 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Fast Localization of Facial Landmark Points
Jan 20, 2015
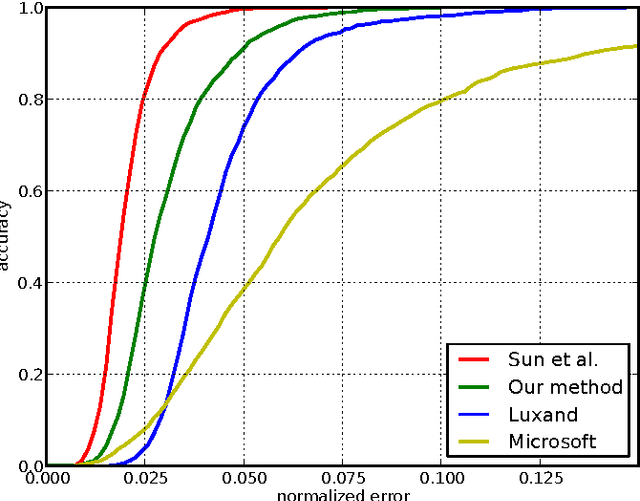
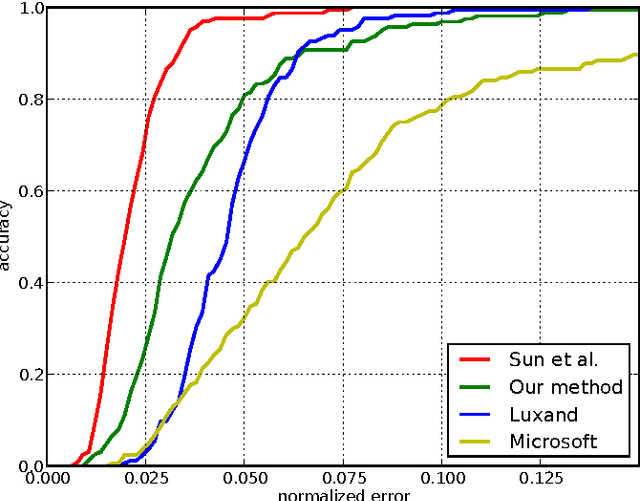
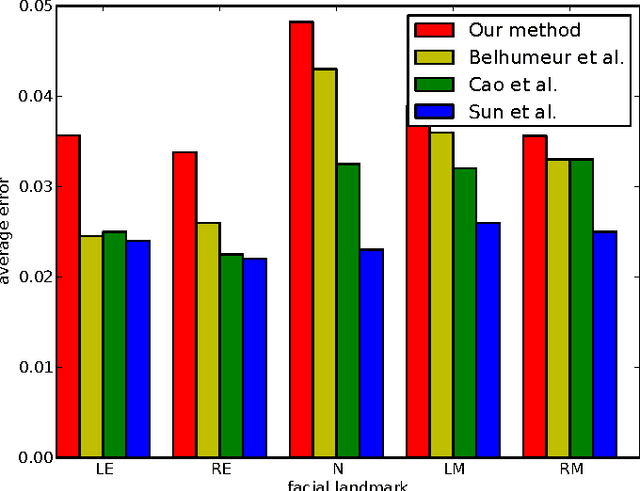
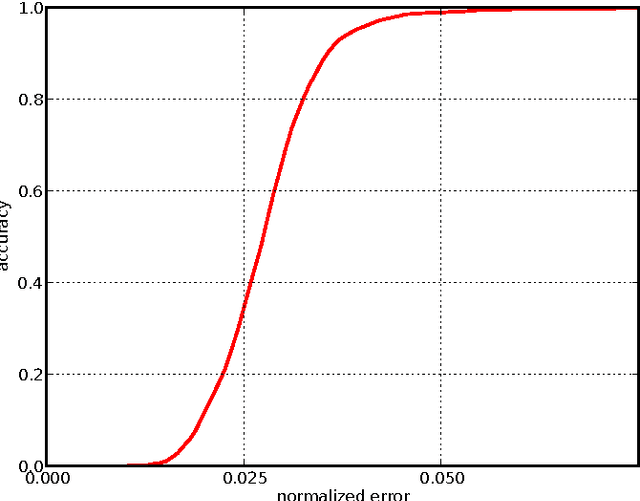
Localization of salient facial landmark points, such as eye corners or the tip of the nose, is still considered a challenging computer vision problem despite recent efforts. This is especially evident in unconstrained environments, i.e., in the presence of background clutter and large head pose variations. Most methods that achieve state-of-the-art accuracy are slow, and, thus, have limited applications. We describe a method that can accurately estimate the positions of relevant facial landmarks in real-time even on hardware with limited processing power, such as mobile devices. This is achieved with a sequence of estimators based on ensembles of regression trees. The trees use simple pixel intensity comparisons in their internal nodes and this makes them able to process image regions very fast. We test the developed system on several publicly available datasets and analyse its processing speed on various devices. Experimental results show that our method has practical value.
Advancing an Interdisciplinary Science of Conversation: Insights from a Large Multimodal Corpus of Human Speech
Mar 01, 2022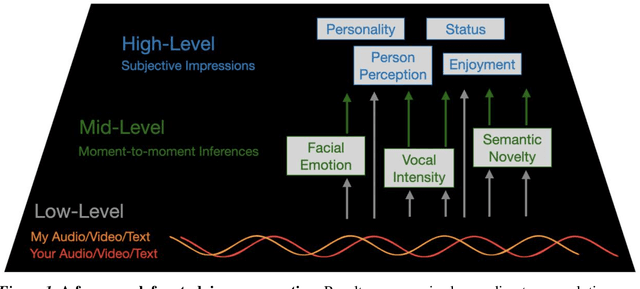
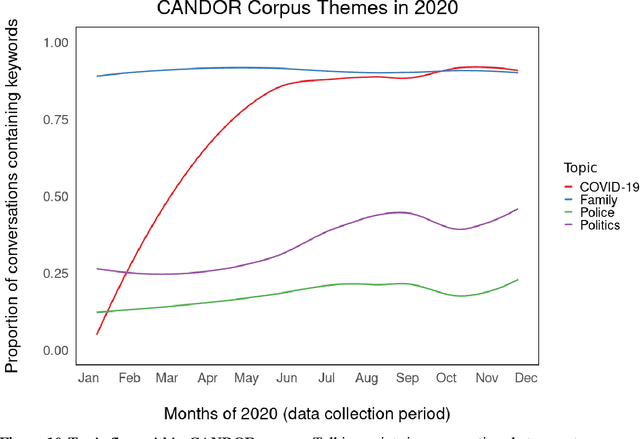

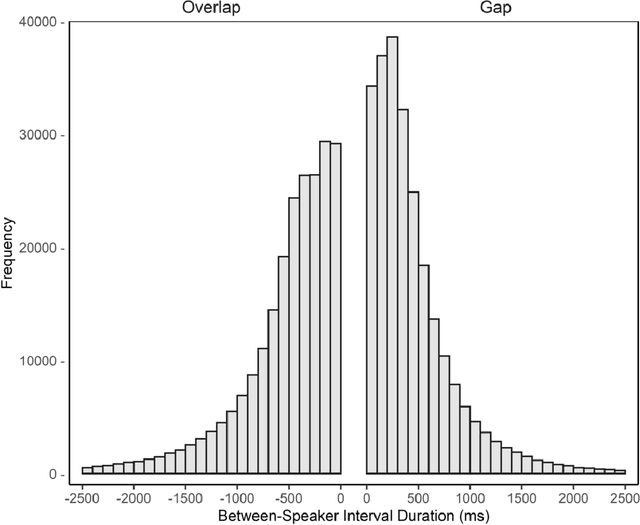
People spend a substantial portion of their lives engaged in conversation, and yet our scientific understanding of conversation is still in its infancy. In this report we advance an interdisciplinary science of conversation, with findings from a large, novel, multimodal corpus of 1,656 recorded conversations in spoken English. This 7+ million word, 850 hour corpus totals over 1TB of audio, video, and transcripts, with moment-to-moment measures of vocal, facial, and semantic expression, along with an extensive survey of speaker post conversation reflections. We leverage the considerable scope of the corpus to (1) extend key findings from the literature, such as the cooperativeness of human turn-taking; (2) define novel algorithmic procedures for the segmentation of speech into conversational turns; (3) apply machine learning insights across various textual, auditory, and visual features to analyze what makes conversations succeed or fail; and (4) explore how conversations are related to well-being across the lifespan. We also report (5) a comprehensive mixed-method report, based on quantitative analysis and qualitative review of each recording, that showcases how individuals from diverse backgrounds alter their communication patterns and find ways to connect. We conclude with a discussion of how this large-scale public dataset may offer new directions for future research, especially across disciplinary boundaries, as scholars from a variety of fields appear increasingly interested in the study of conversation.
Real-time RGBD-based Extended Body Pose Estimation
Mar 05, 2021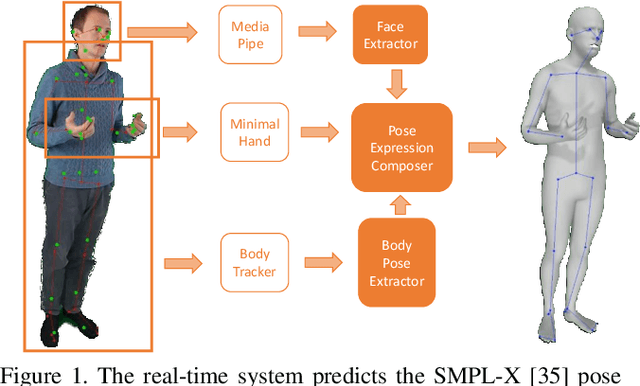
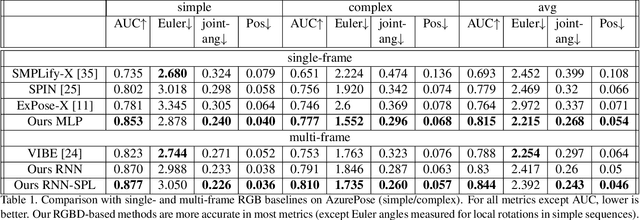
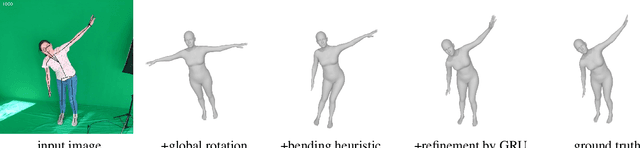
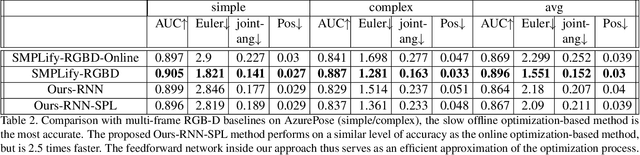
We present a system for real-time RGBD-based estimation of 3D human pose. We use parametric 3D deformable human mesh model (SMPL-X) as a representation and focus on the real-time estimation of parameters for the body pose, hands pose and facial expression from Kinect Azure RGB-D camera. We train estimators of body pose and facial expression parameters. Both estimators use previously published landmark extractors as input and custom annotated datasets for supervision, while hand pose is estimated directly by a previously published method. We combine the predictions of those estimators into a temporally-smooth human pose. We train the facial expression extractor on a large talking face dataset, which we annotate with facial expression parameters. For the body pose we collect and annotate a dataset of 56 people captured from a rig of 5 Kinect Azure RGB-D cameras and use it together with a large motion capture AMASS dataset. Our RGB-D body pose model outperforms the state-of-the-art RGB-only methods and works on the same level of accuracy compared to a slower RGB-D optimization-based solution. The combined system runs at 30 FPS on a server with a single GPU. The code will be available at https://saic-violet.github.io/rgbd-kinect-pose
LOMo: Latent Ordinal Model for Facial Analysis in Videos
Apr 06, 2016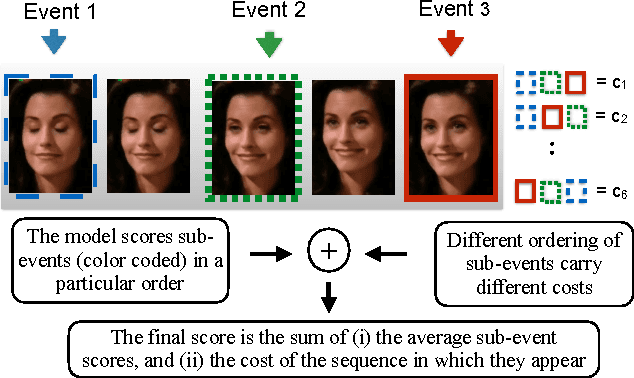
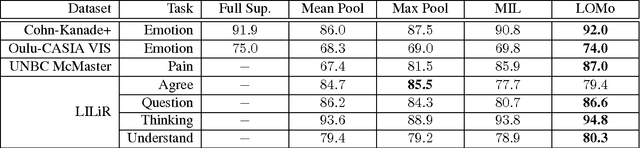
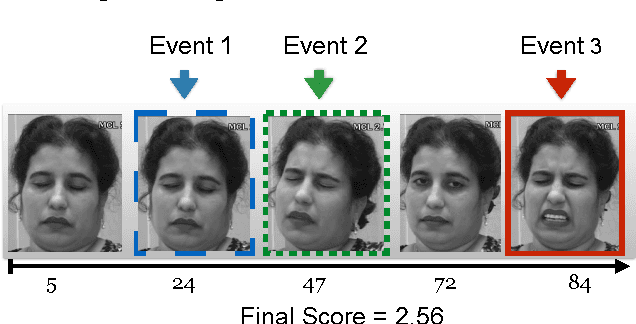
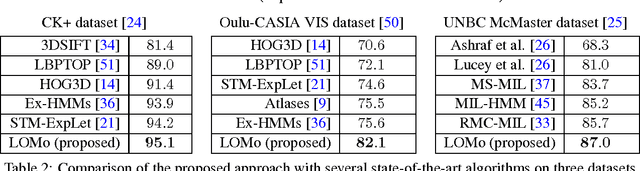
We study the problem of facial analysis in videos. We propose a novel weakly supervised learning method that models the video event (expression, pain etc.) as a sequence of automatically mined, discriminative sub-events (eg. onset and offset phase for smile, brow lower and cheek raise for pain). The proposed model is inspired by the recent works on Multiple Instance Learning and latent SVM/HCRF- it extends such frameworks to model the ordinal or temporal aspect in the videos, approximately. We obtain consistent improvements over relevant competitive baselines on four challenging and publicly available video based facial analysis datasets for prediction of expression, clinical pain and intent in dyadic conversations. In combination with complimentary features, we report state-of-the-art results on these datasets.
Landmarks-assisted Collaborative Deep Framework for Automatic 4D Facial Expression Recognition
Oct 11, 2019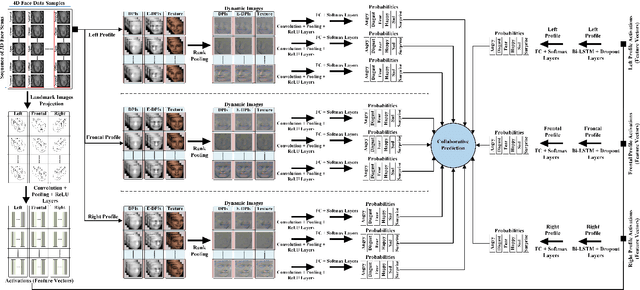
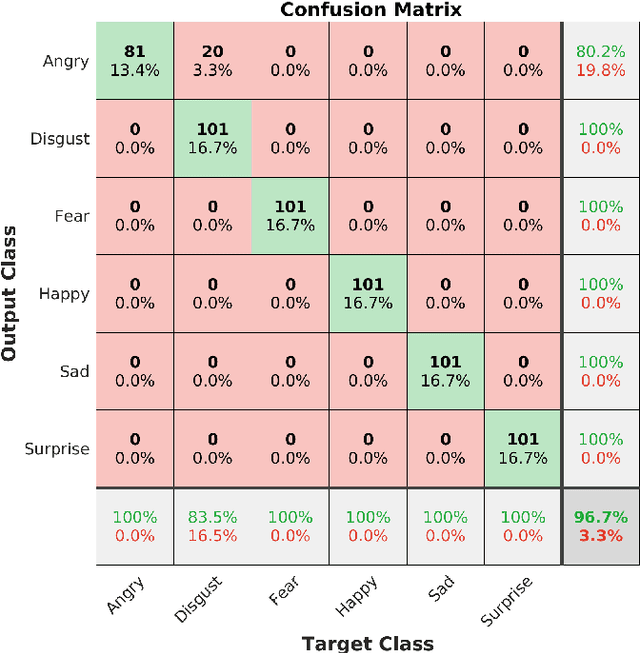
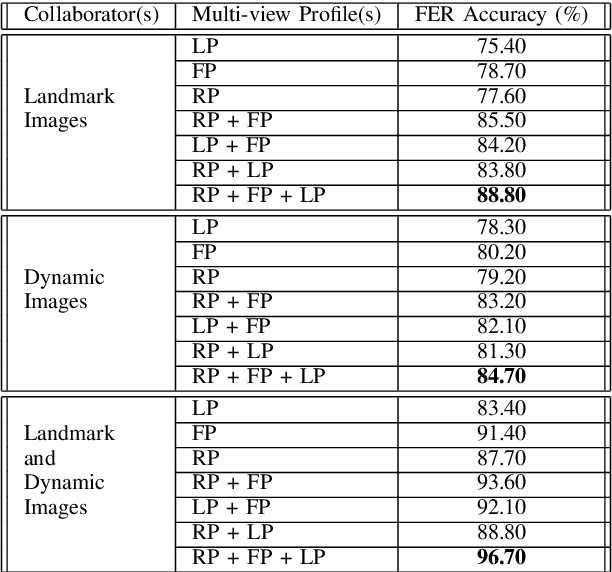
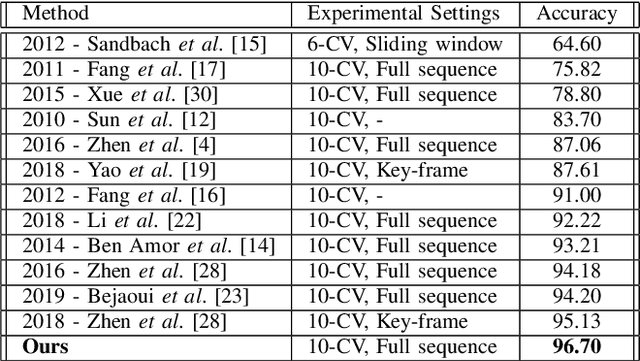
We propose a novel landmarks-assisted collaborative end-to-end deep framework for automatic 4D FER. Using 4D face scan data, we calculate its various geometrical images, and afterwards use rank pooling to generate their dynamic images encapsulating important facial muscle movements over time. As well, the given 3D landmarks are projected on a 2D plane as binary images and convolutional layers are used to extract sequences of feature vectors for every landmark video. During the training stage, the dynamic images are used to train an end-to-end deep network, while the feature vectors of landmark images are used train a long short-term memory (LSTM) network. The finally improved set of expression predictions are obtained when the dynamic and landmark images collaborate over multi-views using the proposed deep framework. Performance results obtained from extensive experimentation on the widely-adopted BU-4DFE database under globally used settings prove that our proposed collaborative framework outperforms the state-of-the-art 4D FER methods and reach a promising classification accuracy of 96.7% demonstrating its effectiveness.
Local Learning with Deep and Handcrafted Features for Facial Expression Recognition
Sep 25, 2018
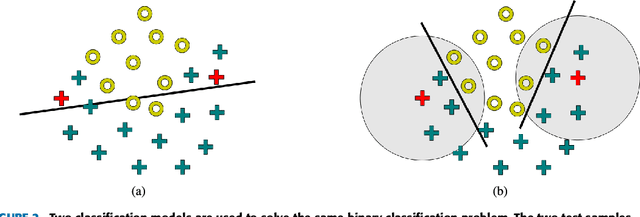
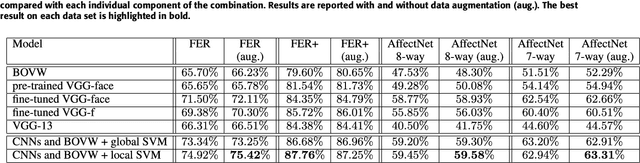
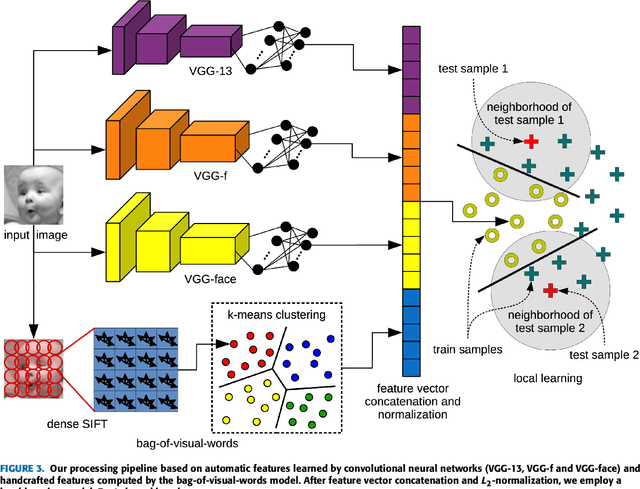
We present an approach that combines automatic features learned by convolutional neural networks (CNN) and handcrafted features computed by the bag-of-visual-words (BOVW) model in order to achieve state-of-the-art results in facial expression recognition. To obtain automatic features, we experiment with multiple CNN architectures, pre-trained models and training procedures, e.g. Dense-Sparse-Dense. After fusing the two types of features, we employ a local learning framework to predict the class label for each test image. The local learning framework is based on three steps. First, a k-nearest neighbors model is applied for selecting the nearest training samples for an input test image. Second, a one-versus-all Support Vector Machines (SVM) classifier is trained on the selected training samples. Finally, the SVM classifier is used for predicting the class label only for the test image it was trained for. Although we used local learning in combination with handcrafted features in our previous work, to the best of our knowledge, local learning has never been employed in combination with deep features. The experiments on the 2013 Facial Expression Recognition (FER) Challenge data set and the FER+ data set demonstrate that our approach achieves state-of-the-art results. With a top accuracy of 75.42% on the FER 2013 data set and 87.76% on the FER+ data set, we surpass all competition by more than 2% on both data sets.
Meta Transfer Learning for Facial Emotion Recognition
May 25, 2018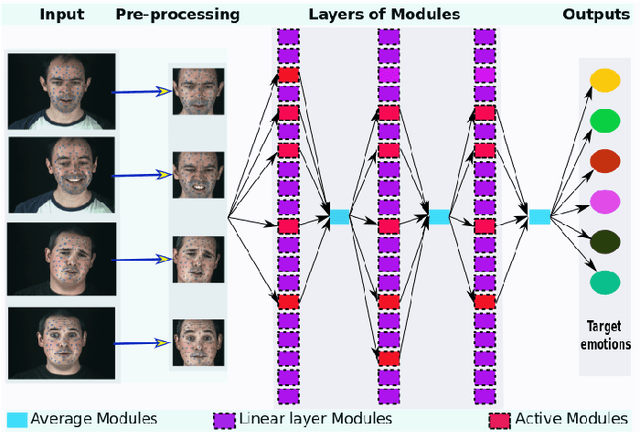
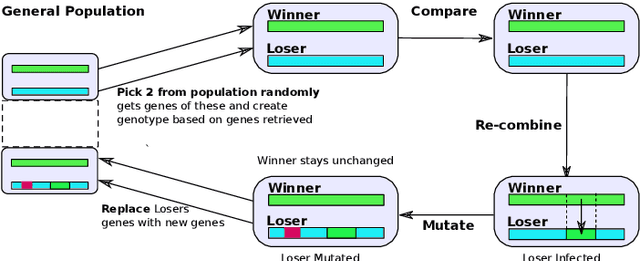
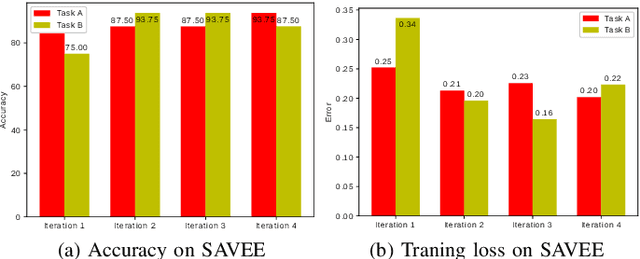
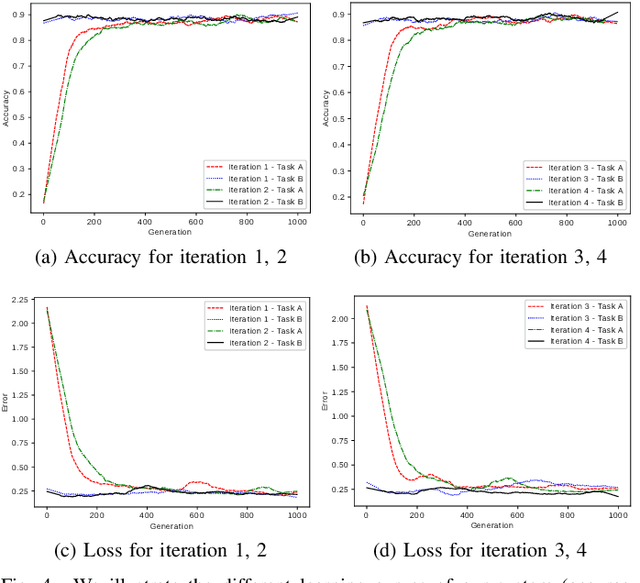
The use of deep learning techniques for automatic facial expression recognition has recently attracted great interest but developed models are still unable to generalize well due to the lack of large emotion datasets for deep learning. To overcome this problem, in this paper, we propose utilizing a novel transfer learning approach relying on PathNet and investigate how knowledge can be accumulated within a given dataset and how the knowledge captured from one emotion dataset can be transferred into another in order to improve the overall performance. To evaluate the robustness of our system, we have conducted various sets of experiments on two emotion datasets: SAVEE and eNTERFACE. The experimental results demonstrate that our proposed system leads to improvement in performance of emotion recognition and performs significantly better than the recent state-of-the-art schemes adopting fine-\ tuning/pre-trained approaches.
Grammatical facial expression recognition using customized deep neural network architecture
Nov 16, 2017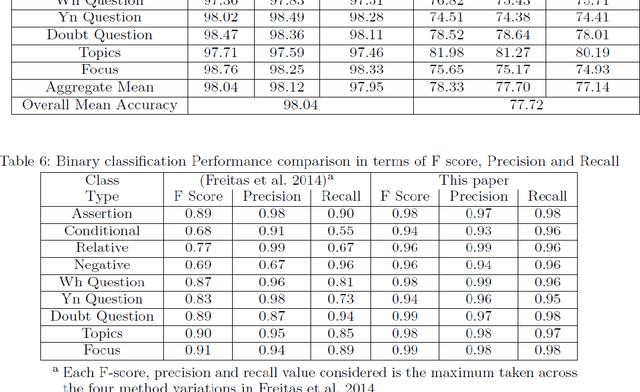
This paper proposes to expand the visual understanding capacity of computers by helping it recognize human sign language more efficiently. This is carried out through recognition of facial expressions, which accompany the hand signs used in this language. This paper specially focuses on the popular Brazilian sign language (LIBRAS). While classifying different hand signs into their respective word meanings has already seen much literature dedicated to it, the emotions or intention with which the words are expressed haven't primarily been taken into consideration. As from our normal human experience, words expressed with different emotions or mood can have completely different meanings attached to it. Lending computers the ability of classifying these facial expressions, can help add another level of deep understanding of what the deaf person exactly wants to communicate. The proposed idea is implemented through a deep neural network having a customized architecture. This helps learning specific patterns in individual expressions much better as compared to a generic approach. With an overall accuracy of 98.04%, the implemented deep network performs excellently well and thus is fit to be used in any given practical scenario.
Super-FAN: Integrated facial landmark localization and super-resolution of real-world low resolution faces in arbitrary poses with GANs
Mar 27, 2018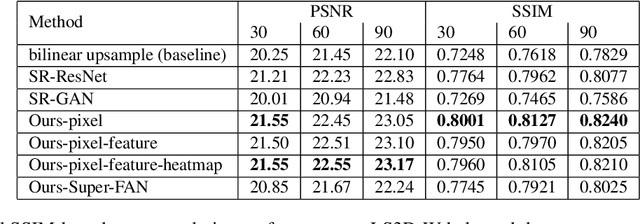
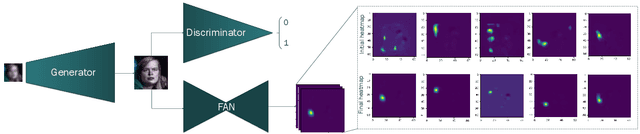
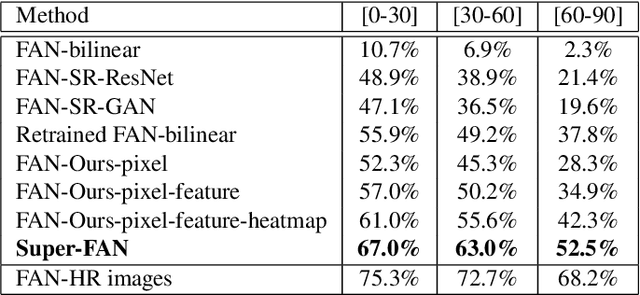
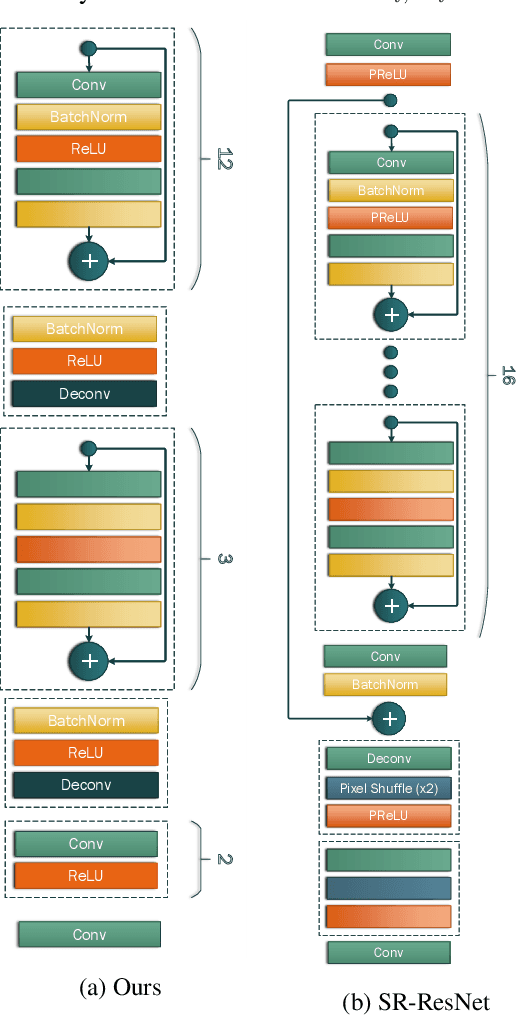
This paper addresses 2 challenging tasks: improving the quality of low resolution facial images and accurately locating the facial landmarks on such poor resolution images. To this end, we make the following 5 contributions: (a) we propose Super-FAN: the very first end-to-end system that addresses both tasks simultaneously, i.e. both improves face resolution and detects the facial landmarks. The novelty or Super-FAN lies in incorporating structural information in a GAN-based super-resolution algorithm via integrating a sub-network for face alignment through heatmap regression and optimizing a novel heatmap loss. (b) We illustrate the benefit of training the two networks jointly by reporting good results not only on frontal images (as in prior work) but on the whole spectrum of facial poses, and not only on synthetic low resolution images (as in prior work) but also on real-world images. (c) We improve upon the state-of-the-art in face super-resolution by proposing a new residual-based architecture. (d) Quantitatively, we show large improvement over the state-of-the-art for both face super-resolution and alignment. (e) Qualitatively, we show for the first time good results on real-world low resolution images.
FaceVR: Real-Time Facial Reenactment and Eye Gaze Control in Virtual Reality
Mar 21, 2018

We propose FaceVR, a novel image-based method that enables video teleconferencing in VR based on self-reenactment. State-of-the-art face tracking methods in the VR context are focused on the animation of rigged 3d avatars. While they achieve good tracking performance the results look cartoonish and not real. In contrast to these model-based approaches, FaceVR enables VR teleconferencing using an image-based technique that results in nearly photo-realistic outputs. The key component of FaceVR is a robust algorithm to perform real-time facial motion capture of an actor who is wearing a head-mounted display (HMD), as well as a new data-driven approach for eye tracking from monocular videos. Based on reenactment of a prerecorded stereo video of the person without the HMD, FaceVR incorporates photo-realistic re-rendering in real time, thus allowing artificial modifications of face and eye appearances. For instance, we can alter facial expressions or change gaze directions in the prerecorded target video. In a live setup, we apply these newly-introduced algorithmic components.