 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Child Face Recognition at Scale: Synthetic Data Generation and Performance Benchmark
Apr 23, 2023
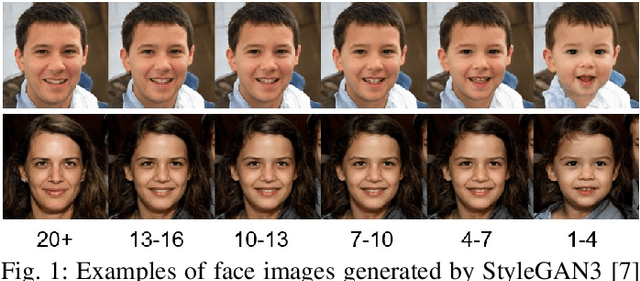


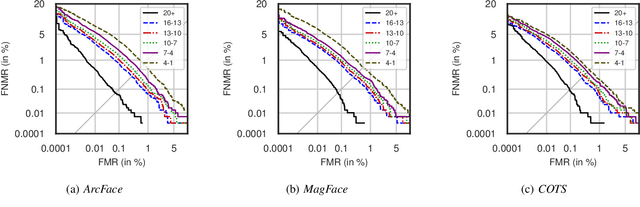
We address the need for a large-scale database of children's faces by using generative adversarial networks (GANs) and face age progression (FAP) models to synthesize a realistic dataset referred to as HDA-SynChildFaces. To this end, we proposed a processing pipeline that initially utilizes StyleGAN3 to sample adult subjects, which are subsequently progressed to children of varying ages using InterFaceGAN. Intra-subject variations, such as facial expression and pose, are created by further manipulating the subjects in their latent space. Additionally, the presented pipeline allows to evenly distribute the races of subjects, allowing to generate a balanced and fair dataset with respect to race distribution. The created HDA-SynChildFaces consists of 1,652 subjects and a total of 188,832 images, each subject being present at various ages and with many different intra-subject variations. Subsequently, we evaluates the performance of various facial recognition systems on the generated database and compare the results of adults and children at different ages. The study reveals that children consistently perform worse than adults, on all tested systems, and the degradation in performance is proportional to age. Additionally, our study uncovers some biases in the recognition systems, with Asian and Black subjects and females performing worse than White and Latino Hispanic subjects and males.
GREAT Score: Global Robustness Evaluation of Adversarial Perturbation using Generative Models
May 03, 2023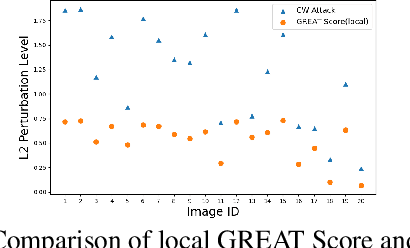
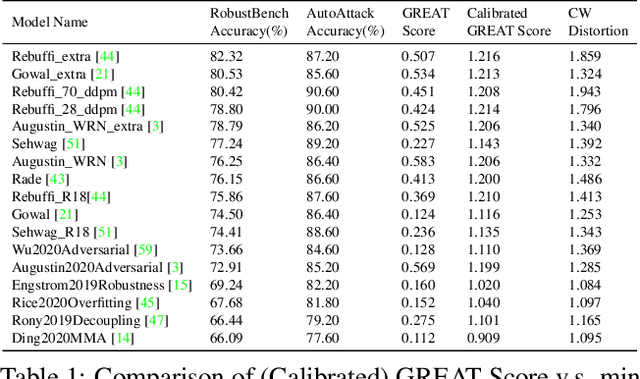
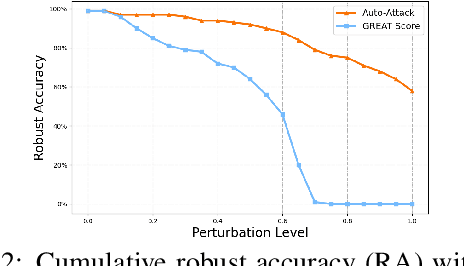
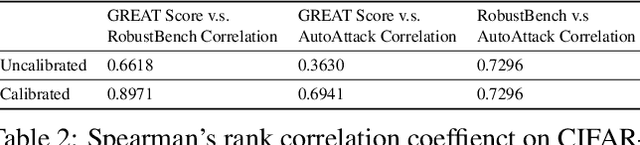
Current studies on adversarial robustness mainly focus on aggregating local robustness results from a set of data samples to evaluate and rank different models. However, the local statistics may not well represent the true global robustness of the underlying unknown data distribution. To address this challenge, this paper makes the first attempt to present a new framework, called GREAT Score , for global robustness evaluation of adversarial perturbation using generative models. Formally, GREAT Score carries the physical meaning of a global statistic capturing a mean certified attack-proof perturbation level over all samples drawn from a generative model. For finite-sample evaluation, we also derive a probabilistic guarantee on the sample complexity and the difference between the sample mean and the true mean. GREAT Score has several advantages: (1) Robustness evaluations using GREAT Score are efficient and scalable to large models, by sparing the need of running adversarial attacks. In particular, we show high correlation and significantly reduced computation cost of GREAT Score when compared to the attack-based model ranking on RobustBench (Croce,et. al. 2021). (2) The use of generative models facilitates the approximation of the unknown data distribution. In our ablation study with different generative adversarial networks (GANs), we observe consistency between global robustness evaluation and the quality of GANs. (3) GREAT Score can be used for remote auditing of privacy-sensitive black-box models, as demonstrated by our robustness evaluation on several online facial recognition services.
FaceTopoNet: Facial Expression Recognition using Face Topology Learning
Sep 13, 2022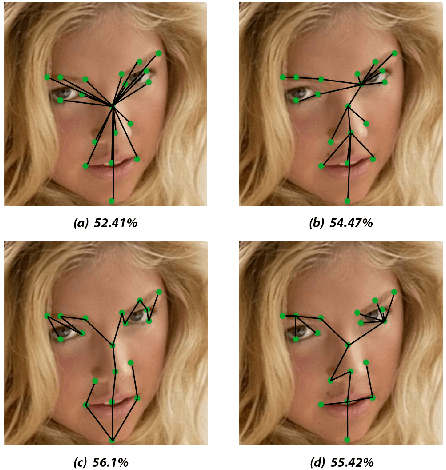

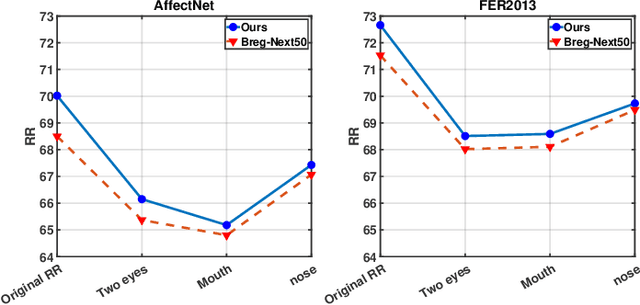
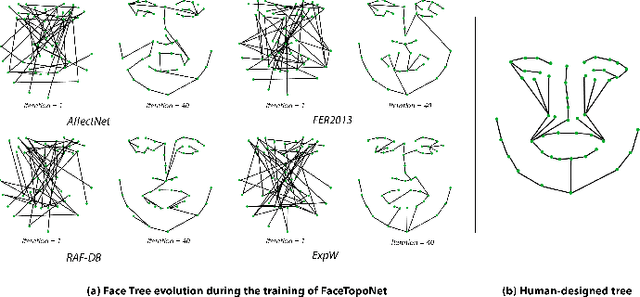
Prior work has shown that the order in which different components of the face are learned using a sequential learner can play an important role in the performance of facial expression recognition systems. We propose FaceTopoNet, an end-to-end deep model for facial expression recognition, which is capable of learning an effective tree topology of the face. Our model then traverses the learned tree to generate a sequence, which is then used to form an embedding to feed a sequential learner. The devised model adopts one stream for learning structure and one stream for learning texture. The structure stream focuses on the positions of the facial landmarks, while the main focus of the texture stream is on the patches around the landmarks to learn textural information. We then fuse the outputs of the two streams by utilizing an effective attention-based fusion strategy. We perform extensive experiments on four large-scale in-the-wild facial expression datasets - namely AffectNet, FER2013, ExpW, and RAF-DB - and one lab-controlled dataset (CK+) to evaluate our approach. FaceTopoNet achieves state-of-the-art performance on three of the five datasets and obtains competitive results on the other two datasets. We also perform rigorous ablation and sensitivity experiments to evaluate the impact of different components and parameters in our model. Lastly, we perform robustness experiments and demonstrate that FaceTopoNet is more robust against occlusions in comparison to other leading methods in the area.
On Developing Facial Stress Analysis and Expression Recognition Platform
Sep 16, 2022

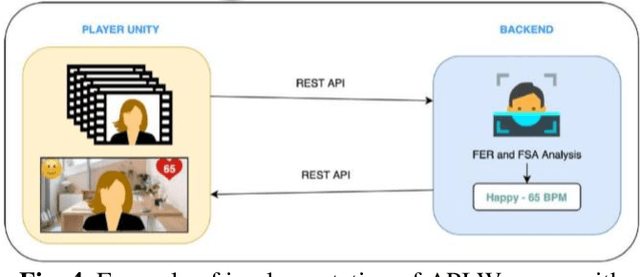
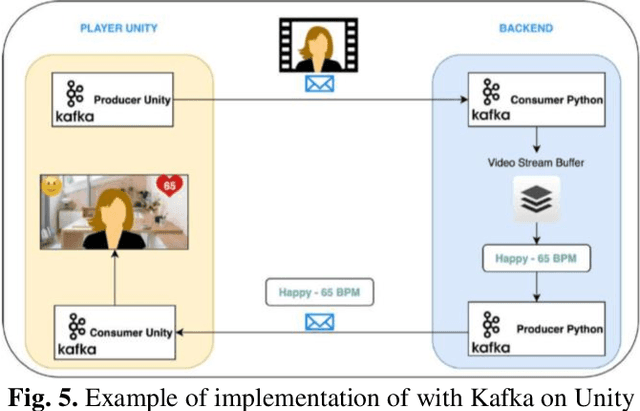
This work represents the experimental and development process of system facial expression recognition and facial stress analysis algorithms for an immersive digital learning platform. The system retrieves from users web camera and evaluates it using artificial neural network (ANN) algorithms. The ANN output signals can be used to score and improve the learning process. Adapting an ANN to a new system can require a significant implementation effort or the need to repeat the ANN training. There are also limitations related to the minimum hardware required to run an ANN. To overpass these constraints, some possible implementations of facial expression recognition and facial stress analysis algorithms in real-time systems are presented. The implementation of the new solution has made it possible to improve the accuracy in the recognition of facial expressions and also to increase their response speed. Experimental results showed that using the developed algorithms allow to detect the heart rate with better rate in comparison with social equipment.
Sparsifying Bayesian neural networks with latent binary variables and normalizing flows
May 05, 2023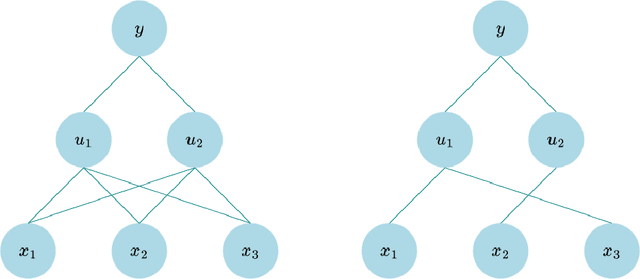
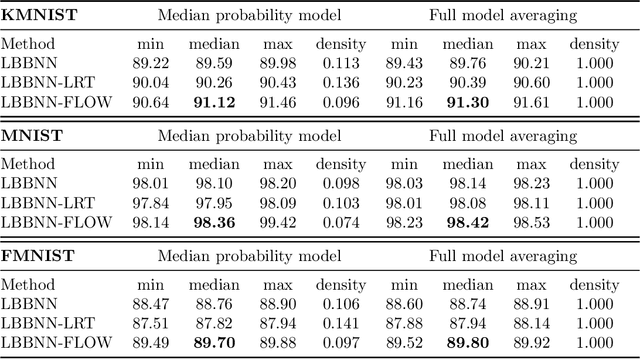
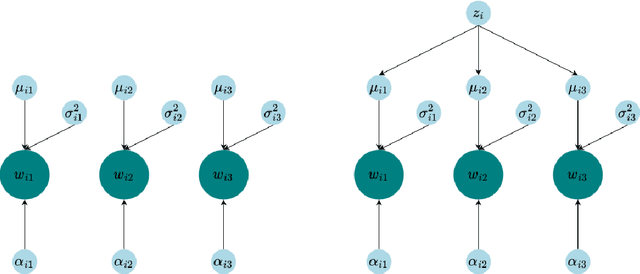
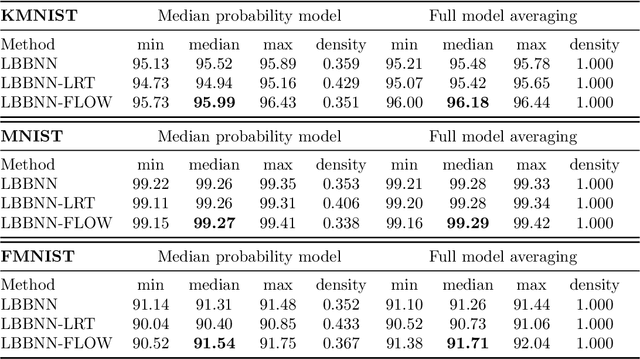
Artificial neural networks (ANNs) are powerful machine learning methods used in many modern applications such as facial recognition, machine translation, and cancer diagnostics. A common issue with ANNs is that they usually have millions or billions of trainable parameters, and therefore tend to overfit to the training data. This is especially problematic in applications where it is important to have reliable uncertainty estimates. Bayesian neural networks (BNN) can improve on this, since they incorporate parameter uncertainty. In addition, latent binary Bayesian neural networks (LBBNN) also take into account structural uncertainty by allowing the weights to be turned on or off, enabling inference in the joint space of weights and structures. In this paper, we will consider two extensions to the LBBNN method: Firstly, by using the local reparametrization trick (LRT) to sample the hidden units directly, we get a more computationally efficient algorithm. More importantly, by using normalizing flows on the variational posterior distribution of the LBBNN parameters, the network learns a more flexible variational posterior distribution than the mean field Gaussian. Experimental results show that this improves predictive power compared to the LBBNN method, while also obtaining more sparse networks. We perform two simulation studies. In the first study, we consider variable selection in a logistic regression setting, where the more flexible variational distribution leads to improved results. In the second study, we compare predictive uncertainty based on data generated from two-dimensional Gaussian distributions. Here, we argue that our Bayesian methods lead to more realistic estimates of predictive uncertainty.
A 3D GAN for Improved Large-pose Facial Recognition
Dec 18, 2020
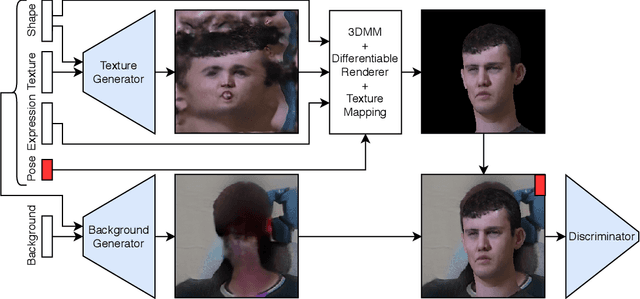
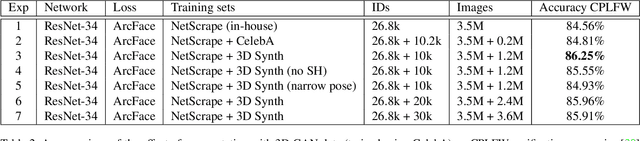
Facial recognition using deep convolutional neural networks relies on the availability of large datasets of face images. Many examples of identities are needed, and for each identity, a large variety of images are needed in order for the network to learn robustness to intra-class variation. In practice, such datasets are difficult to obtain, particularly those containing adequate variation of pose. Generative Adversarial Networks (GANs) provide a potential solution to this problem due to their ability to generate realistic, synthetic images. However, recent studies have shown that current methods of disentangling pose from identity are inadequate. In this work we incorporate a 3D morphable model into the generator of a GAN in order to learn a nonlinear texture model from in-the-wild images. This allows generation of new, synthetic identities, and manipulation of pose and expression without compromising the identity. Our synthesised data is used to augment training of facial recognition networks with performance evaluated on the challenging CFPW and Cross-Pose LFW datasets.
Facial Expression Recognition with Swin Transformer
Mar 25, 2022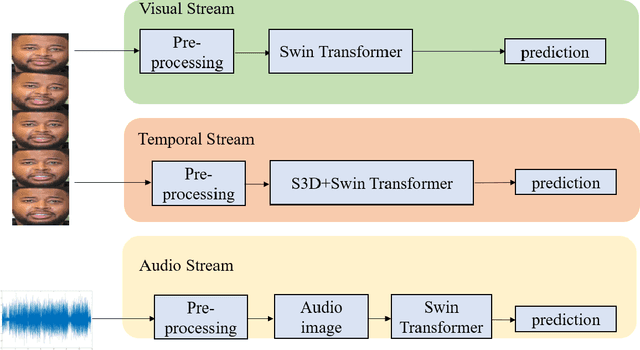
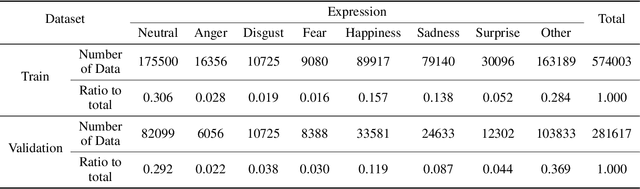

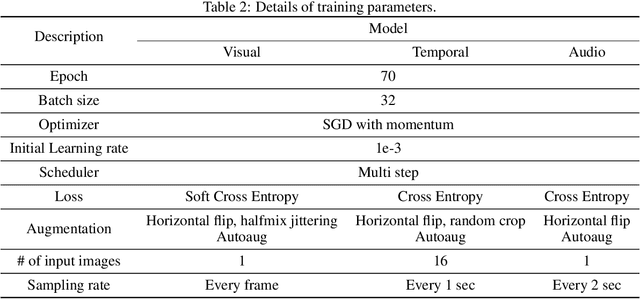
The task of recognizing human facial expressions plays a vital role in various human-related systems, including health care and medical fields. With the recent success of deep learning and the accessibility of a large amount of annotated data, facial expression recognition research has been mature enough to be utilized in real-world scenarios with audio-visual datasets. In this paper, we introduce Swin transformer-based facial expression approach for an in-the-wild audio-visual dataset of the Aff-Wild2 Expression dataset. Specifically, we employ a three-stream network (i.e., Visual stream, Temporal stream, and Audio stream) for the audio-visual videos to fuse the multi-modal information into facial expression recognition. Experimental results on the Aff-Wild2 dataset show the effectiveness of our proposed multi-modal approaches.
Neural Approaches to Entity-Centric Information Extraction
Apr 15, 2023

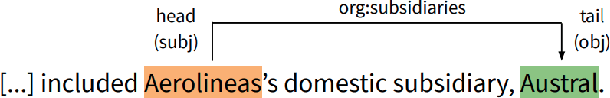
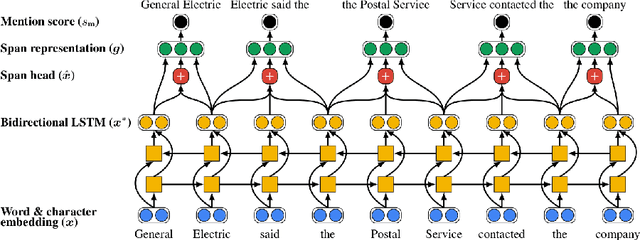
Artificial Intelligence (AI) has huge impact on our daily lives with applications such as voice assistants, facial recognition, chatbots, autonomously driving cars, etc. Natural Language Processing (NLP) is a cross-discipline of AI and Linguistics, dedicated to study the understanding of the text. This is a very challenging area due to unstructured nature of the language, with many ambiguous and corner cases. In this thesis we address a very specific area of NLP that involves the understanding of entities (e.g., names of people, organizations, locations) in text. First, we introduce a radically different, entity-centric view of the information in text. We argue that instead of using individual mentions in text to understand their meaning, we should build applications that would work in terms of entity concepts. Next, we present a more detailed model on how the entity-centric approach can be used for the entity linking task. In our work, we show that this task can be improved by considering performing entity linking at the coreference cluster level rather than each of the mentions individually. In our next work, we further study how information from Knowledge Base entities can be integrated into text. Finally, we analyze the evolution of the entities from the evolving temporal perspective.
LowKey: Leveraging Adversarial Attacks to Protect Social Media Users from Facial Recognition
Jan 25, 2021

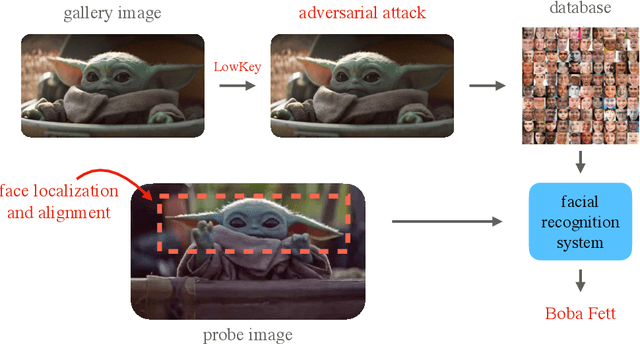
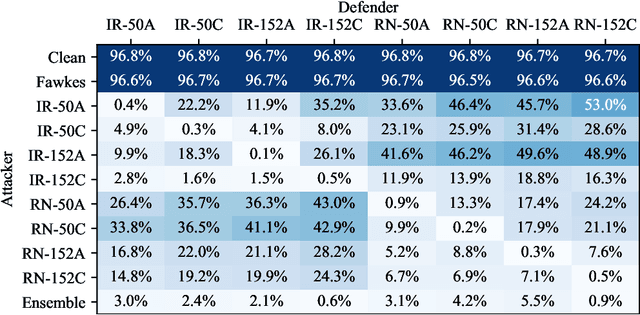
Facial recognition systems are increasingly deployed by private corporations, government agencies, and contractors for consumer services and mass surveillance programs alike. These systems are typically built by scraping social media profiles for user images. Adversarial perturbations have been proposed for bypassing facial recognition systems. However, existing methods fail on full-scale systems and commercial APIs. We develop our own adversarial filter that accounts for the entire image processing pipeline and is demonstrably effective against industrial-grade pipelines that include face detection and large scale databases. Additionally, we release an easy-to-use webtool that significantly degrades the accuracy of Amazon Rekognition and the Microsoft Azure Face Recognition API, reducing the accuracy of each to below 1%.
Intensity-Aware Loss for Dynamic Facial Expression Recognition in the Wild
Aug 19, 2022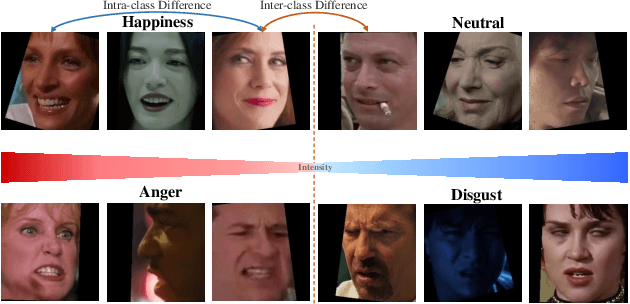
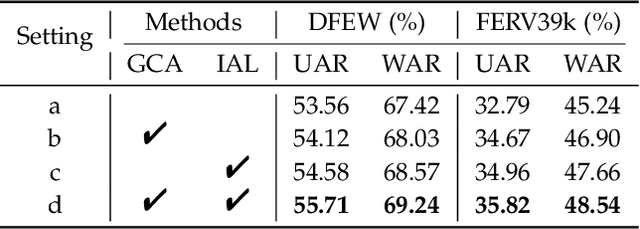
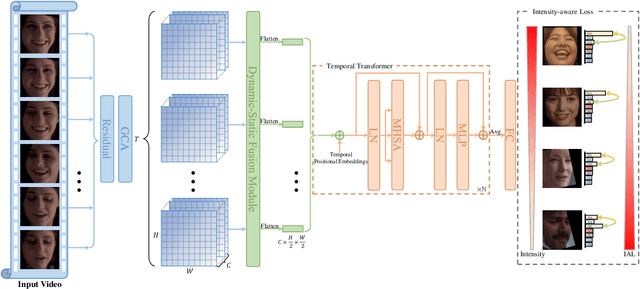
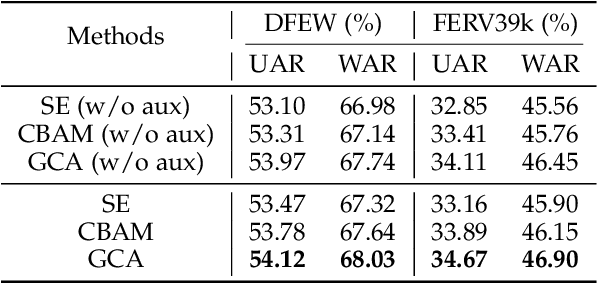
Compared with the image-based static facial expression recognition (SFER) task, the dynamic facial expression recognition (DFER) task based on video sequences is closer to the natural expression recognition scene. However, DFER is often more challenging. One of the main reasons is that video sequences often contain frames with different expression intensities, especially for the facial expressions in the real-world scenarios, while the images in SFER frequently present uniform and high expression intensities. However, if the expressions with different intensities are treated equally, the features learned by the networks will have large intra-class and small inter-class differences, which is harmful to DFER. To tackle this problem, we propose the global convolution-attention block (GCA) to rescale the channels of the feature maps. In addition, we introduce the intensity-aware loss (IAL) in the training process to help the network distinguish the samples with relatively low expression intensities. Experiments on two in-the-wild dynamic facial expression datasets (i.e., DFEW and FERV39k) indicate that our method outperforms the state-of-the-art DFER approaches. The source code will be made publicly available.