 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Region Based Adversarial Synthesis of Facial Action Units
Oct 23, 2019
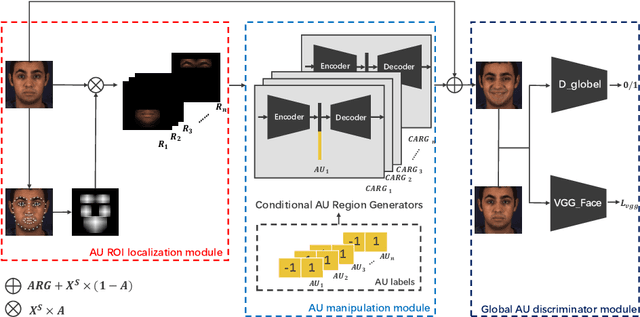
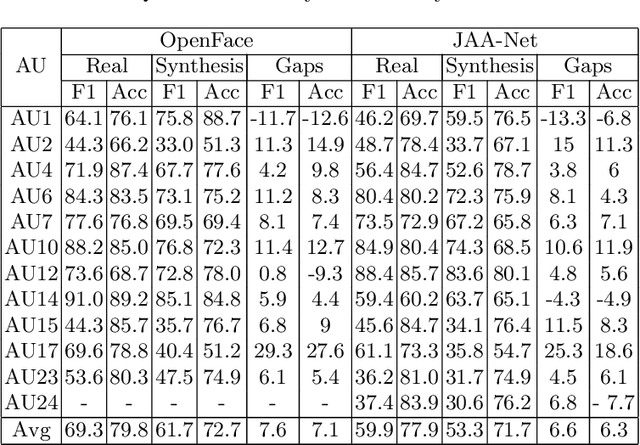
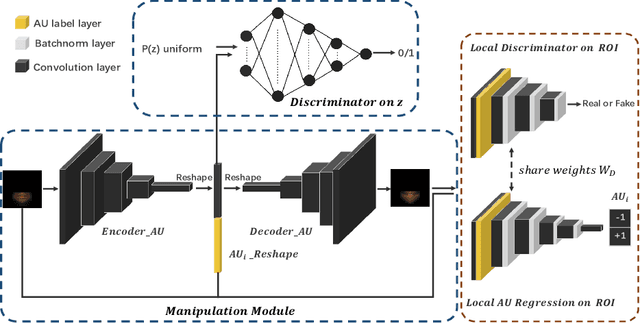
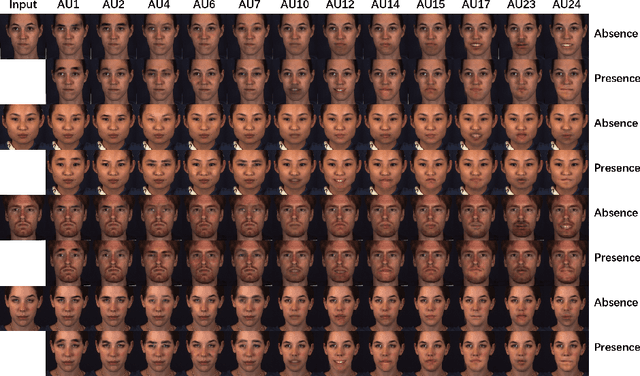
Facial expression synthesis or editing has recently received increasing attention in the field of affective computing and facial expression modeling. However, most existing facial expression synthesis works are limited in paired training data, low resolution, identity information damaging, and so on. To address those limitations, this paper introduces a novel Action Unit (AU) level facial expression synthesis method called Local Attentive Conditional Generative Adversarial Network (LAC-GAN) based on face action units annotations. Given desired AU labels, LAC-GAN utilizes local AU regional rules to control the status of each AU and attentive mechanism to combine several of them into the whole photo-realistic facial expressions or arbitrary facial expressions. In addition, unpaired training data is utilized in our proposed method to train the manipulation module with the corresponding AU labels, which learns a mapping between a facial expression manifold. Extensive qualitative and quantitative evaluations are conducted on the commonly used BP4D dataset to verify the effectiveness of our proposed AU synthesis method.
Identity-Sensitive Knowledge Propagation for Cloth-Changing Person Re-identification
Aug 25, 2022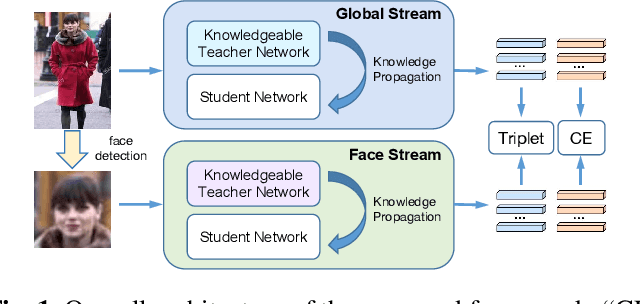
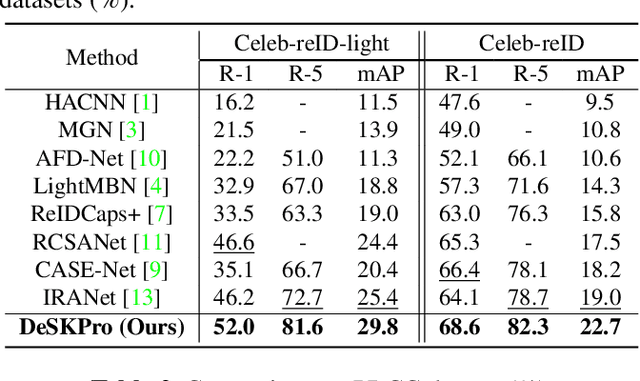
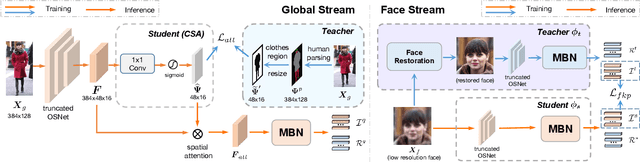
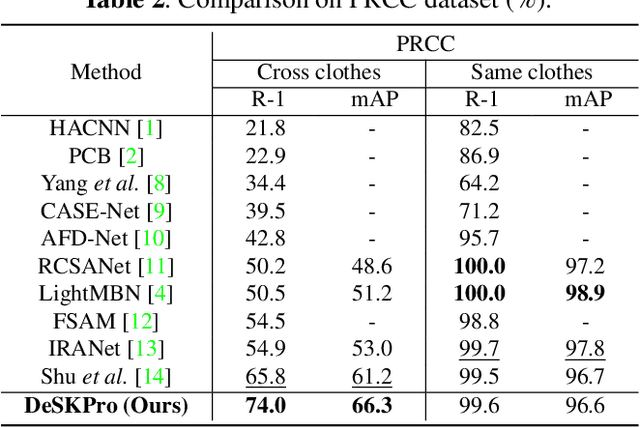
Cloth-changing person re-identification (CC-ReID), which aims to match person identities under clothing changes, is a new rising research topic in recent years. However, typical biometrics-based CC-ReID methods often require cumbersome pose or body part estimators to learn cloth-irrelevant features from human biometric traits, which comes with high computational costs. Besides, the performance is significantly limited due to the resolution degradation of surveillance images. To address the above limitations, we propose an effective Identity-Sensitive Knowledge Propagation framework (DeSKPro) for CC-ReID. Specifically, a Cloth-irrelevant Spatial Attention module is introduced to eliminate the distraction of clothing appearance by acquiring knowledge from the human parsing module. To mitigate the resolution degradation issue and mine identity-sensitive cues from human faces, we propose to restore the missing facial details using prior facial knowledge, which is then propagated to a smaller network. After training, the extra computations for human parsing or face restoration are no longer required. Extensive experiments show that our framework outperforms state-of-the-art methods by a large margin. Our code is available at https://github.com/KimbingNg/DeskPro.
Semantic Unfolding of StyleGAN Latent Space
Jun 29, 2022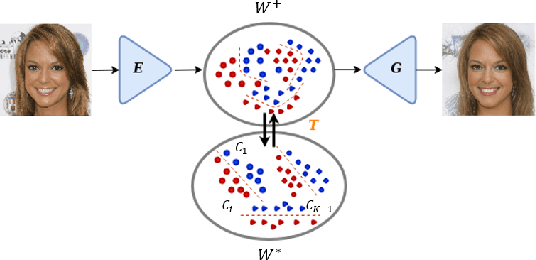
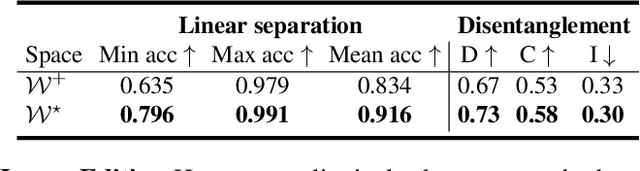

Generative adversarial networks (GANs) have proven to be surprisingly efficient for image editing by inverting and manipulating the latent code corresponding to an input real image. This editing property emerges from the disentangled nature of the latent space. In this paper, we identify that the facial attribute disentanglement is not optimal, thus facial editing relying on linear attribute separation is flawed. We thus propose to improve semantic disentanglement with supervision. Our method consists in learning a proxy latent representation using normalizing flows, and we show that this leads to a more efficient space for face image editing.
Accurate Facial Parts Localization and Deep Learning for 3D Facial Expression Recognition
Mar 04, 2018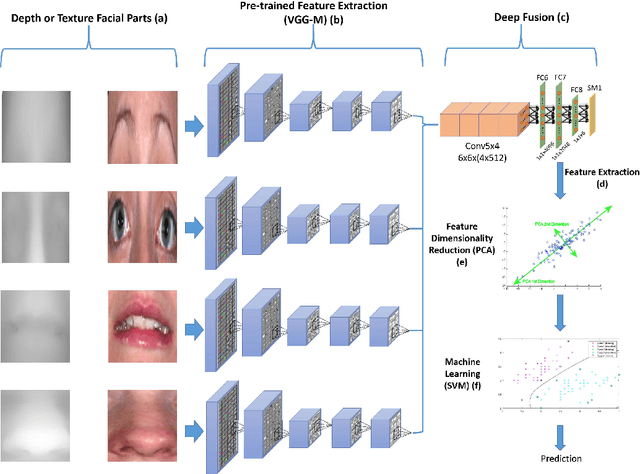

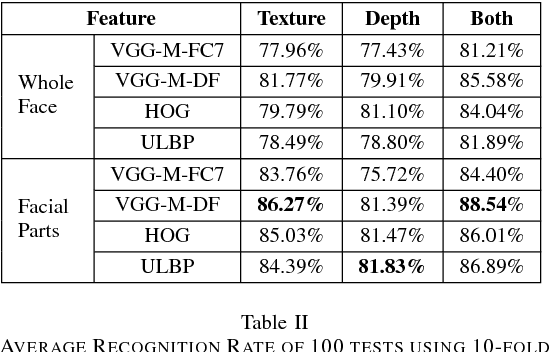
Meaningful facial parts can convey key cues for both facial action unit detection and expression prediction. Textured 3D face scan can provide both detailed 3D geometric shape and 2D texture appearance cues of the face which are beneficial for Facial Expression Recognition (FER). However, accurate facial parts extraction as well as their fusion are challenging tasks. In this paper, a novel system for 3D FER is designed based on accurate facial parts extraction and deep feature fusion of facial parts. In particular, each textured 3D face scan is firstly represented as a 2D texture map and a depth map with one-to-one dense correspondence. Then, the facial parts of both texture map and depth map are extracted using a novel 4-stage process consists of facial landmark localization, facial rotation correction, facial resizing, facial parts bounding box extraction and post-processing procedures. Finally, deep fusion Convolutional Neural Networks (CNNs) features of all facial parts are learned from both texture maps and depth maps, respectively and nonlinear SVMs are used for expression prediction. Experiments are conducted on the BU-3DFE database, demonstrating the effectiveness of combing different facial parts, texture and depth cues and reporting the state-of-the-art results in comparison with all existing methods under the same setting.
Multi-Spectral Facial Biometrics in Access Control
Jul 22, 2020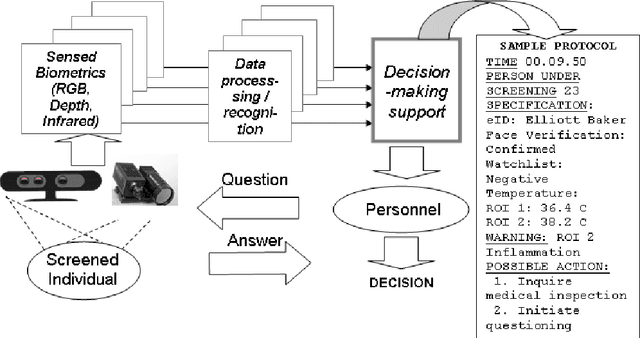

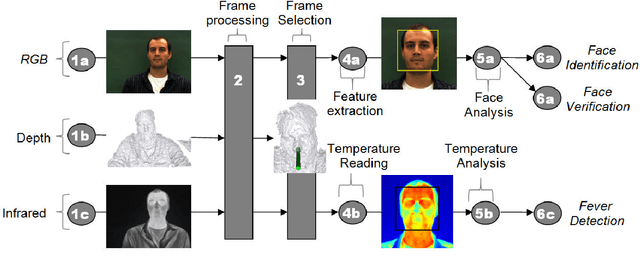
This study demonstrates how facial biometrics, acquired using multi-spectral sensors, such as RGB, depth, and infrared, assist the data accumulation in the process of authorizing users of automated and semi-automated access systems. This data serves the purposes of person authentication, as well as facial temperature estimation. We utilize depth data taken using an inexpensive RGB-D sensor to find the head pose of a subject. This allows the selection of video frames containing a frontal-view head pose for face recognition and face temperature reading. Usage of the frontal-view frames improves the efficiency of face recognition while the corresponding synchronized IR video frames allow for more efficient temperature estimation for facial regions of interest. In addition, this study reports emerging applications of biometrics in biomedical and health care solutions. Including surveys of recent pilot projects, involving new sensors of biometric data and new applications of human physiological and behavioral biometrics. It also shows the new and promising horizons of using biometrics in natural and contactless control interfaces for surgical control, rehabilitation and accessibility.
Learning to Amend Facial Expression Representation via De-albino and Affinity
Mar 18, 2021


Facial Expression Recognition (FER) is a classification task that points to face variants. Hence, there are certain intimate relationships between facial expressions. We call them affinity features, which are barely taken into account by current FER algorithms. Besides, to capture the edge information of the image, Convolutional Neural Networks (CNNs) generally utilize a host of edge paddings. Although they are desirable, the feature map is deeply eroded after multi-layer convolution. We name what has formed in this process the albino features, which definitely weaken the representation of the expression. To tackle these challenges, we propose a novel architecture named Amend Representation Module (ARM). ARM is a substitute for the pooling layer. Theoretically, it could be embedded in any CNN with a pooling layer. ARM efficiently enhances facial expression representation from two different directions: 1) reducing the weight of eroded features to offset the side effect of padding, and 2) sharing affinity features over mini-batch to strengthen the representation learning. In terms of data imbalance, we designed a minimal random resampling (MRR) scheme to suppress network overfitting. Experiments on public benchmarks prove that our ARM boosts the performance of FER remarkably. The validation accuracies are respectively 90.55% on RAF-DB, 64.49% on Affect-Net, and 71.38% on FER2013, exceeding current state-of-the-art methods.
Facial Expression Restoration Based on Improved Graph Convolutional Networks
Oct 23, 2019
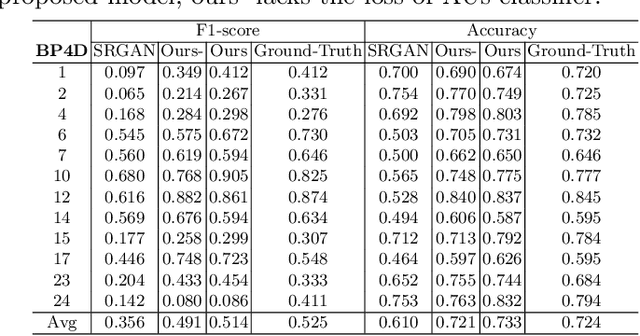
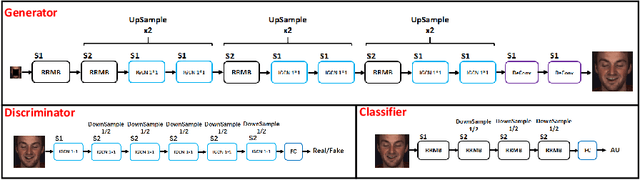
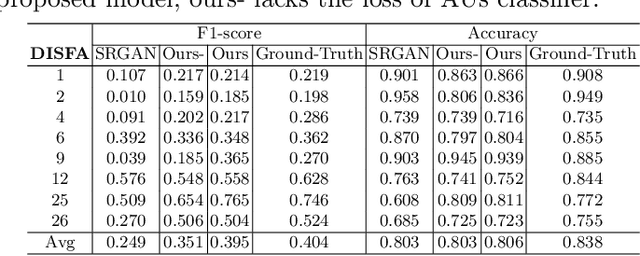
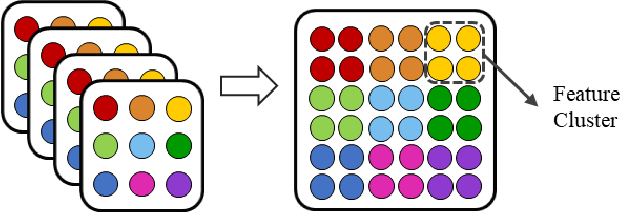
Facial expression analysis in the wild is challenging when the facial image is with low resolution or partial occlusion. Considering the correlations among different facial local regions under different facial expressions, this paper proposes a novel facial expression restoration method based on generative adversarial network by integrating an improved graph convolutional network (IGCN) and region relation modeling block (RRMB). Unlike conventional graph convolutional networks taking vectors as input features, IGCN can use tensors of face patches as inputs. It is better to retain the structure information of face patches. The proposed RRMB is designed to address facial generative tasks including inpainting and super-resolution with facial action units detection, which aims to restore facial expression as the ground-truth. Extensive experiments conducted on BP4D and DISFA benchmarks demonstrate the effectiveness of our proposed method through quantitative and qualitative evaluations.
SD-GAN: Semantic Decomposition for Face Image Synthesis with Discrete Attribute
Jul 12, 2022
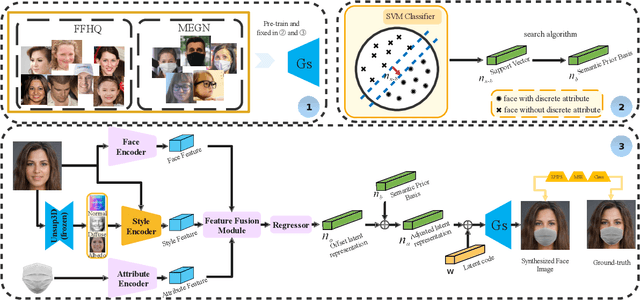
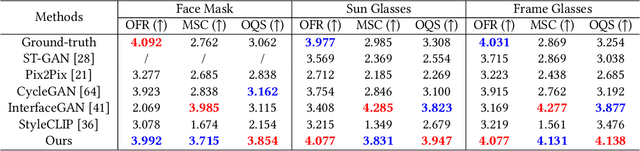
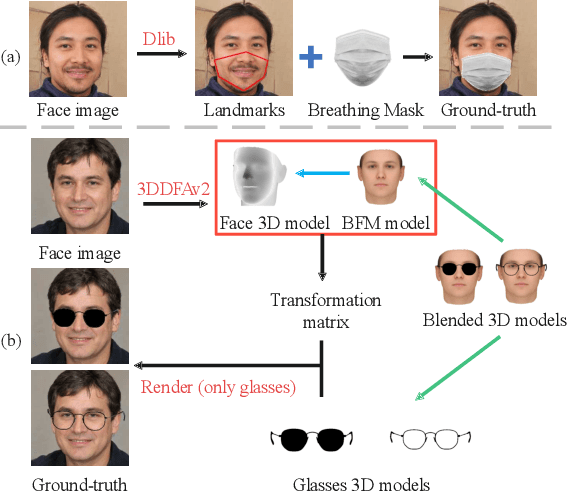
Manipulating latent code in generative adversarial networks (GANs) for facial image synthesis mainly focuses on continuous attribute synthesis (e.g., age, pose and emotion), while discrete attribute synthesis (like face mask and eyeglasses) receives less attention. Directly applying existing works to facial discrete attributes may cause inaccurate results. In this work, we propose an innovative framework to tackle challenging facial discrete attribute synthesis via semantic decomposing, dubbed SD-GAN. To be concrete, we explicitly decompose the discrete attribute representation into two components, i.e. the semantic prior basis and offset latent representation. The semantic prior basis shows an initializing direction for manipulating face representation in the latent space. The offset latent presentation obtained by 3D-aware semantic fusion network is proposed to adjust prior basis. In addition, the fusion network integrates 3D embedding for better identity preservation and discrete attribute synthesis. The combination of prior basis and offset latent representation enable our method to synthesize photo-realistic face images with discrete attributes. Notably, we construct a large and valuable dataset MEGN (Face Mask and Eyeglasses images crawled from Google and Naver) for completing the lack of discrete attributes in the existing dataset. Extensive qualitative and quantitative experiments demonstrate the state-of-the-art performance of our method. Our code is available at: https://github.com/MontaEllis/SD-GAN.
Generative Adversarial Stacked Autoencoders for Facial Pose Normalization and Emotion Recognition
Jul 19, 2020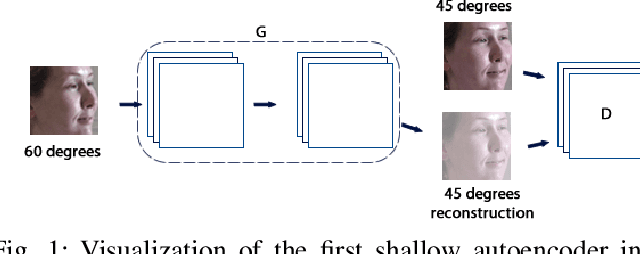
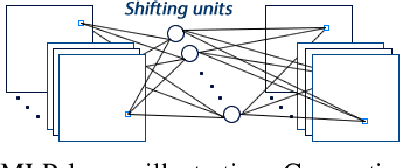

In this work, we propose a novel Generative Adversarial Stacked Autoencoder that learns to map facial expressions, with up to plus or minus 60 degrees, to an illumination invariant facial representation of 0 degrees. We accomplish this by using a novel convolutional layer that exploits both local and global spatial information, and a convolutional layer with a reduced number of parameters that exploits facial symmetry. Furthermore, we introduce a generative adversarial gradual greedy layer-wise learning algorithm designed to train Adversarial Autoencoders in an efficient and incremental manner. We demonstrate the efficiency of our method and report state-of-the-art performance on several facial emotion recognition corpora, including one collected in the wild.
Fantômas: Evaluating Reversibility of Face Anonymizations Using a General Deep Learning Attacker
Oct 19, 2022


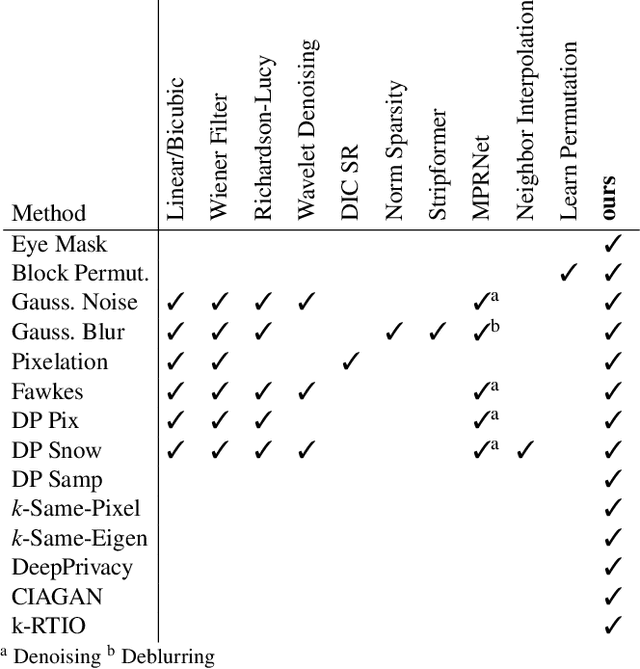
Biometric data is a rich source of information that can be used to identify individuals and infer private information about them. To mitigate this privacy risk, anonymization techniques employ transformations on clear data to obfuscate sensitive information, all while retaining some utility of the data. Albeit published with impressive claims, they sometimes are not evaluated with convincing methodology. We hence are interested to which extent recently suggested anonymization techniques for obfuscating facial images are effective. More specifically, we test how easily they can be automatically reverted, to estimate the privacy they can provide. Our approach is agnostic to the anonymization technique as we learn a machine learning model on the clear and corresponding anonymized data. We find that 10 out of 14 tested face anonymization techniques are at least partially reversible, and six of them are at least highly reversible.