 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-box Adversarial Transferability: An Empirical Study in Cybersecurity Perspective
Apr 15, 2024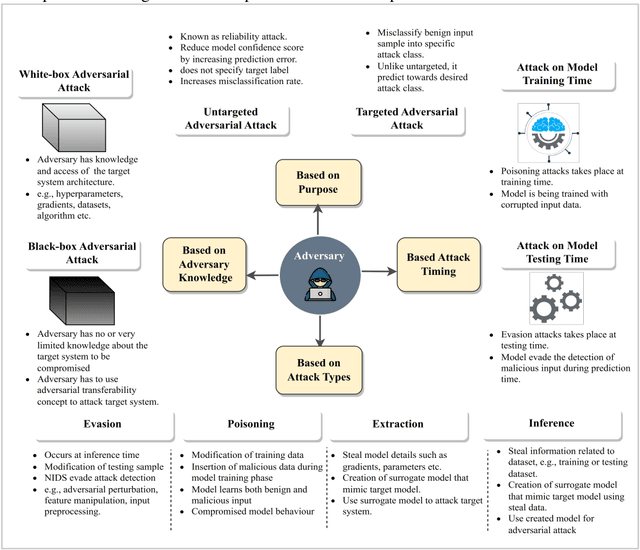
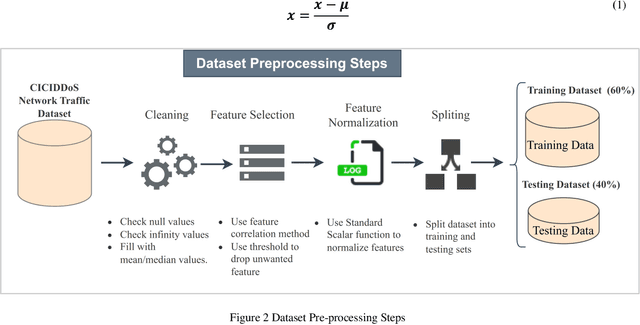
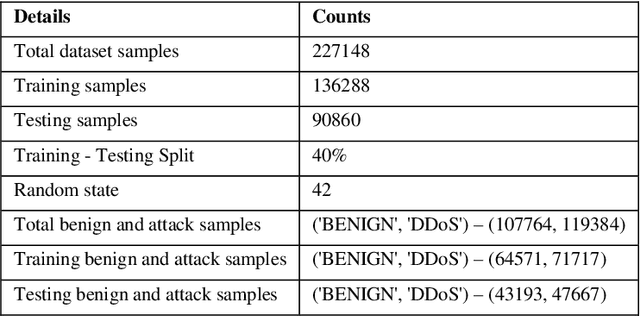
The rapid advancement of artificial intelligence within the realm of cybersecurity raises significant security concerns. The vulnerability of deep learning models in adversarial attacks is one of the major issues. In adversarial machine learning, malicious users try to fool the deep learning model by inserting adversarial perturbation inputs into the model during its training or testing phase. Subsequently, it reduces the model confidence score and results in incorrect classifications. The novel key contribution of the research is to empirically test the black-box adversarial transferability phenomena in cyber attack detection systems. It indicates that the adversarial perturbation input generated through the surrogate model has a similar impact on the target model in producing the incorrect classification. To empirically validate this phenomenon, surrogate and target models are used. The adversarial perturbation inputs are generated based on the surrogate-model for which the hacker has complete information. Based on these adversarial perturbation inputs, both surrogate and target models are evaluated during the inference phase. We have done extensive experimentation over the CICDDoS-2019 dataset, and the results are classified in terms of various performance metrics like accuracy, precision, recall, and f1-score. The findings indicate that any deep learning model is highly susceptible to adversarial attacks, even if the attacker does not have access to the internal details of the target model. The results also indicate that white-box adversarial attacks have a severe impact compared to black-box adversarial attacks. There is a need to investigate and explore adversarial defence techniques to increase the robustness of the deep learning models against adversarial attacks.
Untargeted White-box Adversarial Attack with Heuristic Defence Methods in Real-time Deep Learning based Network Intrusion Detection System
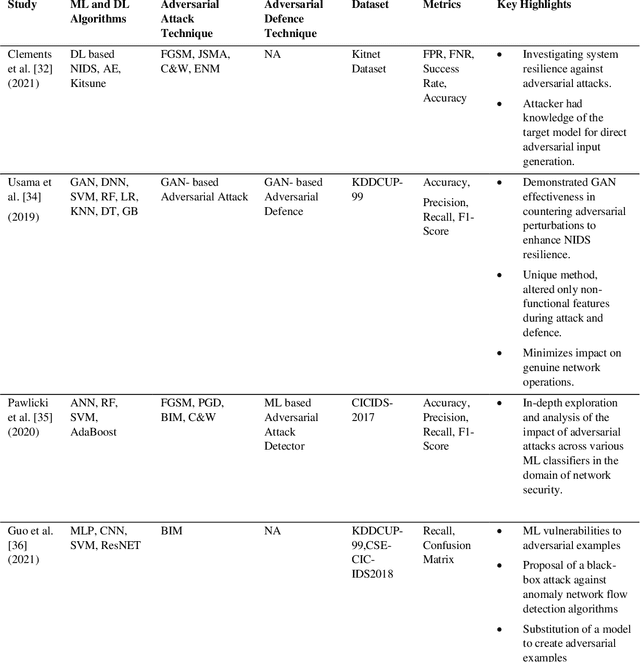
Oct 07, 2023Network Intrusion Detection System (NIDS) is a key component in securing the computer network from various cyber security threats and network attacks. However, consider an unfortunate situation where the NIDS is itself attacked and vulnerable more specifically, we can say, How to defend the defender?. In Adversarial Machine Learning (AML), the malicious actors aim to fool the Machine Learning (ML) and Deep Learning (DL) models to produce incorrect predictions with intentionally crafted adversarial examples. These adversarial perturbed examples have become the biggest vulnerability of ML and DL based systems and are major obstacles to their adoption in real-time and mission-critical applications such as NIDS. AML is an emerging research domain, and it has become a necessity for the in-depth study of adversarial attacks and their defence strategies to safeguard the computer network from various cyber security threads. In this research work, we aim to cover important aspects related to NIDS, adversarial attacks and its defence mechanism to increase the robustness of the ML and DL based NIDS. We implemented four powerful adversarial attack techniques, namely, Fast Gradient Sign Method (FGSM), Jacobian Saliency Map Attack (JSMA), Projected Gradient Descent (PGD) and Carlini & Wagner (C&W) in NIDS. We analyzed its performance in terms of various performance metrics in detail. Furthermore, the three heuristics defence strategies, i.e., Adversarial Training (AT), Gaussian Data Augmentation (GDA) and High Confidence (HC), are implemented to improve the NIDS robustness under adversarial attack situations. The complete workflow is demonstrated in real-time network with data packet flow. This research work provides the overall background for the researchers interested in AML and its implementation from a computer network security point of view.
A Novel Deep Learning based Model to Defend Network Intrusion Detection System against Adversarial Attacks
Jul 31, 2023Network Intrusion Detection System (NIDS) is an essential tool in securing cyberspace from a variety of security risks and unknown cyberattacks. A number of solutions have been implemented for Machine Learning (ML), and Deep Learning (DL) based NIDS. However, all these solutions are vulnerable to adversarial attacks, in which the malicious actor tries to evade or fool the model by injecting adversarial perturbed examples into the system. The main aim of this research work is to study powerful adversarial attack algorithms and their defence method on DL-based NIDS. Fast Gradient Sign Method (FGSM), Jacobian Saliency Map Attack (JSMA), Projected Gradient Descent (PGD) and Carlini & Wagner (C&W) are four powerful adversarial attack methods implemented against the NIDS. As a defence method, Adversarial Training is used to increase the robustness of the NIDS model. The results are summarized in three phases, i.e., 1) before the adversarial attack, 2) after the adversarial attack, and 3) after the adversarial defence. The Canadian Institute for Cybersecurity Intrusion Detection System 2017 (CICIDS-2017) dataset is used for evaluation purposes with various performance measurements like f1-score, accuracy etc.
Using Kernel SHAP XAI Method to optimize the Network Anomaly Detection Model
Jul 31, 2023



Anomaly detection and its explanation is important in many research areas such as intrusion detection, fraud detection, unknown attack detection in network traffic and logs. It is challenging to identify the cause or explanation of why one instance is an anomaly? and the other is not due to its unbounded and lack of supervisory nature. The answer to this question is possible with the emerging technique of explainable artificial intelligence (XAI). XAI provides tools and techniques to interpret and explain the output and working of complex models such as Deep Learning (DL). This paper aims to detect and explain network anomalies with XAI, kernelSHAP method. The same approach is used to improve the network anomaly detection model in terms of accuracy, recall, precision and f score. The experiment is conduced with the latest CICIDS2017 dataset. Two models are created (Model_1 and OPT_Model) and compared. The overall accuracy and F score of OPT_Model (when trained in unsupervised way) are 0.90 and 0.76, respectively.
Utilizing XAI technique to improve autoencoder based model for computer network anomaly detection with shapley additive explanation(SHAP)
Dec 14, 2021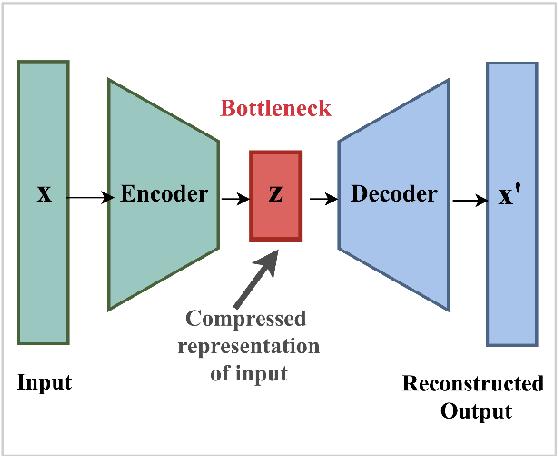

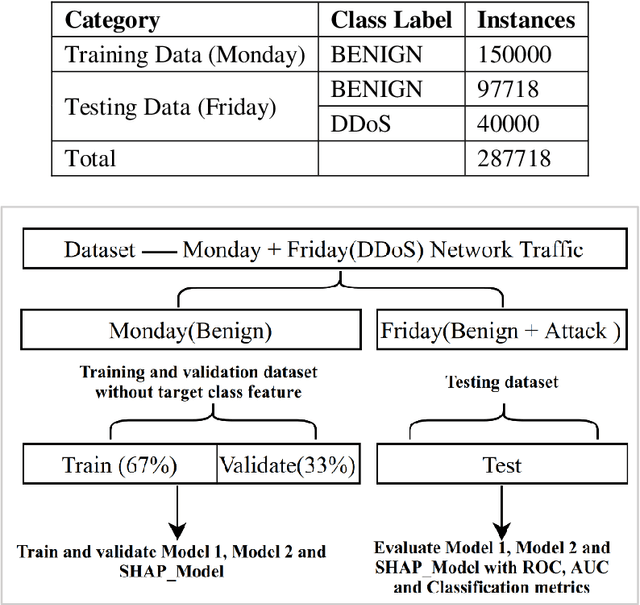

Machine learning (ML) and Deep Learning (DL) methods are being adopted rapidly, especially in computer network security, such as fraud detection, network anomaly detection, intrusion detection, and much more. However, the lack of transparency of ML and DL based models is a major obstacle to their implementation and criticized due to its black-box nature, even with such tremendous results. Explainable Artificial Intelligence (XAI) is a promising area that can improve the trustworthiness of these models by giving explanations and interpreting its output. If the internal working of the ML and DL based models is understandable, then it can further help to improve its performance. The objective of this paper is to show that how XAI can be used to interpret the results of the DL model, the autoencoder in this case. And, based on the interpretation, we improved its performance for computer network anomaly detection. The kernel SHAP method, which is based on the shapley values, is used as a novel feature selection technique. This method is used to identify only those features that are actually causing the anomalous behaviour of the set of attack/anomaly instances. Later, these feature sets are used to train and validate the autoencoder but on benign data only. Finally, the built SHAP_Model outperformed the other two models proposed based on the feature selection method. This whole experiment is conducted on the subset of the latest CICIDS2017 network dataset. The overall accuracy and AUC of SHAP_Model is 94% and 0.969, respectively.
* 20 pages, 12 figures, 4 tables, journal article