 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
CycleDRUMS: Automatic Drum Arrangement For Bass Lines Using CycleGAN
Apr 09, 2021
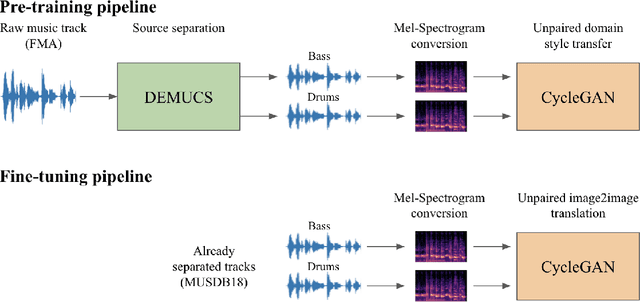
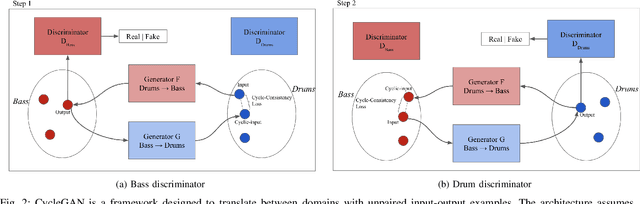
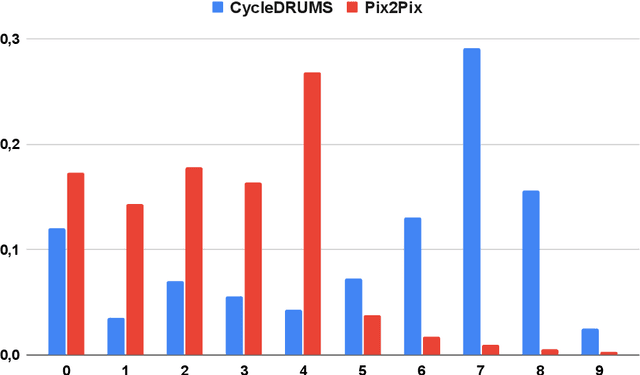
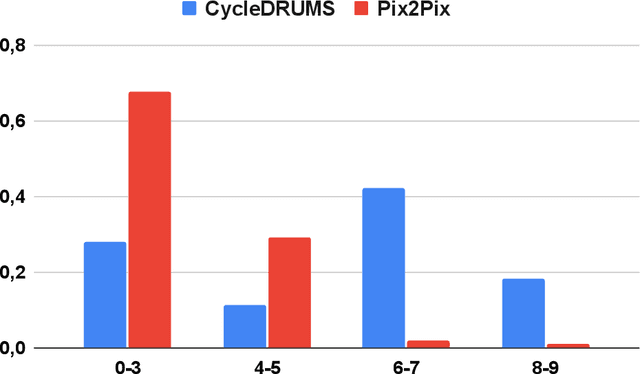
The two main research threads in computer-based music generation are: the construction of autonomous music-making systems, and the design of computer-based environments to assist musicians. In the symbolic domain, the key problem of automatically arranging a piece music was extensively studied, while relatively fewer systems tackled this challenge in the audio domain. In this contribution, we propose CycleDRUMS, a novel method for generating drums given a bass line. After converting the waveform of the bass into a mel-spectrogram, we are able to automatically generate original drums that follow the beat, sound credible and can be directly mixed with the input bass. We formulated this task as an unpaired image-to-image translation problem, and we addressed it with CycleGAN, a well-established unsupervised style transfer framework, originally designed for treating images. The choice to deploy raw audio and mel-spectrograms enabled us to better represent how humans perceive music, and to potentially draw sounds for new arrangements from the vast collection of music recordings accumulated in the last century. In absence of an objective way of evaluating the output of both generative adversarial networks and music generative systems, we further defined a possible metric for the proposed task, partially based on human (and expert) judgement. Finally, as a comparison, we replicated our results with Pix2Pix, a paired image-to-image translation network, and we showed that our approach outperforms it.
Dance Generation with Style Embedding: Learning and Transferring Latent Representations of Dance Styles
Apr 30, 2021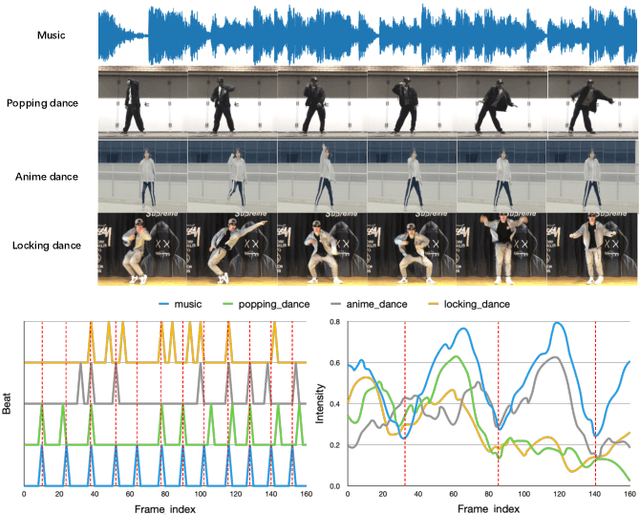
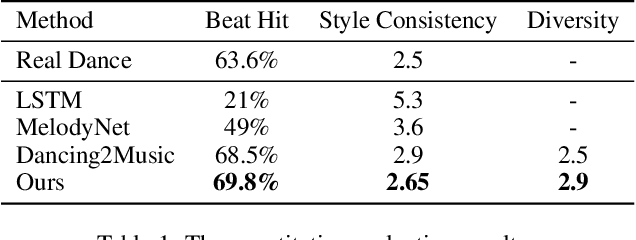
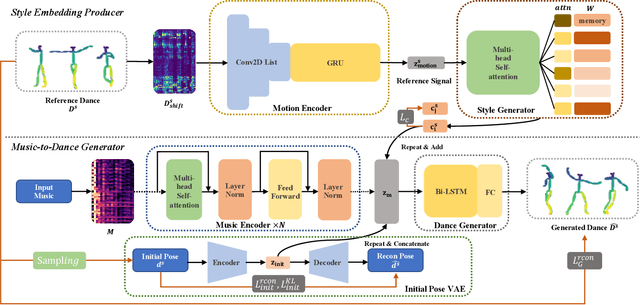
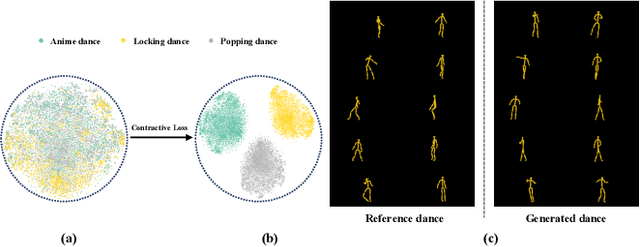
Choreography refers to creation of dance steps and motions for dances according to the latent knowledge in human mind, where the created dance motions are in general style-specific and consistent. So far, such latent style-specific knowledge about dance styles cannot be represented explicitly in human language and has not yet been learned in previous works on music-to-dance generation tasks. In this paper, we propose a novel music-to-dance synthesis framework with controllable style embeddings. These embeddings are learned representations of style-consistent kinematic abstraction of reference dance clips, which act as controllable factors to impose style constraints on dance generation in a latent manner. Thus, the dance styles can be transferred to dance motions by merely modifying the style embeddings. To support this study, we build a large music-to-dance dataset. The qualitative and quantitative evaluations demonstrate the advantage of our proposed framework, as well as the ability of synthesizing diverse styles of dances from identical music via style embeddings.
Karaoker: Alignment-free singing voice synthesis with speech training data
Apr 08, 2022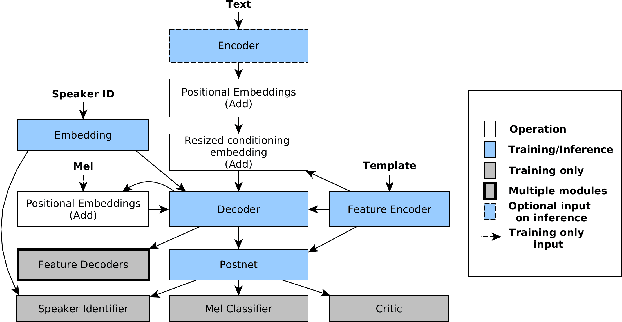
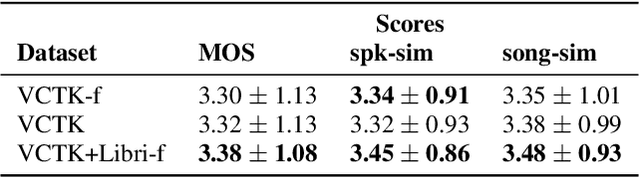
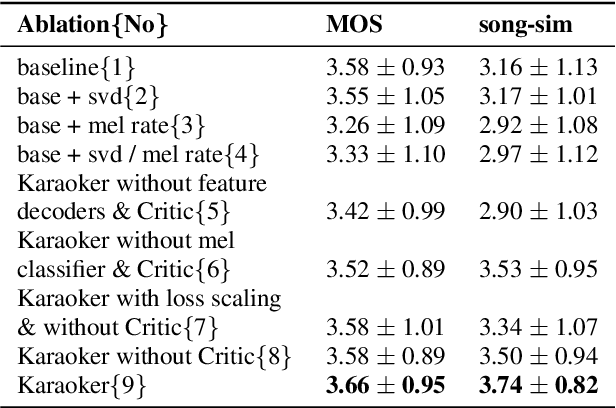
Existing singing voice synthesis models (SVS) are usually trained on singing data and depend on either error-prone time-alignment and duration features or explicit music score information. In this paper, we propose Karaoker, a multispeaker Tacotron-based model conditioned on voice characteristic features that is trained exclusively on spoken data without requiring time-alignments. Karaoker synthesizes singing voice following a multi-dimensional template extracted from a source waveform of an unseen speaker/singer. The model is jointly conditioned with a single deep convolutional encoder on continuous data including pitch, intensity, harmonicity, formants, cepstral peak prominence and octaves. We extend the text-to-speech training objective with feature reconstruction, classification and speaker identification tasks that guide the model to an accurate result. Except for multi-tasking, we also employ a Wasserstein GAN training scheme as well as new losses on the acoustic model's output to further refine the quality of the model.
An End-to-End Neural Network for Polyphonic Piano Music Transcription
Feb 11, 2016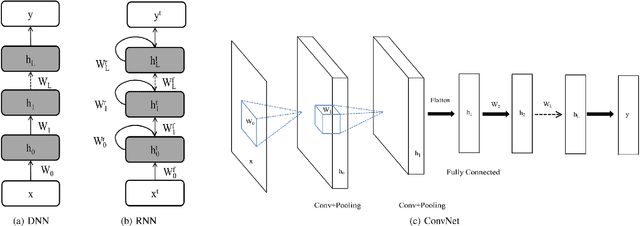
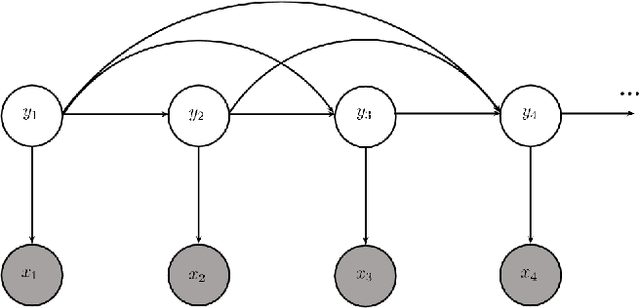

We present a supervised neural network model for polyphonic piano music transcription. The architecture of the proposed model is analogous to speech recognition systems and comprises an acoustic model and a music language model. The acoustic model is a neural network used for estimating the probabilities of pitches in a frame of audio. The language model is a recurrent neural network that models the correlations between pitch combinations over time. The proposed model is general and can be used to transcribe polyphonic music without imposing any constraints on the polyphony. The acoustic and language model predictions are combined using a probabilistic graphical model. Inference over the output variables is performed using the beam search algorithm. We perform two sets of experiments. We investigate various neural network architectures for the acoustic models and also investigate the effect of combining acoustic and music language model predictions using the proposed architecture. We compare performance of the neural network based acoustic models with two popular unsupervised acoustic models. Results show that convolutional neural network acoustic models yields the best performance across all evaluation metrics. We also observe improved performance with the application of the music language models. Finally, we present an efficient variant of beam search that improves performance and reduces run-times by an order of magnitude, making the model suitable for real-time applications.
Nearly optimal resolution estimate for the two-dimensional super-resolution and a new algorithm for direction of arrival estimation with uniform rectangular array
May 14, 2022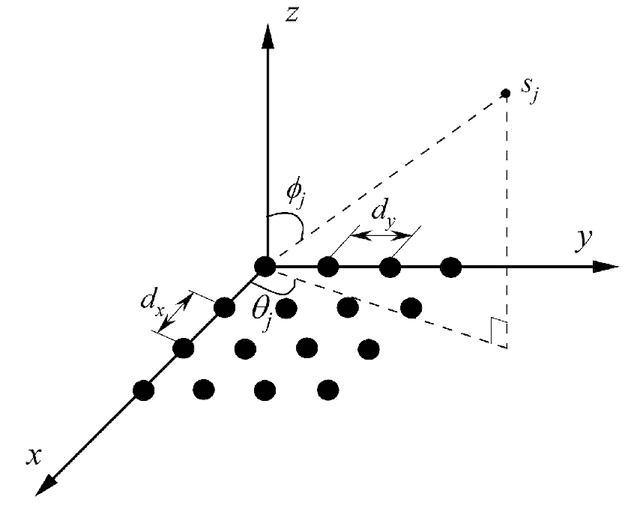
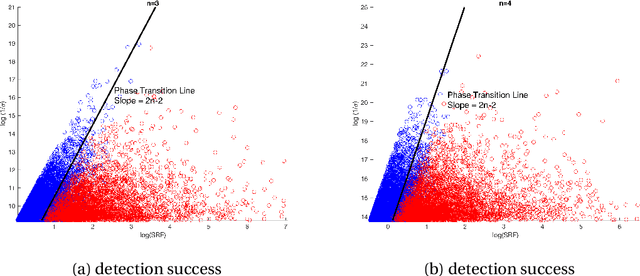
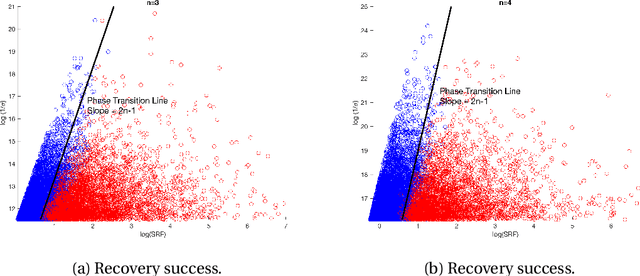
In this paper, we develop a new technique to obtain nearly optimal estimates of the computational resolution limits introduced in Appl. Comput. Harmon. Anal. 56 (2022) 402-446; IEEE Trans. Inf. Theory 67(7) (2021) 4812-4827; Inverse Probl. 37(10) (2021) 104001 for two-dimensional super-resolution problems. Our main contributions are fivefold: (i) Our work improves the resolution estimate for number detection and location recovery in two-dimensional super-resolution problems to nearly optimal; (ii) As a consequence, we derive a stability result for a sparsity-promoting algorithm in two-dimensional super-resolution problems (or Direction of Arrival problems (DOA)). The stability result exhibits the optimal performance of sparsity promoting in solving such problems; (iii) Our techniques pave the way for improving the estimate for resolution limits in higher-dimensional super-resolutions to nearly optimal; (iv) Inspired by these new techniques, we propose a new coordinate-combination-based model order detection algorithm for two-dimensional DOA estimation and theoretically demonstrate its optimal performance, and (v) we also propose a new coordinate-combination-based MUSIC algorithm for super-resolving sources in two-dimensional DOA estimation. It has excellent performance and enjoys many advantages compared to the conventional DOA algorithms. The coordinate-combination idea seems to be a promising way for multi-dimensional DOA estimation.
DJ-MC: A Reinforcement-Learning Agent for Music Playlist Recommendation
Mar 25, 2015

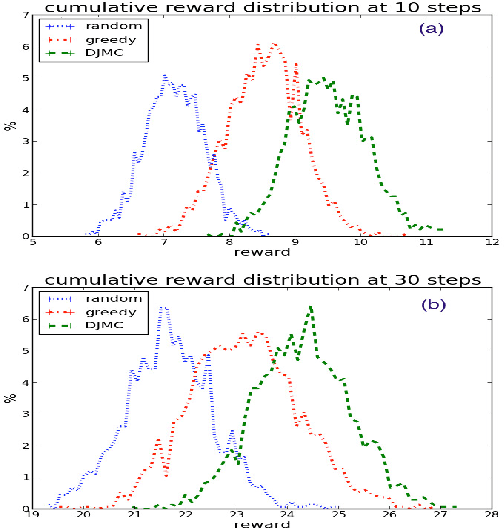
In recent years, there has been growing focus on the study of automated recommender systems. Music recommendation systems serve as a prominent domain for such works, both from an academic and a commercial perspective. A fundamental aspect of music perception is that music is experienced in temporal context and in sequence. In this work we present DJ-MC, a novel reinforcement-learning framework for music recommendation that does not recommend songs individually but rather song sequences, or playlists, based on a model of preferences for both songs and song transitions. The model is learned online and is uniquely adapted for each listener. To reduce exploration time, DJ-MC exploits user feedback to initialize a model, which it subsequently updates by reinforcement. We evaluate our framework with human participants using both real song and playlist data. Our results indicate that DJ-MC's ability to recommend sequences of songs provides a significant improvement over more straightforward approaches, which do not take transitions into account.
NONOTO: A Model-agnostic Web Interface for Interactive Music Composition by Inpainting
Jul 23, 2019
Inpainting-based generative modeling allows for stimulating human-machine interactions by letting users perform stylistically coherent local editions to an object using a statistical model. We present NONOTO, a new interface for interactive music generation based on inpainting models. It is aimed both at researchers, by offering a simple and flexible API allowing them to connect their own models with the interface, and at musicians by providing industry-standard features such as audio playback, real-time MIDI output and straightforward synchronization with DAWs using Ableton Link.
Proceedings of the First International Workshop on Deep Learning and Music
Jun 27, 2017Proceedings of the First International Workshop on Deep Learning and Music, joint with IJCNN, Anchorage, US, May 17-18, 2017
A quantum Fourier transform (QFT) based note detection algorithm
Apr 30, 2022
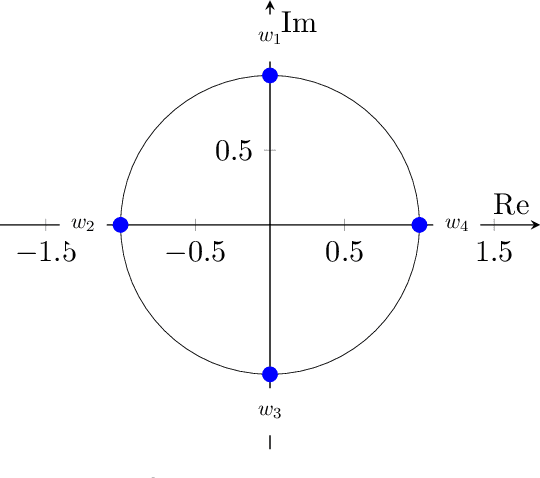
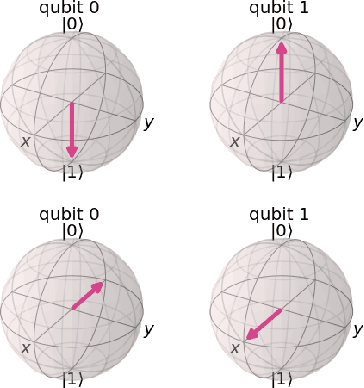

In quantum information processing (QIP), the quantum Fourier transform (QFT) has a plethora of applications [1] [2] [3]: Shor's algorithm and phase estimation are just a few well-known examples. Shor's quantum factorization algorithm, one of the most widely quoted quantum algorithms [4] [5] [6] relies heavily on the QFT and efficiently finds integer prime factors of large numbers on quantum computers [4]. This seminal ground-breaking design for quantum algorithms has triggered a cascade of viable alternatives to previously unsolvable problems on a classical computer that are potentially superior and can run in polynomial time. In this work we examine the QFT's structure and implementation for the creation of a quantum music note detection algorithm both on a simulated and a real quantum computer. Though formal approaches [7] [1] [8] [9] exist for the verification of quantum algorithms, in this study we limit ourselves to a simpler, symbolic representation which we validate using the symbolic SymPy [10] [11] package which symbolically replicates quantum computing processes. The algorithm is then implemented as a quantum circuit, using IBM's qiskit [12] library and finally period detection is exemplified on an actual single musical tone using a varying number of qubits.