 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice and accompaniment separation in music using self-attention convolutional neural network
Paper and Code
Mar 19, 2020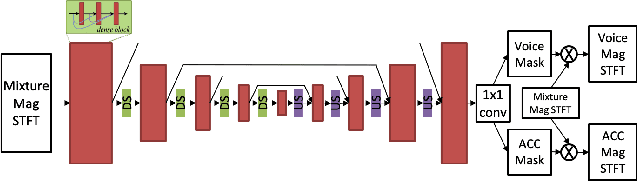
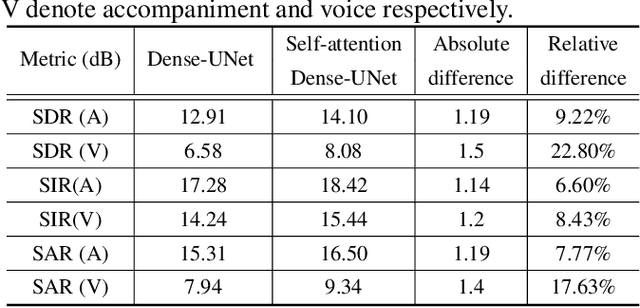
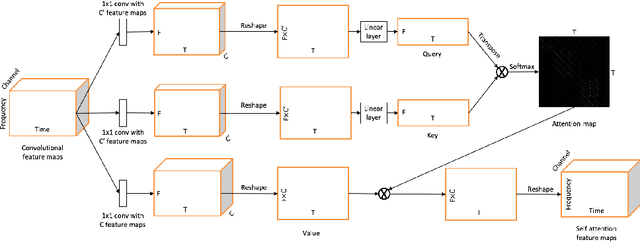
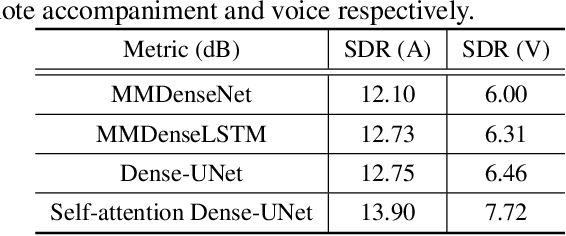
Music source separation has been a popular topic in signal processing for decades, not only because of its technical difficulty, but also due to its importance to many commercial applications, such as automatic karoake and remixing. In this work, we propose a novel self-attention network to separate voice and accompaniment in music. First, a convolutional neural network (CNN) with densely-connected CNN blocks is built as our base network. We then insert self-attention subnets at different levels of the base CNN to make use of the long-term intra-dependency of music, i.e., repetition. Within self-attention subnets, repetitions of the same musical patterns inform reconstruction of other repetitions, for better source separation performance. Results show the proposed method leads to 19.5% relative improvement in vocals separation in terms of SDR. We compare our methods with state-of-the-art systems i.e. MMDenseNet and MMDenseLSTM.