 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Blind Face Restoration for Under-Display Camera via Dictionary Guided Transformer
Aug 20, 2023



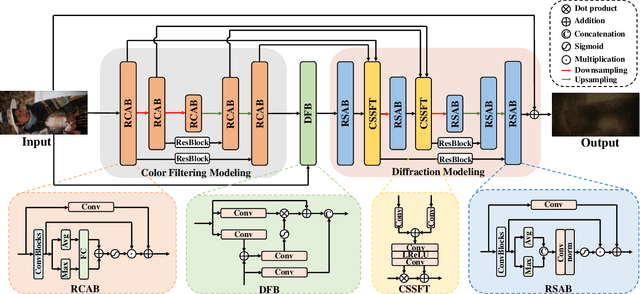
By hiding the front-facing camera below the display panel, Under-Display Camera (UDC) provides users with a full-screen experience. However, due to the characteristics of the display, images taken by UDC suffer from significant quality degradation. Methods have been proposed to tackle UDC image restoration and advances have been achieved. There are still no specialized methods and datasets for restoring UDC face images, which may be the most common problem in the UDC scene. To this end, considering color filtering, brightness attenuation, and diffraction in the imaging process of UDC, we propose a two-stage network UDC Degradation Model Network named UDC-DMNet to synthesize UDC images by modeling the processes of UDC imaging. Then we use UDC-DMNet and high-quality face images from FFHQ and CelebA-Test to create UDC face training datasets FFHQ-P/T and testing datasets CelebA-Test-P/T for UDC face restoration. We propose a novel dictionary-guided transformer network named DGFormer. Introducing the facial component dictionary and the characteristics of the UDC image in the restoration makes DGFormer capable of addressing blind face restoration in UDC scenarios. Experiments show that our DGFormer and UDC-DMNet achieve state-of-the-art performance.
SAPIEN: Affective Virtual Agents Powered by Large Language Models
Aug 06, 2023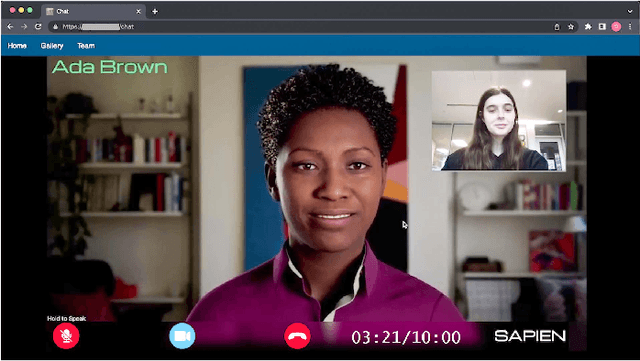
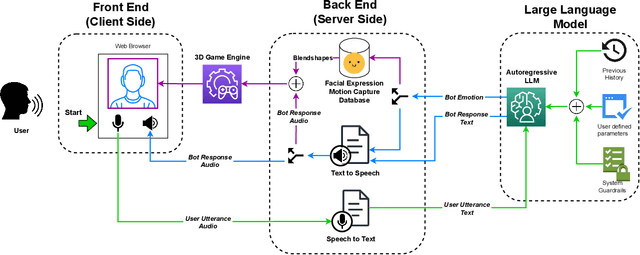
In this demo paper, we introduce SAPIEN, a platform for high-fidelity virtual agents driven by large language models that can hold open domain conversations with users in 13 different languages, and display emotions through facial expressions and voice. The platform allows users to customize their virtual agent's personality, background, and conversation premise, thus providing a rich, immersive interaction experience. Furthermore, after the virtual meeting, the user can choose to get the conversation analyzed and receive actionable feedback on their communication skills. This paper illustrates an overview of the platform and discusses the various application domains of this technology, ranging from entertainment to mental health, communication training, language learning, education, healthcare, and beyond. Additionally, we consider the ethical implications of such realistic virtual agent representations and the potential challenges in ensuring responsible use.
Improving 2D face recognition via fine-level facial depth generation and RGB-D complementary feature learning
May 08, 2023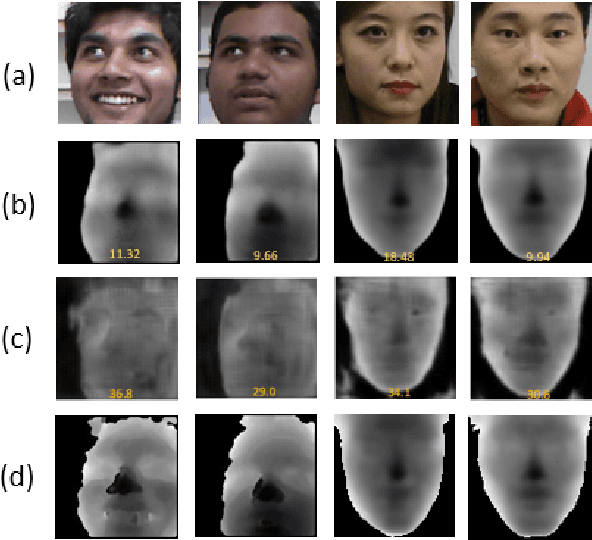


Face recognition in complex scenes suffers severe challenges coming from perturbations such as pose deformation, ill illumination, partial occlusion. Some methods utilize depth estimation to obtain depth corresponding to RGB to improve the accuracy of face recognition. However, the depth generated by them suffer from image blur, which introduces noise in subsequent RGB-D face recognition tasks. In addition, existing RGB-D face recognition methods are unable to fully extract complementary features. In this paper, we propose a fine-grained facial depth generation network and an improved multimodal complementary feature learning network. Extensive experiments on the Lock3DFace dataset and the IIIT-D dataset show that the proposed FFDGNet and I MCFLNet can improve the accuracy of RGB-D face recognition while achieving the state-of-the-art performance.
Face Encryption via Frequency-Restricted Identity-Agnostic Attacks
Aug 25, 2023
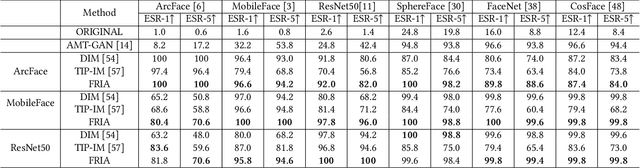
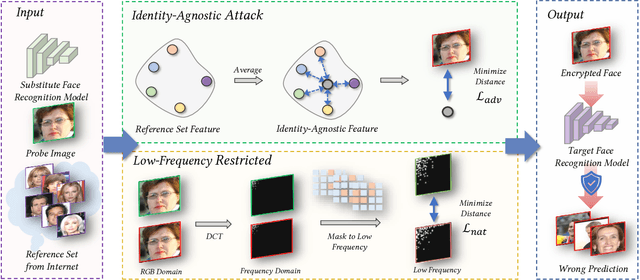
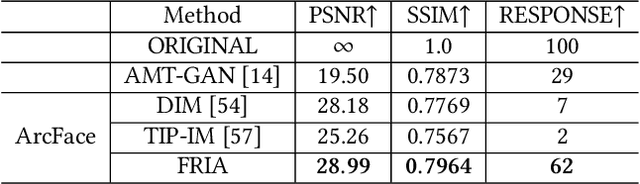
Billions of people are sharing their daily live images on social media everyday. However, malicious collectors use deep face recognition systems to easily steal their biometric information (e.g., faces) from these images. Some studies are being conducted to generate encrypted face photos using adversarial attacks by introducing imperceptible perturbations to reduce face information leakage. However, existing studies need stronger black-box scenario feasibility and more natural visual appearances, which challenge the feasibility of privacy protection. To address these problems, we propose a frequency-restricted identity-agnostic (FRIA) framework to encrypt face images from unauthorized face recognition without access to personal information. As for the weak black-box scenario feasibility, we obverse that representations of the average feature in multiple face recognition models are similar, thus we propose to utilize the average feature via the crawled dataset from the Internet as the target to guide the generation, which is also agnostic to identities of unknown face recognition systems; in nature, the low-frequency perturbations are more visually perceptible by the human vision system. Inspired by this, we restrict the perturbation in the low-frequency facial regions by discrete cosine transform to achieve the visual naturalness guarantee. Extensive experiments on several face recognition models demonstrate that our FRIA outperforms other state-of-the-art methods in generating more natural encrypted faces while attaining high black-box attack success rates of 96%. In addition, we validate the efficacy of FRIA using real-world black-box commercial API, which reveals the potential of FRIA in practice. Our codes can be found in https://github.com/XinDong10/FRIA.
DIFAI: Diverse Facial Inpainting using StyleGAN Inversion
Jan 20, 2023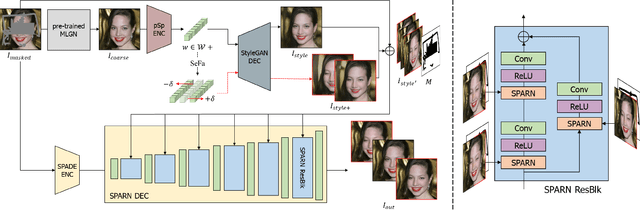
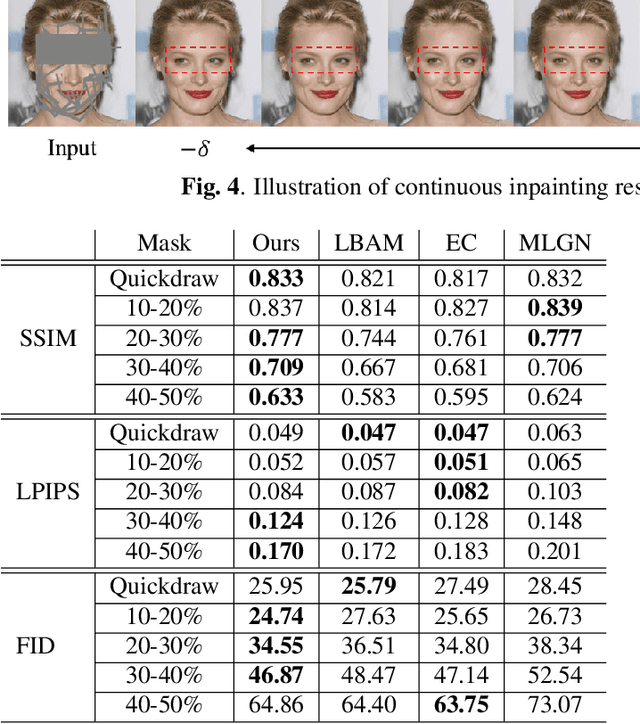

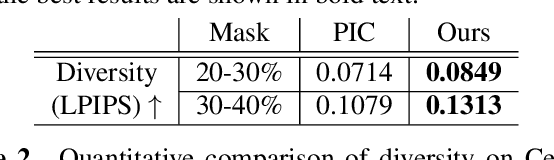
Image inpainting is an old problem in computer vision that restores occluded regions and completes damaged images. In the case of facial image inpainting, most of the methods generate only one result for each masked image, even though there are other reasonable possibilities. To prevent any potential biases and unnatural constraints stemming from generating only one image, we propose a novel framework for diverse facial inpainting exploiting the embedding space of StyleGAN. Our framework employs pSp encoder and SeFa algorithm to identify semantic components of the StyleGAN embeddings and feed them into our proposed SPARN decoder that adopts region normalization for plausible inpainting. We demonstrate that our proposed method outperforms several state-of-the-art methods.
Screening Autism Spectrum Disorder in childrens using Deep Learning Approach : Evaluating the classification model of YOLOv8 by comparing with other models
Jun 25, 2023
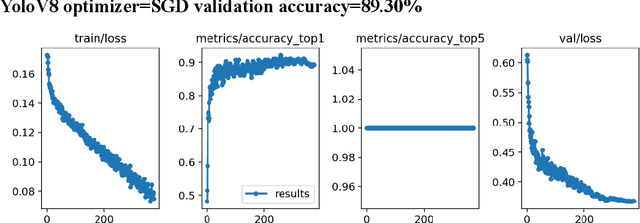
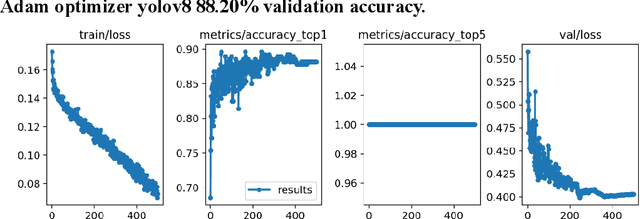
Autism spectrum disorder (ASD) is a developmental condition that presents significant challenges in social interaction, communication, and behavior. Early intervention plays a pivotal role in enhancing cognitive abilities and reducing autistic symptoms in children with ASD. Numerous clinical studies have highlighted distinctive facial characteristics that distinguish ASD children from typically developing (TD) children. In this study, we propose a practical solution for ASD screening using facial images using YoloV8 model. By employing YoloV8, a deep learning technique, on a dataset of Kaggle, we achieved exceptional results. Our model achieved a remarkable 89.64% accuracy in classification and an F1-score of 0.89. Our findings provide support for the clinical observations regarding facial feature discrepancies between children with ASD. The high F1-score obtained demonstrates the potential of deep learning models in screening children with ASD. We conclude that the newest version of YoloV8 which is usually used for object detection can be used for classification problem of Austistic and Non-autistic images.
Generation of artificial facial drug abuse images using Deep De-identified anonymous Dataset augmentation through Genetics Algorithm (3DG-GA)
Apr 12, 2023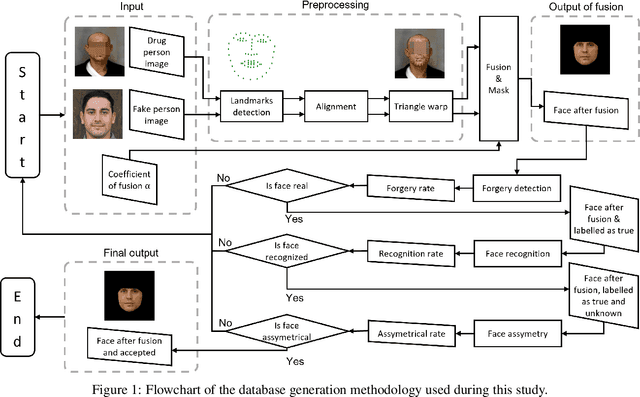


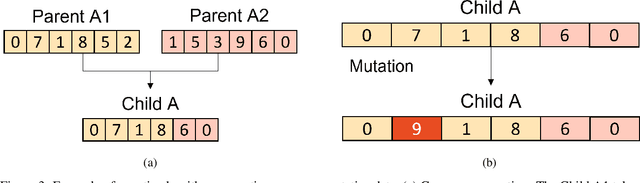
In biomedical research and artificial intelligence, access to large, well-balanced, and representative datasets is crucial for developing trustworthy applications that can be used in real-world scenarios. However, obtaining such datasets can be challenging, as they are often restricted to hospitals and specialized facilities. To address this issue, the study proposes to generate highly realistic synthetic faces exhibiting drug abuse traits through augmentation. The proposed method, called "3DG-GA", Deep De-identified anonymous Dataset Generation, uses Genetics Algorithm as a strategy for synthetic faces generation. The algorithm includes GAN artificial face generation, forgery detection, and face recognition. Initially, a dataset of 120 images of actual facial drug abuse is used. By preserving, the drug traits, the 3DG-GA provides a dataset containing 3000 synthetic facial drug abuse images. The dataset will be open to the scientific community, which can reproduce our results and benefit from the generated datasets while avoiding legal or ethical restrictions.
ADD: An Automatic Desensitization Fisheye Dataset for Autonomous Driving
Aug 15, 2023Autonomous driving systems require many images for analyzing the surrounding environment. However, there is fewer data protection for private information among these captured images, such as pedestrian faces or vehicle license plates, which has become a significant issue. In this paper, in response to the call for data security laws and regulations and based on the advantages of large Field of View(FoV) of the fisheye camera, we build the first Autopilot Desensitization Dataset, called ADD, and formulate the first deep-learning-based image desensitization framework, to promote the study of image desensitization in autonomous driving scenarios. The compiled dataset consists of 650K images, including different face and vehicle license plate information captured by the surround-view fisheye camera. It covers various autonomous driving scenarios, including diverse facial characteristics and license plate colors. Then, we propose an efficient multitask desensitization network called DesCenterNet as a benchmark on the ADD dataset, which can perform face and vehicle license plate detection and desensitization tasks. Based on ADD, we further provide an evaluation criterion for desensitization performance, and extensive comparison experiments have verified the effectiveness and superiority of our method on image desensitization.
Self-supervised Facial Action Unit Detection with Region and Relation Learning
Mar 10, 2023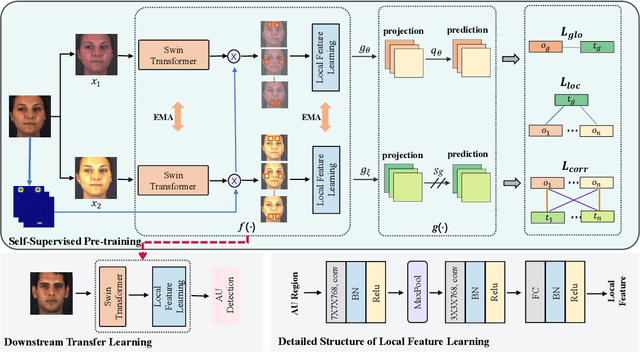
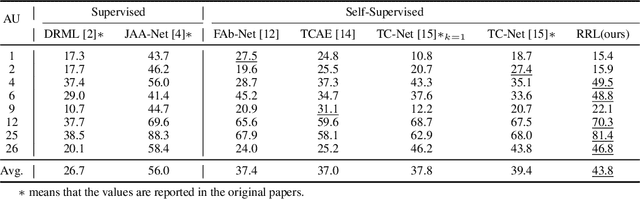
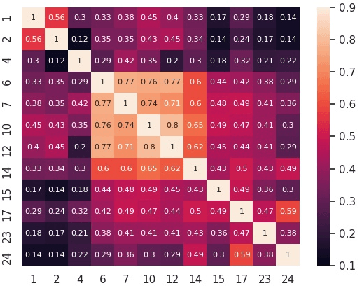
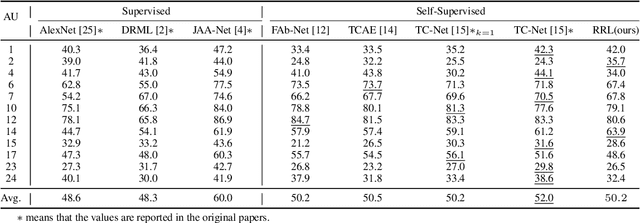
Facial action unit (AU) detection is a challenging task due to the scarcity of manual annotations. Recent works on AU detection with self-supervised learning have emerged to address this problem, aiming to learn meaningful AU representations from numerous unlabeled data. However, most existing AU detection works with self-supervised learning utilize global facial features only, while AU-related properties such as locality and relevance are not fully explored. In this paper, we propose a novel self-supervised framework for AU detection with the region and relation learning. In particular, AU related attention map is utilized to guide the model to focus more on AU-specific regions to enhance the integrity of AU local features. Meanwhile, an improved Optimal Transport (OT) algorithm is introduced to exploit the correlation characteristics among AUs. In addition, Swin Transformer is exploited to model the long-distance dependencies within each AU region during feature learning. The evaluation results on BP4D and DISFA demonstrate that our proposed method is comparable or even superior to the state-of-the-art self-supervised learning methods and supervised AU detection methods.