 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pipeline Parallelism for DNN Inference with Practical Performance Guarantees
Nov 07, 2023
We optimize pipeline parallelism for deep neural network (DNN) inference by partitioning model graphs into $k$ stages and minimizing the running time of the bottleneck stage, including communication. We design practical algorithms for this NP-hard problem and show that they are nearly optimal in practice by comparing against strong lower bounds obtained via novel mixed-integer programming (MIP) formulations. We apply these algorithms and lower-bound methods to production models to achieve substantially improved approximation guarantees compared to standard combinatorial lower bounds. For example, evaluated via geometric means across production data with $k=16$ pipeline stages, our MIP formulations more than double the lower bounds, improving the approximation ratio from $2.175$ to $1.058$. This work shows that while max-throughput partitioning is theoretically hard, we have a handle on the algorithmic side of the problem in practice and much of the remaining challenge is in developing more accurate cost models to feed into the partitioning algorithms.
Efficient Bottom-Up Synthesis for Programs with Local Variables
Nov 07, 2023We propose a new synthesis algorithm that can efficiently search programs with local variables (e.g., those introduced by lambdas). Prior bottom-up synthesis algorithms are not able to evaluate programs with free local variables, and therefore cannot effectively reduce the search space of such programs (e.g., using standard observational equivalence reduction techniques), making synthesis slow. Our algorithm can reduce the space of programs with local variables. The key idea, dubbed lifted interpretation, is to lift up the program interpretation process, from evaluating one program at a time to simultaneously evaluating all programs from a grammar. Lifted interpretation provides a mechanism to systematically enumerate all binding contexts for local variables, thereby enabling us to evaluate and reduce the space of programs with local variables. Our ideas are instantiated in the domain of web automation. The resulting tool, Arborist, can automate a significantly broader range of challenging tasks more efficiently than state-of-the-art techniques including WebRobot and Helena.
Knowledge-Based Support for Adhesive Selection: Will it Stick?
Nov 07, 2023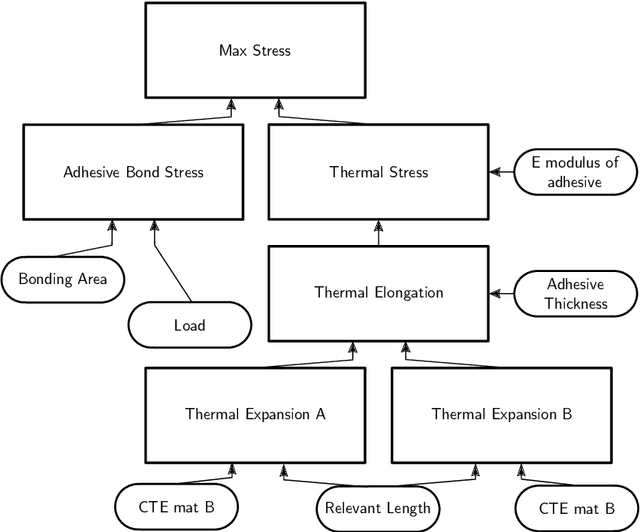

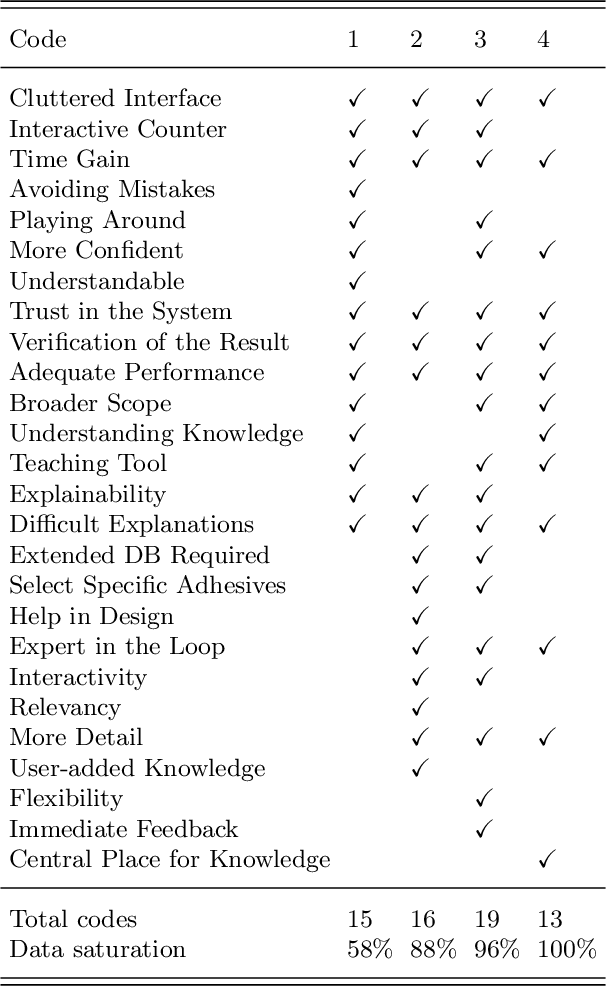
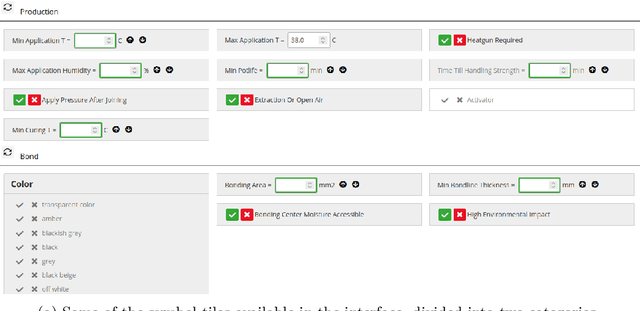
As the popularity of adhesive joints in industry increases, so does the need for tools to support the process of selecting a suitable adhesive. While some such tools already exist, they are either too limited in scope, or offer too little flexibility in use. This work presents a more advanced tool, that was developed together with a team of adhesive experts. We first extract the experts' knowledge about this domain and formalize it in a Knowledge Base (KB). The IDP-Z3 reasoning system can then be used to derive the necessary functionality from this KB. Together with a user-friendly interactive interface, this creates an easy-to-use tool capable of assisting the adhesive experts. To validate our approach, we performed user testing in the form of qualitative interviews. The experts are very positive about the tool, stating that, among others, it will help save time and find more suitable adhesives. Under consideration in Theory and Practice of Logic Programming (TPLP).
Disentangled Counterfactual Learning for Physical Audiovisual Commonsense Reasoning
Nov 02, 2023In this paper, we propose a Disentangled Counterfactual Learning~(DCL) approach for physical audiovisual commonsense reasoning. The task aims to infer objects' physics commonsense based on both video and audio input, with the main challenge is how to imitate the reasoning ability of humans. Most of the current methods fail to take full advantage of different characteristics in multi-modal data, and lacking causal reasoning ability in models impedes the progress of implicit physical knowledge inferring. To address these issues, our proposed DCL method decouples videos into static (time-invariant) and dynamic (time-varying) factors in the latent space by the disentangled sequential encoder, which adopts a variational autoencoder (VAE) to maximize the mutual information with a contrastive loss function. Furthermore, we introduce a counterfactual learning module to augment the model's reasoning ability by modeling physical knowledge relationships among different objects under counterfactual intervention. Our proposed method is a plug-and-play module that can be incorporated into any baseline. In experiments, we show that our proposed method improves baseline methods and achieves state-of-the-art performance. Our source code is available at https://github.com/Andy20178/DCL.
Automatic Configuration of Multi-Agent Model Predictive Controllers based on Semantic Graph World Models
Nov 02, 2023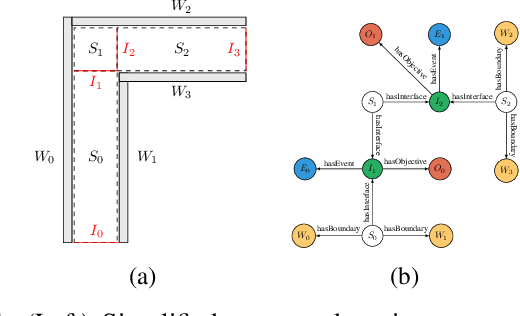
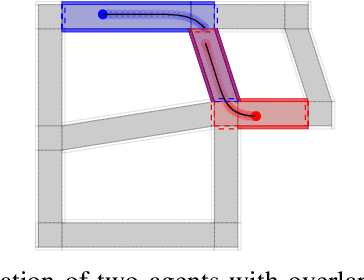
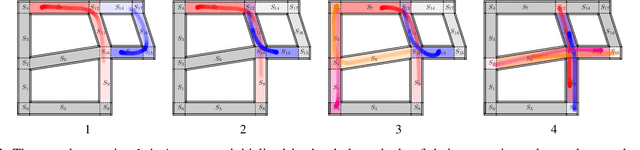

We propose a shared semantic map architecture to construct and configure Model Predictive Controllers (MPC) dynamically, that solve navigation problems for multiple robotic agents sharing parts of the same environment. The navigation task is represented as a sequence of semantically labeled areas in the map, that must be traversed sequentially, i.e. a route. Each semantic label represents one or more constraints on the robots' motion behaviour in that area. The advantages of this approach are: (i) an MPC-based motion controller in each individual robot can be (re-)configured, at runtime, with the locally and temporally relevant parameters; (ii) the application can influence, also at runtime, the navigation behaviour of the robots, just by adapting the semantic labels; and (iii) the robots can reason about their need for coordination, through analyzing over which horizon in time and space their routes overlap. The paper provides simulations of various representative situations, showing that the approach of runtime configuration of the MPC drastically decreases computation time, while retaining task execution performance similar to an approach in which each robot always includes all other robots in its MPC computations.
CEFL: Carbon-Efficient Federated Learning
Oct 27, 2023Federated Learning (FL) distributes machine learning (ML) training across many edge devices to reduce data transfer overhead and protect data privacy. Since FL model training may span millions of devices and is thus resource-intensive, prior work has focused on improving its resource efficiency to optimize time-to-accuracy. However, prior work generally treats all resources the same, while, in practice, they may incur widely different costs, which instead motivates optimizing cost-to-accuracy. To address the problem, we design CEFL, which uses adaptive cost-aware client selection policies to optimize an arbitrary cost metric when training FL models. Our policies extend and combine prior work on utility-based client selection and critical learning periods by making them cost-aware. We demonstrate CEFL by designing carbon-efficient FL, where energy's carbon-intensity is the cost, and show that it i) reduces carbon emissions by 93\% and reduces training time by 50% compared to random client selection and ii) reduces carbon emissions by 80%, while only increasing training time by 38%, compared to a state-of-the-art approach that optimizes training time.
Clustering of Urban Traffic Patterns by K-Means and Dynamic Time Warping: Case Study
Sep 18, 2023Clustering of urban traffic patterns is an essential task in many different areas of traffic management and planning. In this paper, two significant applications in the clustering of urban traffic patterns are described. The first application estimates the missing speed values using the speed of road segments with similar traffic patterns to colorify map tiles. The second one is the estimation of essential road segments for generating addresses for a local point on the map, using the similarity patterns of different road segments. The speed time series extracts the traffic pattern in different road segments. In this paper, we proposed the time series clustering algorithm based on K-Means and Dynamic Time Warping. The case study of our proposed algorithm is based on the Snapp application's driver speed time series data. The results of the two applications illustrate that the proposed method can extract similar urban traffic patterns.
Untargeted White-box Adversarial Attack with Heuristic Defence Methods in Real-time Deep Learning based Network Intrusion Detection System
Oct 05, 2023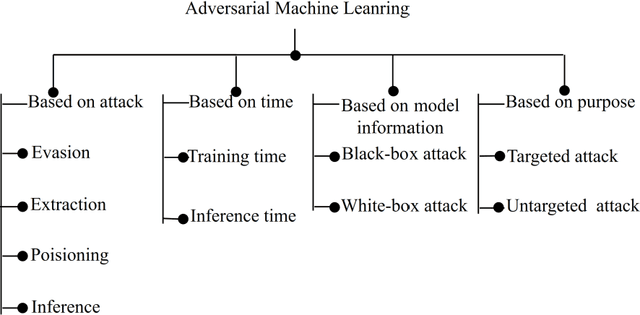

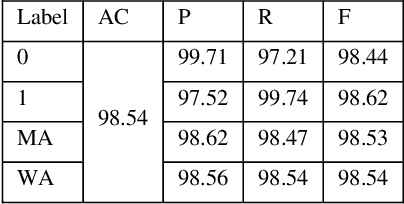
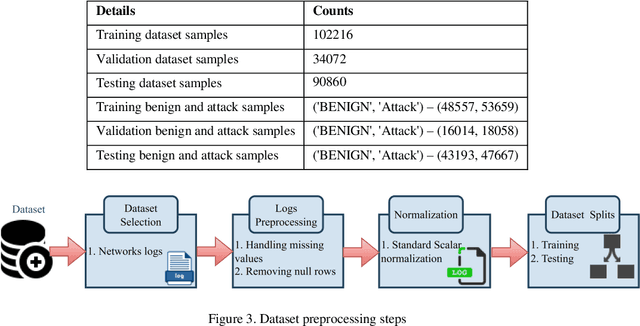
Network Intrusion Detection System (NIDS) is a key component in securing the computer network from various cyber security threats and network attacks. However, consider an unfortunate situation where the NIDS is itself attacked and vulnerable more specifically, we can say, How to defend the defender?. In Adversarial Machine Learning (AML), the malicious actors aim to fool the Machine Learning (ML) and Deep Learning (DL) models to produce incorrect predictions with intentionally crafted adversarial examples. These adversarial perturbed examples have become the biggest vulnerability of ML and DL based systems and are major obstacles to their adoption in real-time and mission-critical applications such as NIDS. AML is an emerging research domain, and it has become a necessity for the in-depth study of adversarial attacks and their defence strategies to safeguard the computer network from various cyber security threads. In this research work, we aim to cover important aspects related to NIDS, adversarial attacks and its defence mechanism to increase the robustness of the ML and DL based NIDS. We implemented four powerful adversarial attack techniques, namely, Fast Gradient Sign Method (FGSM), Jacobian Saliency Map Attack (JSMA), Projected Gradient Descent (PGD) and Carlini & Wagner (C&W) in NIDS. We analyzed its performance in terms of various performance metrics in detail. Furthermore, the three heuristics defence strategies, i.e., Adversarial Training (AT), Gaussian Data Augmentation (GDA) and High Confidence (HC), are implemented to improve the NIDS robustness under adversarial attack situations. The complete workflow is demonstrated in real-time network with data packet flow. This research work provides the overall background for the researchers interested in AML and its implementation from a computer network security point of view.
Setting the Right Expectations: Algorithmic Recourse Over Time
Sep 13, 2023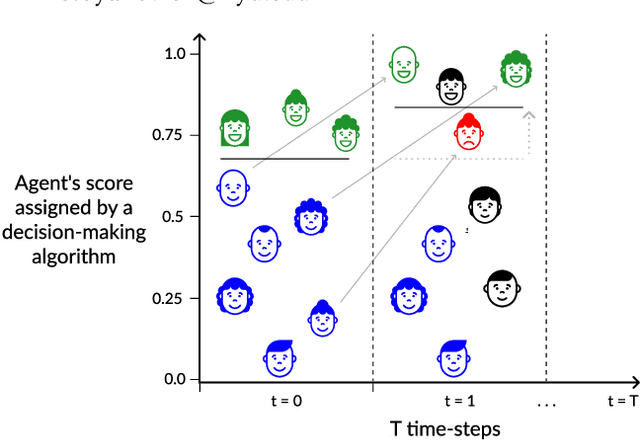
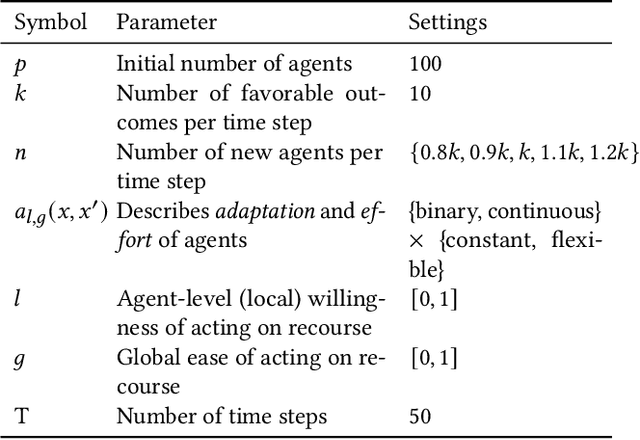
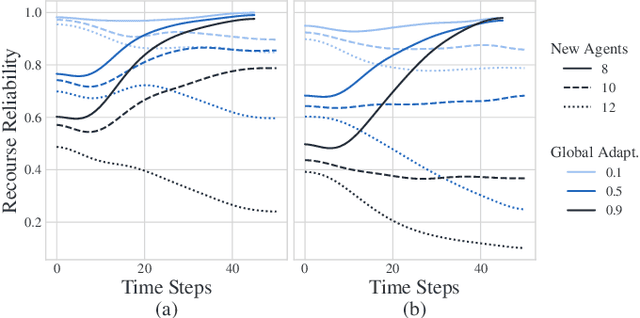
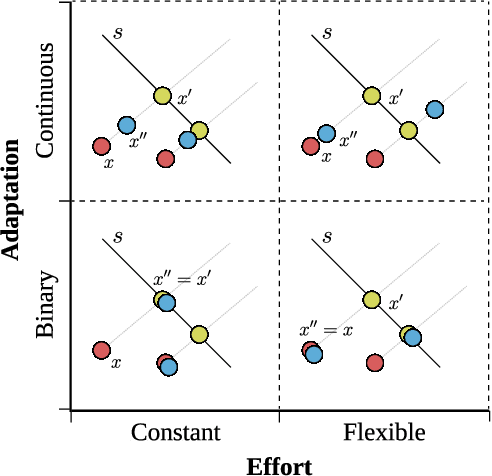
Algorithmic systems are often called upon to assist in high-stakes decision making. In light of this, algorithmic recourse, the principle wherein individuals should be able to take action against an undesirable outcome made by an algorithmic system, is receiving growing attention. The bulk of the literature on algorithmic recourse to-date focuses primarily on how to provide recourse to a single individual, overlooking a critical element: the effects of a continuously changing context. Disregarding these effects on recourse is a significant oversight, since, in almost all cases, recourse consists of an individual making a first, unfavorable attempt, and then being given an opportunity to make one or several attempts at a later date - when the context might have changed. This can create false expectations, as initial recourse recommendations may become less reliable over time due to model drift and competition for access to the favorable outcome between individuals. In this work we propose an agent-based simulation framework for studying the effects of a continuously changing environment on algorithmic recourse. In particular, we identify two main effects that can alter the reliability of recourse for individuals represented by the agents: (1) competition with other agents acting upon recourse, and (2) competition with new agents entering the environment. Our findings highlight that only a small set of specific parameterizations result in algorithmic recourse that is reliable for agents over time. Consequently, we argue that substantial additional work is needed to understand recourse reliability over time, and to develop recourse methods that reward agents' effort.
Harmonic Retrieval Using Weighted Lifted-Structure Low-Rank Matrix Completion
Nov 08, 2023In this paper, we investigate the problem of recovering the frequency components of a mixture of $K$ complex sinusoids from a random subset of $N$ equally-spaced time-domain samples. Because of the random subset, the samples are effectively non-uniform. Besides, the frequency values of each of the $K$ complex sinusoids are assumed to vary continuously within a given range. For this problem, we propose a two-step strategy: (i) we first lift the incomplete set of uniform samples (unavailable samples are treated as missing data) into a structured matrix with missing entries, which is potentially low-rank; then (ii) we complete the matrix using a weighted nuclear minimization problem. We call the method a \emph{ weighted lifted-structured (WLi) low-rank matrix recovery}. Our approach can be applied to a range of matrix structures such as Hankel and double-Hankel, among others, and provides improvement over the unweighted existing schemes such as EMaC and DEMaC. We provide theoretical guarantees for the proposed method, as well as numerical simulations in both noiseless and noisy settings. Both the theoretical and the numerical results confirm the superiority of the proposed approach.