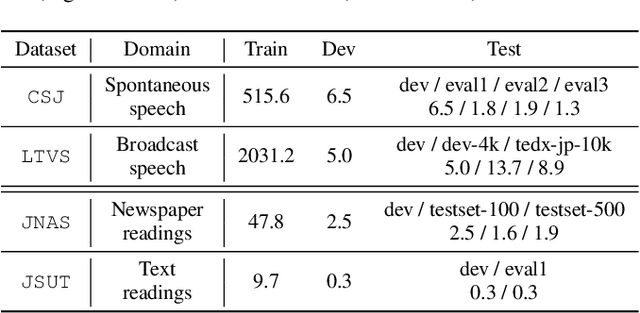
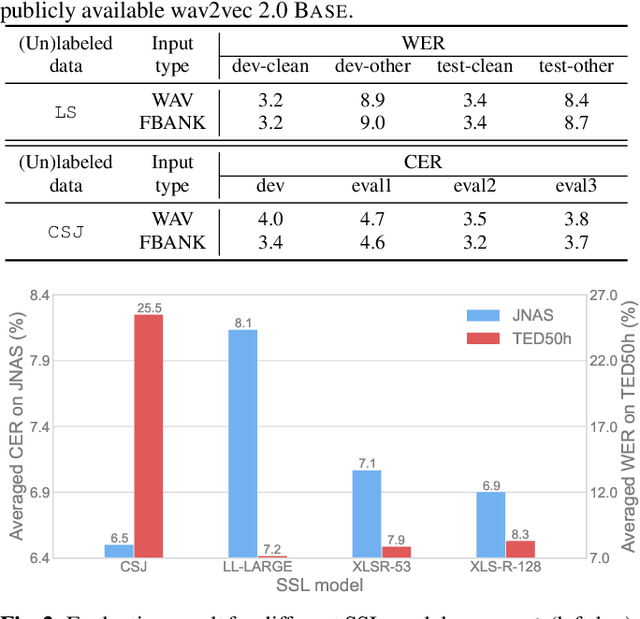
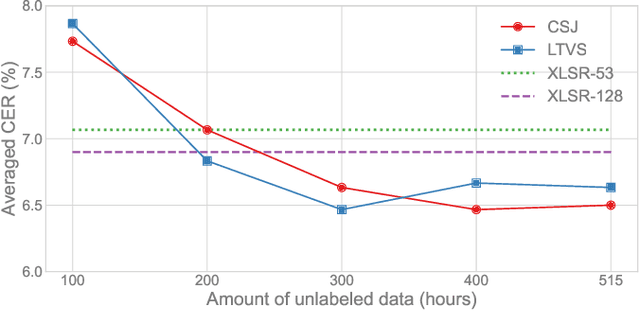
Self-supervised learning (SSL) has been dramatically successful not only in monolingual but also in cross-lingual settings. However, since the two settings have been studied individually in general, there has been little research focusing on how effective a cross-lingual model is in comparison with a monolingual model. In this paper, we investigate this fundamental question empirically with Japanese automatic speech recognition (ASR) tasks. First, we begin by comparing the ASR performance of cross-lingual and monolingual models for two different language tasks while keeping the acoustic domain as identical as possible. Then, we examine how much unlabeled data collected in Japanese is needed to achieve performance comparable to a cross-lingual model pre-trained with tens of thousands of hours of English and/or multilingual data. Finally, we extensively investigate the effectiveness of SSL in Japanese and demonstrate state-of-the-art performance on multiple ASR tasks. Since there is no comprehensive SSL study for Japanese, we hope this study will guide Japanese SSL research.