 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
The Impact of Label Noise on a Music Tagger
Aug 14, 2020
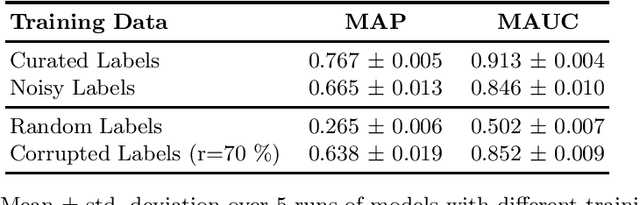
We explore how much can be learned from noisy labels in audio music tagging. Our experiments show that carefully annotated labels result in highest figures of merit, but even high amounts of noisy labels contain enough information for successful learning. Artificial corruption of curated data allows us to quantize this contribution of noisy labels.
Polyphonic Music Composition with LSTM Neural Networks and Reinforcement Learning
Feb 05, 2019
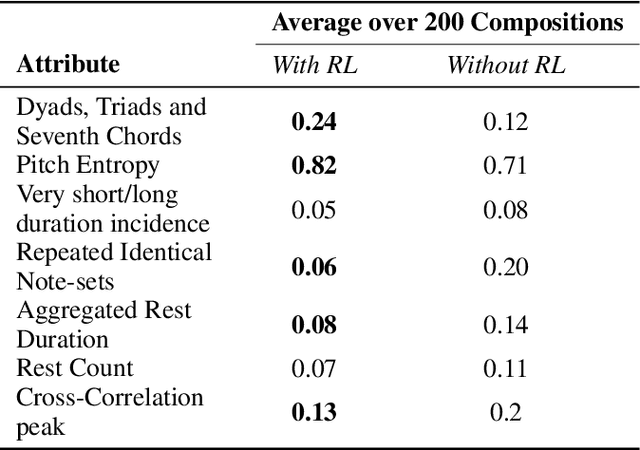

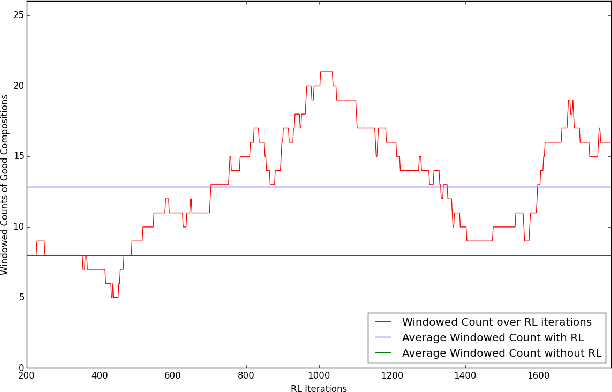
In the domain of algorithmic music composition, machine learning-driven systems eliminate the need for carefully hand-crafting rules for composition. In particular, the capability of recurrent neural networks to learn complex temporal patterns lends itself well to the musical domain. Promising results have been observed across a number of recent attempts at music composition using deep RNNs. These approaches generally aim at first training neural networks to reproduce subsequences drawn from existing songs. Subsequently, they are used to compose music either at the audio sample-level or at the note-level. We designed a representation that divides polyphonic music into a small number of monophonic streams. This representation greatly reduces the complexity of the problem and eliminates an exponential number of probably poor compositions. On top of our LSTM neural network that learnt musical sequences in this representation, we built an RL agent that learnt to find combinations of songs whose joint dominance produced pleasant compositions. We present \textbf{Amadeus}, an algorithmic music composition system that composes music that consists of intricate melodies, basic chords, and even occasional contrapuntal sequences.
Unsupervised denoising for sparse multi-spectral computed tomography
Nov 02, 2022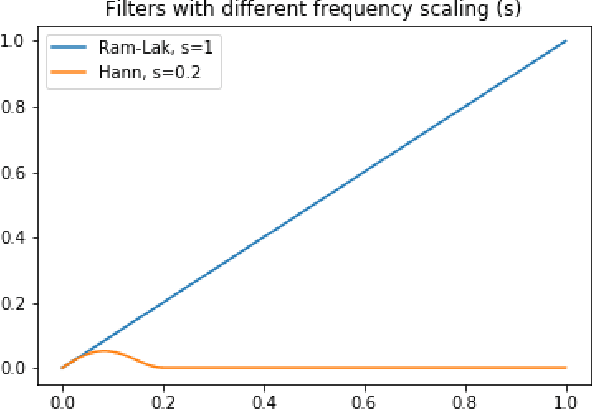

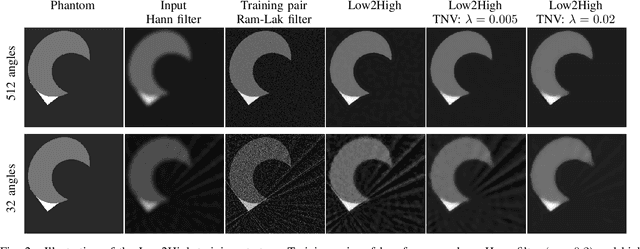
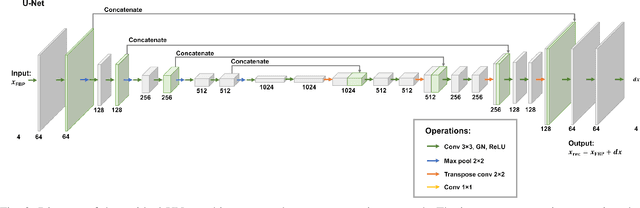
Multi-energy computed tomography (CT) with photon counting detectors (PCDs) enables spectral imaging as PCDs can assign the incoming photons to specific energy channels. However, PCDs with many spectral channels drastically increase the computational complexity of the CT reconstruction, and bespoke reconstruction algorithms need fine-tuning to varying noise statistics. \rev{Especially if many projections are taken, a large amount of data has to be collected and stored. Sparse view CT is one solution for data reduction. However, these issues are especially exacerbated when sparse imaging scenarios are encountered due to a significant reduction in photon counts.} In this work, we investigate the suitability of learning-based improvements to the challenging task of obtaining high-quality reconstructions from sparse measurements for a 64-channel PCD-CT. In particular, to overcome missing reference data for the training procedure, we propose an unsupervised denoising and artefact removal approach by exploiting different filter functions in the reconstruction and an explicit coupling of spectral channels with the nuclear norm. Performance is assessed on both simulated synthetic data and the openly available experimental Multi-Spectral Imaging via Computed Tomography (MUSIC) dataset. We compared the quality of our unsupervised method to iterative total nuclear variation regularized reconstructions and a supervised denoiser trained with reference data. We show that improved reconstruction quality can be achieved with flexibility on noise statistics and effective suppression of streaking artefacts when using unsupervised denoising with spectral coupling.
Jointist: Joint Learning for Multi-instrument Transcription and Its Applications
Jun 28, 2022
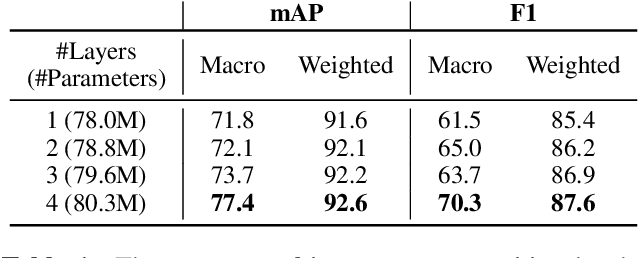
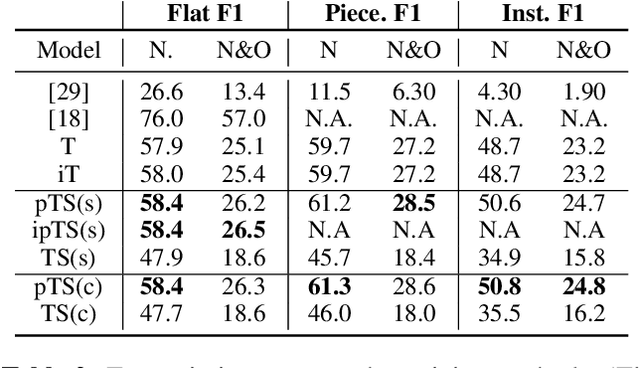
In this paper, we introduce Jointist, an instrument-aware multi-instrument framework that is capable of transcribing, recognizing, and separating multiple musical instruments from an audio clip. Jointist consists of the instrument recognition module that conditions the other modules: the transcription module that outputs instrument-specific piano rolls, and the source separation module that utilizes instrument information and transcription results. The instrument conditioning is designed for an explicit multi-instrument functionality while the connection between the transcription and source separation modules is for better transcription performance. Our challenging problem formulation makes the model highly useful in the real world given that modern popular music typically consists of multiple instruments. However, its novelty necessitates a new perspective on how to evaluate such a model. During the experiment, we assess the model from various aspects, providing a new evaluation perspective for multi-instrument transcription. We also argue that transcription models can be utilized as a preprocessing module for other music analysis tasks. In the experiment on several downstream tasks, the symbolic representation provided by our transcription model turned out to be helpful to spectrograms in solving downbeat detection, chord recognition, and key estimation.
Adversarial Learning for Improved Onsets and Frames Music Transcription
Jun 20, 2019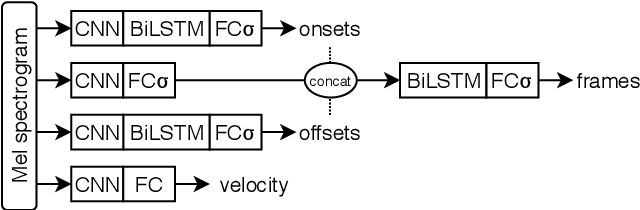
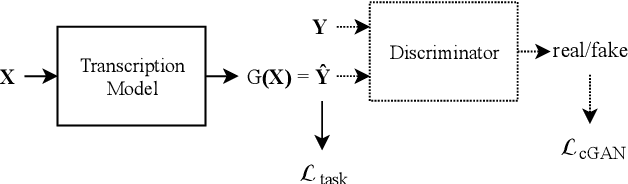
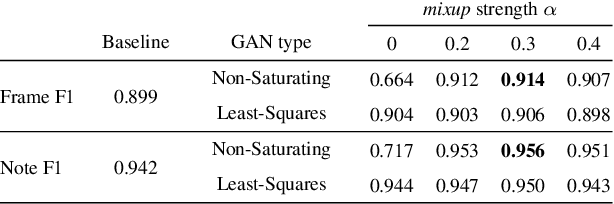
Automatic music transcription is considered to be one of the hardest problems in music information retrieval, yet recent deep learning approaches have achieved substantial improvements on transcription performance. These approaches commonly employ supervised learning models that predict various time-frequency representations, by minimizing element-wise losses such as the cross entropy function. However, applying the loss in this manner assumes conditional independence of each label given the input, and thus cannot accurately express inter-label dependencies. To address this issue, we introduce an adversarial training scheme that operates directly on the time-frequency representations and makes the output distribution closer to the ground-truth. Through adversarial learning, we achieve a consistent improvement in both frame-level and note-level metrics over Onsets and Frames, a state-of-the-art music transcription model. Our results show that adversarial learning can significantly reduce the error rate while increasing the confidence of the model estimations. Our approach is generic and applicable to any transcription model based on multi-label predictions, which are very common in music signal analysis.
Recommending Podcasts for Cold-Start Users Based on Music Listening and Taste
Jul 27, 2020
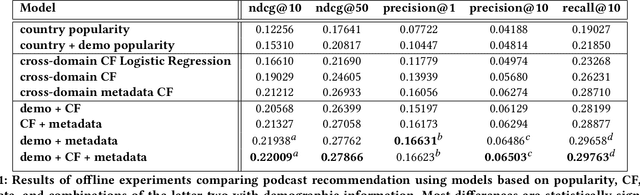
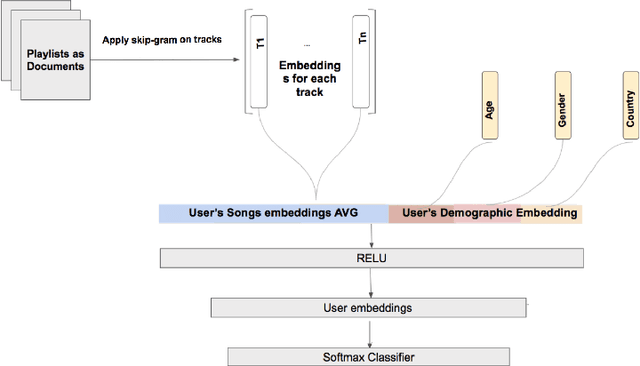
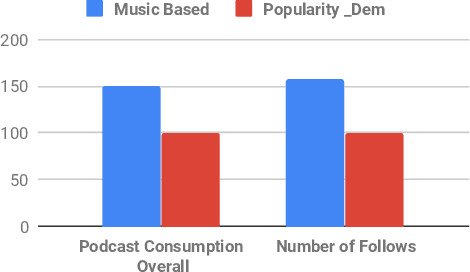
Recommender systems are increasingly used to predict and serve content that aligns with user taste, yet the task of matching new users with relevant content remains a challenge. We consider podcasting to be an emerging medium with rapid growth in adoption, and discuss challenges that arise when applying traditional recommendation approaches to address the cold-start problem. Using music consumption behavior, we examine two main techniques in inferring Spotify users preferences over more than 200k podcasts. Our results show significant improvements in consumption of up to 50\% for both offline and online experiments. We provide extensive analysis on model performance and examine the degree to which music data as an input source introduces bias in recommendations.
Deep Learning for Music
Jun 15, 2016


Our goal is to be able to build a generative model from a deep neural network architecture to try to create music that has both harmony and melody and is passable as music composed by humans. Previous work in music generation has mainly been focused on creating a single melody. More recent work on polyphonic music modeling, centered around time series probability density estimation, has met some partial success. In particular, there has been a lot of work based off of Recurrent Neural Networks combined with Restricted Boltzmann Machines (RNN-RBM) and other similar recurrent energy based models. Our approach, however, is to perform end-to-end learning and generation with deep neural nets alone.
Decoupling Magnitude and Phase Estimation with Deep ResUNet for Music Source Separation
Sep 12, 2021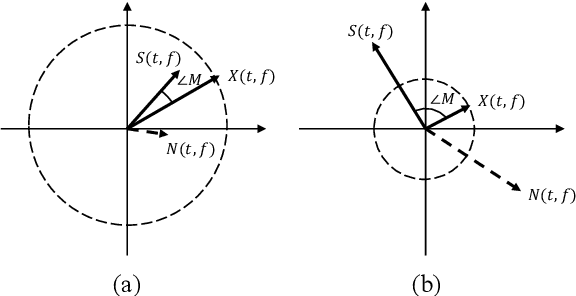
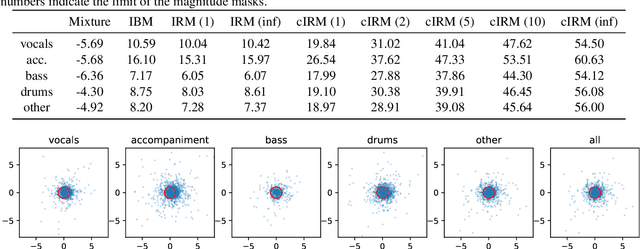
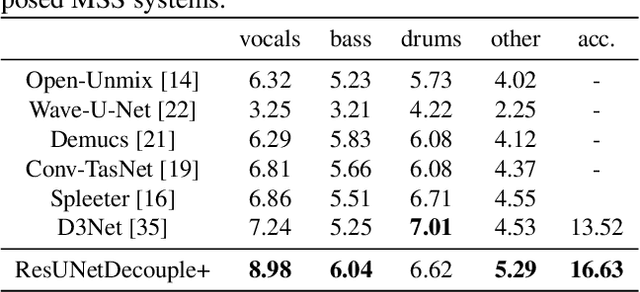
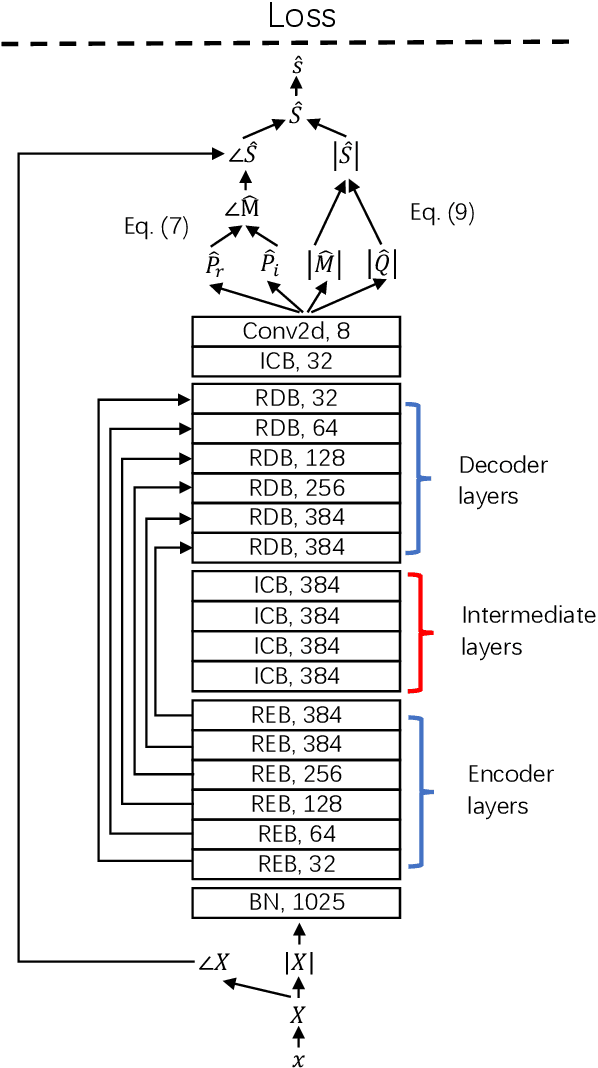
Deep neural network based methods have been successfully applied to music source separation. They typically learn a mapping from a mixture spectrogram to a set of source spectrograms, all with magnitudes only. This approach has several limitations: 1) its incorrect phase reconstruction degrades the performance, 2) it limits the magnitude of masks between 0 and 1 while we observe that 22% of time-frequency bins have ideal ratio mask values of over~1 in a popular dataset, MUSDB18, 3) its potential on very deep architectures is under-explored. Our proposed system is designed to overcome these. First, we propose to estimate phases by estimating complex ideal ratio masks (cIRMs) where we decouple the estimation of cIRMs into magnitude and phase estimations. Second, we extend the separation method to effectively allow the magnitude of the mask to be larger than 1. Finally, we propose a residual UNet architecture with up to 143 layers. Our proposed system achieves a state-of-the-art MSS result on the MUSDB18 dataset, especially, a SDR of 8.98~dB on vocals, outperforming the previous best performance of 7.24~dB. The source code is available at: https://github.com/bytedance/music_source_separation
* 6 pages
Voice and accompaniment separation in music using self-attention convolutional neural network
Mar 19, 2020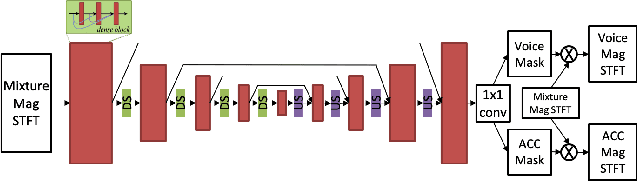
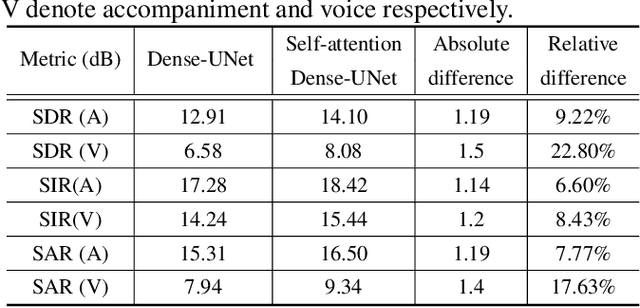
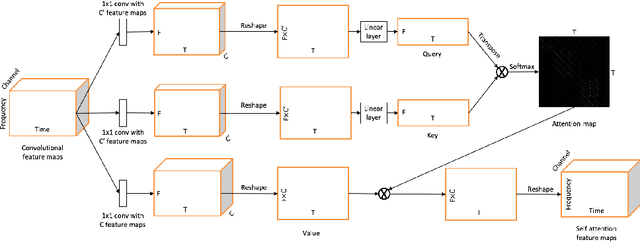
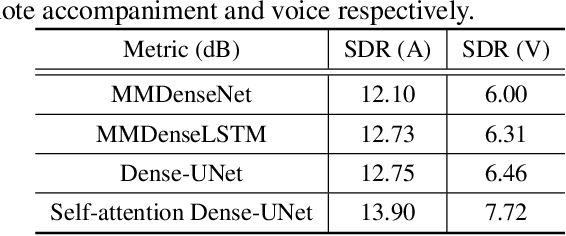
Music source separation has been a popular topic in signal processing for decades, not only because of its technical difficulty, but also due to its importance to many commercial applications, such as automatic karoake and remixing. In this work, we propose a novel self-attention network to separate voice and accompaniment in music. First, a convolutional neural network (CNN) with densely-connected CNN blocks is built as our base network. We then insert self-attention subnets at different levels of the base CNN to make use of the long-term intra-dependency of music, i.e., repetition. Within self-attention subnets, repetitions of the same musical patterns inform reconstruction of other repetitions, for better source separation performance. Results show the proposed method leads to 19.5% relative improvement in vocals separation in terms of SDR. We compare our methods with state-of-the-art systems i.e. MMDenseNet and MMDenseLSTM.
deepsing: Generating Sentiment-aware Visual Stories using Cross-modal Music Translation
Dec 11, 2019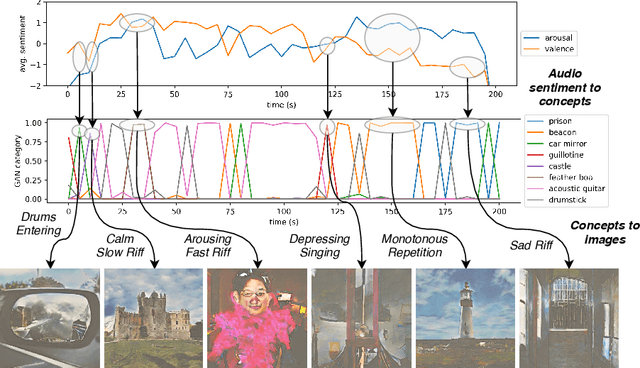

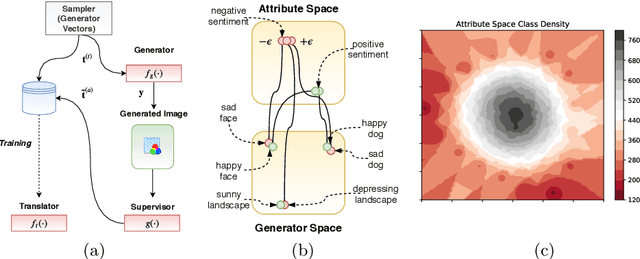
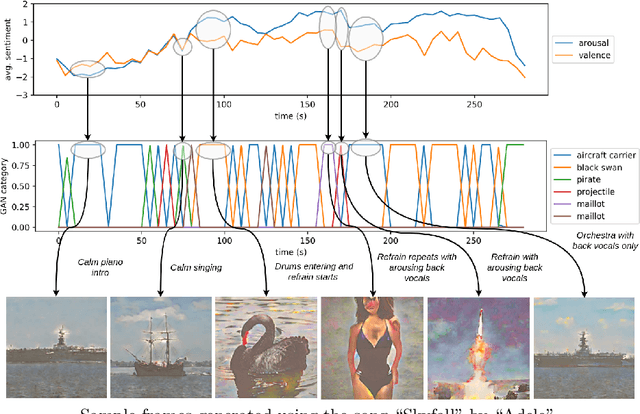
In this paper we propose a deep learning method for performing attributed-based music-to-image translation. The proposed method is applied for synthesizing visual stories according to the sentiment expressed by songs. The generated images aim to induce the same feelings to the viewers, as the original song does, reinforcing the primary aim of music, i.e., communicating feelings. The process of music-to-image translation poses unique challenges, mainly due to the unstable mapping between the different modalities involved in this process. In this paper, we employ a trainable cross-modal translation method to overcome this limitation, leading to the first, to the best of our knowledge, deep learning method for generating sentiment-aware visual stories. Various aspects of the proposed method are extensively evaluated and discussed using different songs.