 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Quasi Manhattan Wasserstein Distance
Oct 19, 2023
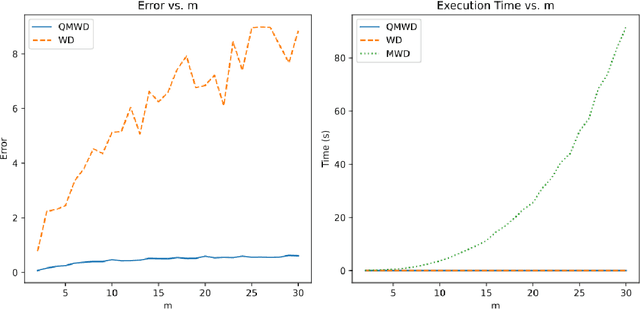
The Quasi Manhattan Wasserstein Distance (QMWD) is a metric designed to quantify the dissimilarity between two matrices by combining elements of the Wasserstein Distance with specific transformations. It offers improved time and space complexity compared to the Manhattan Wasserstein Distance (MWD) while maintaining accuracy. QMWD is particularly advantageous for large datasets or situations with limited computational resources. This article provides a detailed explanation of QMWD, its computation, complexity analysis, and comparisons with WD and MWD.
Zero-delay Consistent Signal Reconstruction from Streamed Multivariate Time Series
Aug 23, 2023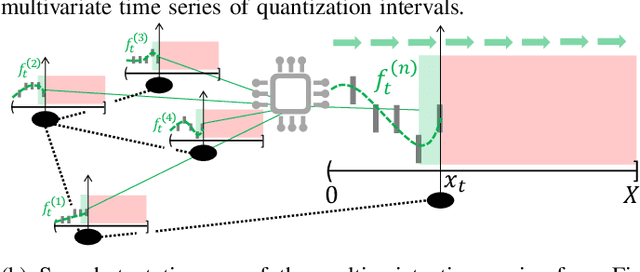
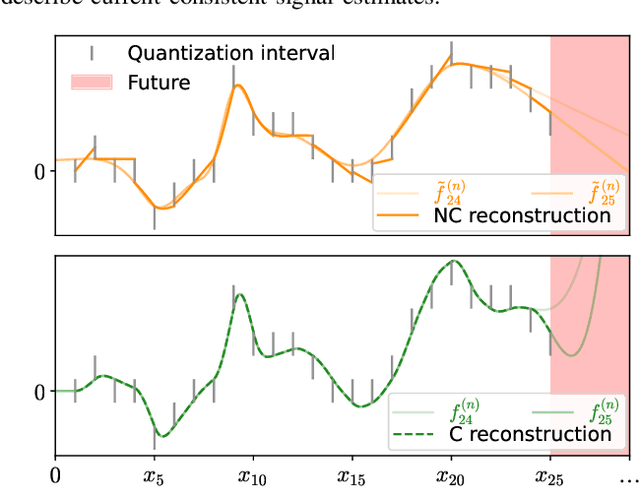
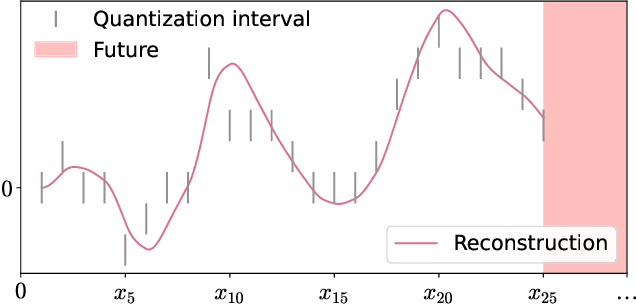
Digitalizing real-world analog signals typically involves sampling in time and discretizing in amplitude. Subsequent signal reconstructions inevitably incur an error that depends on the amplitude resolution and the temporal density of the acquired samples. From an implementation viewpoint, consistent signal reconstruction methods have proven a profitable error-rate decay as the sampling rate increases. Despite that, these results are obtained under offline settings. Therefore, a research gap exists regarding methods for consistent signal reconstruction from data streams. This paper presents a method that consistently reconstructs streamed multivariate time series of quantization intervals under a zero-delay response requirement. On the other hand, previous work has shown that the temporal dependencies within univariate time series can be exploited to reduce the roughness of zero-delay signal reconstructions. This work shows that the spatiotemporal dependencies within multivariate time series can also be exploited to achieve improved results. Specifically, the spatiotemporal dependencies of the multivariate time series are learned, with the assistance of a recurrent neural network, to reduce the roughness of the signal reconstruction on average while ensuring consistency. Our experiments show that our proposed method achieves a favorable error-rate decay with the sampling rate compared to a similar but non-consistent reconstruction.
Network-Aware AutoML Framework for Software-Defined Sensor Networks
Oct 25, 2023As the current detection solutions of distributed denial of service attacks (DDoS) need additional infrastructures to handle high aggregate data rates, they are not suitable for sensor networks or the Internet of Things. Besides, the security architecture of software-defined sensor networks needs to pay attention to the vulnerabilities of both software-defined networks and sensor networks. In this paper, we propose a network-aware automated machine learning (AutoML) framework which detects DDoS attacks in software-defined sensor networks. Our framework selects an ideal machine learning algorithm to detect DDoS attacks in network-constrained environments, using metrics such as variable traffic load, heterogeneous traffic rate, and detection time while preventing over-fitting. Our contributions are two-fold: (i) we first investigate the trade-off between the efficiency of ML algorithms and network/traffic state in the scope of DDoS detection. (ii) we design and implement a software architecture containing open-source network tools, with the deployment of multiple ML algorithms. Lastly, we show that under the denial of service attacks, our framework ensures the traffic packets are still delivered within the network with additional delays.
Guarantees for Self-Play in Multiplayer Games via Polymatrix Decomposability
Oct 25, 2023Self-play is a technique for machine learning in multi-agent systems where a learning algorithm learns by interacting with copies of itself. Self-play is useful for generating large quantities of data for learning, but has the drawback that the agents the learner will face post-training may have dramatically different behavior than the learner came to expect by interacting with itself. For the special case of two-player constant-sum games, self-play that reaches Nash equilibrium is guaranteed to produce strategies that perform well against any post-training opponent; however, no such guarantee exists for multiplayer games. We show that in games that approximately decompose into a set of two-player constant-sum games (called constant-sum polymatrix games) where global $\epsilon$-Nash equilibria are boundedly far from Nash equilibria in each subgame (called subgame stability), any no-external-regret algorithm that learns by self-play will produce a strategy with bounded vulnerability. For the first time, our results identify a structural property of multiplayer games that enable performance guarantees for the strategies produced by a broad class of self-play algorithms. We demonstrate our findings through experiments on Leduc poker.
Improving Performance in Colorectal Cancer Histology Decomposition using Deep and Ensemble Machine Learning
Oct 25, 2023In routine colorectal cancer management, histologic samples stained with hematoxylin and eosin are commonly used. Nonetheless, their potential for defining objective biomarkers for patient stratification and treatment selection is still being explored. The current gold standard relies on expensive and time-consuming genetic tests. However, recent research highlights the potential of convolutional neural networks (CNNs) in facilitating the extraction of clinically relevant biomarkers from these readily available images. These CNN-based biomarkers can predict patient outcomes comparably to golden standards, with the added advantages of speed, automation, and minimal cost. The predictive potential of CNN-based biomarkers fundamentally relies on the ability of convolutional neural networks (CNNs) to classify diverse tissue types from whole slide microscope images accurately. Consequently, enhancing the accuracy of tissue class decomposition is critical to amplifying the prognostic potential of imaging-based biomarkers. This study introduces a hybrid Deep and ensemble machine learning model that surpassed all preceding solutions for this classification task. Our model achieved 96.74% accuracy on the external test set and 99.89% on the internal test set. Recognizing the potential of these models in advancing the task, we have made them publicly available for further research and development.
The Significance of Machine Learning in Clinical Disease Diagnosis: A Review
Oct 25, 2023The global need for effective disease diagnosis remains substantial, given the complexities of various disease mechanisms and diverse patient symptoms. To tackle these challenges, researchers, physicians, and patients are turning to machine learning (ML), an artificial intelligence (AI) discipline, to develop solutions. By leveraging sophisticated ML and AI methods, healthcare stakeholders gain enhanced diagnostic and treatment capabilities. However, there is a scarcity of research focused on ML algorithms for enhancing the accuracy and computational efficiency. This research investigates the capacity of machine learning algorithms to improve the transmission of heart rate data in time series healthcare metrics, concentrating particularly on optimizing accuracy and efficiency. By exploring various ML algorithms used in healthcare applications, the review presents the latest trends and approaches in ML-based disease diagnosis (MLBDD). The factors under consideration include the algorithm utilized, the types of diseases targeted, the data types employed, the applications, and the evaluation metrics. This review aims to shed light on the prospects of ML in healthcare, particularly in disease diagnosis. By analyzing the current literature, the study provides insights into state-of-the-art methodologies and their performance metrics.
* 8 pages
Streaming Factor Trajectory Learning for Temporal Tensor Decomposition
Oct 25, 2023Practical tensor data is often along with time information. Most existing temporal decomposition approaches estimate a set of fixed factors for the objects in each tensor mode, and hence cannot capture the temporal evolution of the objects' representation. More important, we lack an effective approach to capture such evolution from streaming data, which is common in real-world applications. To address these issues, we propose Streaming Factor Trajectory Learning (SFTL) for temporal tensor decomposition. We use Gaussian processes (GPs) to model the trajectory of factors so as to flexibly estimate their temporal evolution. To address the computational challenges in handling streaming data, we convert the GPs into a state-space prior by constructing an equivalent stochastic differential equation (SDE). We develop an efficient online filtering algorithm to estimate a decoupled running posterior of the involved factor states upon receiving new data. The decoupled estimation enables us to conduct standard Rauch-Tung-Striebel smoothing to compute the full posterior of all the trajectories in parallel, without the need for revisiting any previous data. We have shown the advantage of SFTL in both synthetic tasks and real-world applications.
Neural Potential Field for Obstacle-Aware Local Motion Planning
Oct 25, 2023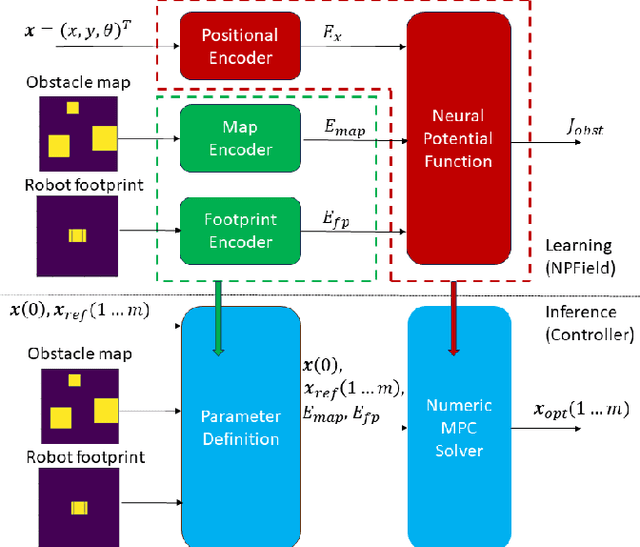

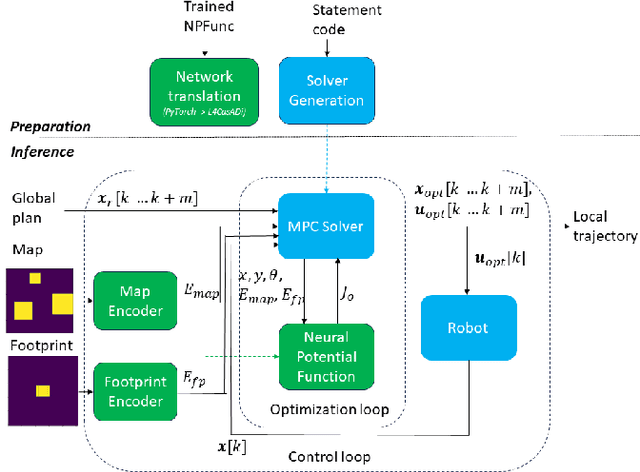
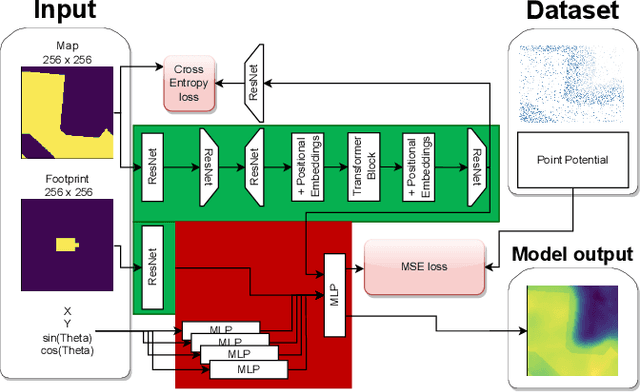
Model predictive control (MPC) may provide local motion planning for mobile robotic platforms. The challenging aspect is the analytic representation of collision cost for the case when both the obstacle map and robot footprint are arbitrary. We propose a Neural Potential Field: a neural network model that returns a differentiable collision cost based on robot pose, obstacle map, and robot footprint. The differentiability of our model allows its usage within the MPC solver. It is computationally hard to solve problems with a very high number of parameters. Therefore, our architecture includes neural image encoders, which transform obstacle maps and robot footprints into embeddings, which reduce problem dimensionality by two orders of magnitude. The reference data for network training are generated based on algorithmic calculation of a signed distance function. Comparative experiments showed that the proposed approach is comparable with existing local planners: it provides trajectories with outperforming smoothness, comparable path length, and safe distance from obstacles. Experiment on Husky UGV mobile robot showed that our approach allows real-time and safe local planning. The code for our approach is presented at https://github.com/cog-isa/NPField together with demo video.
LlamaRec: Two-Stage Recommendation using Large Language Models for Ranking
Oct 25, 2023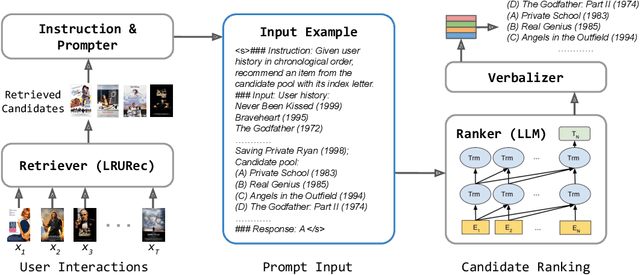
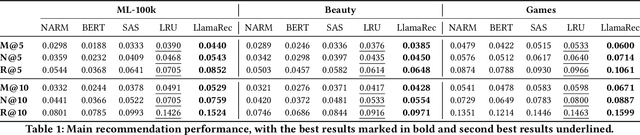

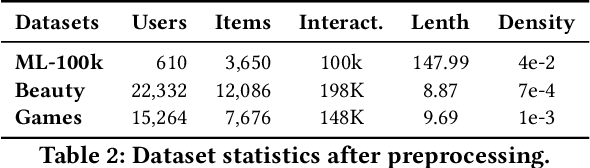
Recently, large language models (LLMs) have exhibited significant progress in language understanding and generation. By leveraging textual features, customized LLMs are also applied for recommendation and demonstrate improvements across diverse recommendation scenarios. Yet the majority of existing methods perform training-free recommendation that heavily relies on pretrained knowledge (e.g., movie recommendation). In addition, inference on LLMs is slow due to autoregressive generation, rendering existing methods less effective for real-time recommendation. As such, we propose a two-stage framework using large language models for ranking-based recommendation (LlamaRec). In particular, we use small-scale sequential recommenders to retrieve candidates based on the user interaction history. Then, both history and retrieved items are fed to the LLM in text via a carefully designed prompt template. Instead of generating next-item titles, we adopt a verbalizer-based approach that transforms output logits into probability distributions over the candidate items. Therefore, the proposed LlamaRec can efficiently rank items without generating long text. To validate the effectiveness of the proposed framework, we compare against state-of-the-art baseline methods on benchmark datasets. Our experimental results demonstrate the performance of LlamaRec, which consistently achieves superior performance in both recommendation performance and efficiency.
Simultaneous Shape Tracking of Multiple Deformable Linear Objects with Global-Local Topology Preservation
Oct 20, 2023This work presents an algorithm for tracking the shape of multiple entangling Deformable Linear Objects (DLOs) from a sequence of RGB-D images. This algorithm runs in real-time and improves on previous single-DLO tracking approaches by enabling tracking of multiple objects. This is achieved using Global-Local Topology Preservation (GLTP). This work uses the geodesic distance in GLTP to define the distance between separate objects and the distance between different parts of the same object. Tracking multiple entangling DLOs is demonstrated experimentally. The source code is publicly released.