 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaraoker: Alignment-free singing voice synthesis with speech training data
Paper and Code
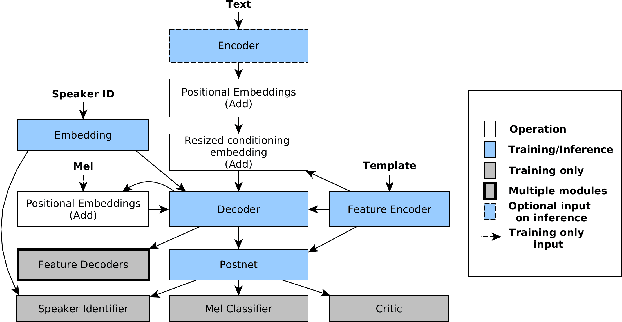
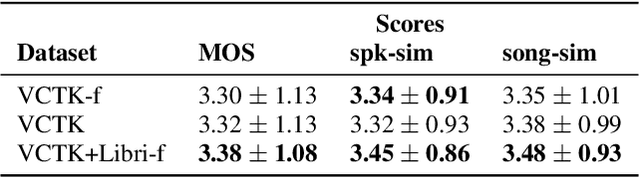
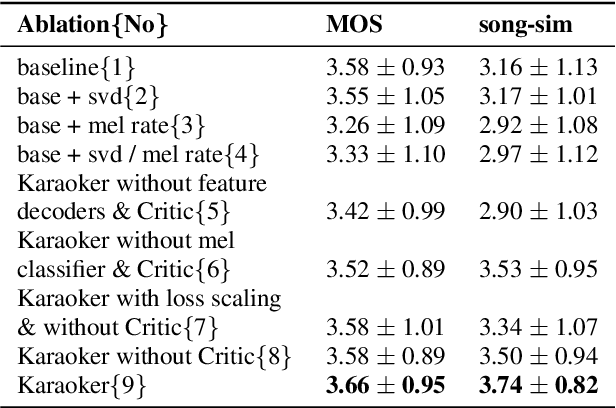
Existing singing voice synthesis models (SVS) are usually trained on singing data and depend on either error-prone time-alignment and duration features or explicit music score information. In this paper, we propose Karaoker, a multispeaker Tacotron-based model conditioned on voice characteristic features that is trained exclusively on spoken data without requiring time-alignments. Karaoker synthesizes singing voice following a multi-dimensional template extracted from a source waveform of an unseen speaker/singer. The model is jointly conditioned with a single deep convolutional encoder on continuous data including pitch, intensity, harmonicity, formants, cepstral peak prominence and octaves. We extend the text-to-speech training objective with feature reconstruction, classification and speaker identification tasks that guide the model to an accurate result. Except for multi-tasking, we also employ a Wasserstein GAN training scheme as well as new losses on the acoustic model's output to further refine the quality of the model.