 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Multi-Genre Music Transformer -- Composing Full Length Musical Piece
Jan 06, 2023
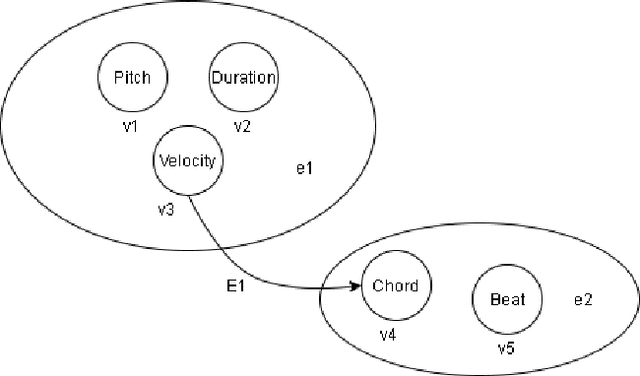

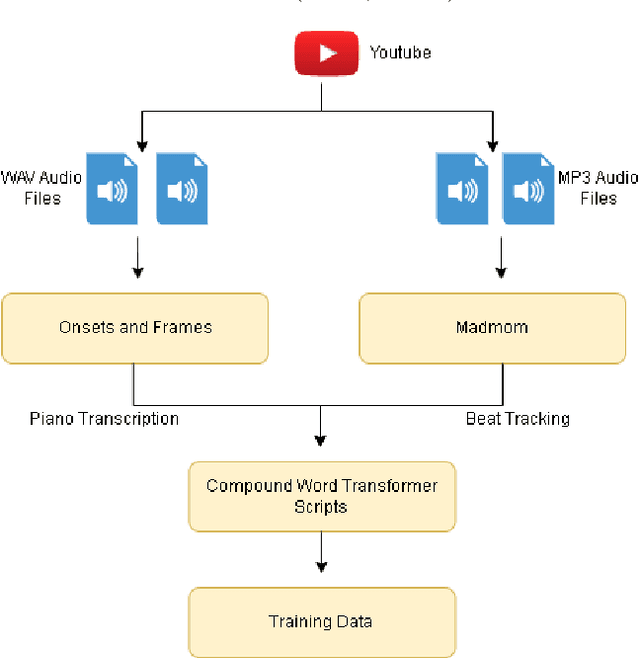
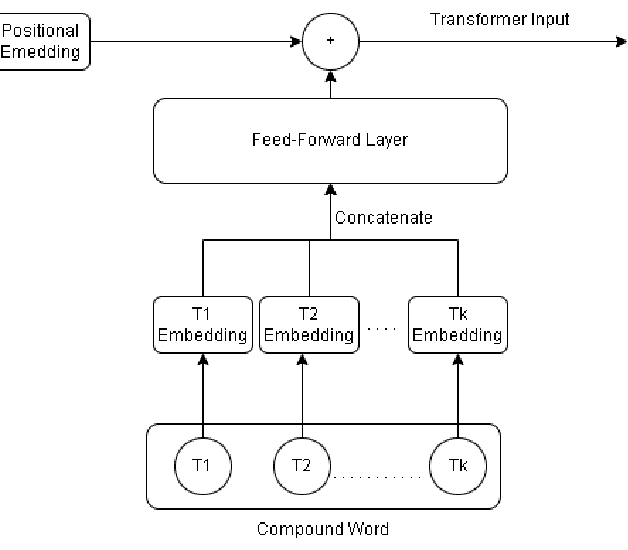
In the task of generating music, the art factor plays a big role and is a great challenge for AI. Previous work involving adversarial training to produce new music pieces and modeling the compatibility of variety in music (beats, tempo, musical stems) demonstrated great examples of learning this task. Though this was limited to generating mashups or learning features from tempo and key distributions to produce similar patterns. Compound Word Transformer was able to represent music generation task as a sequence generation challenge involving musical events defined by compound words. These musical events give a more accurate description of notes progression, chord change, harmony and the art factor. The objective of the project is to implement a Multi-Genre Transformer which learns to produce music pieces through more adaptive learning process involving more challenging task where genres or form of the composition is also considered. We built a multi-genre compound word dataset, implemented a linear transformer which was trained on this dataset. We call this Multi-Genre Transformer, which was able to generate full length new musical pieces which is diverse and comparable to original tracks. The model trains 2-5 times faster than other models discussed.
Toward Universal Text-to-Music Retrieval
Nov 26, 2022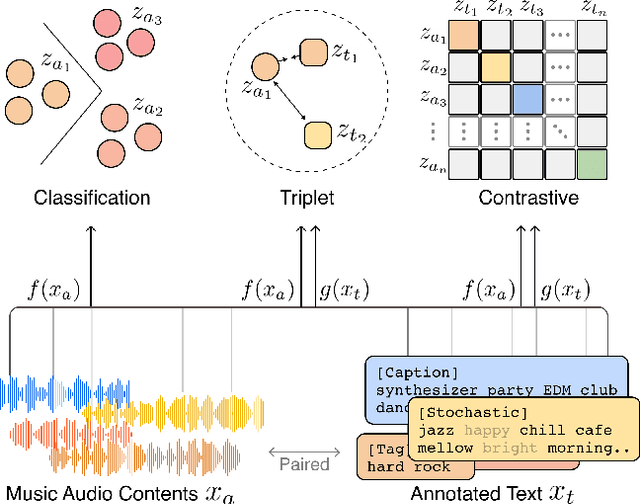

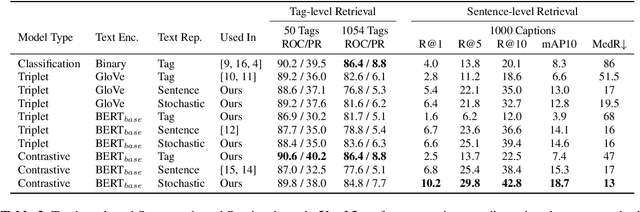

This paper introduces effective design choices for text-to-music retrieval systems. An ideal text-based retrieval system would support various input queries such as pre-defined tags, unseen tags, and sentence-level descriptions. In reality, most previous works mainly focused on a single query type (tag or sentence) which may not generalize to another input type. Hence, we review recent text-based music retrieval systems using our proposed benchmark in two main aspects: input text representation and training objectives. Our findings enable a universal text-to-music retrieval system that achieves comparable retrieval performances in both tag- and sentence-level inputs. Furthermore, the proposed multimodal representation generalizes to 9 different downstream music classification tasks. We present the code and demo online.
Msanii: High Fidelity Music Synthesis on a Shoestring Budget
Jan 16, 2023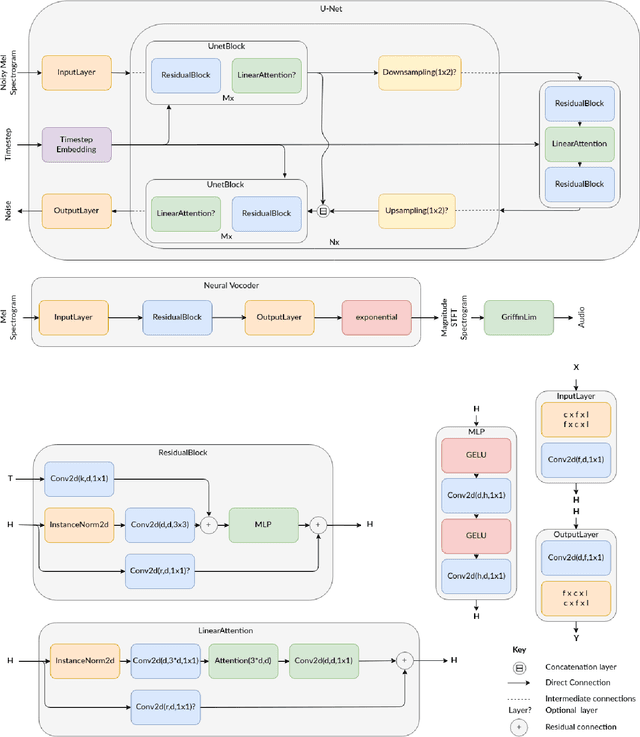
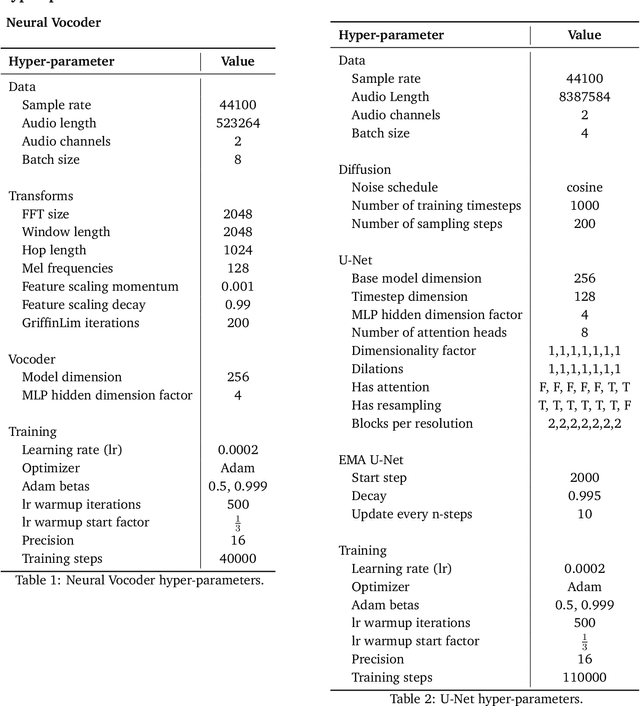

In this paper, we present Msanii, a novel diffusion-based model for synthesizing long-context, high-fidelity music efficiently. Our model combines the expressiveness of mel spectrograms, the generative capabilities of diffusion models, and the vocoding capabilities of neural vocoders. We demonstrate the effectiveness of Msanii by synthesizing tens of seconds (190 seconds) of stereo music at high sample rates (44.1 kHz) without the use of concatenative synthesis, cascading architectures, or compression techniques. To the best of our knowledge, this is the first work to successfully employ a diffusion-based model for synthesizing such long music samples at high sample rates. Our demo can be found https://kinyugo.github.io/msanii-demo and our code https://github.com/Kinyugo/msanii .
A Review of Intelligent Music Generation Systems
Nov 22, 2022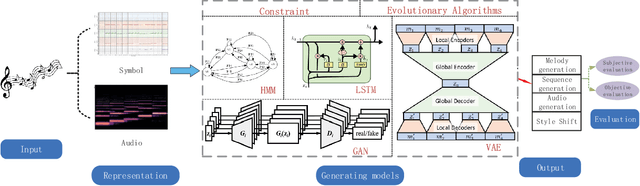

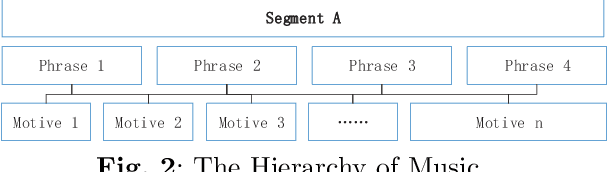
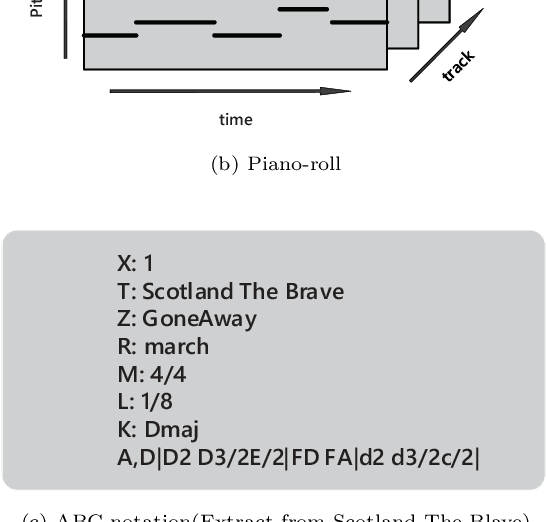
Intelligent music generation, one of the most popular subfields of computer creativity, can lower the creative threshold for non-specialists and increase the efficiency of music creation. In the last five years, the quality of algorithm-based automatic music generation has increased significantly, motivated by the use of modern generative algorithms to learn the patterns implicit within a piece of music based on rule constraints or a musical corpus, thus generating music samples in various styles. Some of the available literature reviews lack a systematic benchmark of generative models and are traditional and conservative in their perspective, resulting in a vision of the future development of the field that is not deeply integrated with the current rapid scientific progress. In this paper, we conduct a comprehensive survey and analysis of recent intelligent music generation techniques,provide a critical discussion, explicitly identify their respective characteristics, and present them in a general table. We first introduce how music as a stream of information is encoded and the relevant datasets, then compare different types of generation algorithms, summarize their strengths and weaknesses, and discuss existing methods for evaluation. Finally, the development of artificial intelligence in composition is studied, especially by comparing the different characteristics of music generation techniques in the East and West and analyzing the development prospects in this field.
Pied Piper: Meta Search for Music
Nov 14, 2022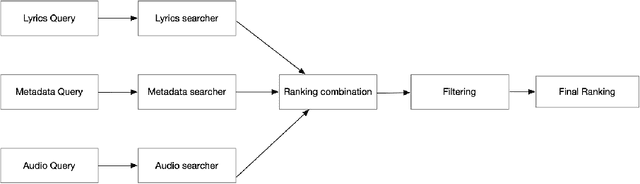
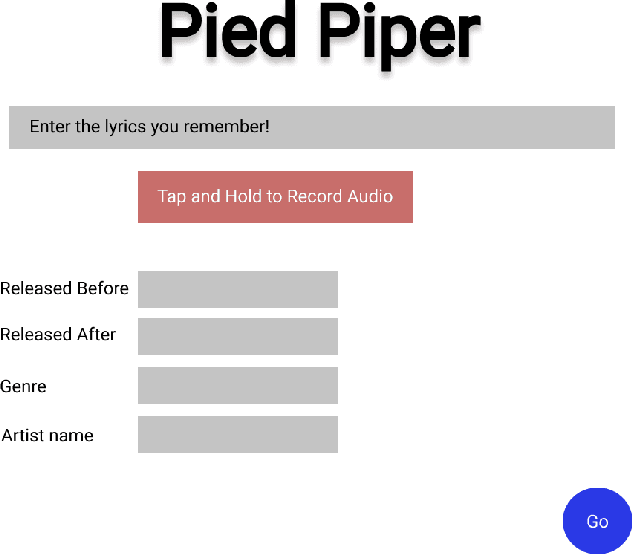
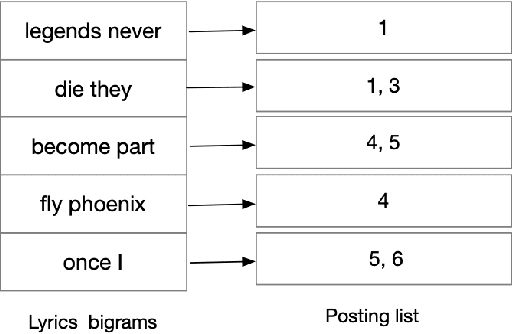
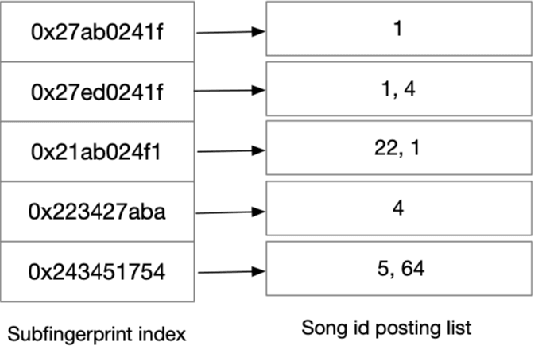
Internet search engines have become an integral part of life, but for pop music, people still rely on textual search engines like Google. We propose Pied piper, a meta search engine for music. It can search for music lyrics, song metadata and song audio or a combination of any of these as the input query and efficiently return the relevant results.
Affective Idiosyncratic Responses to Music
Oct 17, 2022
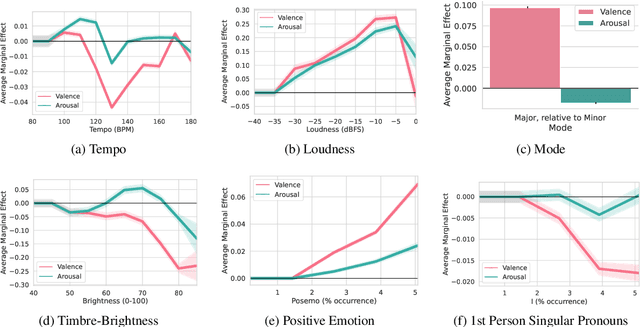
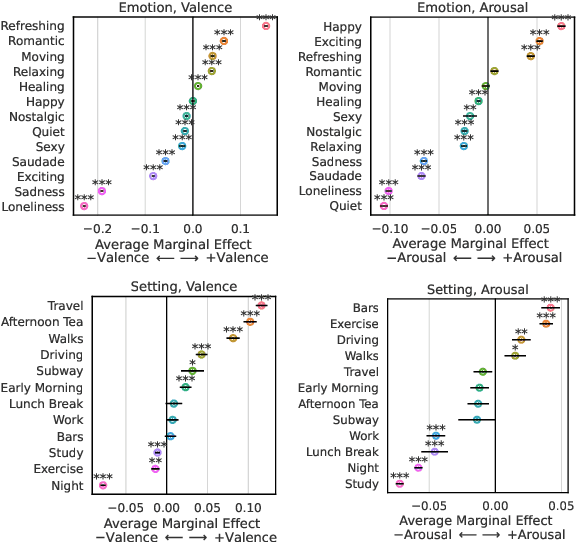
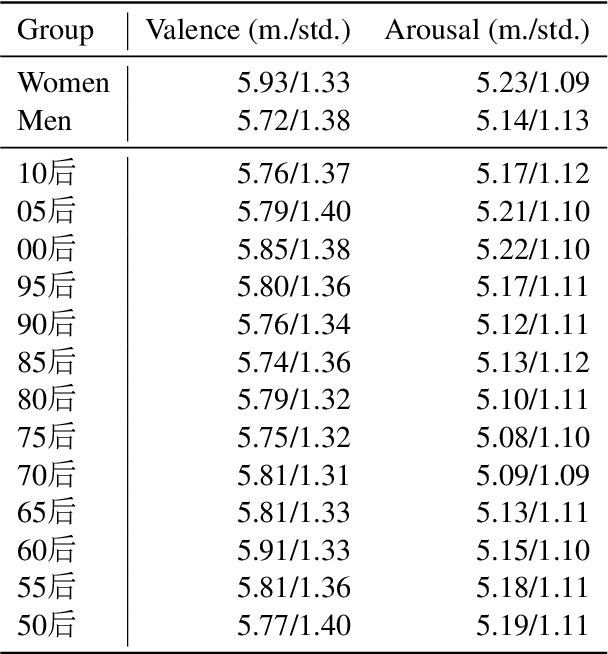
Affective responses to music are highly personal. Despite consensus that idiosyncratic factors play a key role in regulating how listeners emotionally respond to music, precisely measuring the marginal effects of these variables has proved challenging. To address this gap, we develop computational methods to measure affective responses to music from over 403M listener comments on a Chinese social music platform. Building on studies from music psychology in systematic and quasi-causal analyses, we test for musical, lyrical, contextual, demographic, and mental health effects that drive listener affective responses. Finally, motivated by the social phenomenon known as w\v{a}ng-y\`i-y\'un, we identify influencing factors of platform user self-disclosures, the social support they receive, and notable differences in discloser user activity.
Sparks of Large Audio Models: A Survey and Outlook
Sep 03, 2023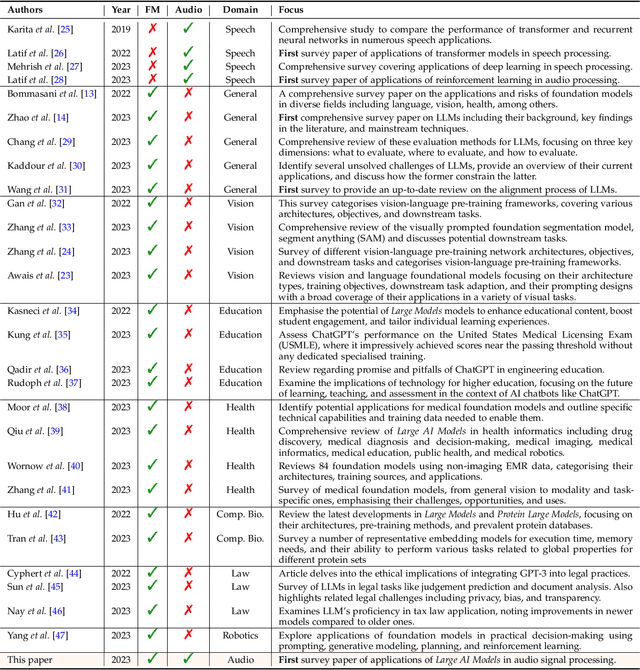

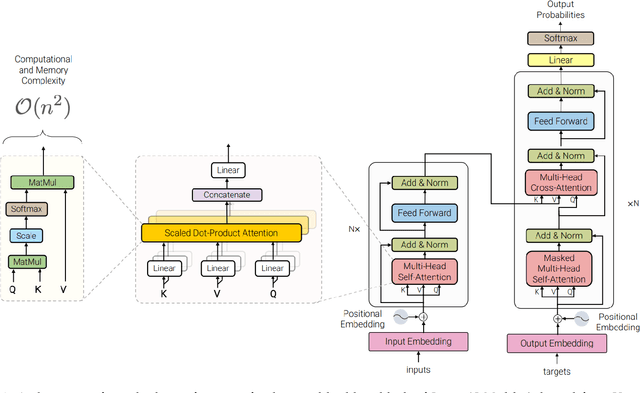
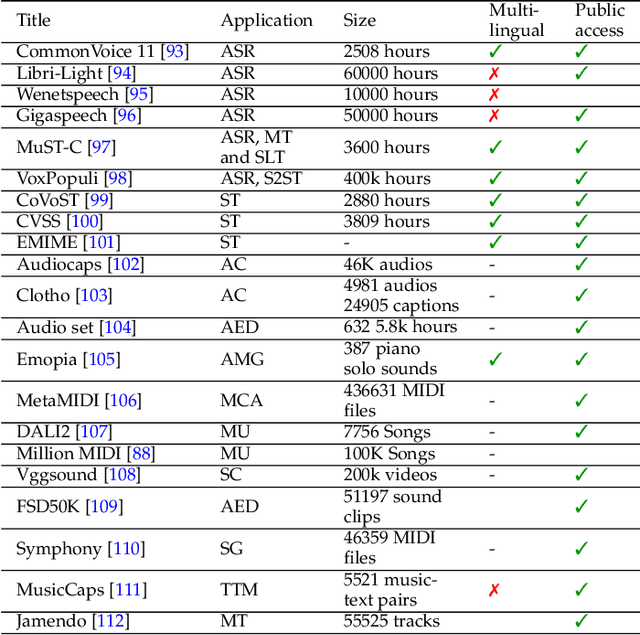
This survey paper provides a comprehensive overview of the recent advancements and challenges in applying large language models to the field of audio signal processing. Audio processing, with its diverse signal representations and a wide range of sources--from human voices to musical instruments and environmental sounds--poses challenges distinct from those found in traditional Natural Language Processing scenarios. Nevertheless, \textit{Large Audio Models}, epitomized by transformer-based architectures, have shown marked efficacy in this sphere. By leveraging massive amount of data, these models have demonstrated prowess in a variety of audio tasks, spanning from Automatic Speech Recognition and Text-To-Speech to Music Generation, among others. Notably, recently these Foundational Audio Models, like SeamlessM4T, have started showing abilities to act as universal translators, supporting multiple speech tasks for up to 100 languages without any reliance on separate task-specific systems. This paper presents an in-depth analysis of state-of-the-art methodologies regarding \textit{Foundational Large Audio Models}, their performance benchmarks, and their applicability to real-world scenarios. We also highlight current limitations and provide insights into potential future research directions in the realm of \textit{Large Audio Models} with the intent to spark further discussion, thereby fostering innovation in the next generation of audio-processing systems. Furthermore, to cope with the rapid development in this area, we will consistently update the relevant repository with relevant recent articles and their open-source implementations at https://github.com/EmulationAI/awesome-large-audio-models.
Generating symbolic music using diffusion models
Mar 15, 2023
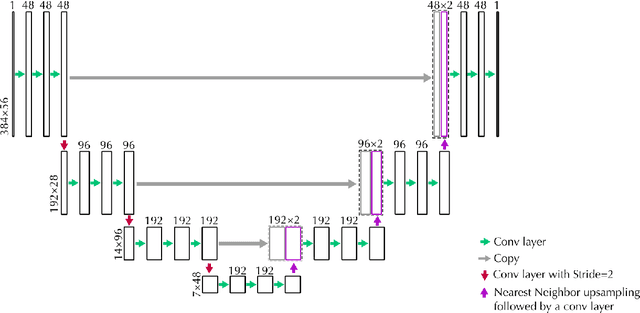


Probabilistic Denoising Diffusion models have emerged as simple yet very powerful generative models. Diffusion models unlike other generative models do not suffer from mode collapse nor require a discriminator to generate high quality samples. In this paper, we propose a diffusion model that uses a binomial prior distribution to generate piano-rolls. The paper also proposes an efficient method to train the model and generate samples. The generated music has coherence at time scales up to the length of the training piano-roll segments. We show how such a model is conditioned on the input and can be used to harmonize a given melody, complete an incomplete piano-roll or generate a variation of a given piece. The code is shared publicly to encourage the use and development of the method by the community.
Generating music with sentiment using Transformer-GANs
Dec 21, 2022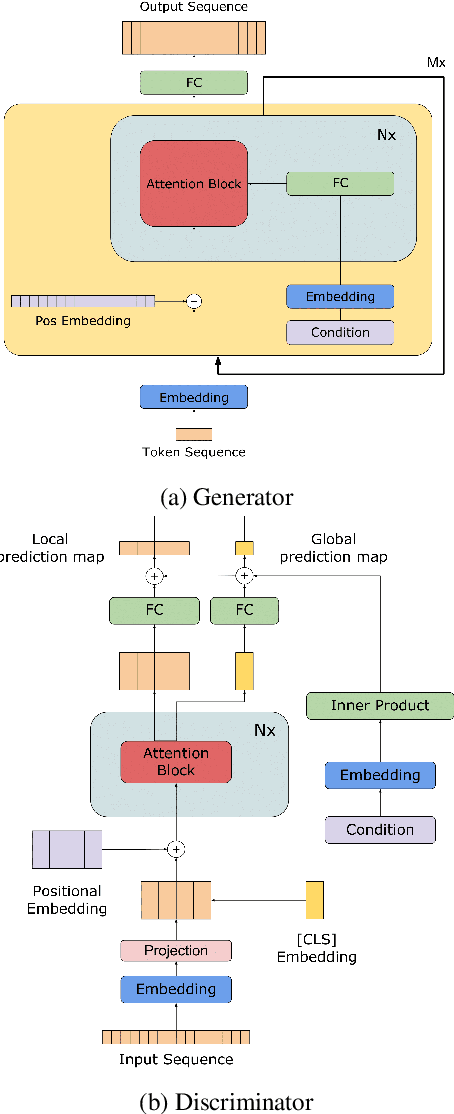
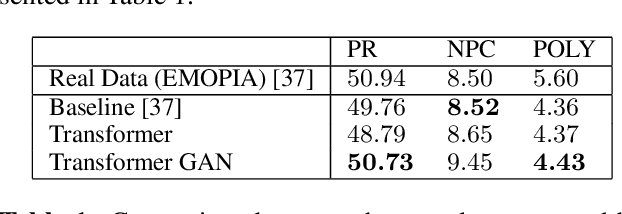
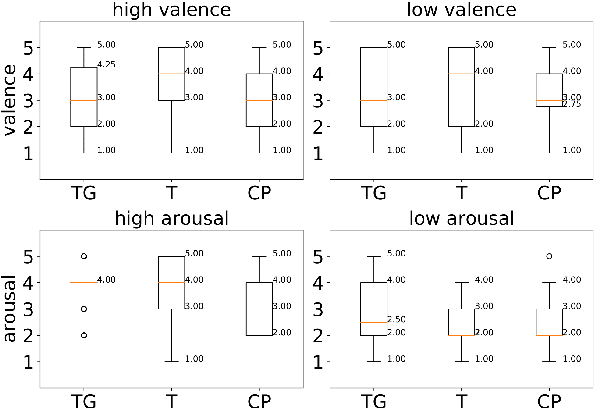
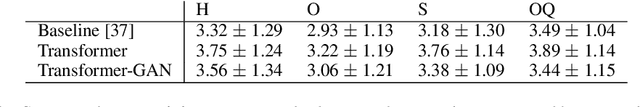
The field of Automatic Music Generation has seen significant progress thanks to the advent of Deep Learning. However, most of these results have been produced by unconditional models, which lack the ability to interact with their users, not allowing them to guide the generative process in meaningful and practical ways. Moreover, synthesizing music that remains coherent across longer timescales while still capturing the local aspects that make it sound ``realistic'' or ``human-like'' is still challenging. This is due to the large computational requirements needed to work with long sequences of data, and also to limitations imposed by the training schemes that are often employed. In this paper, we propose a generative model of symbolic music conditioned by data retrieved from human sentiment. The model is a Transformer-GAN trained with labels that correspond to different configurations of the valence and arousal dimensions that quantitatively represent human affective states. We try to tackle both of the problems above by employing an efficient linear version of Attention and using a Discriminator both as a tool to improve the overall quality of the generated music and its ability to follow the conditioning signals.