 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
3DHR-Co: A Collaborative Test-time Refinement Framework for In-the-Wild 3D Human-Body Reconstruction Task
Oct 02, 2023
The field of 3D human-body reconstruction (abbreviated as 3DHR) that utilizes parametric pose and shape representations has witnessed significant advancements in recent years. However, the application of 3DHR techniques to handle real-world, diverse scenes, known as in-the-wild data, still faces limitations. The primary challenge arises as curating accurate 3D human pose ground truth (GT) for in-the-wild scenes is still difficult to obtain due to various factors. Recent test-time refinement approaches on 3DHR leverage initial 2D off-the-shelf human keypoints information to support the lack of 3D supervision on in-the-wild data. However, we observed that additional 2D supervision alone could cause the overfitting issue on common 3DHR backbones, making the 3DHR test-time refinement task seem intractable. We answer this challenge by proposing a strategy that complements 3DHR test-time refinement work under a collaborative approach. Specifically, we initially apply a pre-adaptation approach that works by collaborating various 3DHR models in a single framework to directly improve their initial outputs. This approach is then further combined with the test-time adaptation work under specific settings that minimize the overfitting issue to further boost the 3DHR performance. The whole framework is termed as 3DHR-Co, and on the experiment sides, we showed that the proposed work can significantly enhance the scores of common classic 3DHR backbones up to -34 mm pose error suppression, putting them among the top list on the in-the-wild benchmark data. Such achievement shows that our approach helps unveil the true potential of the common classic 3DHR backbones. Based on these findings, we further investigate various settings on the proposed framework to better elaborate the capability of our collaborative approach in the 3DHR task.
Time Stretch with Continuous-Wave Lasers for Practical Fast Realtime Measurements
Sep 19, 2023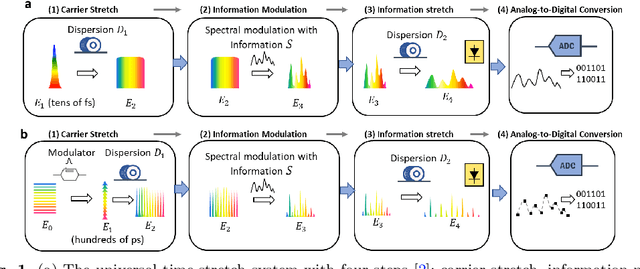
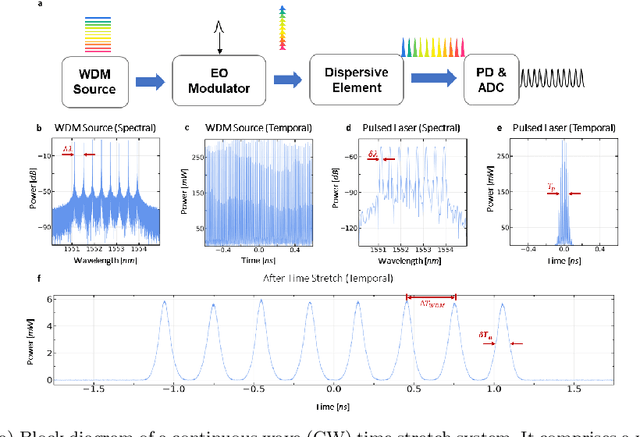
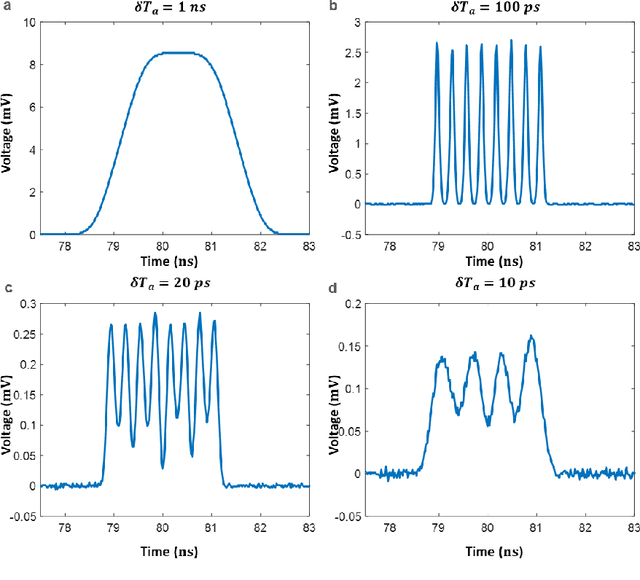
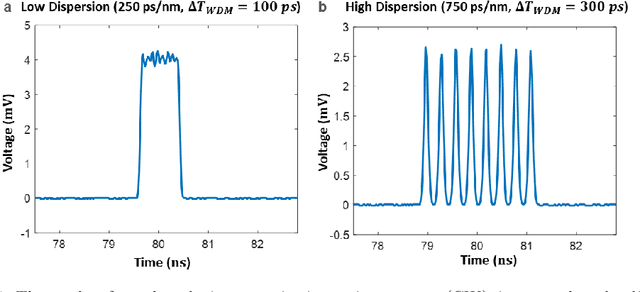
Realtime high-throughput sensing and detection enables the capture of rare events within sub-picosecond time scale, which makes it possible for scientists to uncover the mystery of ultrafast physical processes. Photonic time stretch is one of the most successful approaches that utilize the ultra-wide bandwidth of mode-locked laser for detecting ultrafast signal. Though powerful, it relies on supercontinuum mode-locked laser source, which is expensive and difficult to integrate. This greatly limits the application of this technology. Here we propose a novel Continuous Wave (CW) implementation of the photonic time stretch. Instead of a supercontinuum mode-locked laser, a wavelength division multiplexed (WDM) CW laser, pulsed by electro-optic (EO) modulation, is adopted as the laser source. This opens up the possibility for low-cost integrated time stretch systems. This new approach is validated via both simulation and experiment. Two scenarios for potential application are also described.
Towards Effective Paraphrasing for Information Disguise
Nov 08, 2023Information Disguise (ID), a part of computational ethics in Natural Language Processing (NLP), is concerned with best practices of textual paraphrasing to prevent the non-consensual use of authors' posts on the Internet. Research on ID becomes important when authors' written online communication pertains to sensitive domains, e.g., mental health. Over time, researchers have utilized AI-based automated word spinners (e.g., SpinRewriter, WordAI) for paraphrasing content. However, these tools fail to satisfy the purpose of ID as their paraphrased content still leads to the source when queried on search engines. There is limited prior work on judging the effectiveness of paraphrasing methods for ID on search engines or their proxies, neural retriever (NeurIR) models. We propose a framework where, for a given sentence from an author's post, we perform iterative perturbation on the sentence in the direction of paraphrasing with an attempt to confuse the search mechanism of a NeurIR system when the sentence is queried on it. Our experiments involve the subreddit 'r/AmItheAsshole' as the source of public content and Dense Passage Retriever as a NeurIR system-based proxy for search engines. Our work introduces a novel method of phrase-importance rankings using perplexity scores and involves multi-level phrase substitutions via beam search. Our multi-phrase substitution scheme succeeds in disguising sentences 82% of the time and hence takes an essential step towards enabling researchers to disguise sensitive content effectively before making it public. We also release the code of our approach.
* Accepted at ECIR 2023
Edge-assisted U-Shaped Split Federated Learning with Privacy-preserving for Internet of Things
Nov 08, 2023In the realm of the Internet of Things (IoT), deploying deep learning models to process data generated or collected by IoT devices is a critical challenge. However, direct data transmission can cause network congestion and inefficient execution, given that IoT devices typically lack computation and communication capabilities. Centralized data processing in data centers is also no longer feasible due to concerns over data privacy and security. To address these challenges, we present an innovative Edge-assisted U-Shaped Split Federated Learning (EUSFL) framework, which harnesses the high-performance capabilities of edge servers to assist IoT devices in model training and optimization process. In this framework, we leverage Federated Learning (FL) to enable data holders to collaboratively train models without sharing their data, thereby enhancing data privacy protection by transmitting only model parameters. Additionally, inspired by Split Learning (SL), we split the neural network into three parts using U-shaped splitting for local training on IoT devices. By exploiting the greater computation capability of edge servers, our framework effectively reduces overall training time and allows IoT devices with varying capabilities to perform training tasks efficiently. Furthermore, we proposed a novel noise mechanism called LabelDP to ensure that data features and labels can securely resist reconstruction attacks, eliminating the risk of privacy leakage. Our theoretical analysis and experimental results demonstrate that EUSFL can be integrated with various aggregation algorithms, maintaining good performance across different computing capabilities of IoT devices, and significantly reducing training time and local computation overhead.
Fine-tuning Language Models for Factuality
Nov 14, 2023The fluency and creativity of large pre-trained language models (LLMs) have led to their widespread use, sometimes even as a replacement for traditional search engines. Yet language models are prone to making convincing but factually inaccurate claims, often referred to as 'hallucinations.' These errors can inadvertently spread misinformation or harmfully perpetuate misconceptions. Further, manual fact-checking of model responses is a time-consuming process, making human factuality labels expensive to acquire. In this work, we fine-tune language models to be more factual, without human labeling and targeting more open-ended generation settings than past work. We leverage two key recent innovations in NLP to do so. First, several recent works have proposed methods for judging the factuality of open-ended text by measuring consistency with an external knowledge base or simply a large model's confidence scores. Second, the direct preference optimization algorithm enables straightforward fine-tuning of language models on objectives other than supervised imitation, using a preference ranking over possible model responses. We show that learning from automatically generated factuality preference rankings, generated either through existing retrieval systems or our novel retrieval-free approach, significantly improves the factuality (percent of generated claims that are correct) of Llama-2 on held-out topics compared with RLHF or decoding strategies targeted at factuality. At 7B scale, compared to Llama-2-chat, we observe 58% and 40% reduction in factual error rate when generating biographies and answering medical questions, respectively.
Offline Data Enhanced On-Policy Policy Gradient with Provable Guarantees
Nov 14, 2023Hybrid RL is the setting where an RL agent has access to both offline data and online data by interacting with the real-world environment. In this work, we propose a new hybrid RL algorithm that combines an on-policy actor-critic method with offline data. On-policy methods such as policy gradient and natural policy gradient (NPG) have shown to be more robust to model misspecification, though sometimes it may not be as sample efficient as methods that rely on off-policy learning. On the other hand, offline methods that depend on off-policy training often require strong assumptions in theory and are less stable to train in practice. Our new approach integrates a procedure of off-policy training on the offline data into an on-policy NPG framework. We show that our approach, in theory, can obtain a best-of-both-worlds type of result -- it achieves the state-of-art theoretical guarantees of offline RL when offline RL-specific assumptions hold, while at the same time maintaining the theoretical guarantees of on-policy NPG regardless of the offline RL assumptions' validity. Experimentally, in challenging rich-observation environments, we show that our approach outperforms a state-of-the-art hybrid RL baseline which only relies on off-policy policy optimization, demonstrating the empirical benefit of combining on-policy and off-policy learning. Our code is publicly available at https://github.com/YifeiZhou02/HNPG.
Comparison of model selection techniques for seafloor scattering statistics
Nov 14, 2023In quantitative analysis of seafloor imagery, it is common to model the collection of individual pixel intensities scattered by the seafloor as a random variable with a given statistical distribution. There is a considerable literature on statistical models for seafloor scattering, mostly focused on areas with statistically homogeneous properties (i.e. exhibiting spatial stationarity). For more complex seafloors, the pixel intensity distribution is more appropriately modeled using a mixture of simple distributions. For very complex seafloors, fitting 3 or more mixture components makes physical sense, but the statistical model becomes much more complex in these cases. Therefore, picking the number of components of the mixture model is a decision that must be made, using a priori information, or using a data driven approach. However, this information is time consuming to collect, and depends on the skill and experience of the human. Therefore, a data-driven approach is advantageous to use, and is explored in this work. Criteria for choosing a model always need to balance the trade-off for the best fit for the data on the one hand and the model complexity on the other hand. In this work, we compare several statistical model selection criteria, e.g., the Bayesian information criterion. Examples are given for SAS data collected by an autonomous underwater vehicle in a rocky environment off the coast of Bergen, Norway using data from the HISAS-1032 synthetic aperture sonar system.
Identifying Light-curve Signals with a Deep Learning Based Object Detection Algorithm. II. A General Light Curve Classification Framework
Nov 14, 2023Vast amounts of astronomical photometric data are generated from various projects, requiring significant efforts to identify variable stars and other object classes. In light of this, a general, widely applicable classification framework would simplify the task of designing custom classifiers. We present a novel deep learning framework for classifying light curves using a weakly supervised object detection model. Our framework identifies the optimal windows for both light curves and power spectra automatically, and zooms in on their corresponding data. This allows for automatic feature extraction from both time and frequency domains, enabling our model to handle data across different scales and sampling intervals. We train our model on datasets obtained from both space-based and ground-based multi-band observations of variable stars and transients. We achieve an accuracy of 87% for combined variables and transient events, which is comparable to the performance of previous feature-based models. Our trained model can be utilized directly to other missions, such as ASAS-SN, without requiring any retraining or fine-tuning. To address known issues with miscalibrated predictive probabilities, we apply conformal prediction to generate robust predictive sets that guarantee true label coverage with a given probability. Additionally, we incorporate various anomaly detection algorithms to empower our model with the ability to identify out-of-distribution objects. Our framework is implemented in the Deep-LC toolkit, which is an open-source Python package hosted on Github and PyPI.
Large Language Model-Driven Classroom Flipping: Empowering Student-Centric Peer Questioning with Flipped Interaction
Nov 14, 2023Reciprocal questioning is essential for effective teaching and learning, fostering active engagement and deeper understanding through collaborative interactions, especially in large classrooms. Can large language model (LLM), such as OpenAI's GPT (Generative Pre-trained Transformer) series, assist in this? This paper investigates a pedagogical approach of classroom flipping based on flipped interaction in LLMs. Flipped interaction involves using language models to prioritize generating questions instead of answers to prompts. We demonstrate how traditional classroom flipping techniques, including Peer Instruction and Just-in-Time Teaching (JiTT), can be enhanced through flipped interaction techniques, creating student-centric questions for hybrid teaching. In particular, we propose a workflow to integrate prompt engineering with clicker and JiTT quizzes by a poll-prompt-quiz routine and a quiz-prompt-discuss routine to empower students to self-regulate their learning capacity and enable teachers to swiftly personalize training pathways. We develop an LLM-driven chatbot software that digitizes various elements of classroom flipping and facilitates the assessment of students using these routines to deliver peer-generated questions. We have applied our LLM-driven chatbot software for teaching both undergraduate and graduate students from 2020 to 2022, effectively useful for bridging the gap between teachers and students in remote teaching during the COVID-19 pandemic years. In particular, LLM-driven classroom flipping can be particularly beneficial in large class settings to optimize teaching pace and enable engaging classroom experiences.
MetisFL: An Embarrassingly Parallelized Controller for Scalable & Efficient Federated Learning Workflows
Nov 13, 2023
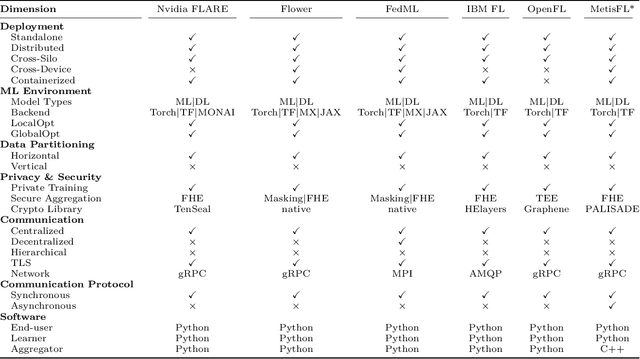
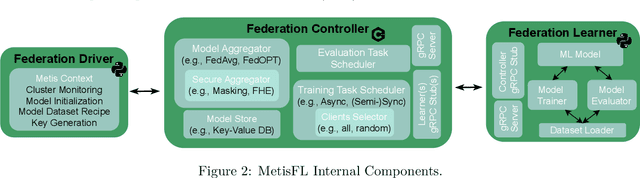
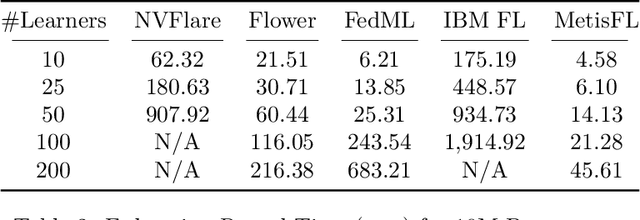
A Federated Learning (FL) system typically consists of two core processing entities: the federation controller and the learners. The controller is responsible for managing the execution of FL workflows across learners and the learners for training and evaluating federated models over their private datasets. While executing an FL workflow, the FL system has no control over the computational resources or data of the participating learners. Still, it is responsible for other operations, such as model aggregation, task dispatching, and scheduling. These computationally heavy operations generally need to be handled by the federation controller. Even though many FL systems have been recently proposed to facilitate the development of FL workflows, most of these systems overlook the scalability of the controller. To meet this need, we designed and developed a novel FL system called MetisFL, where the federation controller is the first-class citizen. MetisFL re-engineers all the operations conducted by the federation controller to accelerate the training of large-scale FL workflows. By quantitatively comparing MetisFL against other state-of-the-art FL systems, we empirically demonstrate that MetisFL leads to a 10-fold wall-clock time execution boost across a wide range of challenging FL workflows with increasing model sizes and federation sites.