 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Voice2Action: Language Models as Agent for Efficient Real-Time Interaction in Virtual Reality
Sep 29, 2023
Large Language Models (LLMs) are trained and aligned to follow natural language instructions with only a handful of examples, and they are prompted as task-driven autonomous agents to adapt to various sources of execution environments. However, deploying agent LLMs in virtual reality (VR) has been challenging due to the lack of efficiency in online interactions and the complex manipulation categories in 3D environments. In this work, we propose Voice2Action, a framework that hierarchically analyzes customized voice signals and textual commands through action and entity extraction and divides the execution tasks into canonical interaction subsets in real-time with error prevention from environment feedback. Experiment results in an urban engineering VR environment with synthetic instruction data show that Voice2Action can perform more efficiently and accurately than approaches without optimizations.
Joint Problems in Learning Multiple Dynamical Systems
Nov 03, 2023Clustering of time series is a well-studied problem, with applications ranging from quantitative, personalized models of metabolism obtained from metabolite concentrations to state discrimination in quantum information theory. We consider a variant, where given a set of trajectories and a number of parts, we jointly partition the set of trajectories and learn linear dynamical system (LDS) models for each part, so as to minimize the maximum error across all the models. We present globally convergent methods and EM heuristics, accompanied by promising computational results.
Understanding and Visualizing Droplet Distributions in Simulations of Shallow Clouds
Oct 31, 2023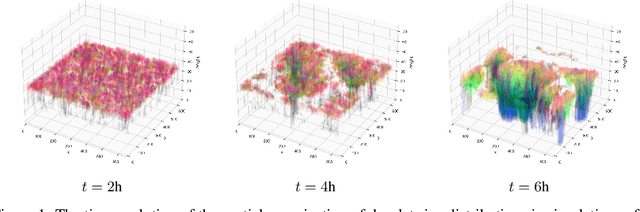
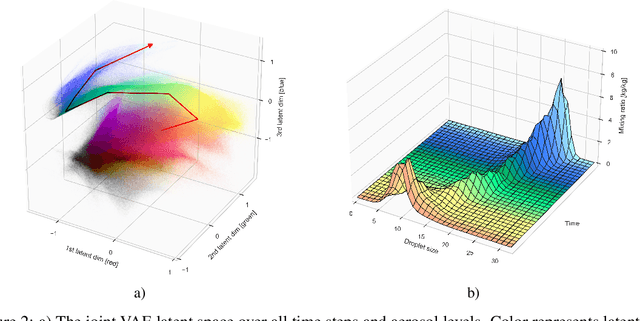
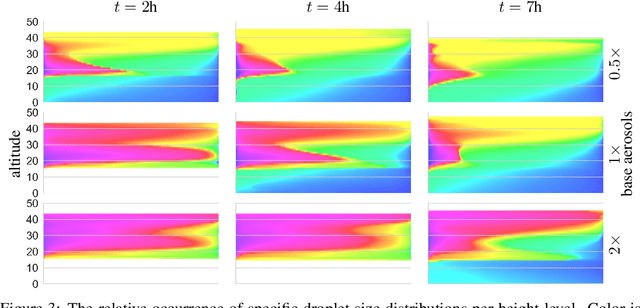
Thorough analysis of local droplet-level interactions is crucial to better understand the microphysical processes in clouds and their effect on the global climate. High-accuracy simulations of relevant droplet size distributions from Large Eddy Simulations (LES) of bin microphysics challenge current analysis techniques due to their high dimensionality involving three spatial dimensions, time, and a continuous range of droplet sizes. Utilizing the compact latent representations from Variational Autoencoders (VAEs), we produce novel and intuitive visualizations for the organization of droplet sizes and their evolution over time beyond what is possible with clustering techniques. This greatly improves interpretation and allows us to examine aerosol-cloud interactions by contrasting simulations with different aerosol concentrations. We find that the evolution of the droplet spectrum is similar across aerosol levels but occurs at different paces. This similarity suggests that precipitation initiation processes are alike despite variations in onset times.
Bayesian Neural Controlled Differential Equations for Treatment Effect Estimation
Oct 26, 2023Treatment effect estimation in continuous time is crucial for personalized medicine. However, existing methods for this task are limited to point estimates of the potential outcomes, whereas uncertainty estimates have been ignored. Needless to say, uncertainty quantification is crucial for reliable decision-making in medical applications. To fill this gap, we propose a novel Bayesian neural controlled differential equation (BNCDE) for treatment effect estimation in continuous time. In our BNCDE, the time dimension is modeled through a coupled system of neural controlled differential equations and neural stochastic differential equations, where the neural stochastic differential equations allow for tractable variational Bayesian inference. Thereby, for an assigned sequence of treatments, our BNCDE provides meaningful posterior predictive distributions of the potential outcomes. To the best of our knowledge, ours is the first tailored neural method to provide uncertainty estimates of treatment effects in continuous time. As such, our method is of direct practical value for promoting reliable decision-making in medicine.
Contrastive Multi-Modal Representation Learning for Spark Plug Fault Diagnosis
Nov 04, 2023Due to the incapability of one sensory measurement to provide enough information for condition monitoring of some complex engineered industrial mechanisms and also for overcoming the misleading noise of a single sensor, multiple sensors are installed to improve the condition monitoring of some industrial equipment. Therefore, an efficient data fusion strategy is demanded. In this research, we presented a Denoising Multi-Modal Autoencoder with a unique training strategy based on contrastive learning paradigm, both being utilized for the first time in the machine health monitoring realm. The presented approach, which leverages the merits of both supervised and unsupervised learning, not only achieves excellent performance in fusing multiple modalities (or views) of data into an enriched common representation but also takes data fusion to the next level wherein one of the views can be omitted during inference time with very slight performance reduction, or even without any reduction at all. The presented methodology enables multi-modal fault diagnosis systems to perform more robustly in case of sensor failure occurrence, and one can also intentionally omit one of the sensors (the more expensive one) in order to build a more cost-effective condition monitoring system without sacrificing performance for practical purposes. The effectiveness of the presented methodology is examined on a real-world private multi-modal dataset gathered under non-laboratory conditions from a complex engineered mechanism, an inline four-stroke spark-ignition engine, aiming for spark plug fault diagnosis. This dataset, which contains the accelerometer and acoustic signals as two modalities, has a very slight amount of fault, and achieving good performance on such a dataset promises that the presented method can perform well on other equipment as well.
A Definition of Open-Ended Learning Problems for Goal-Conditioned Agents
Nov 02, 2023A lot of recent machine learning research papers have "Open-ended learning" in their title. But very few of them attempt to define what they mean when using the term. Even worse, when looking more closely there seems to be no consensus on what distinguishes open-ended learning from related concepts such as continual learning, lifelong learning or autotelic learning. In this paper, we contribute to fixing this situation. After illustrating the genealogy of the concept and more recent perspectives about what it truly means, we outline that open-ended learning is generally conceived as a composite notion encompassing a set of diverse properties. In contrast with these previous approaches, we propose to isolate a key elementary property of open-ended processes, which is to always produce novel elements from time to time over an infinite horizon. From there, we build the notion of open-ended learning problems and focus in particular on the subset of open-ended goal-conditioned reinforcement learning problems, as this framework facilitates the definition of learning a growing repertoire of skills. Finally, we highlight the work that remains to be performed to fill the gap between our elementary definition and the more involved notions of open-ended learning that developmental AI researchers may have in mind.
Hashing Neural Video Decomposition with Multiplicative Residuals in Space-Time
Sep 25, 2023We present a video decomposition method that facilitates layer-based editing of videos with spatiotemporally varying lighting and motion effects. Our neural model decomposes an input video into multiple layered representations, each comprising a 2D texture map, a mask for the original video, and a multiplicative residual characterizing the spatiotemporal variations in lighting conditions. A single edit on the texture maps can be propagated to the corresponding locations in the entire video frames while preserving other contents' consistencies. Our method efficiently learns the layer-based neural representations of a 1080p video in 25s per frame via coordinate hashing and allows real-time rendering of the edited result at 71 fps on a single GPU. Qualitatively, we run our method on various videos to show its effectiveness in generating high-quality editing effects. Quantitatively, we propose to adopt feature-tracking evaluation metrics for objectively assessing the consistency of video editing. Project page: https://lightbulb12294.github.io/hashing-nvd/
TACNET: Temporal Audio Source Counting Network
Nov 04, 2023In this paper, we introduce the Temporal Audio Source Counting Network (TaCNet), an innovative architecture that addresses limitations in audio source counting tasks. TaCNet operates directly on raw audio inputs, eliminating complex preprocessing steps and simplifying the workflow. Notably, it excels in real-time speaker counting, even with truncated input windows. Our extensive evaluation, conducted using the LibriCount dataset, underscores TaCNet's exceptional performance, positioning it as a state-of-the-art solution for audio source counting tasks. With an average accuracy of 74.18 percentage over 11 classes, TaCNet demonstrates its effectiveness across diverse scenarios, including applications involving Chinese and Persian languages. This cross-lingual adaptability highlights its versatility and potential impact.
Leveraging Transformers to Improve Breast Cancer Classification and Risk Assessment with Multi-modal and Longitudinal Data
Nov 06, 2023Breast cancer screening, primarily conducted through mammography, is often supplemented with ultrasound for women with dense breast tissue. However, existing deep learning models analyze each modality independently, missing opportunities to integrate information across imaging modalities and time. In this study, we present Multi-modal Transformer (MMT), a neural network that utilizes mammography and ultrasound synergistically, to identify patients who currently have cancer and estimate the risk of future cancer for patients who are currently cancer-free. MMT aggregates multi-modal data through self-attention and tracks temporal tissue changes by comparing current exams to prior imaging. Trained on 1.3 million exams, MMT achieves an AUROC of 0.943 in detecting existing cancers, surpassing strong uni-modal baselines. For 5-year risk prediction, MMT attains an AUROC of 0.826, outperforming prior mammography-based risk models. Our research highlights the value of multi-modal and longitudinal imaging in cancer diagnosis and risk stratification.
ViDa: Visualizing DNA hybridization trajectories with biophysics-informed deep graph embeddings
Nov 06, 2023Visualization tools can help synthetic biologists and molecular programmers understand the complex reactive pathways of nucleic acid reactions, which can be designed for many potential applications and can be modelled using a continuous-time Markov chain (CTMC). Here we present ViDa, a new visualization approach for DNA reaction trajectories that uses a 2D embedding of the secondary structure state space underlying the CTMC model. To this end, we integrate a scattering transform of the secondary structure adjacency, a variational autoencoder, and a nonlinear dimensionality reduction method. We augment the training loss with domain-specific supervised terms that capture both thermodynamic and kinetic features. We assess ViDa on two well-studied DNA hybridization reactions. Our results demonstrate that the domain-specific features lead to significant quality improvements over the state-of-the-art in DNA state space visualization, successfully separating different folding pathways and thus providing useful insights into dominant reaction mechanisms.