 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainerPFN: Towards tabular foundation models for model-free zero-shot feature importance estimations
Jan 30, 2026Computing the importance of features in supervised classification tasks is critical for model interpretability. Shapley values are a widely used approach for explaining model predictions, but require direct access to the underlying model, an assumption frequently violated in real-world deployments. Further, even when model access is possible, their exact computation may be prohibitively expensive. We investigate whether meaningful Shapley value estimations can be obtained in a zero-shot setting, using only the input data distribution and no evaluations of the target model. To this end, we introduce ExplainerPFN, a tabular foundation model built on TabPFN that is pretrained on synthetic datasets generated from random structural causal models and supervised using exact or near-exact Shapley values. Once trained, ExplainerPFN predicts feature attributions for unseen tabular datasets without model access, gradients, or example explanations. Our contributions are fourfold: (1) we show that few-shot learning-based explanations can achieve high fidelity to SHAP values with as few as two reference observations; (2) we propose ExplainerPFN, the first zero-shot method for estimating Shapley values without access to the underlying model or reference explanations; (3) we provide an open-source implementation of ExplainerPFN, including the full training pipeline and synthetic data generator; and (4) through extensive experiments on real and synthetic datasets, we show that ExplainerPFN achieves performance competitive with few-shot surrogate explainers that rely on 2-10 SHAP examples.
SHAP-based Explanations are Sensitive to Feature Representation
May 13, 2025



Local feature-based explanations are a key component of the XAI toolkit. These explanations compute feature importance values relative to an ``interpretable'' feature representation. In tabular data, feature values themselves are often considered interpretable. This paper examines the impact of data engineering choices on local feature-based explanations. We demonstrate that simple, common data engineering techniques, such as representing age with a histogram or encoding race in a specific way, can manipulate feature importance as determined by popular methods like SHAP. Notably, the sensitivity of explanations to feature representation can be exploited by adversaries to obscure issues like discrimination. While the intuition behind these results is straightforward, their systematic exploration has been lacking. Previous work has focused on adversarial attacks on feature-based explainers by biasing data or manipulating models. To the best of our knowledge, this is the first study demonstrating that explainers can be misled by standard, seemingly innocuous data engineering techniques.
Safeguarding Large Language Models in Real-time with Tunable Safety-Performance Trade-offs
Jan 02, 2025



Large Language Models (LLMs) have been shown to be susceptible to jailbreak attacks, or adversarial attacks used to illicit high risk behavior from a model. Jailbreaks have been exploited by cybercriminals and blackhat actors to cause significant harm, highlighting the critical need to safeguard widely-deployed models. Safeguarding approaches, which include fine-tuning models or having LLMs "self-reflect", may lengthen the inference time of a model, incur a computational penalty, reduce the semantic fluency of an output, and restrict ``normal'' model behavior. Importantly, these Safety-Performance Trade-offs (SPTs) remain an understudied area. In this work, we introduce a novel safeguard, called SafeNudge, that combines Controlled Text Generation with "nudging", or using text interventions to change the behavior of a model. SafeNudge triggers during text-generation while a jailbreak attack is being executed, and can reduce successful jailbreak attempts by 30% by guiding the LLM towards a safe responses. It adds minimal latency to inference and has a negligible impact on the semantic fluency of outputs. Further, we allow for tunable SPTs. SafeNudge is open-source and available through https://pypi.org/, and is compatible with models loaded with the Hugging Face "transformers" library.
Output Scouting: Auditing Large Language Models for Catastrophic Responses
Oct 04, 2024



Recent high profile incidents in which the use of Large Language Models (LLMs) resulted in significant harm to individuals have brought about a growing interest in AI safety. One reason LLM safety issues occur is that models often have at least some non-zero probability of producing harmful outputs. In this work, we explore the following scenario: imagine an AI safety auditor is searching for catastrophic responses from an LLM (e.g. a "yes" responses to "can I fire an employee for being pregnant?"), and is able to query the model a limited number times (e.g. 1000 times). What is a strategy for querying the model that would efficiently find those failure responses? To this end, we propose output scouting: an approach that aims to generate semantically fluent outputs to a given prompt matching any target probability distribution. We then run experiments using two LLMs and find numerous examples of catastrophic responses. We conclude with a discussion that includes advice for practitioners who are looking to implement LLM auditing for catastrophic responses. We also release an open-source toolkit (https://github.com/joaopfonseca/outputscouting) that implements our auditing framework using the Hugging Face transformers library.
Development of Machine Learning Classifiers for Blood-based Diagnosis and Prognosis of Suspected Acute Infections and Sepsis
Jul 03, 2024



We applied machine learning to the unmet medical need of rapid and accurate diagnosis and prognosis of acute infections and sepsis in emergency departments. Our solution consists of a Myrna (TM) Instrument and embedded TriVerity (TM) classifiers. The instrument measures abundances of 29 messenger RNAs in patient's blood, subsequently used as features for machine learning. The classifiers convert the input features to an intuitive test report comprising the separate likelihoods of (1) a bacterial infection (2) a viral infection, and (3) severity (need for Intensive Care Unit-level care). In internal validation, the system achieved AUROC = 0.83 on the three-class disease diagnosis (bacterial, viral, or non-infected) and AUROC = 0.77 on binary prognosis of disease severity. The Myrna, TriVerity system was granted breakthrough device designation by the United States Food and Drug Administration (FDA). This engineering manuscript teaches the standard and novel machine learning methods used to translate an academic research concept to a clinical product aimed at improving patient care, and discusses lessons learned.
ShaRP: Explaining Rankings with Shapley Values
Jan 30, 2024



Algorithmic decisions in critical domains such as hiring, college admissions, and lending are often based on rankings. Because of the impact these decisions have on individuals, organizations, and population groups, there is a need to understand them: to know whether the decisions are abiding by the law, to help individuals improve their rankings, and to design better ranking procedures. In this paper, we present ShaRP (Shapley for Rankings and Preferences), a framework that explains the contributions of features to different aspects of a ranked outcome, and is based on Shapley values. Using ShaRP, we show that even when the scoring function used by an algorithmic ranker is known and linear, the weight of each feature does not correspond to its Shapley value contribution. The contributions instead depend on the feature distributions, and on the subtle local interactions between the scoring features. ShaRP builds on the Quantitative Input Influence framework, and can compute the contributions of features for multiple Quantities of Interest, including score, rank, pair-wise preference, and top-k. Because it relies on black-box access to the ranker, ShaRP can be used to explain both score-based and learned ranking models. We show results of an extensive experimental validation of ShaRP using real and synthetic datasets, showcasing its usefulness for qualitative analysis.
Fairness in Algorithmic Recourse Through the Lens of Substantive Equality of Opportunity
Jan 29, 2024



Algorithmic recourse -- providing recommendations to those affected negatively by the outcome of an algorithmic system on how they can take action and change that outcome -- has gained attention as a means of giving persons agency in their interactions with artificial intelligence (AI) systems. Recent work has shown that even if an AI decision-making classifier is ``fair'' (according to some reasonable criteria), recourse itself may be unfair due to differences in the initial circumstances of individuals, compounding disparities for marginalized populations and requiring them to exert more effort than others. There is a need to define more methods and metrics for evaluating fairness in recourse that span a range of normative views of the world, and specifically those that take into account time. Time is a critical element in recourse because the longer it takes an individual to act, the more the setting may change due to model or data drift. This paper seeks to close this research gap by proposing two notions of fairness in recourse that are in normative alignment with substantive equality of opportunity, and that consider time. The first considers the (often repeated) effort individuals exert per successful recourse event, and the second considers time per successful recourse event. Building upon an agent-based framework for simulating recourse, this paper demonstrates how much effort is needed to overcome disparities in initial circumstances. We then proposes an intervention to improve the fairness of recourse by rewarding effort, and compare it to existing strategies.
Setting the Right Expectations: Algorithmic Recourse Over Time
Sep 13, 2023



Algorithmic systems are often called upon to assist in high-stakes decision making. In light of this, algorithmic recourse, the principle wherein individuals should be able to take action against an undesirable outcome made by an algorithmic system, is receiving growing attention. The bulk of the literature on algorithmic recourse to-date focuses primarily on how to provide recourse to a single individual, overlooking a critical element: the effects of a continuously changing context. Disregarding these effects on recourse is a significant oversight, since, in almost all cases, recourse consists of an individual making a first, unfavorable attempt, and then being given an opportunity to make one or several attempts at a later date - when the context might have changed. This can create false expectations, as initial recourse recommendations may become less reliable over time due to model drift and competition for access to the favorable outcome between individuals. In this work we propose an agent-based simulation framework for studying the effects of a continuously changing environment on algorithmic recourse. In particular, we identify two main effects that can alter the reliability of recourse for individuals represented by the agents: (1) competition with other agents acting upon recourse, and (2) competition with new agents entering the environment. Our findings highlight that only a small set of specific parameterizations result in algorithmic recourse that is reliable for agents over time. Consequently, we argue that substantial additional work is needed to understand recourse reliability over time, and to develop recourse methods that reward agents' effort.
Research Trends and Applications of Data Augmentation Algorithms
Jul 18, 2022

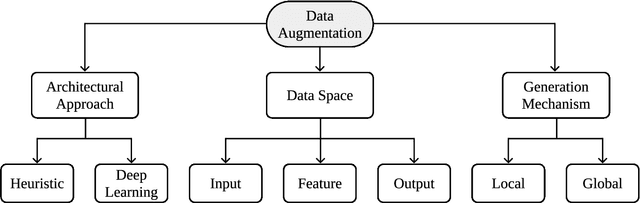
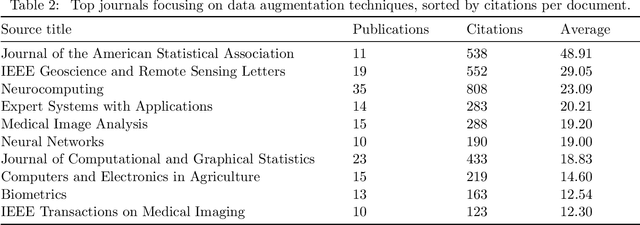
In the Machine Learning research community, there is a consensus regarding the relationship between model complexity and the required amount of data and computation power. In real world applications, these computational requirements are not always available, motivating research on regularization methods. In addition, current and past research have shown that simpler classification algorithms can reach state-of-the-art performance on computer vision tasks given a robust method to artificially augment the training dataset. Because of this, data augmentation techniques became a popular research topic in recent years. However, existing data augmentation methods are generally less transferable than other regularization methods. In this paper we identify the main areas of application of data augmentation algorithms, the types of algorithms used, significant research trends, their progression over time and research gaps in data augmentation literature. To do this, the related literature was collected through the Scopus database. Its analysis was done following network science, text mining and exploratory analysis approaches. We expect readers to understand the potential of data augmentation, as well as identify future research directions and open questions within data augmentation research.