 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLandmarks-assisted Collaborative Deep Framework for Automatic 4D Facial Expression Recognition
Paper and Code
Oct 11, 2019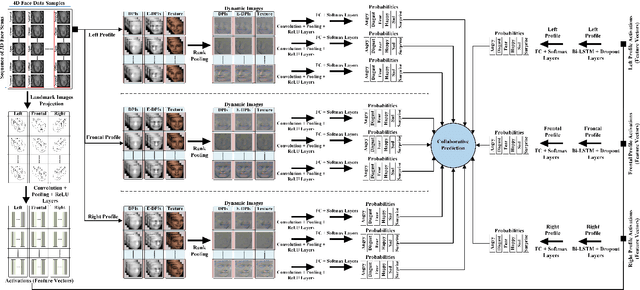
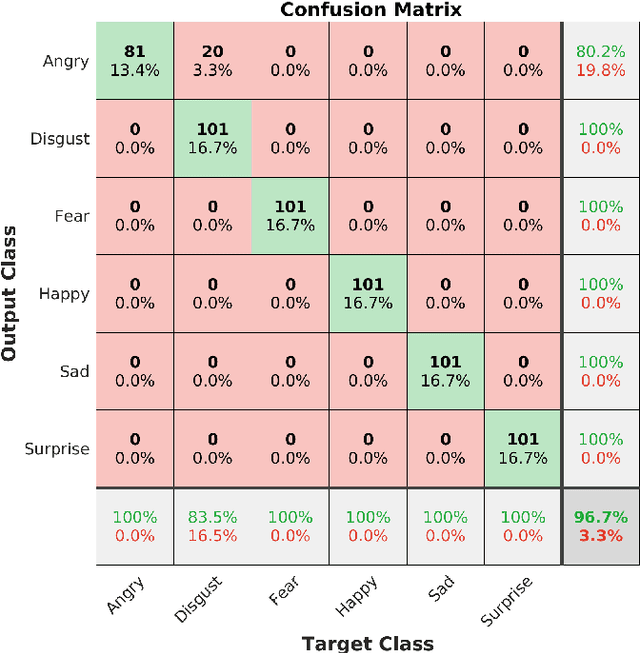
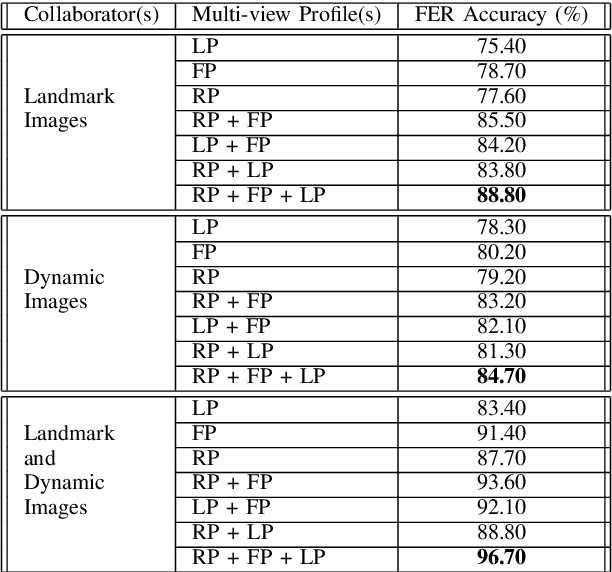
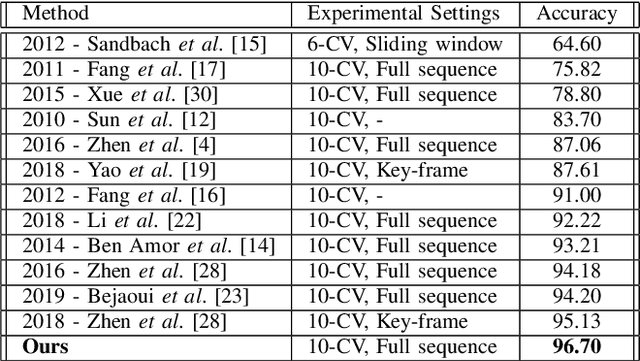
We propose a novel landmarks-assisted collaborative end-to-end deep framework for automatic 4D FER. Using 4D face scan data, we calculate its various geometrical images, and afterwards use rank pooling to generate their dynamic images encapsulating important facial muscle movements over time. As well, the given 3D landmarks are projected on a 2D plane as binary images and convolutional layers are used to extract sequences of feature vectors for every landmark video. During the training stage, the dynamic images are used to train an end-to-end deep network, while the feature vectors of landmark images are used train a long short-term memory (LSTM) network. The finally improved set of expression predictions are obtained when the dynamic and landmark images collaborate over multi-views using the proposed deep framework. Performance results obtained from extensive experimentation on the widely-adopted BU-4DFE database under globally used settings prove that our proposed collaborative framework outperforms the state-of-the-art 4D FER methods and reach a promising classification accuracy of 96.7% demonstrating its effectiveness.