 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Blurry Video Compression: A Trade-off between Visual Enhancement and Data Compression
Nov 08, 2023
Existing video compression (VC) methods primarily aim to reduce the spatial and temporal redundancies between consecutive frames in a video while preserving its quality. In this regard, previous works have achieved remarkable results on videos acquired under specific settings such as instant (known) exposure time and shutter speed which often result in sharp videos. However, when these methods are evaluated on videos captured under different temporal priors, which lead to degradations like motion blur and low frame rate, they fail to maintain the quality of the contents. In this work, we tackle the VC problem in a general scenario where a given video can be blurry due to predefined camera settings or dynamics in the scene. By exploiting the natural trade-off between visual enhancement and data compression, we formulate VC as a min-max optimization problem and propose an effective framework and training strategy to tackle the problem. Extensive experimental results on several benchmark datasets confirm the effectiveness of our method compared to several state-of-the-art VC approaches.
Field Robot for High-throughput and High-resolution 3D Plant Phenotyping
Nov 05, 2023With the need to feed a growing world population, the efficiency of crop production is of paramount importance. To support breeding and field management, various characteristics of the plant phenotype need to be measured -- a time-consuming process when performed manually. We present a robotic platform equipped with multiple laser and camera sensors for high-throughput, high-resolution in-field plant scanning. We create digital twins of the plants through 3D reconstruction. This allows the estimation of phenotypic traits such as leaf area, leaf angle, and plant height. We validate our system on a real field, where we reconstruct accurate point clouds and meshes of sugar beet, soybean, and maize.
MTS-DVGAN: Anomaly Detection in Cyber-Physical Systems using a Dual Variational Generative Adversarial Network
Nov 04, 2023Deep generative models are promising in detecting novel cyber-physical attacks, mitigating the vulnerability of Cyber-physical systems (CPSs) without relying on labeled information. Nonetheless, these generative models face challenges in identifying attack behaviors that closely resemble normal data, or deviate from the normal data distribution but are in close proximity to the manifold of the normal cluster in latent space. To tackle this problem, this article proposes a novel unsupervised dual variational generative adversarial model named MST-DVGAN, to perform anomaly detection in multivariate time series data for CPS security. The central concept is to enhance the model's discriminative capability by widening the distinction between reconstructed abnormal samples and their normal counterparts. Specifically, we propose an augmented module by imposing contrastive constraints on the reconstruction process to obtain a more compact embedding. Then, by exploiting the distribution property and modeling the normal patterns of multivariate time series, a variational autoencoder is introduced to force the generative adversarial network (GAN) to generate diverse samples. Furthermore, two augmented loss functions are designed to extract essential characteristics in a self-supervised manner through mutual guidance between the augmented samples and original samples. Finally, a specific feature center loss is introduced for the generator network to enhance its stability. Empirical experiments are conducted on three public datasets, namely SWAT, WADI and NSL_KDD. Comparing with the state-of-the-art methods, the evaluation results show that the proposed MTS-DVGAN is more stable and can achieve consistent performance improvement.
* 27 pages, 14 figures, 8 tables. Accepted by Computers & Security
Computer Vision for Particle Size Analysis of Coarse-Grained Soils
Nov 11, 2023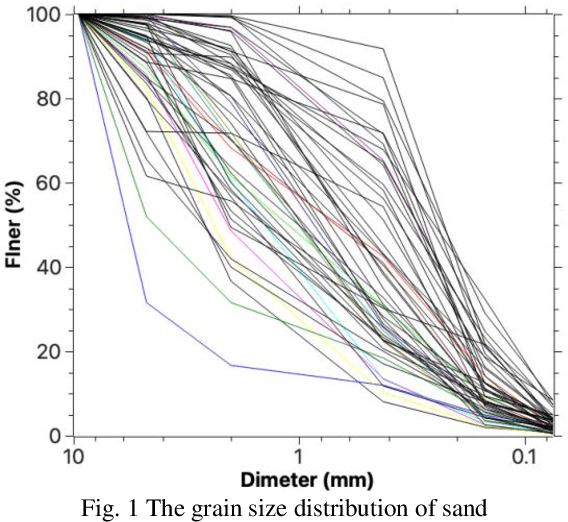
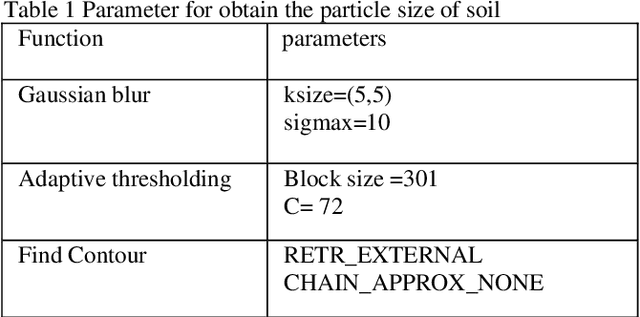
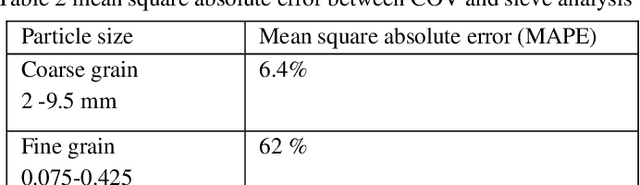

Particle size analysis (PSA) is a fundamental technique for evaluating the physical characteristics of soils. However, traditional methods like sieving can be time-consuming and labor-intensive. In this study, we present a novel approach that utilizes computer vision (CV) and the Python programming language for PSA of coarse-grained soils, employing a standard mobile phone camera. By eliminating the need for a high-performance camera, our method offers convenience and cost savings. Our methodology involves using the OPENCV library to detect and measure soil particles in digital photographs taken under ordinary lighting conditions. For accurate particle size determination, a calibration target with known dimensions is placed on a plain paper alongside 20 different sand samples. The proposed method is compared with traditional sieve analysis and exhibits satisfactory performance for soil particles larger than 2 mm, with a mean absolute percent error (MAPE) of approximately 6%. However, particles smaller than 2 mm result in higher MAPE, reaching up to 60%. To address this limitation, we recommend using a higher-resolution camera to capture images of the smaller soil particles. Furthermore, we discuss the advantages, limitations, and potential future improvements of our method. Remarkably, the program can be executed on a mobile phone, providing immediate results without the need to send soil samples to a laboratory. This field-friendly feature makes our approach highly convenient for on-site usage, outside of a traditional laboratory setting. Ultimately, this novel method represents an initial disruption to the industry, enabling efficient particle size analysis of soil without the reliance on laboratory-based sieve analysis. KEYWORDS: Computer vision, Grain size, ARUCO
Near-Optimal Min-Sum Motion Planning for Two Square Robots in a Polygonal Environment
Oct 31, 2023Let $\mathcal{W} \subset \mathbb{R}^2$ be a planar polygonal environment (i.e., a polygon potentially with holes) with a total of $n$ vertices, and let $A,B$ be two robots, each modeled as an axis-aligned unit square, that can translate inside $\mathcal{W}$. Given source and target placements $s_A,t_A,s_B,t_B \in \mathcal{W}$ of $A$ and $B$, respectively, the goal is to compute a \emph{collision-free motion plan} $\mathbf{\pi}^*$, i.e., a motion plan that continuously moves $A$ from $s_A$ to $t_A$ and $B$ from $s_B$ to $t_B$ so that $A$ and $B$ remain inside $\mathcal{W}$ and do not collide with each other during the motion. Furthermore, if such a plan exists, then we wish to return a plan that minimizes the sum of the lengths of the paths traversed by the robots, $\left|\mathbf{\pi}^*\right|$. Given $\mathcal{W}, s_A,t_A,s_B,t_B$ and a parameter $\varepsilon > 0$, we present an $n^2\varepsilon^{-O(1)} \log n$-time $(1+\varepsilon)$-approximation algorithm for this problem. We are not aware of any polynomial time algorithm for this problem, nor do we know whether the problem is NP-Hard. Our result is the first polynomial-time $(1+\varepsilon)$-approximation algorithm for an optimal motion planning problem involving two robots moving in a polygonal environment.
Traj-LO: In Defense of LiDAR-Only Odometry Using an Effective Continuous-Time Trajectory
Sep 25, 2023LiDAR Odometry is an essential component in many robotic applications. Unlike the mainstreamed approaches that focus on improving the accuracy by the additional inertial sensors, this letter explores the capability of LiDAR-only odometry through a continuous-time perspective. Firstly, the measurements of LiDAR are regarded as streaming points continuously captured at high frequency. Secondly, the LiDAR movement is parameterized by a simple yet effective continuous-time trajectory. Therefore, our proposed Traj-LO approach tries to recover the spatial-temporal consistent movement of LiDAR by tightly coupling the geometric information from LiDAR points and kinematic constraints from trajectory smoothness. This framework is generalized for different kinds of LiDAR as well as multi-LiDAR systems. Extensive experiments on the public datasets demonstrate the robustness and effectiveness of our proposed LiDAR-only approach, even in scenarios where the kinematic state exceeds the IMU's measuring range. Our implementation is open-sourced on GitHub.
Time-to-Pattern: Information-Theoretic Unsupervised Learning for Scalable Time Series Summarization
Aug 26, 2023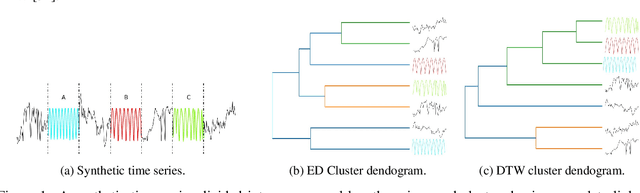
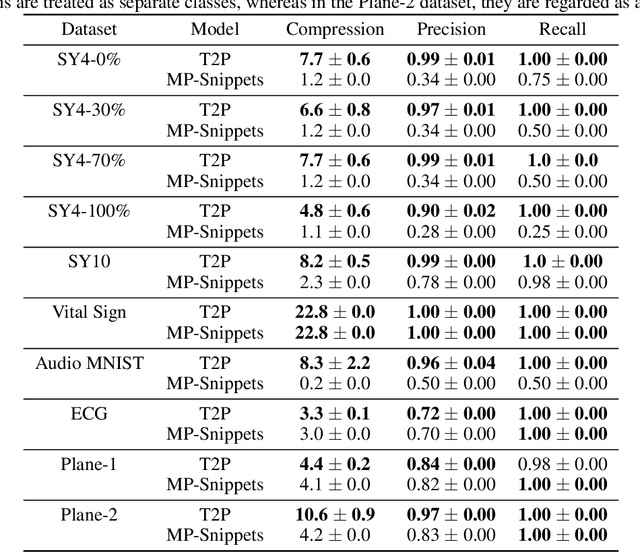
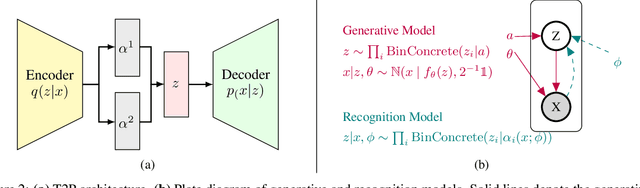

Data summarization is the process of generating interpretable and representative subsets from a dataset. Existing time series summarization approaches often search for recurring subsequences using a set of manually devised similarity functions to summarize the data. However, such approaches are fraught with limitations stemming from an exhaustive search coupled with a heuristic definition of series similarity. Such approaches affect the diversity and comprehensiveness of the generated data summaries. To mitigate these limitations, we introduce an approach to time series summarization, called Time-to-Pattern (T2P), which aims to find a set of diverse patterns that together encode the most salient information, following the notion of minimum description length. T2P is implemented as a deep generative model that learns informative embeddings of the discrete time series on a latent space specifically designed to be interpretable. Our synthetic and real-world experiments reveal that T2P discovers informative patterns, even in noisy and complex settings. Furthermore, our results also showcase the improved performance of T2P over previous work in pattern diversity and processing scalability, which conclusively demonstrate the algorithm's effectiveness for time series summarization.
Model-Based Minimum Bayes Risk Decoding
Nov 09, 2023Minimum Bayes Risk (MBR) decoding has been shown to be a powerful alternative to beam search decoding in a variety of text generation tasks. MBR decoding selects a hypothesis from a pool of hypotheses that has the least expected risk under a probability model according to a given utility function. Since it is impractical to compute the expected risk exactly over all possible hypotheses, two approximations are commonly used in MBR. First, it integrates over a sampled set of hypotheses rather than over all possible hypotheses. Second, it estimates the probability of each hypothesis using a Monte Carlo estimator. While the first approximation is necessary to make it computationally feasible, the second is not essential since we typically have access to the model probability at inference time. We propose Model-Based MBR (MBMBR), a variant of MBR that uses the model probability itself as the estimate of the probability distribution instead of the Monte Carlo estimate. We show analytically and empirically that the model-based estimate is more promising than the Monte Carlo estimate in text generation tasks. Our experiments show that MBMBR outperforms MBR in several text generation tasks, both with encoder-decoder models and with large language models.
PRODIGy: a PROfile-based DIalogue Generation dataset
Nov 09, 2023Providing dialogue agents with a profile representation can improve their consistency and coherence, leading to better conversations. However, current profile-based dialogue datasets for training such agents contain either explicit profile representations that are simple and dialogue-specific, or implicit representations that are difficult to collect. In this work, we propose a unified framework in which we bring together both standard and more sophisticated profile representations by creating a new resource where each dialogue is aligned with all possible speaker representations such as communication style, biographies, and personality. This framework allows to test several baselines built using generative language models with several profile configurations. The automatic evaluation shows that profile-based models have better generalisation capabilities than models trained on dialogues only, both in-domain and cross-domain settings. These results are consistent for fine-tuned models and instruction-based LLMs. Additionally, human evaluation demonstrates a clear preference for generations consistent with both profile and context. Finally, to account for possible privacy concerns, all experiments are done under two configurations: inter-character and intra-character. In the former, the LM stores the information about the character in its internal representation, while in the latter, the LM does not retain any personal information but uses it only at inference time.
ScribblePolyp: Scribble-Supervised Polyp Segmentation through Dual Consistency Alignment
Nov 09, 2023Automatic polyp segmentation models play a pivotal role in the clinical diagnosis of gastrointestinal diseases. In previous studies, most methods relied on fully supervised approaches, necessitating pixel-level annotations for model training. However, the creation of pixel-level annotations is both expensive and time-consuming, impeding the development of model generalization. In response to this challenge, we introduce ScribblePolyp, a novel scribble-supervised polyp segmentation framework. Unlike fully-supervised models, ScribblePolyp only requires the annotation of two lines (scribble labels) for each image, significantly reducing the labeling cost. Despite the coarse nature of scribble labels, which leave a substantial portion of pixels unlabeled, we propose a two-branch consistency alignment approach to provide supervision for these unlabeled pixels. The first branch employs transformation consistency alignment to narrow the gap between predictions under different transformations of the same input image. The second branch leverages affinity propagation to refine predictions into a soft version, extending additional supervision to unlabeled pixels. In summary, ScribblePolyp is an efficient model that does not rely on teacher models or moving average pseudo labels during training. Extensive experiments on the SUN-SEG dataset underscore the effectiveness of ScribblePolyp, achieving a Dice score of 0.8155, with the potential for a 1.8% improvement in the Dice score through a straightforward self-training strategy.