 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
3D Dense Geometry-Guided Facial Expression Synthesis by Adversarial Learning
Sep 30, 2020

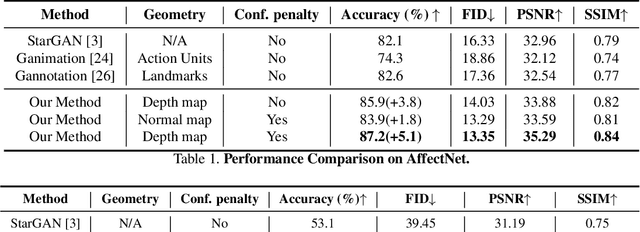
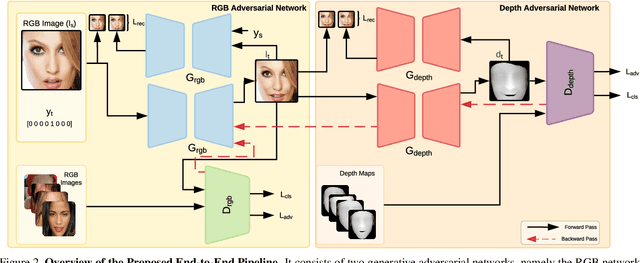

Manipulating facial expressions is a challenging task due to fine-grained shape changes produced by facial muscles and the lack of input-output pairs for supervised learning. Unlike previous methods using Generative Adversarial Networks (GAN), which rely on cycle-consistency loss or sparse geometry (landmarks) loss for expression synthesis, we propose a novel GAN framework to exploit 3D dense (depth and surface normals) information for expression manipulation. However, a large-scale dataset containing RGB images with expression annotations and their corresponding depth maps is not available. To this end, we propose to use an off-the-shelf state-of-the-art 3D reconstruction model to estimate the depth and create a large-scale RGB-Depth dataset after a manual data clean-up process. We utilise this dataset to minimise the novel depth consistency loss via adversarial learning (note we do not have ground truth depth maps for generated face images) and the depth categorical loss of synthetic data on the discriminator. In addition, to improve the generalisation and lower the bias of the depth parameters, we propose to use a novel confidence regulariser on the discriminator side of the framework. We extensively performed both quantitative and qualitative evaluations on two publicly available challenging facial expression benchmarks: AffectNet and RaFD. Our experiments demonstrate that the proposed method outperforms the competitive baseline and existing arts by a large margin.
Spontaneous Facial Expression Recognition using Sparse Representation
Sep 30, 2018

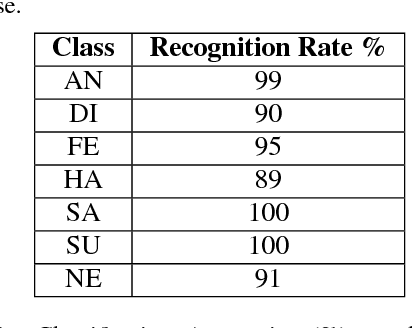
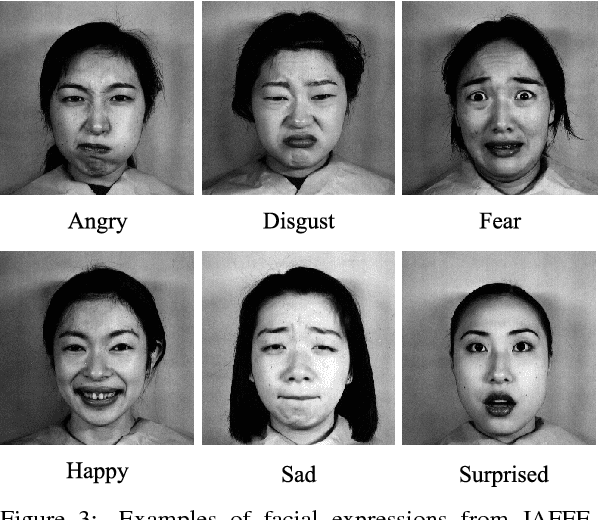
Facial expression is the most natural means for human beings to communicate their emotions. Most facial expression analysis studies consider the case of acted expressions. Spontaneous facial expression recognition is significantly more challenging since each person has a different way to react to a given emotion. We consider the problem of recognizing spontaneous facial expression by learning discriminative dictionaries for sparse representation. Facial images are represented as a sparse linear combination of prototype atoms via Orthogonal Matching Pursuit algorithm. Sparse codes are then used to train an SVM classifier dedicated to the recognition task. The dictionary that sparsifies the facial images (feature points with the same class labels should have similar sparse codes) is crucial for robust classification. Learning sparsifying dictionaries heavily relies on the initialization process of the dictionary. To improve the performance of dictionaries, a random face feature descriptor based on the Random Projection concept is developed. The effectiveness of the proposed method is evaluated through several experiments on the spontaneous facial expressions DynEmo database. It is also estimated on the well-known acted facial expressions JAFFE database for a purpose of comparison with state-of-the-art methods.
FACIAL: Synthesizing Dynamic Talking Face with Implicit Attribute Learning
Aug 18, 2021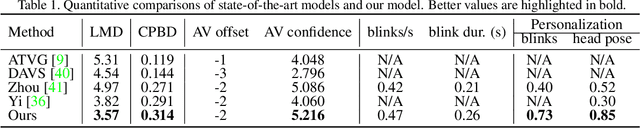
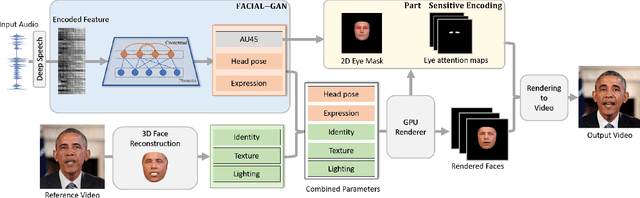
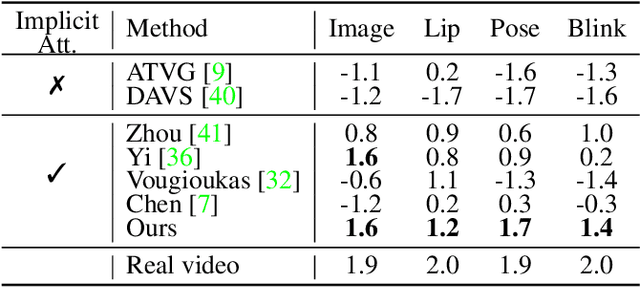
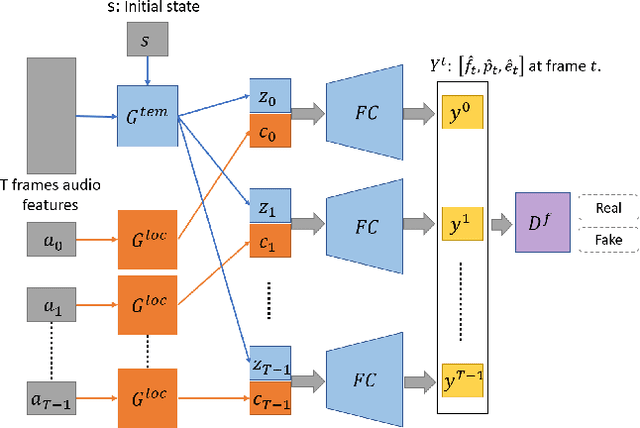
In this paper, we propose a talking face generation method that takes an audio signal as input and a short target video clip as reference, and synthesizes a photo-realistic video of the target face with natural lip motions, head poses, and eye blinks that are in-sync with the input audio signal. We note that the synthetic face attributes include not only explicit ones such as lip motions that have high correlations with speech, but also implicit ones such as head poses and eye blinks that have only weak correlation with the input audio. To model such complicated relationships among different face attributes with input audio, we propose a FACe Implicit Attribute Learning Generative Adversarial Network (FACIAL-GAN), which integrates the phonetics-aware, context-aware, and identity-aware information to synthesize the 3D face animation with realistic motions of lips, head poses, and eye blinks. Then, our Rendering-to-Video network takes the rendered face images and the attention map of eye blinks as input to generate the photo-realistic output video frames. Experimental results and user studies show our method can generate realistic talking face videos with not only synchronized lip motions, but also natural head movements and eye blinks, with better qualities than the results of state-of-the-art methods.
Facial Expression Recognition Under Partial Occlusion from Virtual Reality Headsets based on Transfer Learning
Aug 12, 2020
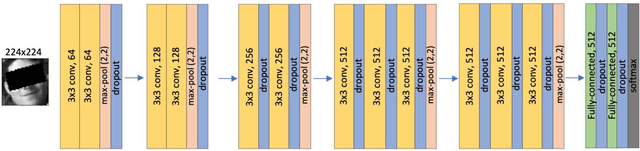
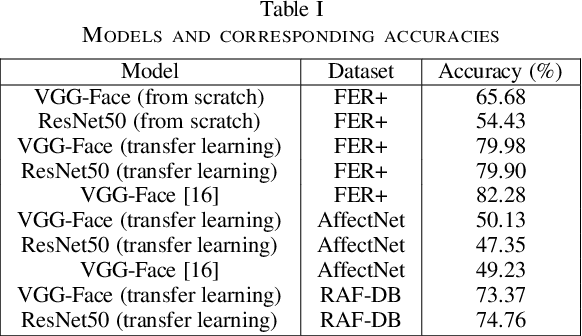
Facial expressions of emotion are a major channel in our daily communications, and it has been subject of intense research in recent years. To automatically infer facial expressions, convolutional neural network based approaches has become widely adopted due to their proven applicability to Facial Expression Recognition (FER) task.On the other hand Virtual Reality (VR) has gained popularity as an immersive multimedia platform, where FER can provide enriched media experiences. However, recognizing facial expression while wearing a head-mounted VR headset is a challenging task due to the upper half of the face being completely occluded. In this paper we attempt to overcome these issues and focus on facial expression recognition in presence of a severe occlusion where the user is wearing a head-mounted display in a VR setting. We propose a geometric model to simulate occlusion resulting from a Samsung Gear VR headset that can be applied to existing FER datasets. Then, we adopt a transfer learning approach, starting from two pretrained networks, namely VGG and ResNet. We further fine-tune the networks on FER+ and RAF-DB datasets. Experimental results show that our approach achieves comparable results to existing methods while training on three modified benchmark datasets that adhere to realistic occlusion resulting from wearing a commodity VR headset. Code for this paper is available at: https://github.com/bita-github/MRP-FER
BPLF: A Bi-Parallel Linear Flow Model for Facial Expression Generation from Emotion Set Images
May 27, 2021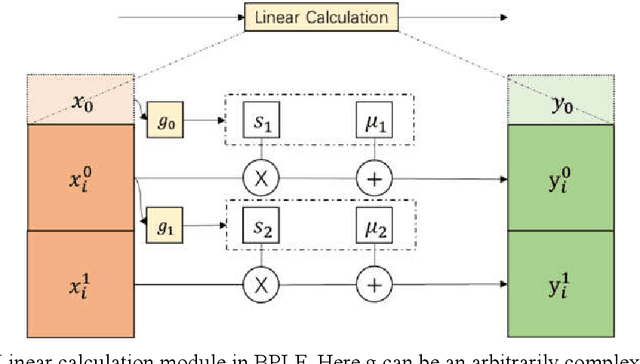
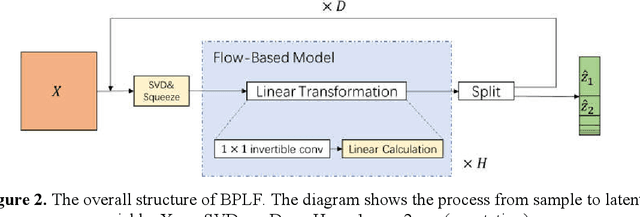
The flow-based generative model is a deep learning generative model, which obtains the ability to generate data by explicitly learning the data distribution. Theoretically its ability to restore data is stronger than other generative models. However, its implementation has many limitations, including limited model design, too many model parameters and tedious calculation. In this paper, a bi-parallel linear flow model for facial emotion generation from emotion set images is constructed, and a series of improvements have been made in terms of the expression ability of the model and the convergence speed in training. The model is mainly composed of several coupling layers superimposed to form a multi-scale structure, in which each coupling layer contains 1*1 reversible convolution and linear operation modules. Furthermore, this paper sorted out the current public data set of facial emotion images, made a new emotion data, and verified the model through this data set. The experimental results show that, under the traditional convolutional neural network, the 3-layer 3*3 convolution kernel is more conducive to extracte the features of the face images. The introduction of principal component decomposition can improve the convergence speed of the model.
EAMM: One-Shot Emotional Talking Face via Audio-Based Emotion-Aware Motion Model
May 31, 2022
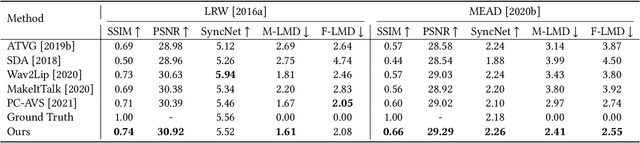
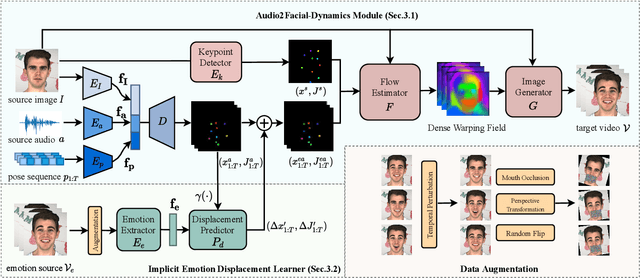

Although significant progress has been made to audio-driven talking face generation, existing methods either neglect facial emotion or cannot be applied to arbitrary subjects. In this paper, we propose the Emotion-Aware Motion Model (EAMM) to generate one-shot emotional talking faces by involving an emotion source video. Specifically, we first propose an Audio2Facial-Dynamics module, which renders talking faces from audio-driven unsupervised zero- and first-order key-points motion. Then through exploring the motion model's properties, we further propose an Implicit Emotion Displacement Learner to represent emotion-related facial dynamics as linearly additive displacements to the previously acquired motion representations. Comprehensive experiments demonstrate that by incorporating the results from both modules, our method can generate satisfactory talking face results on arbitrary subjects with realistic emotion patterns.
A Survey of Fairness in Medical Image Analysis: Concepts, Algorithms, Evaluations, and Challenges
Sep 27, 2022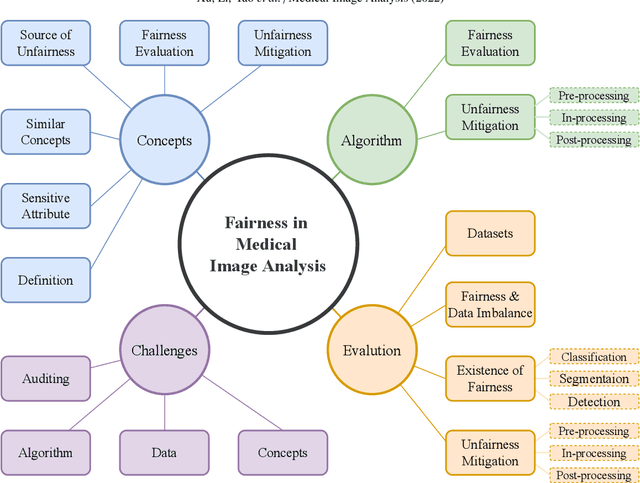

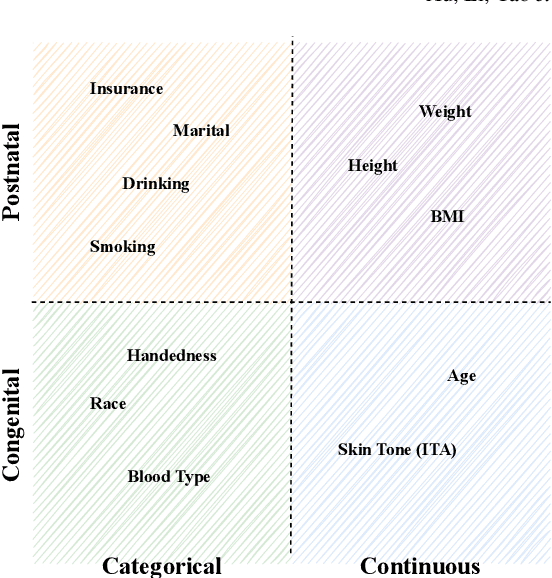
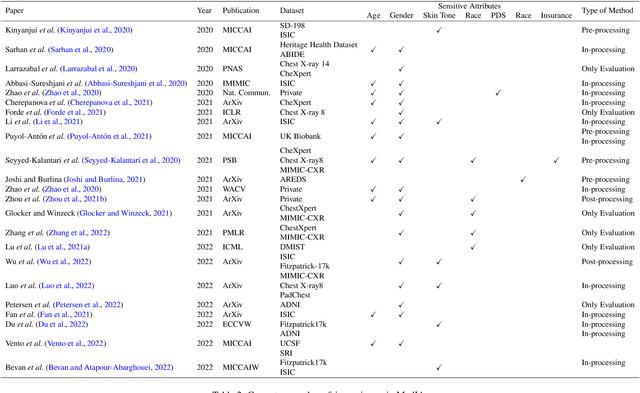
Fairness, a criterion focuses on evaluating algorithm performance on different demographic groups, has gained attention in natural language processing, recommendation system and facial recognition. Since there are plenty of demographic attributes in medical image samples, it is important to understand the concepts of fairness, be acquainted with unfairness mitigation techniques, evaluate fairness degree of an algorithm and recognize challenges in fairness issues in medical image analysis (MedIA). In this paper, we first give a comprehensive and precise definition of fairness, following by introducing currently used techniques in fairness issues in MedIA. After that, we list public medical image datasets that contain demographic attributes for facilitating the fairness research and summarize current algorithms concerning fairness in MedIA. To help achieve a better understanding of fairness, and call attention to fairness related issues in MedIA, experiments are conducted comparing the difference between fairness and data imbalance, verifying the existence of unfairness in various MedIA tasks, especially in classification, segmentation and detection, and evaluating the effectiveness of unfairness mitigation algorithms. Finally, we conclude with opportunities and challenges in fairness in MedIA.
Mesh-Tension Driven Expression-Based Wrinkles for Synthetic Faces
Oct 05, 2022
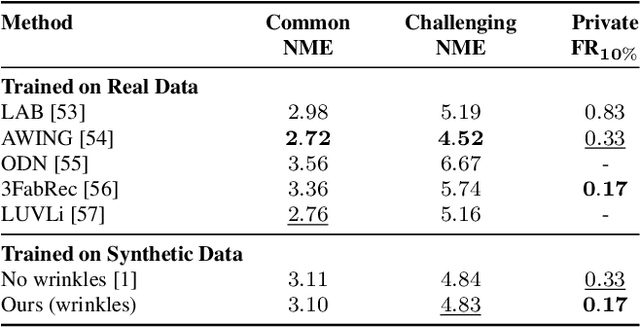

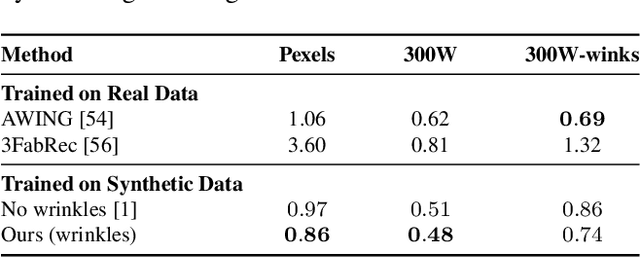
Recent advances in synthesizing realistic faces have shown that synthetic training data can replace real data for various face-related computer vision tasks. A question arises: how important is realism? Is the pursuit of photorealism excessive? In this work, we show otherwise. We boost the realism of our synthetic faces by introducing dynamic skin wrinkles in response to facial expressions and observe significant performance improvements in downstream computer vision tasks. Previous approaches for producing such wrinkles either required prohibitive artist effort to scale across identities and expressions or were not capable of reconstructing high-frequency skin details with sufficient fidelity. Our key contribution is an approach that produces realistic wrinkles across a large and diverse population of digital humans. Concretely, we formalize the concept of mesh-tension and use it to aggregate possible wrinkles from high-quality expression scans into albedo and displacement texture maps. At synthesis, we use these maps to produce wrinkles even for expressions not represented in the source scans. Additionally, to provide a more nuanced indicator of model performance under deformations resulting from compressed expressions, we introduce the 300W-winks evaluation subset and the Pexels dataset of closed eyes and winks.
Iterative Facial Image Inpainting using Cyclic Reverse Generator
Jan 18, 2021
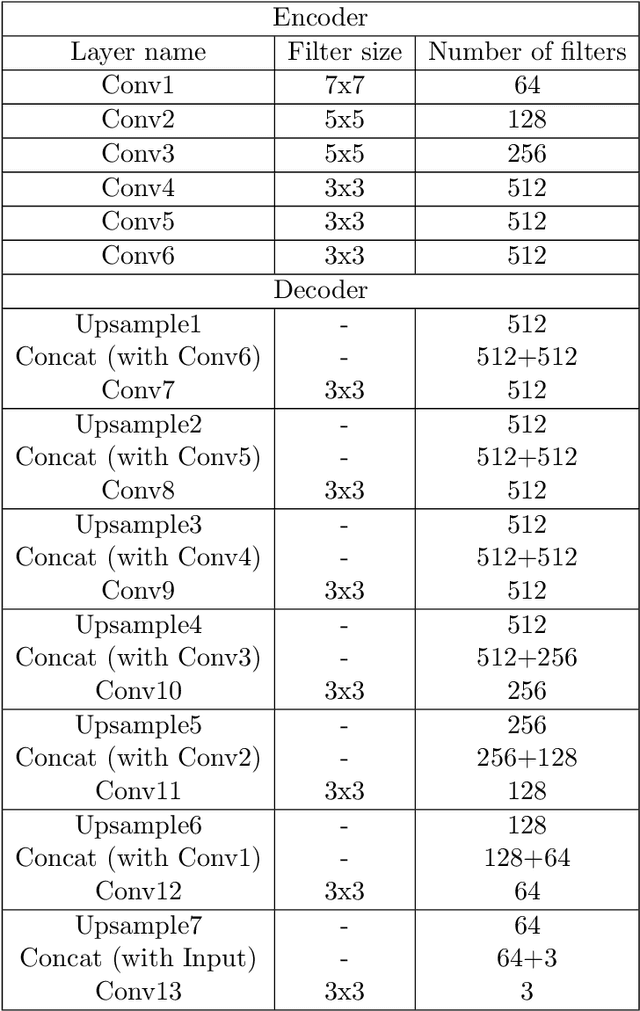
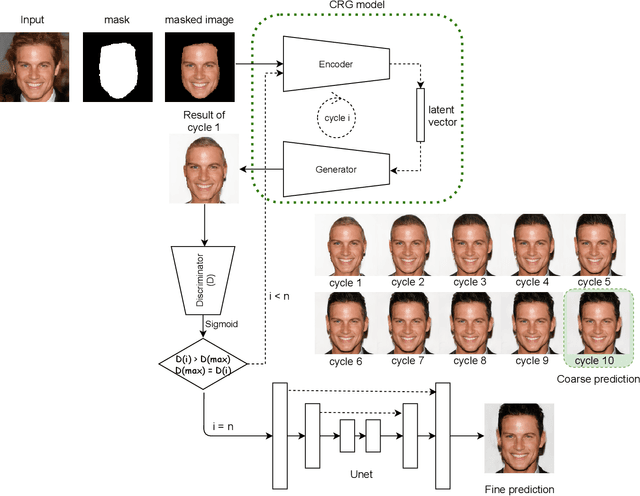

Facial image inpainting is a challenging problem as it requires generating new pixels that include semantic information for masked key components in a face, e.g., eyes and nose. Recently, remarkable methods have been proposed in this field. Most of these approaches use encoder-decoder architectures and have different limitations such as allowing unique results for a given image and a particular mask. Alternatively, some approaches generate promising results using different masks with generator networks. However, these approaches are optimization-based and usually require quite a number of iterations. In this paper, we propose an efficient solution to the facial image painting problem using the Cyclic Reverse Generator (CRG) architecture, which provides an encoder-generator model. We use the encoder to embed a given image to the generator space and incrementally inpaint the masked regions until a plausible image is generated; a discriminator network is utilized to assess the generated images during the iterations. We empirically observed that only a few iterations are sufficient to generate realistic images with the proposed model. After the generation process, for the post processing, we utilize a Unet model that we trained specifically for this task to remedy the artifacts close to the mask boundaries. Our method allows applying sketch-based inpaintings, using variety of mask types, and producing multiple and diverse results. We qualitatively compared our method with the state-of-the-art models and observed that our method can compete with the other models in all mask types; it is particularly better in images where larger masks are utilized.
Comparing Facial Expression Recognition in Humans and Machines: Using CAM, GradCAM, and Extremal Perturbation
Oct 09, 2021

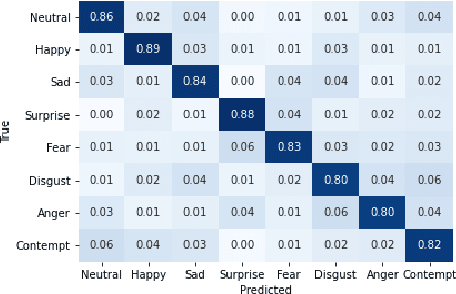
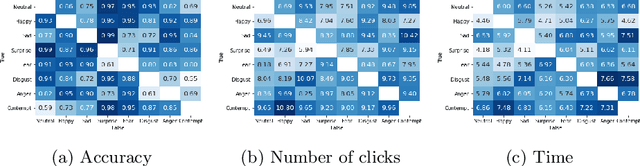
Facial expression recognition (FER) is a topic attracting significant research in both psychology and machine learning with a wide range of applications. Despite a wealth of research on human FER and considerable progress in computational FER made possible by deep neural networks (DNNs), comparatively less work has been done on comparing the degree to which DNNs may be comparable to human performance. In this work, we compared the recognition performance and attention patterns of humans and machines during a two-alternative forced-choice FER task. Human attention was here gathered through click data that progressively uncovered a face, whereas model attention was obtained using three different popular techniques from explainable AI: CAM, GradCAM and Extremal Perturbation. In both cases, performance was gathered as percent correct. For this task, we found that humans outperformed machines quite significantly. In terms of attention patterns, we found that Extremal Perturbation had the best overall fit with the human attention map during the task.