 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Music Mixing Style Transfer: A Contrastive Learning Approach to Disentangle Audio Effects
Nov 04, 2022
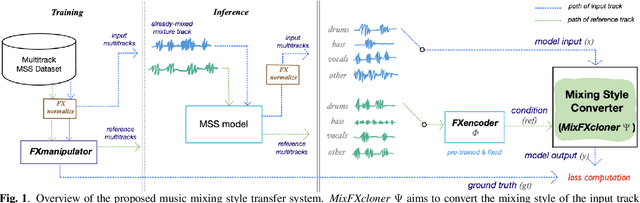
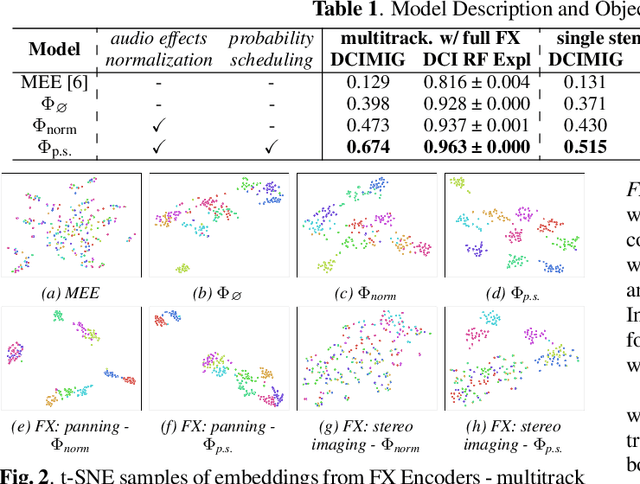
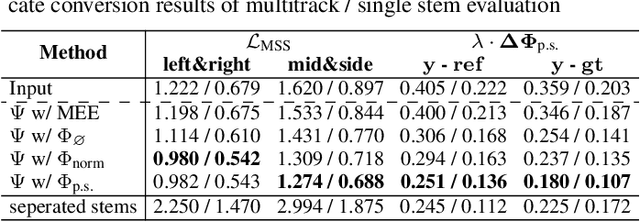
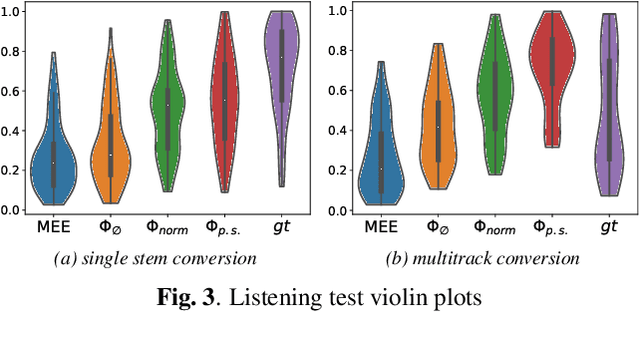
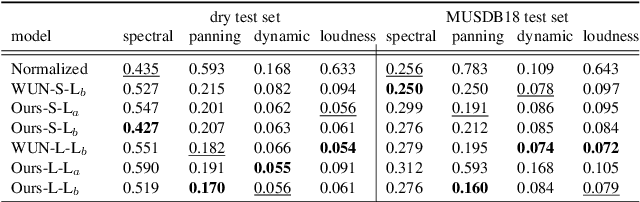
We propose an end-to-end music mixing style transfer system that converts the mixing style of an input multitrack to that of a reference song. This is achieved with an encoder pre-trained with a contrastive objective to extract only audio effects related information from a reference music recording. All our models are trained in a self-supervised manner from an already-processed wet multitrack dataset with an effective data preprocessing method that alleviates the data scarcity of obtaining unprocessed dry data. We analyze the proposed encoder for the disentanglement capability of audio effects and also validate its performance for mixing style transfer through both objective and subjective evaluations. From the results, we show the proposed system not only converts the mixing style of multitrack audio close to a reference but is also robust with mixture-wise style transfer upon using a music source separation model.
Learnable Front Ends Based on Temporal Modulation for Music Tagging
Nov 28, 2022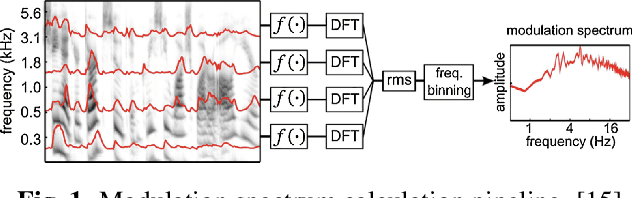
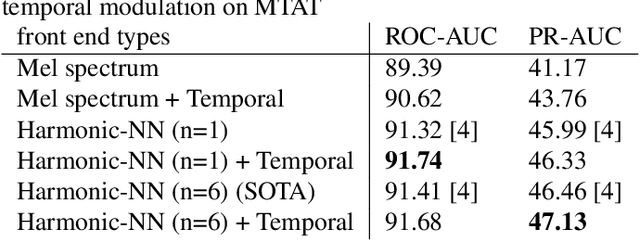
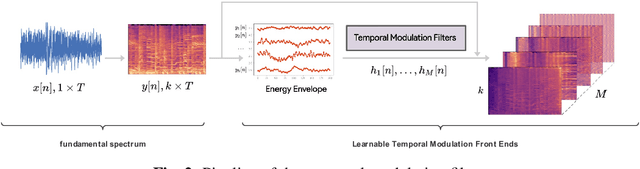
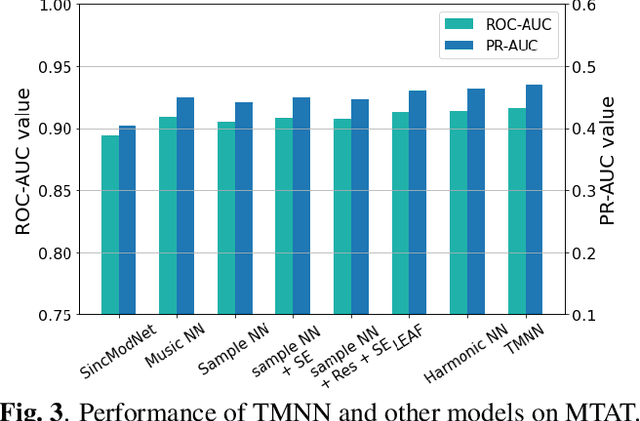
While end-to-end systems are becoming popular in auditory signal processing including automatic music tagging, models using raw audio as input needs a large amount of data and computational resources without domain knowledge. Inspired by the fact that temporal modulation is regarded as an essential component in auditory perception, we introduce the Temporal Modulation Neural Network (TMNN) that combines Mel-like data-driven front ends and temporal modulation filters with a simple ResNet back end. The structure includes a set of temporal modulation filters to capture long-term patterns in all frequency channels. Experimental results show that the proposed front ends surpass state-of-the-art (SOTA) methods on the MagnaTagATune dataset in automatic music tagging, and they are also helpful for keyword spotting on speech commands. Moreover, the model performance for each tag suggests that genre or instrument tags with complex rhythm and mood tags can especially be improved with temporal modulation.
GTN-Bailando: Genre Consistent Long-Term 3D Dance Generation based on Pre-trained Genre Token Network
Apr 25, 2023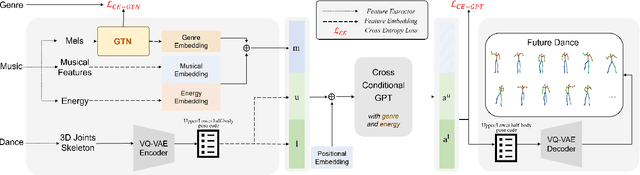
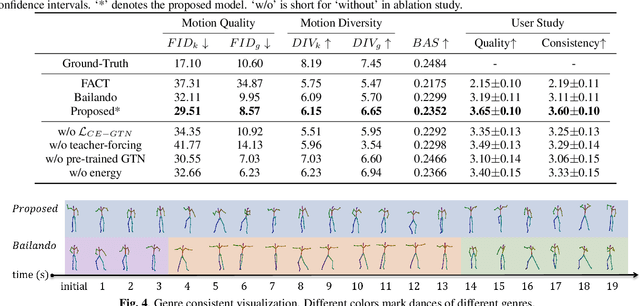
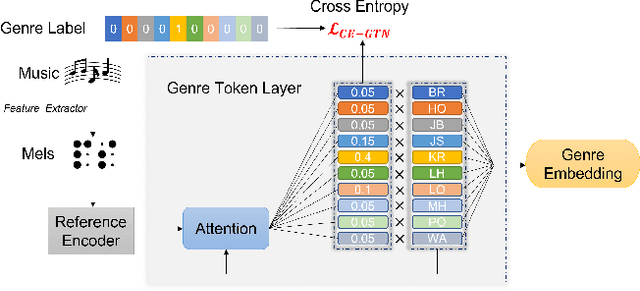
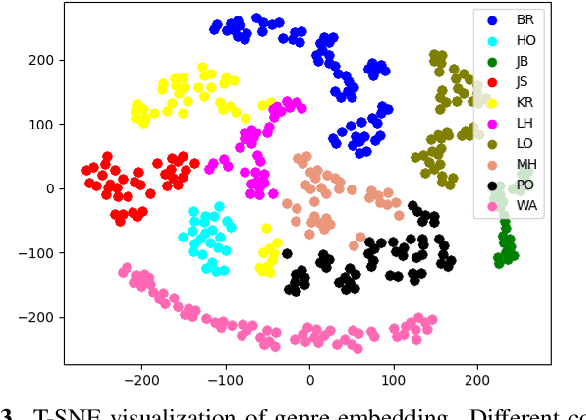
Music-driven 3D dance generation has become an intensive research topic in recent years with great potential for real-world applications. Most existing methods lack the consideration of genre, which results in genre inconsistency in the generated dance movements. In addition, the correlation between the dance genre and the music has not been investigated. To address these issues, we propose a genre-consistent dance generation framework, GTN-Bailando. First, we propose the Genre Token Network (GTN), which infers the genre from music to enhance the genre consistency of long-term dance generation. Second, to improve the generalization capability of the model, the strategy of pre-training and fine-tuning is adopted.Experimental results on the AIST++ dataset show that the proposed dance generation framework outperforms state-of-the-art methods in terms of motion quality and genre consistency.
LOAF-M2L: Joint Learning of Wording and Formatting for Singable Melody-to-Lyric Generation
Jul 05, 2023
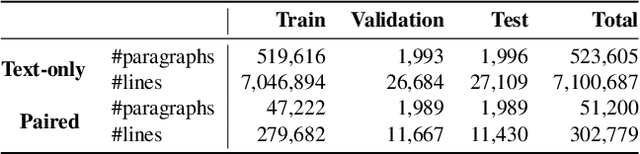

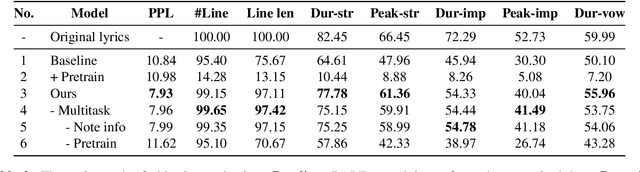
Despite previous efforts in melody-to-lyric generation research, there is still a significant compatibility gap between generated lyrics and melodies, negatively impacting the singability of the outputs. This paper bridges the singability gap with a novel approach to generating singable lyrics by jointly Learning wOrding And Formatting during Melody-to-Lyric training (LOAF-M2L). After general-domain pretraining, our proposed model acquires length awareness first from a large text-only lyric corpus. Then, we introduce a new objective informed by musicological research on the relationship between melody and lyrics during melody-to-lyric training, which enables the model to learn the fine-grained format requirements of the melody. Our model achieves 3.75% and 21.44% absolute accuracy gains in the outputs' number-of-line and syllable-per-line requirements compared to naive fine-tuning, without sacrificing text fluency. Furthermore, our model demonstrates a 63.92% and 74.18% relative improvement of music-lyric compatibility and overall quality in the subjective evaluation, compared to the state-of-the-art melody-to-lyric generation model, highlighting the significance of formatting learning.
A Unified Audio-Visual Learning Framework for Localization, Separation, and Recognition
May 30, 2023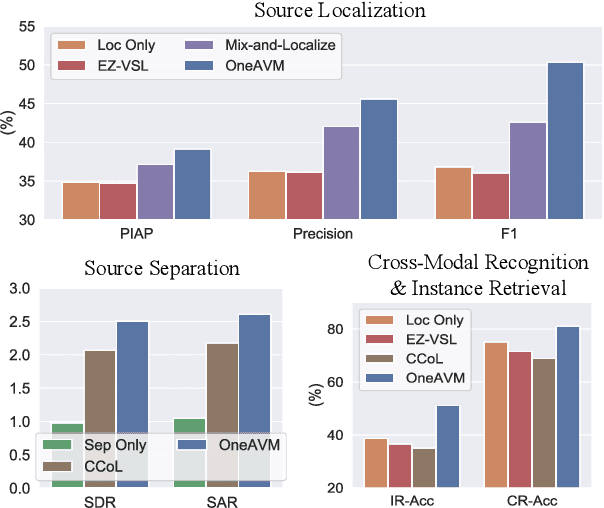
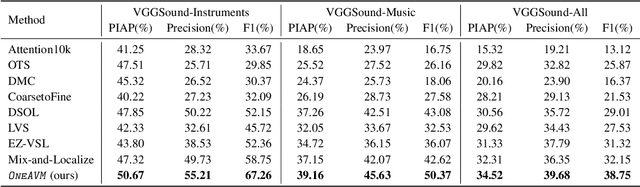
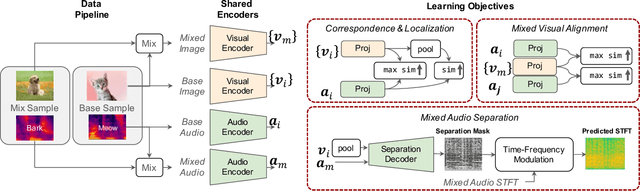
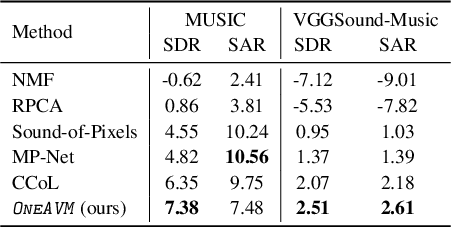
The ability to accurately recognize, localize and separate sound sources is fundamental to any audio-visual perception task. Historically, these abilities were tackled separately, with several methods developed independently for each task. However, given the interconnected nature of source localization, separation, and recognition, independent models are likely to yield suboptimal performance as they fail to capture the interdependence between these tasks. To address this problem, we propose a unified audio-visual learning framework (dubbed OneAVM) that integrates audio and visual cues for joint localization, separation, and recognition. OneAVM comprises a shared audio-visual encoder and task-specific decoders trained with three objectives. The first objective aligns audio and visual representations through a localized audio-visual correspondence loss. The second tackles visual source separation using a traditional mix-and-separate framework. Finally, the third objective reinforces visual feature separation and localization by mixing images in pixel space and aligning their representations with those of all corresponding sound sources. Extensive experiments on MUSIC, VGG-Instruments, VGG-Music, and VGGSound datasets demonstrate the effectiveness of OneAVM for all three tasks, audio-visual source localization, separation, and nearest neighbor recognition, and empirically demonstrate a strong positive transfer between them.
Volume-Independent Music Matching by Frequency Spectrum Comparison
Jun 28, 2022
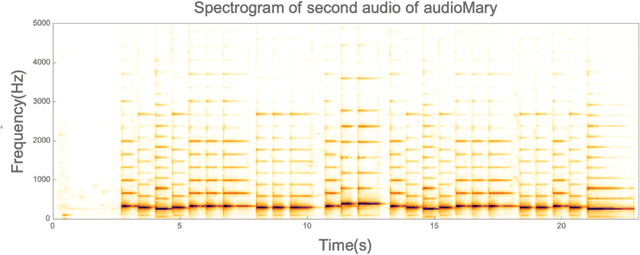

Often, I hear a piece of music and wonder what the name of the piece is. Indeed, there are applications such as Shazam app that provides music matching. However, the limitations of those apps are that the same piece performed by the same musician cannot be identified if it is not the same recording. Shazam identifies the recording of it, not the music. This is because Shazam matches the variation in volume, not the frequencies of the sound. This research attempts to match music the way humans understand it: by the frequency spectrum of music, not the volume variation. Essentially, the idea is to precompute the frequency spectrums of all the music in the database, then take the unknown piece and try to match its frequency spectrum against every segment of every music in the database. I did it by matching the frequency spectrum of the unknown piece to our database by sliding the window by 0.1 seconds and calculating the error by taking Absolute value, normalizing the audio, subtracting the normalized arrays, and taking the sum of absolute differences. The segment that shows the least error is considered the candidate for the match. The matching performance proved to be dependent on the complexity of the music. Matching simple music, such as single note pieces, was successful. However, more complex pieces, such as Chopins Ballade 4, were not successful, that is, the algorithm could not produce low error values in any of the music in the database. I suspect that it has to do with having too many notes: mismatches in the higher harmonics added up to a significant amount of errors, which swamps the calculations.
Audio classification using ML methods
May 30, 2023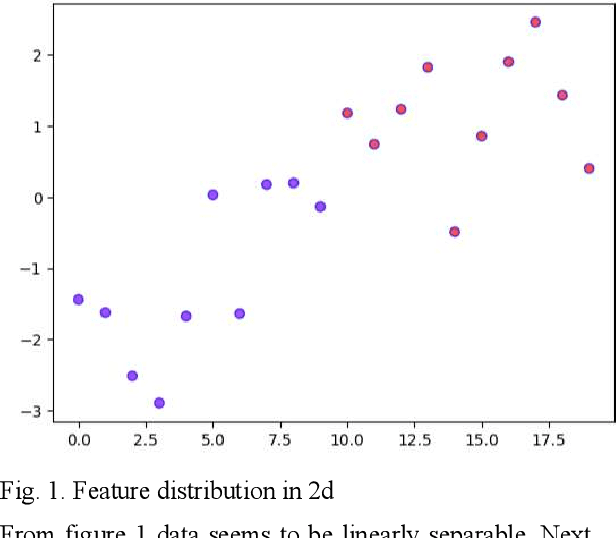
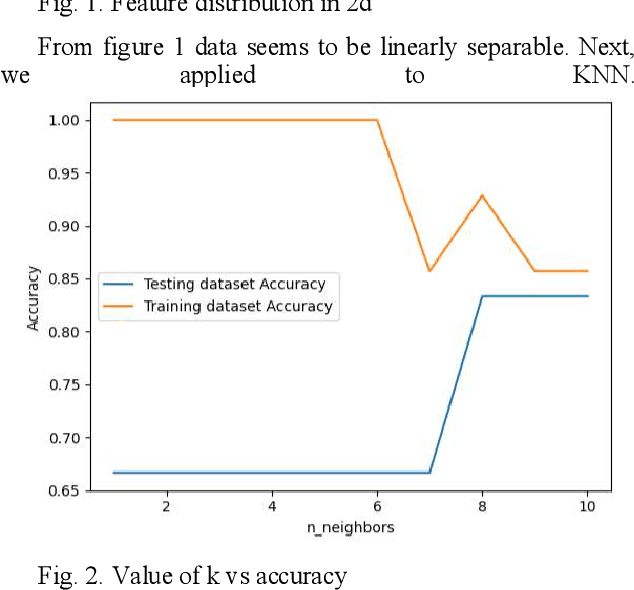


Machine Learning systems have achieved outstanding performance in different domains. In this paper machine learning methods have been applied to classification task to classify music genre. The code shows how to extract features from audio files and classify them using supervised learning into 2 genres namely classical and metal. Algorithms used are LogisticRegression, SVC using different kernals (linear, sigmoid, rbf and poly), KNeighborsClassifier , RandomForestClassifier, DecisionTreeClassifier and GaussianNB.
Automatic music mixing with deep learning and out-of-domain data
Aug 29, 2022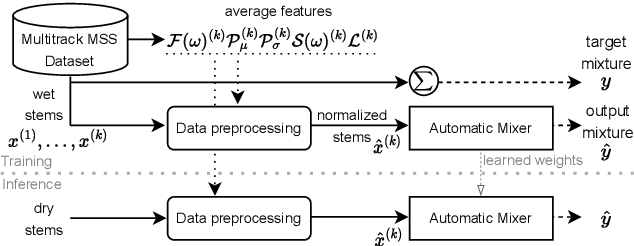
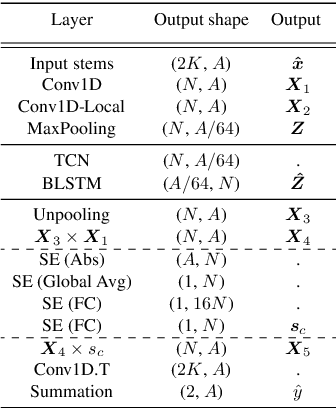

Music mixing traditionally involves recording instruments in the form of clean, individual tracks and blending them into a final mixture using audio effects and expert knowledge (e.g., a mixing engineer). The automation of music production tasks has become an emerging field in recent years, where rule-based methods and machine learning approaches have been explored. Nevertheless, the lack of dry or clean instrument recordings limits the performance of such models, which is still far from professional human-made mixes. We explore whether we can use out-of-domain data such as wet or processed multitrack music recordings and repurpose it to train supervised deep learning models that can bridge the current gap in automatic mixing quality. To achieve this we propose a novel data preprocessing method that allows the models to perform automatic music mixing. We also redesigned a listening test method for evaluating music mixing systems. We validate our results through such subjective tests using highly experienced mixing engineers as participants.
The Ethical Implications of Generative Audio Models: A Systematic Literature Review
Jul 07, 2023Generative audio models typically focus their applications in music and speech generation, with recent models having human-like quality in their audio output. This paper conducts a systematic literature review of 884 papers in the area of generative audio models in order to both quantify the degree to which researchers in the field are considering potential negative impacts and identify the types of ethical implications researchers in this area need to consider. Though 65% of generative audio research papers note positive potential impacts of their work, less than 10% discuss any negative impacts. This jarringly small percentage of papers considering negative impact is particularly worrying because the issues brought to light by the few papers doing so are raising serious ethical implications and concerns relevant to the broader field such as the potential for fraud, deep-fakes, and copyright infringement. By quantifying this lack of ethical consideration in generative audio research and identifying key areas of potential harm, this paper lays the groundwork for future work in the field at a critical point in time in order to guide more conscientious research as this field progresses.
Real-time Percussive Technique Recognition and Embedding Learning for the Acoustic Guitar
Jul 13, 2023Real-time music information retrieval (RT-MIR) has much potential to augment the capabilities of traditional acoustic instruments. We develop RT-MIR techniques aimed at augmenting percussive fingerstyle, which blends acoustic guitar playing with guitar body percussion. We formulate several design objectives for RT-MIR systems for augmented instrument performance: (i) causal constraint, (ii) perceptually negligible action-to-sound latency, (iii) control intimacy support, (iv) synthesis control support. We present and evaluate real-time guitar body percussion recognition and embedding learning techniques based on convolutional neural networks (CNNs) and CNNs jointly trained with variational autoencoders (VAEs). We introduce a taxonomy of guitar body percussion based on hand part and location. We follow a cross-dataset evaluation approach by collecting three datasets labelled according to the taxonomy. The embedding quality of the models is assessed using KL-Divergence across distributions corresponding to different taxonomic classes. Results indicate that the networks are strong classifiers especially in a simplified 2-class recognition task, and the VAEs yield improved class separation compared to CNNs as evidenced by increased KL-Divergence across distributions. We argue that the VAE embedding quality could support control intimacy and rich interaction when the latent space's parameters are used to control an external synthesis engine. Further design challenges around generalisation to different datasets have been identified.