 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bespoke Solvers for Generative Flow Models
Oct 29, 2023
Diffusion or flow-based models are powerful generative paradigms that are notoriously hard to sample as samples are defined as solutions to high-dimensional Ordinary or Stochastic Differential Equations (ODEs/SDEs) which require a large Number of Function Evaluations (NFE) to approximate well. Existing methods to alleviate the costly sampling process include model distillation and designing dedicated ODE solvers. However, distillation is costly to train and sometimes can deteriorate quality, while dedicated solvers still require relatively large NFE to produce high quality samples. In this paper we introduce "Bespoke solvers", a novel framework for constructing custom ODE solvers tailored to the ODE of a given pre-trained flow model. Our approach optimizes an order consistent and parameter-efficient solver (e.g., with 80 learnable parameters), is trained for roughly 1% of the GPU time required for training the pre-trained model, and significantly improves approximation and generation quality compared to dedicated solvers. For example, a Bespoke solver for a CIFAR10 model produces samples with Fr\'echet Inception Distance (FID) of 2.73 with 10 NFE, and gets to 1% of the Ground Truth (GT) FID (2.59) for this model with only 20 NFE. On the more challenging ImageNet-64$\times$64, Bespoke samples at 2.2 FID with 10 NFE, and gets within 2% of GT FID (1.71) with 20 NFE.
Blacksmith: Fast Adversarial Training of Vision Transformers via a Mixture of Single-step and Multi-step Methods
Oct 29, 2023Despite the remarkable success achieved by deep learning algorithms in various domains, such as computer vision, they remain vulnerable to adversarial perturbations. Adversarial Training (AT) stands out as one of the most effective solutions to address this issue; however, single-step AT can lead to Catastrophic Overfitting (CO). This scenario occurs when the adversarially trained network suddenly loses robustness against multi-step attacks like Projected Gradient Descent (PGD). Although several approaches have been proposed to address this problem in Convolutional Neural Networks (CNNs), we found out that they do not perform well when applied to Vision Transformers (ViTs). In this paper, we propose Blacksmith, a novel training strategy to overcome the CO problem, specifically in ViTs. Our approach utilizes either of PGD-2 or Fast Gradient Sign Method (FGSM) randomly in a mini-batch during the adversarial training of the neural network. This will increase the diversity of our training attacks, which could potentially mitigate the CO issue. To manage the increased training time resulting from this combination, we craft the PGD-2 attack based on only the first half of the layers, while FGSM is applied end-to-end. Through our experiments, we demonstrate that our novel method effectively prevents CO, achieves PGD-2 level performance, and outperforms other existing techniques including N-FGSM, which is the state-of-the-art method in fast training for CNNs.
Video Frame Interpolation with Many-to-many Splatting and Spatial Selective Refinement
Oct 29, 2023In this work, we first propose a fully differentiable Many-to-Many (M2M) splatting framework to interpolate frames efficiently. Given a frame pair, we estimate multiple bidirectional flows to directly forward warp the pixels to the desired time step before fusing overlapping pixels. In doing so, each source pixel renders multiple target pixels and each target pixel can be synthesized from a larger area of visual context, establishing a many-to-many splatting scheme with robustness to undesirable artifacts. For each input frame pair, M2M has a minuscule computational overhead when interpolating an arbitrary number of in-between frames, hence achieving fast multi-frame interpolation. However, directly warping and fusing pixels in the intensity domain is sensitive to the quality of motion estimation and may suffer from less effective representation capacity. To improve interpolation accuracy, we further extend an M2M++ framework by introducing a flexible Spatial Selective Refinement (SSR) component, which allows for trading computational efficiency for interpolation quality and vice versa. Instead of refining the entire interpolated frame, SSR only processes difficult regions selected under the guidance of an estimated error map, thereby avoiding redundant computation. Evaluation on multiple benchmark datasets shows that our method is able to improve the efficiency while maintaining competitive video interpolation quality, and it can be adjusted to use more or less compute as needed.
Complex Image Generation SwinTransformer Network for Audio Denoising
Oct 24, 2023Achieving high-performance audio denoising is still a challenging task in real-world applications. Existing time-frequency methods often ignore the quality of generated frequency domain images. This paper converts the audio denoising problem into an image generation task. We first develop a complex image generation SwinTransformer network to capture more information from the complex Fourier domain. We then impose structure similarity and detailed loss functions to generate high-quality images and develop an SDR loss to minimize the difference between denoised and clean audios. Extensive experiments on two benchmark datasets demonstrate that our proposed model is better than state-of-the-art methods.
Simultaneous Shape Tracking of Multiple Deformable Linear Objects with Global-Local Topology Preservation
Oct 23, 2023This work presents an algorithm for tracking the shape of multiple entangling Deformable Linear Objects (DLOs) from a sequence of RGB-D images. This algorithm runs in real-time and improves on previous single-DLO tracking approaches by enabling tracking of multiple objects. This is achieved using Global-Local Topology Preservation (GLTP). This work uses the geodesic distance in GLTP to define the distance between separate objects and the distance between different parts of the same object. Tracking multiple entangling DLOs is demonstrated experimentally. The source code is publicly released.
Speakerly: A Voice-based Writing Assistant for Text Composition
Oct 24, 2023We present Speakerly, a new real-time voice-based writing assistance system that helps users with text composition across various use cases such as emails, instant messages, and notes. The user can interact with the system through instructions or dictation, and the system generates a well-formatted and coherent document. We describe the system architecture and detail how we address the various challenges while building and deploying such a system at scale. More specifically, our system uses a combination of small, task-specific models as well as pre-trained language models for fast and effective text composition while supporting a variety of input modes for better usability.
eDKM: An Efficient and Accurate Train-time Weight Clustering for Large Language Models
Sep 13, 2023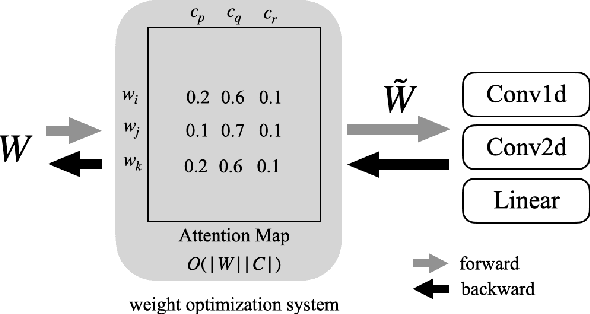

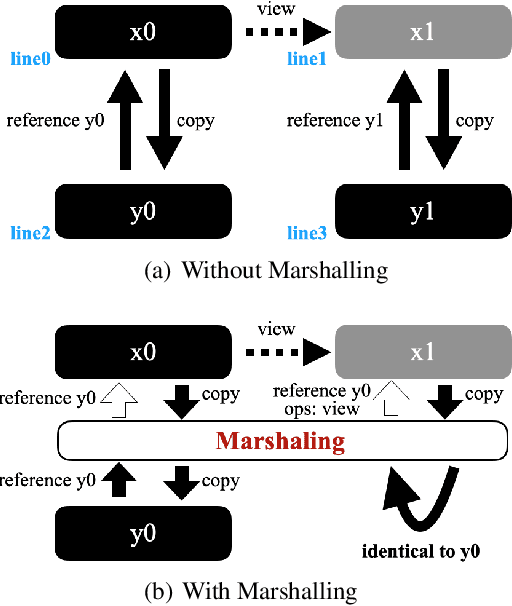
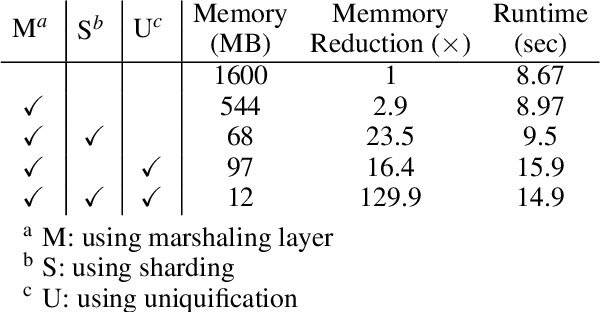
Since Large Language Models or LLMs have demonstrated high-quality performance on many complex language tasks, there is a great interest in bringing these LLMs to mobile devices for faster responses and better privacy protection. However, the size of LLMs (i.e., billions of parameters) requires highly effective compression to fit into storage-limited devices. Among many compression techniques, weight-clustering, a form of non-linear quantization, is one of the leading candidates for LLM compression, and supported by modern smartphones. Yet, its training overhead is prohibitively significant for LLM fine-tuning. Especially, Differentiable KMeans Clustering, or DKM, has shown the state-of-the-art trade-off between compression ratio and accuracy regression, but its large memory complexity makes it nearly impossible to apply to train-time LLM compression. In this paper, we propose a memory-efficient DKM implementation, eDKM powered by novel techniques to reduce the memory footprint of DKM by orders of magnitudes. For a given tensor to be saved on CPU for the backward pass of DKM, we compressed the tensor by applying uniquification and sharding after checking if there is no duplicated tensor previously copied to CPU. Our experimental results demonstrate that \prjname can fine-tune and compress a pretrained LLaMA 7B model from 12.6 GB to 2.5 GB (3bit/weight) with the Alpaca dataset by reducing the train-time memory footprint of a decoder layer by 130$\times$, while delivering good accuracy on broader LLM benchmarks (i.e., 77.7% for PIQA, 66.1% for Winograde, and so on).
EqDrive: Efficient Equivariant Motion Forecasting with Multi-Modality for Autonomous Driving
Oct 26, 2023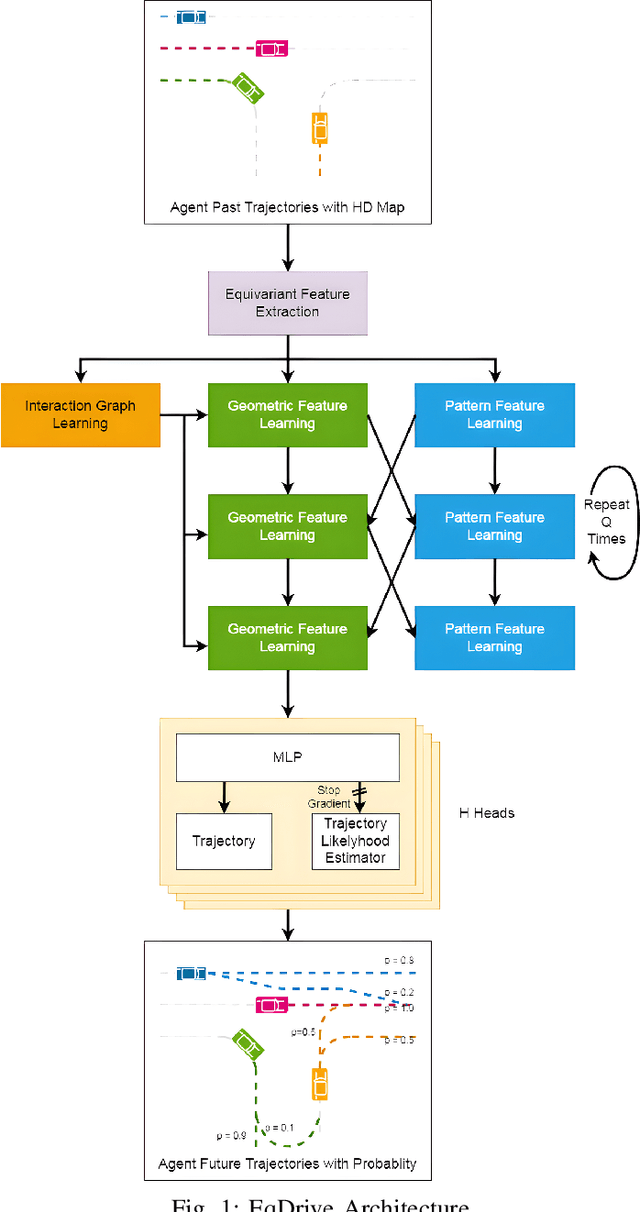
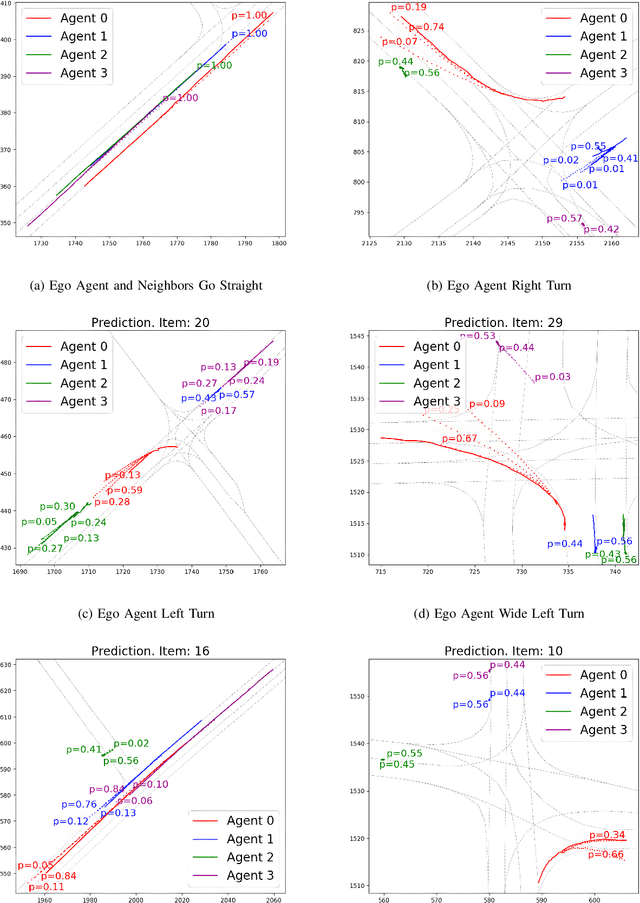
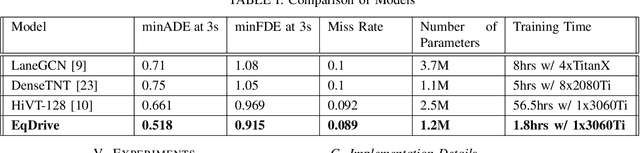
Forecasting vehicular motions in autonomous driving requires a deep understanding of agent interactions and the preservation of motion equivariance under Euclidean geometric transformations. Traditional models often lack the sophistication needed to handle the intricate dynamics inherent to autonomous vehicles and the interaction relationships among agents in the scene. As a result, these models have a lower model capacity, which then leads to higher prediction errors and lower training efficiency. In our research, we employ EqMotion, a leading equivariant particle, and human prediction model that also accounts for invariant agent interactions, for the task of multi-agent vehicle motion forecasting. In addition, we use a multi-modal prediction mechanism to account for multiple possible future paths in a probabilistic manner. By leveraging EqMotion, our model achieves state-of-the-art (SOTA) performance with fewer parameters (1.2 million) and a significantly reduced training time (less than 2 hours).
Predictive Maintenance Model Based on Anomaly Detection in Induction Motors: A Machine Learning Approach Using Real-Time IoT Data
Oct 15, 2023With the support of Internet of Things (IoT) devices, it is possible to acquire data from degradation phenomena and design data-driven models to perform anomaly detection in industrial equipment. This approach not only identifies potential anomalies but can also serve as a first step toward building predictive maintenance policies. In this work, we demonstrate a novel anomaly detection system on induction motors used in pumps, compressors, fans, and other industrial machines. This work evaluates a combination of pre-processing techniques and machine learning (ML) models with a low computational cost. We use a combination of pre-processing techniques such as Fast Fourier Transform (FFT), Wavelet Transform (WT), and binning, which are well-known approaches for extracting features from raw data. We also aim to guarantee an optimal balance between multiple conflicting parameters, such as anomaly detection rate, false positive rate, and inference speed of the solution. To this end, multiobjective optimization and analysis are performed on the evaluated models. Pareto-optimal solutions are presented to select which models have the best results regarding classification metrics and computational effort. Differently from most works in this field that use publicly available datasets to validate their models, we propose an end-to-end solution combining low-cost and readily available IoT sensors. The approach is validated by acquiring a custom dataset from induction motors. Also, we fuse vibration, temperature, and noise data from these sensors as the input to the proposed ML model. Therefore, we aim to propose a methodology general enough to be applied in different industrial contexts in the future.
Empowering SMPC: Bridging the Gap Between Scalability, Memory Efficiency and Privacy in Neural Network Inference
Oct 16, 2023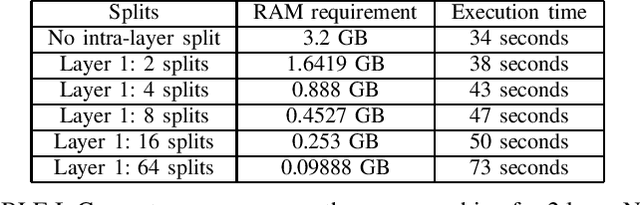
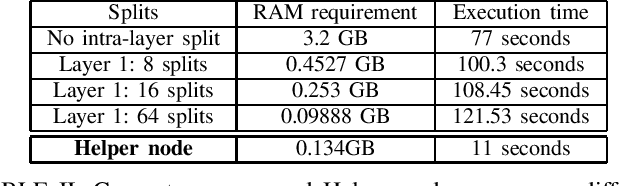
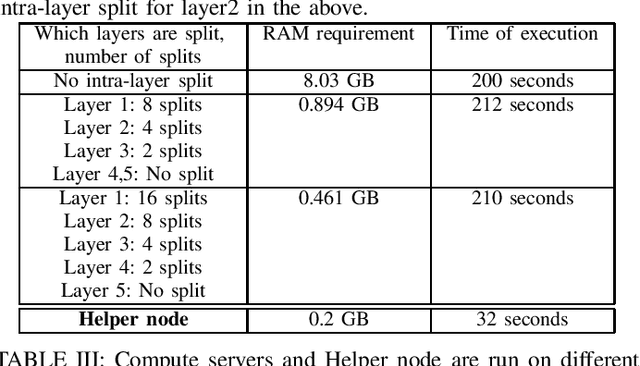

This paper aims to develop an efficient open-source Secure Multi-Party Computation (SMPC) repository, that addresses the issue of practical and scalable implementation of SMPC protocol on machines with moderate computational resources, while aiming to reduce the execution time. We implement the ABY2.0 protocol for SMPC, providing developers with effective tools for building applications on the ABY 2.0 protocol. This article addresses the limitations of the C++ based MOTION2NX framework for secure neural network inference, including memory constraints and operation compatibility issues. Our enhancements include optimizing the memory usage, reducing execution time using a third-party Helper node, and enhancing efficiency while still preserving data privacy. These optimizations enable MNIST dataset inference in just 32 seconds with only 0.2 GB of RAM for a 5-layer neural network. In contrast, the previous baseline implementation required 8.03 GB of RAM and 200 seconds of execution time.