 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
A Novel Space-Time Representation on the Positive Semidefinite Con for Facial Expression Recognition
Jul 20, 2017
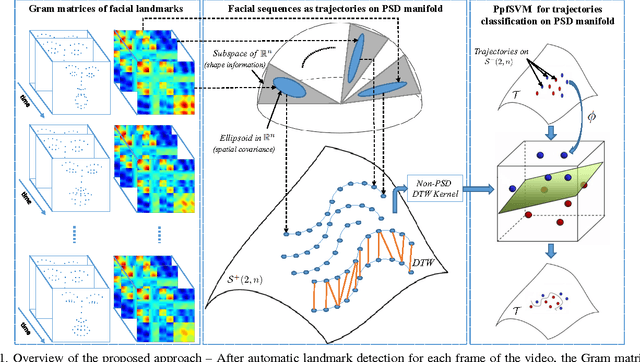
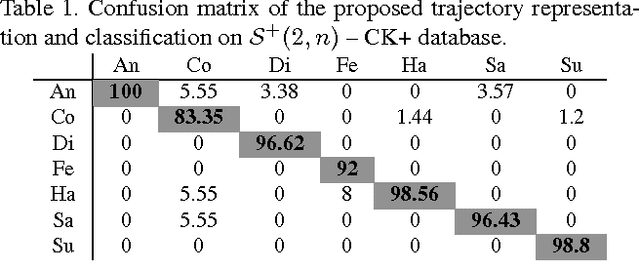
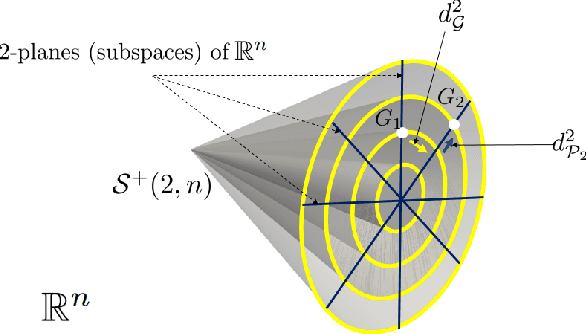
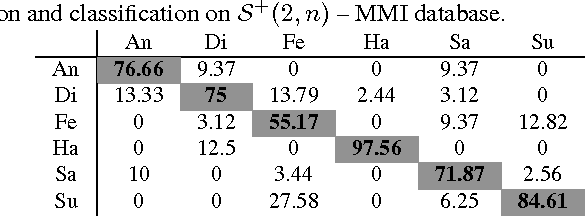
In this paper, we study the problem of facial expression recognition using a novel space-time geometric representation. We describe the temporal evolution of facial landmarks as parametrized trajectories on the Riemannian manifold of positive semidefinite matrices of fixed-rank. Our representation has the advantage to bring naturally a second desirable quantity when comparing shapes -- the spatial covariance -- in addition to the conventional affine-shape representation. We derive then geometric and computational tools for rate-invariant analysis and adaptive re-sampling of trajectories, grounding on the Riemannian geometry of the manifold. Specifically, our approach involves three steps: 1) facial landmarks are first mapped into the Riemannian manifold of positive semidefinite matrices of rank 2, to build time-parameterized trajectories; 2) a temporal alignment is performed on the trajectories, providing a geometry-aware (dis-)similarity measure between them; 3) finally, pairwise proximity function SVM (ppfSVM) is used to classify them, incorporating the latter (dis-)similarity measure into the kernel function. We show the effectiveness of the proposed approach on four publicly available benchmarks (CK+, MMI, Oulu-CASIA, and AFEW). The results of the proposed approach are comparable to or better than the state-of-the-art methods when involving only facial landmarks.
Learning to Sketch Human Facial Portraits using Personal Styles by Case-Based Reasoning
Sep 13, 2016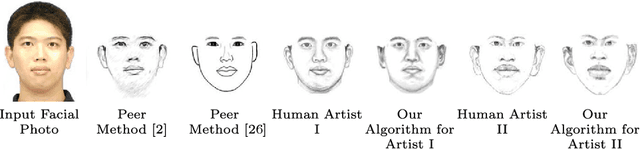
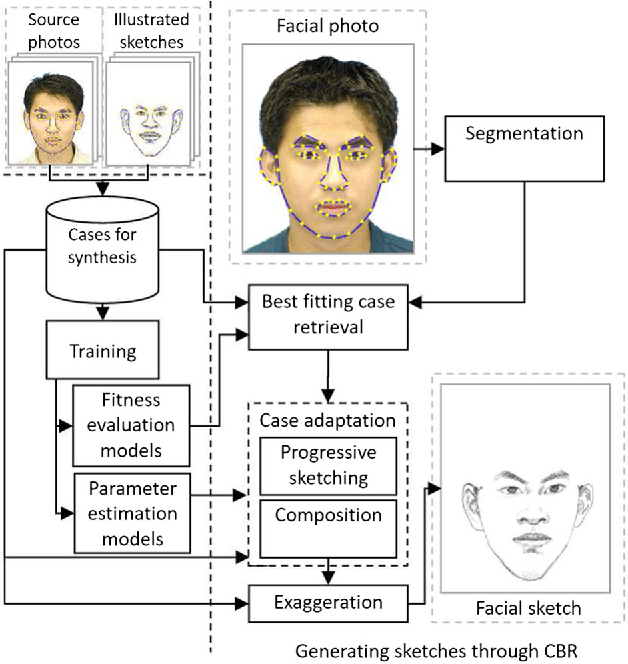
This paper employs case-based reasoning (CBR) to capture the personal styles of individual artists and generate the human facial portraits from photos accordingly. For each human artist to be mimicked, a series of cases are firstly built-up from her/his exemplars of source facial photo and hand-drawn sketch, and then its stylization for facial photo is transformed as a style-transferring process of iterative refinement by looking-for and applying best-fit cases in a sense of style optimization. Two models, fitness evaluation model and parameter estimation model, are learned for case retrieval and adaptation respectively from these cases. The fitness evaluation model is to decide which case is best-fitted to the sketching of current interest, and the parameter estimation model is to automate case adaptation. The resultant sketch is synthesized progressively with an iterative loop of retrieval and adaptation of candidate cases until the desired aesthetic style is achieved. To explore the effectiveness and advantages of the novel approach, we experimentally compare the sketch portraits generated by the proposed method with that of a state-of-the-art example-based facial sketch generation algorithm as well as a couple commercial software packages. The comparisons reveal that our CBR based synthesis method for facial portraits is superior both in capturing and reproducing artists' personal illustration styles to the peer methods.
Spatio-Temporal Relation and Attention Learning for Facial Action Unit Detection
Jan 05, 2020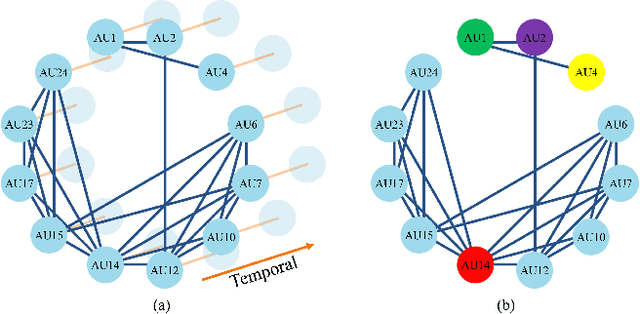
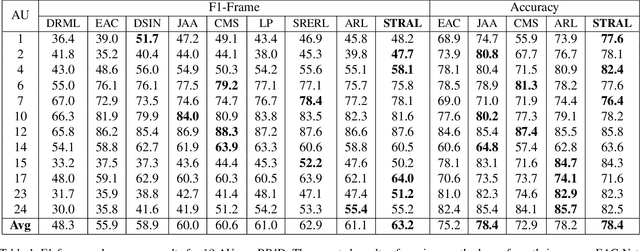
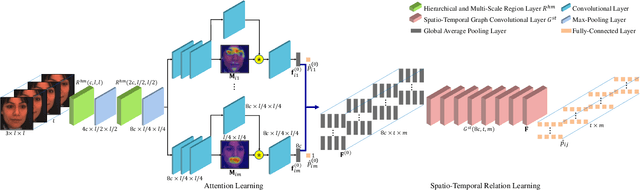
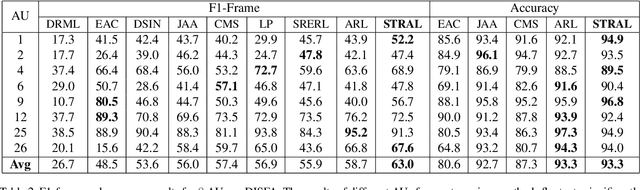
Spatio-temporal relations among facial action units (AUs) convey significant information for AU detection yet have not been thoroughly exploited. The main reasons are the limited capability of current AU detection works in simultaneously learning spatial and temporal relations, and the lack of precise localization information for AU feature learning. To tackle these limitations, we propose a novel spatio-temporal relation and attention learning framework for AU detection. Specifically, we introduce a spatio-temporal graph convolutional network to capture both spatial and temporal relations from dynamic AUs, in which the AU relations are formulated as a spatio-temporal graph with adaptively learned instead of predefined edge weights. Moreover, the learning of spatio-temporal relations among AUs requires individual AU features. Considering the dynamism and shape irregularity of AUs, we propose an attention regularization method to adaptively learn regional attentions that capture highly relevant regions and suppress irrelevant regions so as to extract a complete feature for each AU. Extensive experiments show that our approach achieves substantial improvements over the state-of-the-art AU detection methods on BP4D and especially DISFA benchmarks.
Teacher-Student Training and Triplet Loss for Facial Expression Recognition under Occlusion
Aug 03, 2020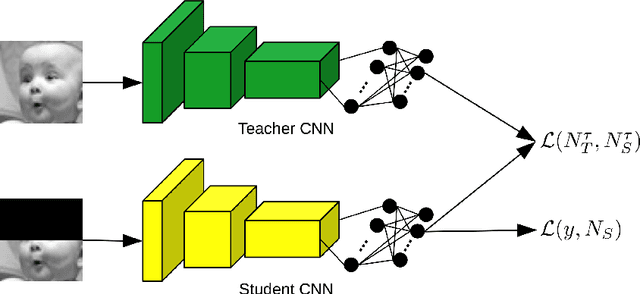
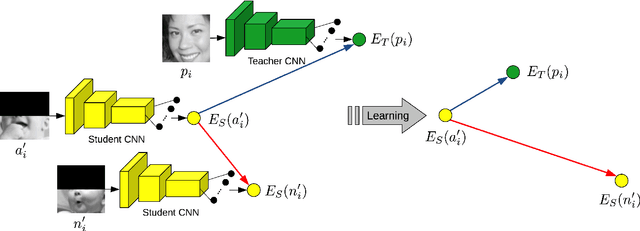
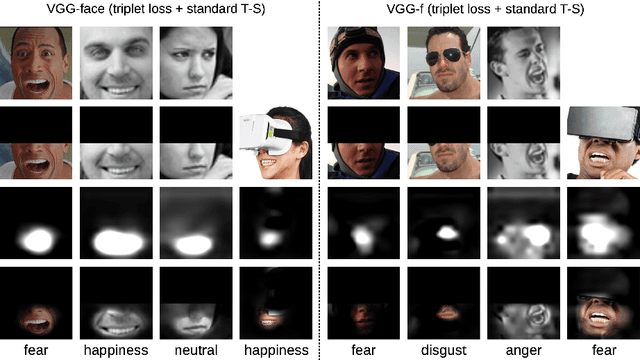
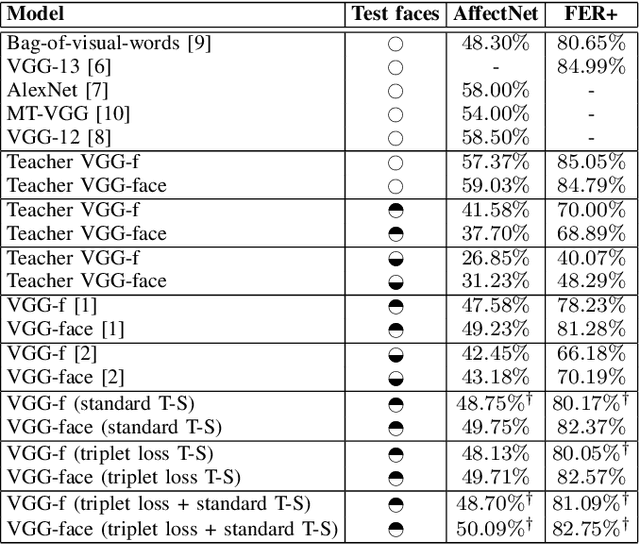
In this paper, we study the task of facial expression recognition under strong occlusion. We are particularly interested in cases where 50% of the face is occluded, e.g. when the subject wears a Virtual Reality (VR) headset. While previous studies show that pre-training convolutional neural networks (CNNs) on fully-visible (non-occluded) faces improves the accuracy, we propose to employ knowledge distillation to achieve further improvements. First of all, we employ the classic teacher-student training strategy, in which the teacher is a CNN trained on fully-visible faces and the student is a CNN trained on occluded faces. Second of all, we propose a new approach for knowledge distillation based on triplet loss. During training, the goal is to reduce the distance between an anchor embedding, produced by a student CNN that takes occluded faces as input, and a positive embedding (from the same class as the anchor), produced by a teacher CNN trained on fully-visible faces, so that it becomes smaller than the distance between the anchor and a negative embedding (from a different class than the anchor), produced by the student CNN. Third of all, we propose to combine the distilled embeddings obtained through the classic teacher-student strategy and our novel teacher-student strategy based on triplet loss into a single embedding vector. We conduct experiments on two benchmarks, FER+ and AffectNet, with two CNN architectures, VGG-f and VGG-face, showing that knowledge distillation can bring significant improvements over the state-of-the-art methods designed for occluded faces in the VR setting.
Cross Attentional Audio-Visual Fusion for Dimensional Emotion Recognition
Nov 09, 2021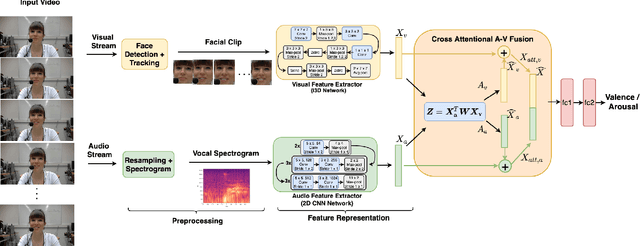
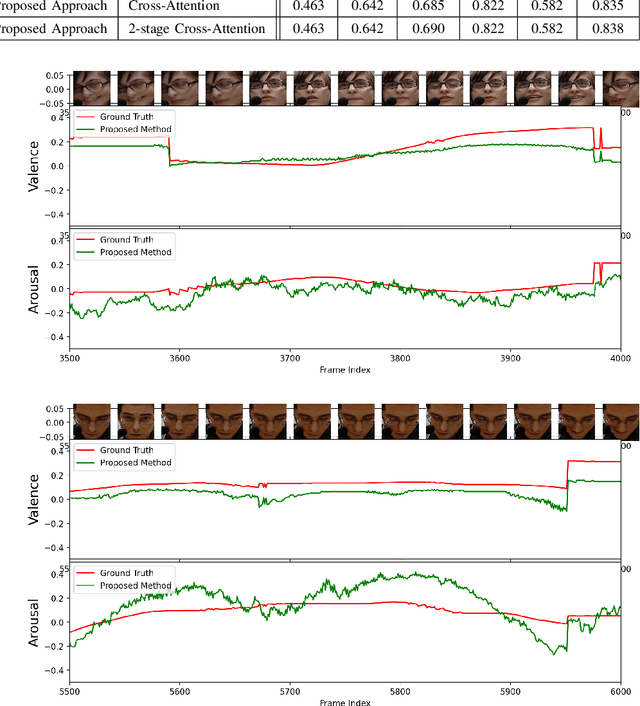
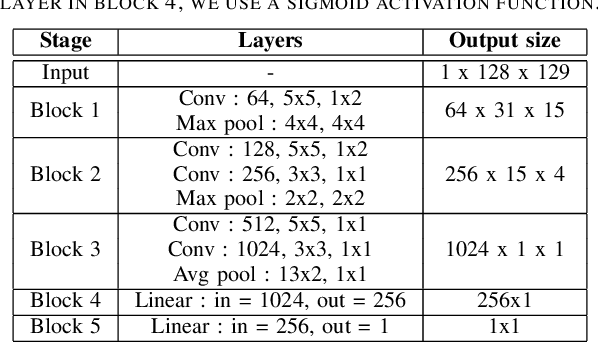
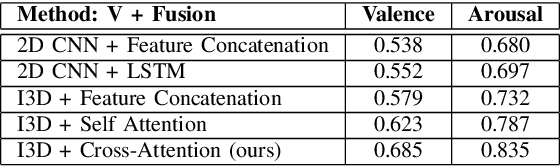
Multimodal analysis has recently drawn much interest in affective computing, since it can improve the overall accuracy of emotion recognition over isolated uni-modal approaches. The most effective techniques for multimodal emotion recognition efficiently leverage diverse and complimentary sources of information, such as facial, vocal, and physiological modalities, to provide comprehensive feature representations. In this paper, we focus on dimensional emotion recognition based on the fusion of facial and vocal modalities extracted from videos, where complex spatiotemporal relationships may be captured. Most of the existing fusion techniques rely on recurrent networks or conventional attention mechanisms that do not effectively leverage the complimentary nature of audio-visual (A-V) modalities. We introduce a cross-attentional fusion approach to extract the salient features across A-V modalities, allowing for accurate prediction of continuous values of valence and arousal. Our new cross-attentional A-V fusion model efficiently leverages the inter-modal relationships. In particular, it computes cross-attention weights to focus on the more contributive features across individual modalities, and thereby combine contributive feature representations, which are then fed to fully connected layers for the prediction of valence and arousal. The effectiveness of the proposed approach is validated experimentally on videos from the RECOLA and Fatigue (private) data-sets. Results indicate that our cross-attentional A-V fusion model is a cost-effective approach that outperforms state-of-the-art fusion approaches. Code is available: \url{https://github.com/praveena2j/Cross-Attentional-AV-Fusion}
Write-a-speaker: Text-based Emotional and Rhythmic Talking-head Generation
Apr 16, 2021
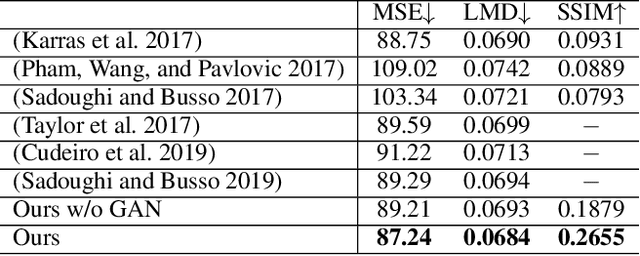
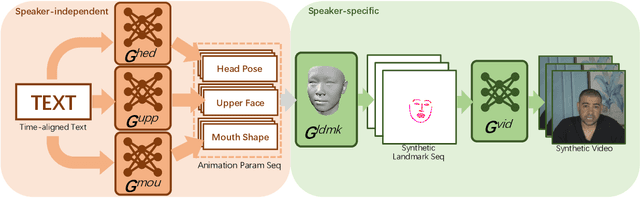
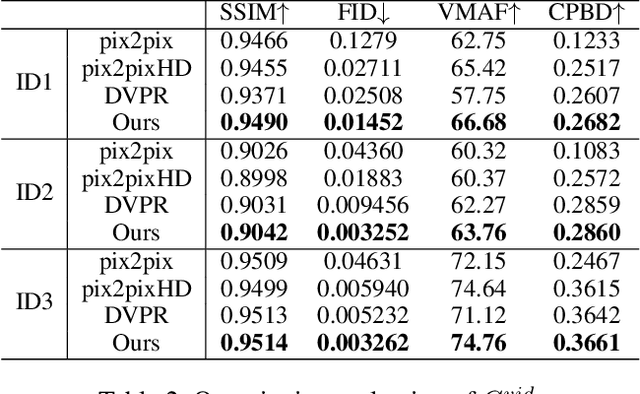
In this paper, we propose a novel text-based talking-head video generation framework that synthesizes high-fidelity facial expressions and head motions in accordance with contextual sentiments as well as speech rhythm and pauses. To be specific, our framework consists of a speaker-independent stage and a speaker-specific stage. In the speaker-independent stage, we design three parallel networks to generate animation parameters of the mouth, upper face, and head from texts, separately. In the speaker-specific stage, we present a 3D face model guided attention network to synthesize videos tailored for different individuals. It takes the animation parameters as input and exploits an attention mask to manipulate facial expression changes for the input individuals. Furthermore, to better establish authentic correspondences between visual motions (i.e., facial expression changes and head movements) and audios, we leverage a high-accuracy motion capture dataset instead of relying on long videos of specific individuals. After attaining the visual and audio correspondences, we can effectively train our network in an end-to-end fashion. Extensive experiments on qualitative and quantitative results demonstrate that our algorithm achieves high-quality photo-realistic talking-head videos including various facial expressions and head motions according to speech rhythms and outperforms the state-of-the-art.
Smile Like You Mean It: Driving Animatronic Robotic Face with Learned Models
May 26, 2021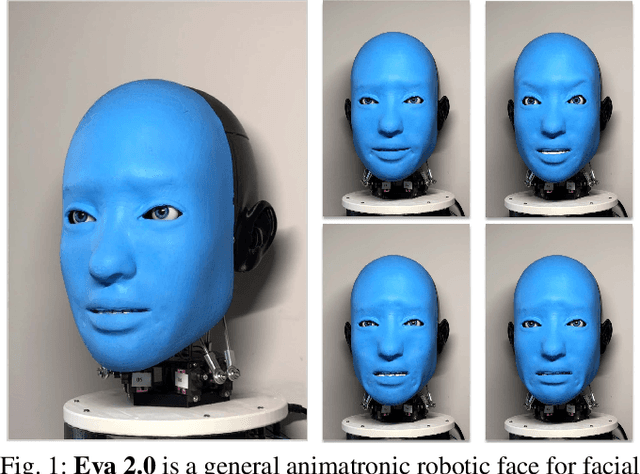



Ability to generate intelligent and generalizable facial expressions is essential for building human-like social robots. At present, progress in this field is hindered by the fact that each facial expression needs to be programmed by humans. In order to adapt robot behavior in real time to different situations that arise when interacting with human subjects, robots need to be able to train themselves without requiring human labels, as well as make fast action decisions and generalize the acquired knowledge to diverse and new contexts. We addressed this challenge by designing a physical animatronic robotic face with soft skin and by developing a vision-based self-supervised learning framework for facial mimicry. Our algorithm does not require any knowledge of the robot's kinematic model, camera calibration or predefined expression set. By decomposing the learning process into a generative model and an inverse model, our framework can be trained using a single motor babbling dataset. Comprehensive evaluations show that our method enables accurate and diverse face mimicry across diverse human subjects. The project website is at http://www.cs.columbia.edu/~bchen/aiface/
Identity-Preserving Pose-Robust Face Hallucination Through Face Subspace Prior
Nov 20, 2021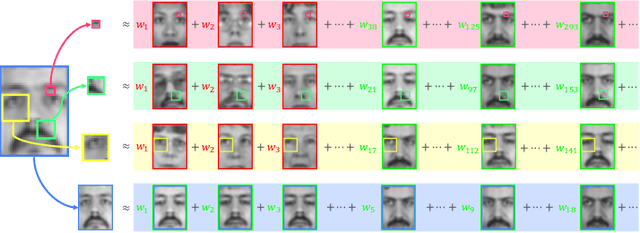
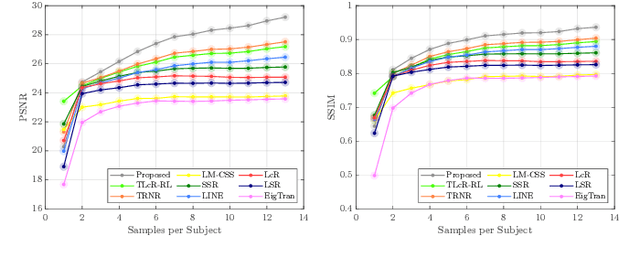

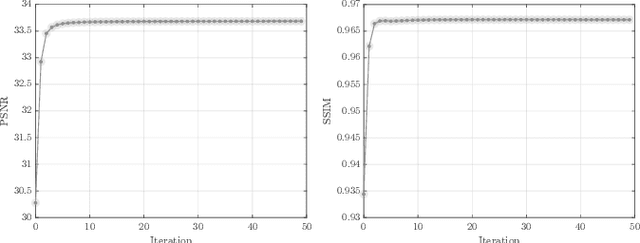
Over the past few decades, numerous attempts have been made to address the problem of recovering a high-resolution (HR) facial image from its corresponding low-resolution (LR) counterpart, a task commonly referred to as face hallucination. Despite the impressive performance achieved by position-patch and deep learning-based methods, most of these techniques are still unable to recover identity-specific features of faces. The former group of algorithms often produces blurry and oversmoothed outputs particularly in the presence of higher levels of degradation, whereas the latter generates faces which sometimes by no means resemble the individuals in the input images. In this paper, a novel face super-resolution approach will be introduced, in which the hallucinated face is forced to lie in a subspace spanned by the available training faces. Therefore, in contrast to the majority of existing face hallucination techniques and thanks to this face subspace prior, the reconstruction is performed in favor of recovering person-specific facial features, rather than merely increasing image quantitative scores. Furthermore, inspired by recent advances in the area of 3D face reconstruction, an efficient 3D dictionary alignment scheme is also presented, through which the algorithm becomes capable of dealing with low-resolution faces taken in uncontrolled conditions. In extensive experiments carried out on several well-known face datasets, the proposed algorithm shows remarkable performance by generating detailed and close to ground truth results which outperform the state-of-the-art face hallucination algorithms by significant margins both in quantitative and qualitative evaluations.
Live Speech Portraits: Real-Time Photorealistic Talking-Head Animation
Sep 24, 2021
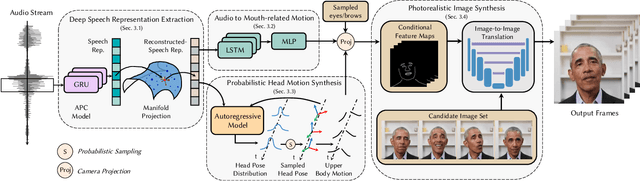
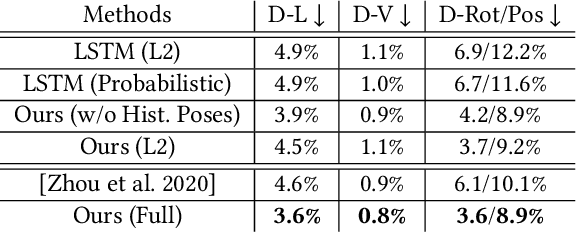
To the best of our knowledge, we first present a live system that generates personalized photorealistic talking-head animation only driven by audio signals at over 30 fps. Our system contains three stages. The first stage is a deep neural network that extracts deep audio features along with a manifold projection to project the features to the target person's speech space. In the second stage, we learn facial dynamics and motions from the projected audio features. The predicted motions include head poses and upper body motions, where the former is generated by an autoregressive probabilistic model which models the head pose distribution of the target person. Upper body motions are deduced from head poses. In the final stage, we generate conditional feature maps from previous predictions and send them with a candidate image set to an image-to-image translation network to synthesize photorealistic renderings. Our method generalizes well to wild audio and successfully synthesizes high-fidelity personalized facial details, e.g., wrinkles, teeth. Our method also allows explicit control of head poses. Extensive qualitative and quantitative evaluations, along with user studies, demonstrate the superiority of our method over state-of-the-art techniques.
Local Multi-Head Channel Self-Attention for Facial Expression Recognition
Nov 18, 2021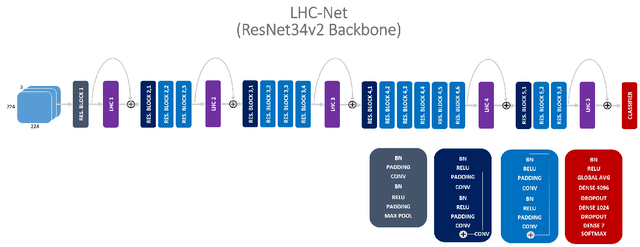
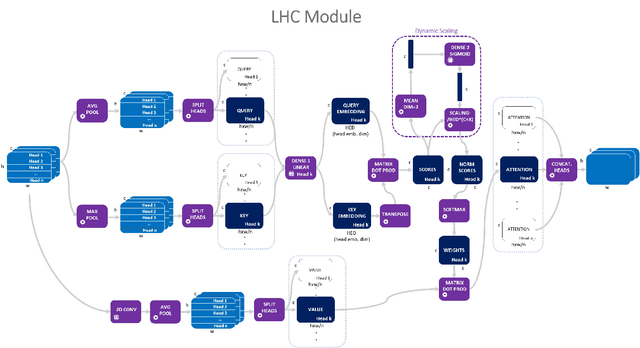
Since the Transformer architecture was introduced in 2017 there has been many attempts to bring the self-attention paradigm in the field of computer vision. In this paper we propose a novel self-attention module that can be easily integrated in virtually every convolutional neural network and that is specifically designed for computer vision, the LHC: Local (multi) Head Channel (self-attention). LHC is based on two main ideas: first, we think that in computer vision the best way to leverage the self-attention paradigm is the channel-wise application instead of the more explored spatial attention and that convolution will not be replaced by attention modules like recurrent networks were in NLP; second, a local approach has the potential to better overcome the limitations of convolution than global attention. With LHC-Net we managed to achieve a new state of the art in the famous FER2013 dataset with a significantly lower complexity and impact on the "host" architecture in terms of computational cost when compared with the previous SOTA.