 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
InkStream: Real-time GNN Inference on Streaming Graphs via Incremental Update
Sep 20, 2023
Classic Graph Neural Network (GNN) inference approaches, designed for static graphs, are ill-suited for streaming graphs that evolve with time. The dynamism intrinsic to streaming graphs necessitates constant updates, posing unique challenges to acceleration on GPU. We address these challenges based on two key insights: (1) Inside the $k$-hop neighborhood, a significant fraction of the nodes is not impacted by the modified edges when the model uses min or max as aggregation function; (2) When the model weights remain static while the graph structure changes, node embeddings can incrementally evolve over time by computing only the impacted part of the neighborhood. With these insights, we propose a novel method, InkStream, designed for real-time inference with minimal memory access and computation, while ensuring an identical output to conventional methods. InkStream operates on the principle of propagating and fetching data only when necessary. It uses an event-based system to control inter-layer effect propagation and intra-layer incremental updates of node embedding. InkStream is highly extensible and easily configurable by allowing users to create and process customized events. We showcase that less than 10 lines of additional user code are needed to support popular GNN models such as GCN, GraphSAGE, and GIN. Our experiments with three GNN models on four large graphs demonstrate that InkStream accelerates by 2.5-427$\times$ on a CPU cluster and 2.4-343$\times$ on two different GPU clusters while producing identical outputs as GNN model inference on the latest graph snapshot.
Real-Time Emergency Vehicle Detection using Mel Spectrograms and Regular Expressions
Sep 25, 2023In emergency situations, the movement of vehicles through city streets can be problematic due to vehicular traffic. This paper presents a method for detecting emergency vehicle sirens in real time. To derive a siren Hi-Lo audio fingerprint it was necessary to apply digital signal processing techniques and signal symbolization, contrasting against a deep neural network audio classifier feeding 280 environmental sounds and 38 Hi-Lo sirens. In both methods, their precision was evaluated based on a confusion matrix and various metrics. The precision of the developed DSP algorithm presented a greater ability to discriminate between signal and noise, compared to the CNN model.
Learning Super-Resolution Ultrasound Localization Microscopy from Radio-Frequency Data
Nov 07, 2023Ultrasound Localization Microscopy (ULM) enables imaging of vascular structures in the micrometer range by accumulating contrast agent particle locations over time. Precise and efficient target localization accuracy remains an active research topic in the ULM field to further push the boundaries of this promising medical imaging technology. Existing work incorporates Delay-And-Sum (DAS) beamforming into particle localization pipelines, which ultimately determines the ULM image resolution capability. In this paper we propose to feed unprocessed Radio-Frequency (RF) data into a super-resolution network while bypassing DAS beamforming and its limitations. To facilitate this, we demonstrate label projection and inverse point transformation between B-mode and RF coordinate space as required by our approach. We assess our method against state-of-the-art techniques based on a public dataset featuring in silico and in vivo data. Results from our RF-trained network suggest that excluding DAS beamforming offers a great potential to optimize on the ULM resolution performance.
Rethinking and Improving Multi-task Learning for End-to-end Speech Translation
Nov 07, 2023Significant improvements in end-to-end speech translation (ST) have been achieved through the application of multi-task learning. However, the extent to which auxiliary tasks are highly consistent with the ST task, and how much this approach truly helps, have not been thoroughly studied. In this paper, we investigate the consistency between different tasks, considering different times and modules. We find that the textual encoder primarily facilitates cross-modal conversion, but the presence of noise in speech impedes the consistency between text and speech representations. Furthermore, we propose an improved multi-task learning (IMTL) approach for the ST task, which bridges the modal gap by mitigating the difference in length and representation. We conduct experiments on the MuST-C dataset. The results demonstrate that our method attains state-of-the-art results. Moreover, when additional data is used, we achieve the new SOTA result on MuST-C English to Spanish task with 20.8% of the training time required by the current SOTA method.
MeVGAN: GAN-based Plugin Model for Video Generation with Applications in Colonoscopy
Nov 07, 2023Video generation is important, especially in medicine, as much data is given in this form. However, video generation of high-resolution data is a very demanding task for generative models, due to the large need for memory. In this paper, we propose Memory Efficient Video GAN (MeVGAN) - a Generative Adversarial Network (GAN) which uses plugin-type architecture. We use a pre-trained 2D-image GAN and only add a simple neural network to construct respective trajectories in the noise space, so that the trajectory forwarded through the GAN model constructs a real-life video. We apply MeVGAN in the task of generating colonoscopy videos. Colonoscopy is an important medical procedure, especially beneficial in screening and managing colorectal cancer. However, because colonoscopy is difficult and time-consuming to learn, colonoscopy simulators are widely used in educating young colonoscopists. We show that MeVGAN can produce good quality synthetic colonoscopy videos, which can be potentially used in virtual simulators.
RobustMat: Neural Diffusion for Street Landmark Patch Matching under Challenging Environments
Nov 07, 2023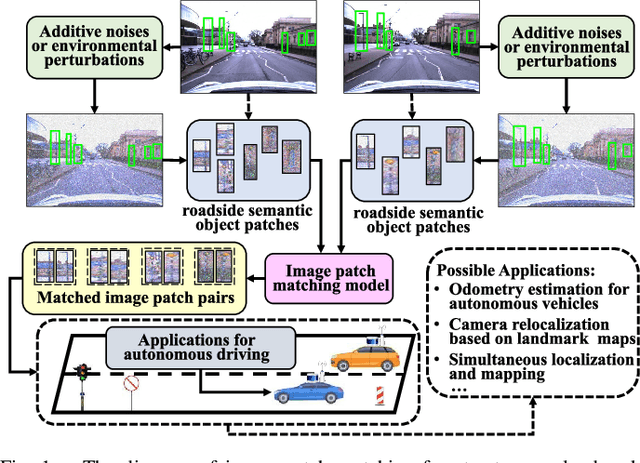
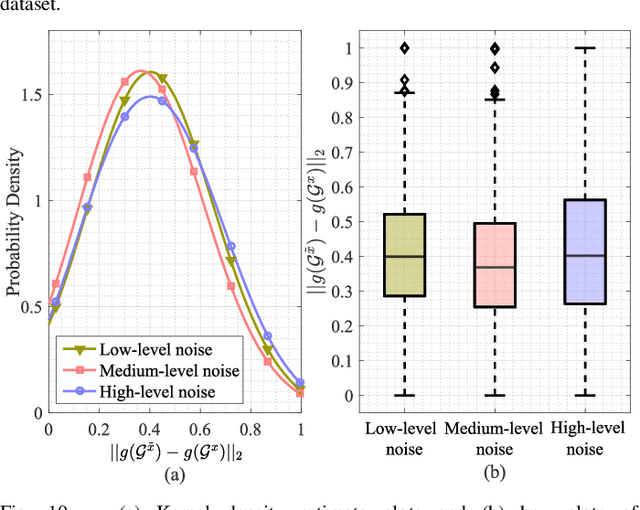
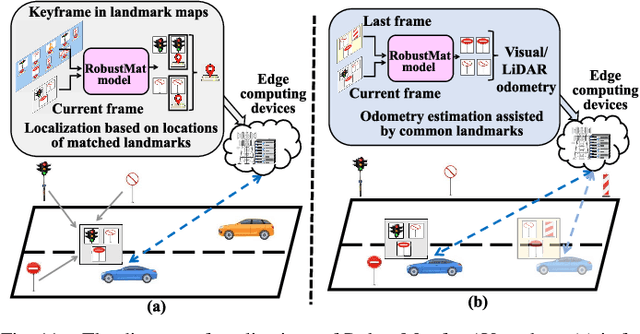
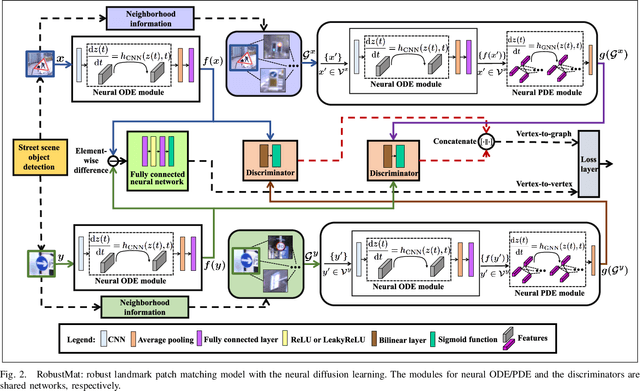
For autonomous vehicles (AVs), visual perception techniques based on sensors like cameras play crucial roles in information acquisition and processing. In various computer perception tasks for AVs, it may be helpful to match landmark patches taken by an onboard camera with other landmark patches captured at a different time or saved in a street scene image database. To perform matching under challenging driving environments caused by changing seasons, weather, and illumination, we utilize the spatial neighborhood information of each patch. We propose an approach, named RobustMat, which derives its robustness to perturbations from neural differential equations. A convolutional neural ODE diffusion module is used to learn the feature representation for the landmark patches. A graph neural PDE diffusion module then aggregates information from neighboring landmark patches in the street scene. Finally, feature similarity learning outputs the final matching score. Our approach is evaluated on several street scene datasets and demonstrated to achieve state-of-the-art matching results under environmental perturbations.
Pipeline Parallelism for DNN Inference with Practical Performance Guarantees
Nov 07, 2023We optimize pipeline parallelism for deep neural network (DNN) inference by partitioning model graphs into $k$ stages and minimizing the running time of the bottleneck stage, including communication. We design practical algorithms for this NP-hard problem and show that they are nearly optimal in practice by comparing against strong lower bounds obtained via novel mixed-integer programming (MIP) formulations. We apply these algorithms and lower-bound methods to production models to achieve substantially improved approximation guarantees compared to standard combinatorial lower bounds. For example, evaluated via geometric means across production data with $k=16$ pipeline stages, our MIP formulations more than double the lower bounds, improving the approximation ratio from $2.175$ to $1.058$. This work shows that while max-throughput partitioning is theoretically hard, we have a handle on the algorithmic side of the problem in practice and much of the remaining challenge is in developing more accurate cost models to feed into the partitioning algorithms.
Efficient Bottom-Up Synthesis for Programs with Local Variables
Nov 07, 2023We propose a new synthesis algorithm that can efficiently search programs with local variables (e.g., those introduced by lambdas). Prior bottom-up synthesis algorithms are not able to evaluate programs with free local variables, and therefore cannot effectively reduce the search space of such programs (e.g., using standard observational equivalence reduction techniques), making synthesis slow. Our algorithm can reduce the space of programs with local variables. The key idea, dubbed lifted interpretation, is to lift up the program interpretation process, from evaluating one program at a time to simultaneously evaluating all programs from a grammar. Lifted interpretation provides a mechanism to systematically enumerate all binding contexts for local variables, thereby enabling us to evaluate and reduce the space of programs with local variables. Our ideas are instantiated in the domain of web automation. The resulting tool, Arborist, can automate a significantly broader range of challenging tasks more efficiently than state-of-the-art techniques including WebRobot and Helena.
Knowledge-Based Support for Adhesive Selection: Will it Stick?
Nov 07, 2023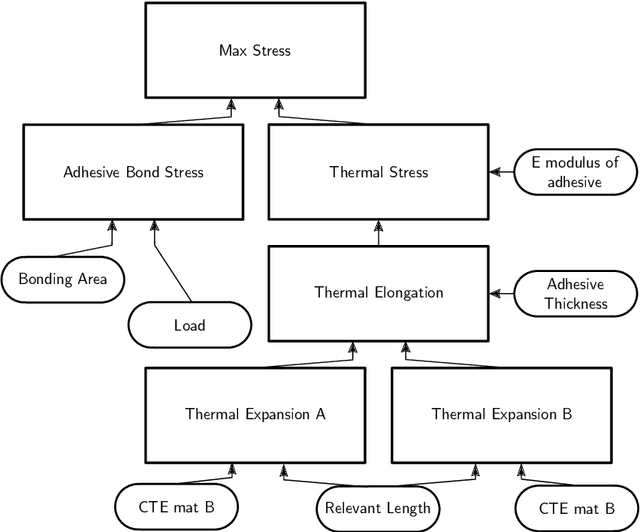

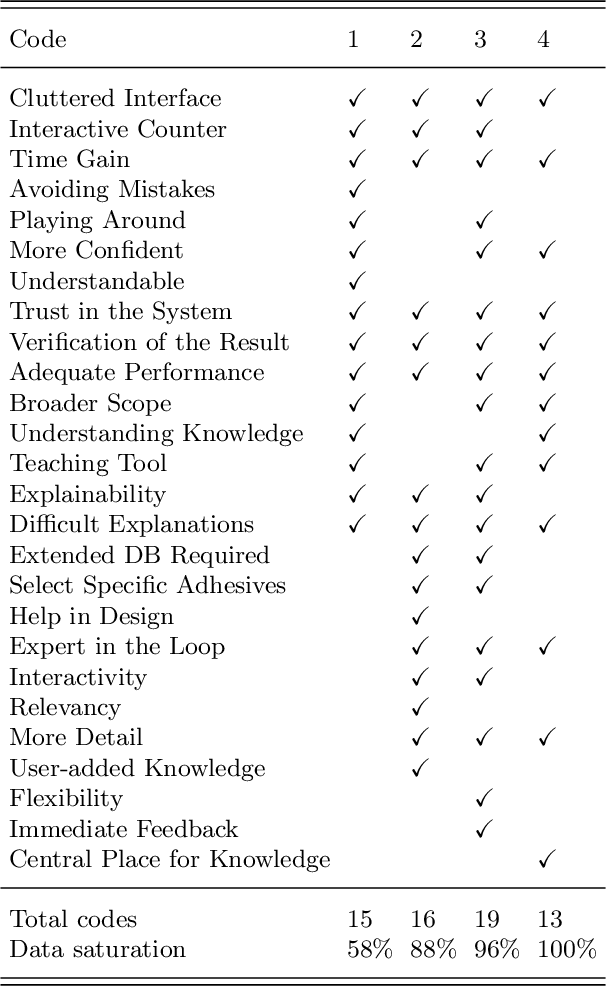
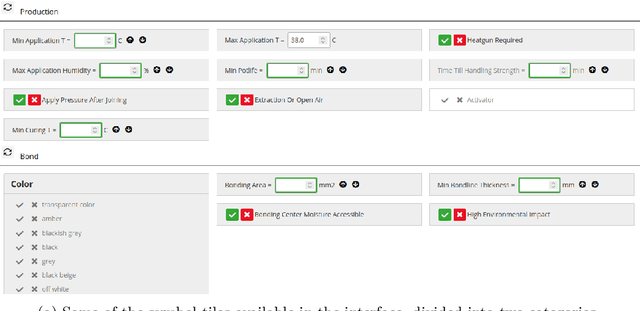
As the popularity of adhesive joints in industry increases, so does the need for tools to support the process of selecting a suitable adhesive. While some such tools already exist, they are either too limited in scope, or offer too little flexibility in use. This work presents a more advanced tool, that was developed together with a team of adhesive experts. We first extract the experts' knowledge about this domain and formalize it in a Knowledge Base (KB). The IDP-Z3 reasoning system can then be used to derive the necessary functionality from this KB. Together with a user-friendly interactive interface, this creates an easy-to-use tool capable of assisting the adhesive experts. To validate our approach, we performed user testing in the form of qualitative interviews. The experts are very positive about the tool, stating that, among others, it will help save time and find more suitable adhesives. Under consideration in Theory and Practice of Logic Programming (TPLP).
Real-Time Capable Decision Making for Autonomous Driving Using Reachable Sets
Sep 21, 2023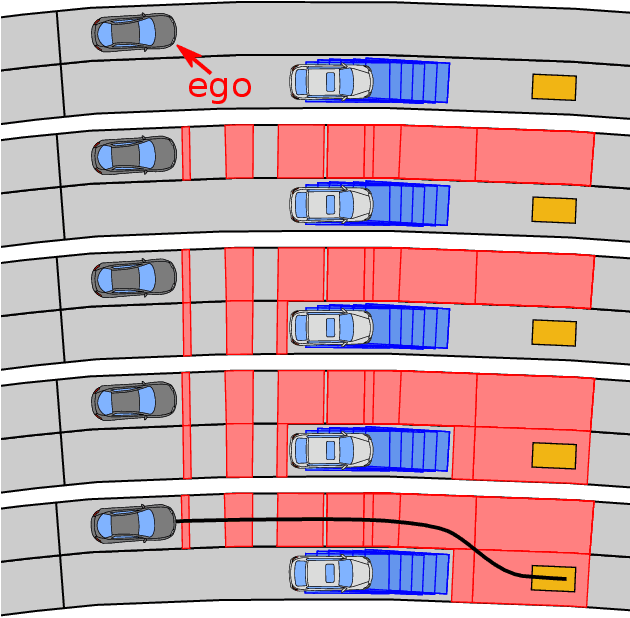
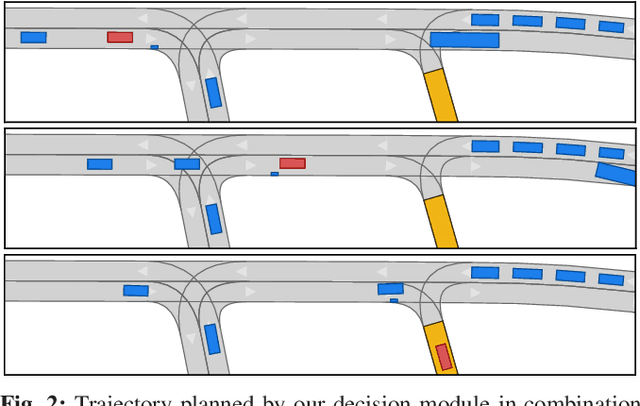
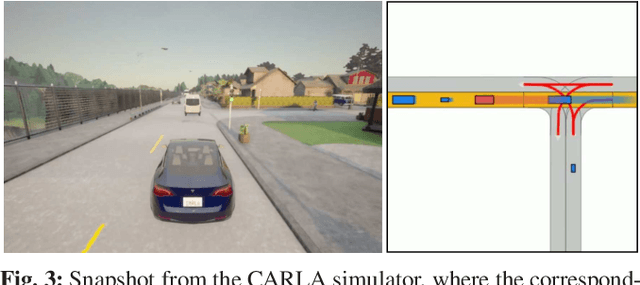
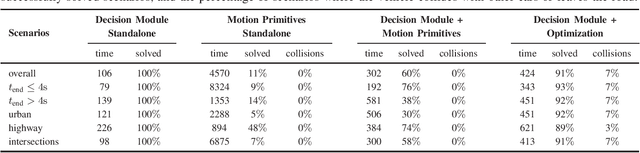
Despite large advances in recent years, real-time capable motion planning for autonomous road vehicles remains a huge challenge. In this work, we present a decision module that is based on set-based reachability analysis: First, we identify all possible driving corridors by computing the reachable set for the longitudinal position of the vehicle along the lanelets of the road network, where lane changes are modeled as discrete events. Next, we select the best driving corridor based on a cost function that penalizes lane changes and deviations from a desired velocity profile. Finally, we generate a reference trajectory inside the selected driving corridor, which can be used to guide or warm start low-level trajectory planners. For the numerical evaluation we combine our decision module with a motion-primitive-based and an optimization-based planner and evaluate the performance on 2000 challenging CommonRoad traffic scenarios as well in the realistic CARLA simulator. The results demonstrate that our decision module is real-time capable and yields significant speed-ups compared to executing a motion planner standalone without a decision module.