 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Subspace Generation for Outlier Detection in High-Dimensional Data
Apr 10, 2025



Outlier detection in high-dimensional tabular data is challenging since data is often distributed across multiple lower-dimensional subspaces -- a phenomenon known as the Multiple Views effect (MV). This effect led to a large body of research focused on mining such subspaces, known as subspace selection. However, as the precise nature of the MV effect was not well understood, traditional methods had to rely on heuristic-driven search schemes that struggle to accurately capture the true structure of the data. Properly identifying these subspaces is critical for unsupervised tasks such as outlier detection or clustering, where misrepresenting the underlying data structure can hinder the performance. We introduce Myopic Subspace Theory (MST), a new theoretical framework that mathematically formulates the Multiple Views effect and writes subspace selection as a stochastic optimization problem. Based on MST, we introduce V-GAN, a generative method trained to solve such an optimization problem. This approach avoids any exhaustive search over the feature space while ensuring that the intrinsic data structure is preserved. Experiments on 42 real-world datasets show that using V-GAN subspaces to build ensemble methods leads to a significant increase in one-class classification performance -- compared to existing subspace selection, feature selection, and embedding methods. Further experiments on synthetic data show that V-GAN identifies subspaces more accurately while scaling better than other relevant subspace selection methods. These results confirm the theoretical guarantees of our approach and also highlight its practical viability in high-dimensional settings.
R+R:Understanding Hyperparameter Effects in DP-SGD
Nov 04, 2024



Research on the effects of essential hyperparameters of DP-SGD lacks consensus, verification, and replication. Contradictory and anecdotal statements on their influence make matters worse. While DP-SGD is the standard optimization algorithm for privacy-preserving machine learning, its adoption is still commonly challenged by low performance compared to non-private learning approaches. As proper hyperparameter settings can improve the privacy-utility trade-off, understanding the influence of the hyperparameters promises to simplify their optimization towards better performance, and likely foster acceptance of private learning. To shed more light on these influences, we conduct a replication study: We synthesize extant research on hyperparameter influences of DP-SGD into conjectures, conduct a dedicated factorial study to independently identify hyperparameter effects, and assess which conjectures can be replicated across multiple datasets, model architectures, and differential privacy budgets. While we cannot (consistently) replicate conjectures about the main and interaction effects of the batch size and the number of epochs, we were able to replicate the conjectured relationship between the clipping threshold and learning rate. Furthermore, we were able to quantify the significant importance of their combination compared to the other hyperparameters.
SEBA: Strong Evaluation of Biometric Anonymizations
Jul 09, 2024



Biometric data is pervasively captured and analyzed. Using modern machine learning approaches, identity and attribute inferences attacks have proven high accuracy. Anonymizations aim to mitigate such disclosures by modifying data in a way that prevents identification. However, the effectiveness of some anonymizations is unclear. Therefore, improvements of the corresponding evaluation methodology have been proposed recently. In this paper, we introduce SEBA, a framework for strong evaluation of biometric anonymizations. It combines and implements the state-of-the-art methodology in an easy-to-use and easy-to-expand software framework. This allows anonymization designers to easily test their techniques using a strong evaluation methodology. As part of this discourse, we introduce and discuss new metrics that allow for a more straightforward evaluation of the privacy-utility trade-off that is inherent to anonymization attempts. Finally, we report on a prototypical experiment to demonstrate SEBA's applicability.
Fantômas: Evaluating Reversibility of Face Anonymizations Using a General Deep Learning Attacker
Oct 19, 2022


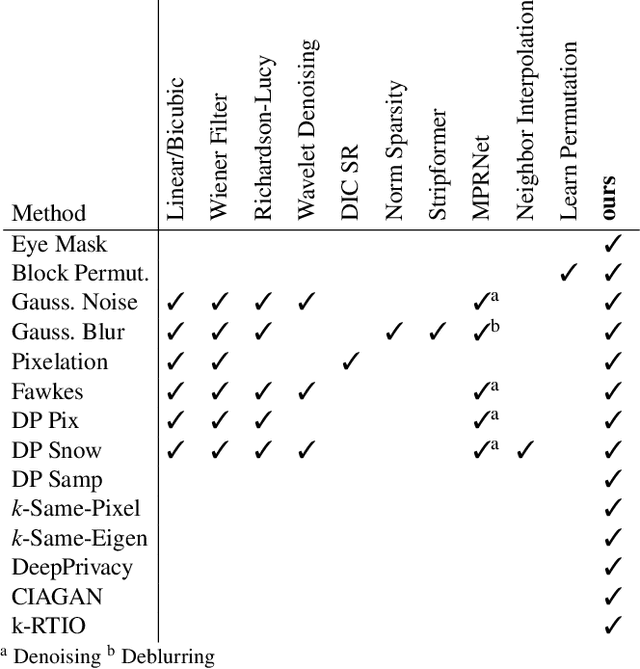
Biometric data is a rich source of information that can be used to identify individuals and infer private information about them. To mitigate this privacy risk, anonymization techniques employ transformations on clear data to obfuscate sensitive information, all while retaining some utility of the data. Albeit published with impressive claims, they sometimes are not evaluated with convincing methodology. We hence are interested to which extent recently suggested anonymization techniques for obfuscating facial images are effective. More specifically, we test how easily they can be automatically reverted, to estimate the privacy they can provide. Our approach is agnostic to the anonymization technique as we learn a machine learning model on the clear and corresponding anonymized data. We find that 10 out of 14 tested face anonymization techniques are at least partially reversible, and six of them are at least highly reversible.
Understanding person identification via gait
Mar 09, 2022
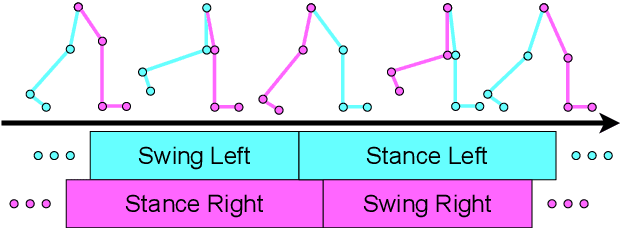
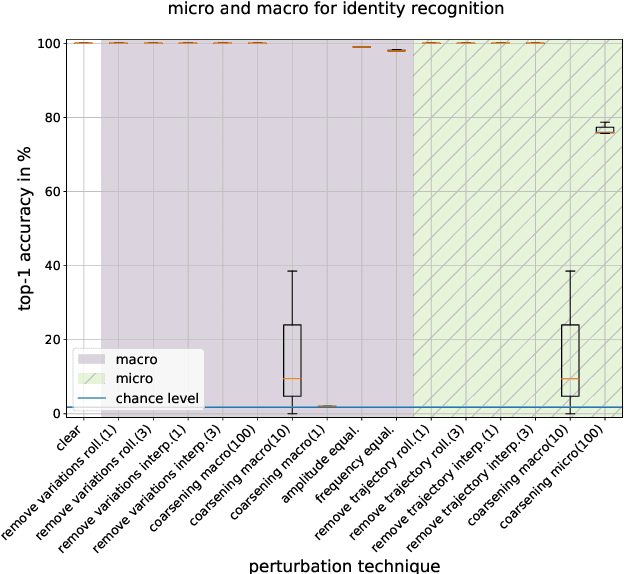
Gait recognition is the process of identifying humans from their bipedal locomotion such as walking or running. As such gait data is privacy sensitive information and should be anonymized. With the rise of more and higher quality gait recording techniques, such as depth cameras or motion capture suits, an increasing amount of high-quality gait data becomes available which requires anonymization. As a first step towards developing anonymization techniques for high-quality gait data, we study different aspects of movement data to quantify their contribution to the gait recognition process. We first extract categories of features from the literature on human gait perception and then design computational experiments for each of the categories which we run against a gait recognition system. Our results show that gait anonymization is a challenging process as the data is highly redundant and interdependent.
On the privacy-utility trade-off in differentially private hierarchical text classification
Mar 04, 2021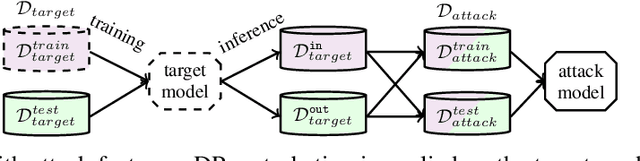
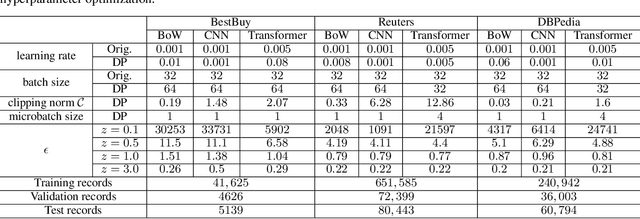
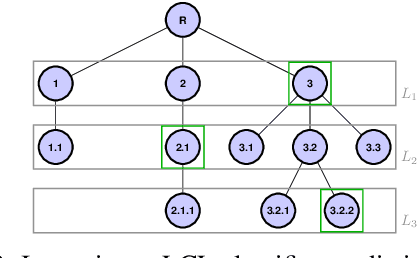
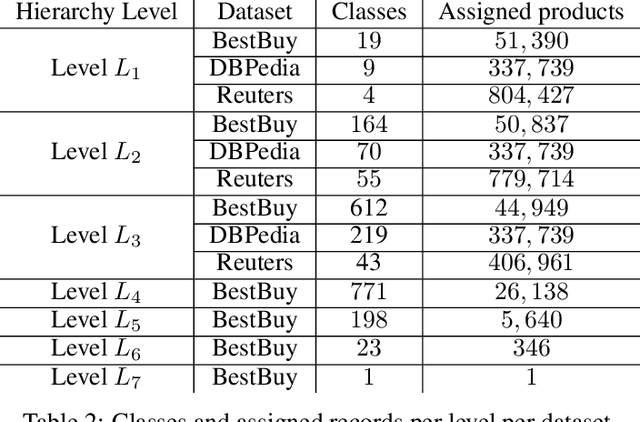
Hierarchical models for text classification can leak sensitive or confidential training data information to adversaries due to training data memorization. Using differential privacy during model training can mitigate leakage attacks against trained models by perturbing the training optimizer. However, for hierarchical text classification a multiplicity of model architectures is available and it is unclear whether some architectures yield a better trade-off between remaining model accuracy and model leakage under differentially private training perturbation than others. We use a white-box membership inference attack to assess the information leakage of three widely used neural network architectures for hierarchical text classification under differential privacy. We show that relatively weak differential privacy guarantees already suffice to completely mitigate the membership inference attack, thus resulting only in a moderate decrease in utility. More specifically, for large datasets with long texts we observed transformer-based models to achieve an overall favorable privacy-utility trade-off, while for smaller datasets with shorter texts CNNs are preferable.
Infinite Mixture Model of Markov Chains
Jun 19, 2017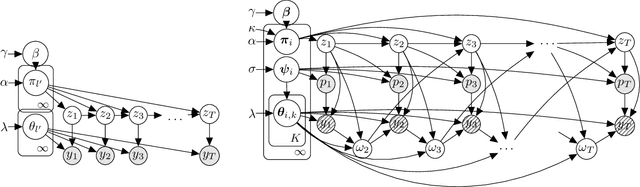
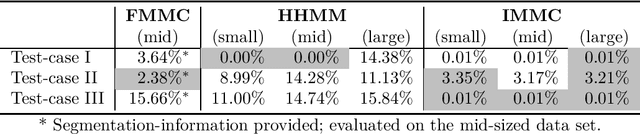
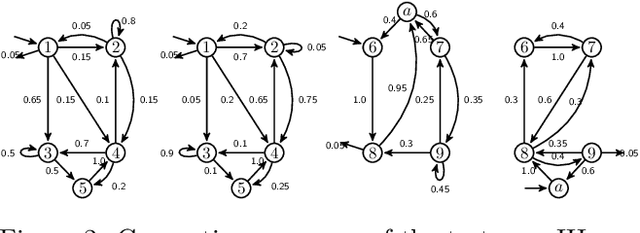

We propose a Bayesian nonparametric mixture model for prediction- and information extraction tasks with an efficient inference scheme. It models categorical-valued time series that exhibit dynamics from multiple underlying patterns (e.g. user behavior traces). We simplify the idea of capturing these patterns by hierarchical hidden Markov models (HHMMs) - and extend the existing approaches by the additional representation of structural information. Our empirical results are based on both synthetic- and real world data. They indicate that the results are easily interpretable, and that the model excels at segmentation and prediction performance: it successfully identifies the generating patterns and can be used for effective prediction of future observations.