 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Combinatorial Stochastic-Greedy Bandit
Dec 13, 2023
We propose a novel combinatorial stochastic-greedy bandit (SGB) algorithm for combinatorial multi-armed bandit problems when no extra information other than the joint reward of the selected set of $n$ arms at each time step $t\in [T]$ is observed. SGB adopts an optimized stochastic-explore-then-commit approach and is specifically designed for scenarios with a large set of base arms. Unlike existing methods that explore the entire set of unselected base arms during each selection step, our SGB algorithm samples only an optimized proportion of unselected arms and selects actions from this subset. We prove that our algorithm achieves a $(1-1/e)$-regret bound of $\mathcal{O}(n^{\frac{1}{3}} k^{\frac{2}{3}} T^{\frac{2}{3}} \log(T)^{\frac{2}{3}})$ for monotone stochastic submodular rewards, which outperforms the state-of-the-art in terms of the cardinality constraint $k$. Furthermore, we empirically evaluate the performance of our algorithm in the context of online constrained social influence maximization. Our results demonstrate that our proposed approach consistently outperforms the other algorithms, increasing the performance gap as $k$ grows.
Explainable Trajectory Representation through Dictionary Learning
Dec 13, 2023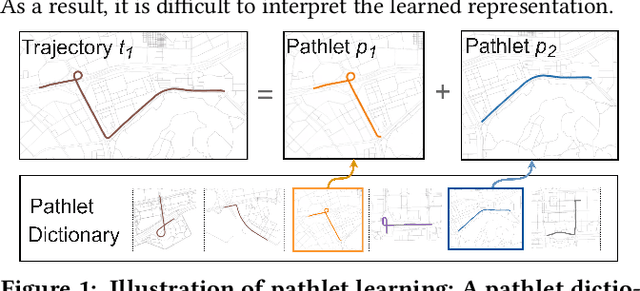

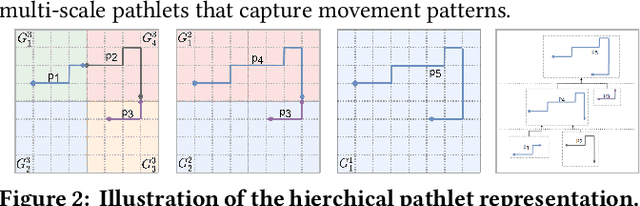
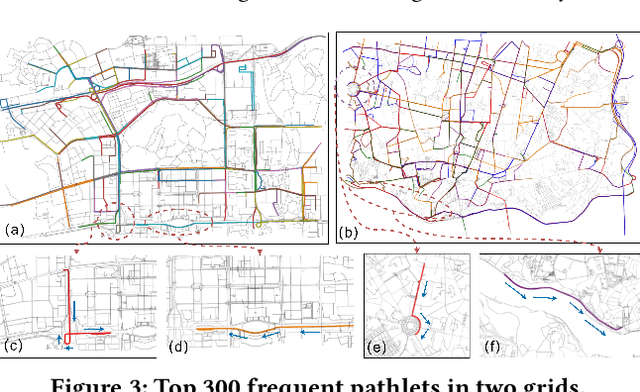
Trajectory representation learning on a network enhances our understanding of vehicular traffic patterns and benefits numerous downstream applications. Existing approaches using classic machine learning or deep learning embed trajectories as dense vectors, which lack interpretability and are inefficient to store and analyze in downstream tasks. In this paper, an explainable trajectory representation learning framework through dictionary learning is proposed. Given a collection of trajectories on a network, it extracts a compact dictionary of commonly used subpaths called "pathlets", which optimally reconstruct each trajectory by simple concatenations. The resulting representation is naturally sparse and encodes strong spatial semantics. Theoretical analysis of our proposed algorithm is conducted to provide a probabilistic bound on the estimation error of the optimal dictionary. A hierarchical dictionary learning scheme is also proposed to ensure the algorithm's scalability on large networks, leading to a multi-scale trajectory representation. Our framework is evaluated on two large-scale real-world taxi datasets. Compared to previous work, the dictionary learned by our method is more compact and has better reconstruction rate for new trajectories. We also demonstrate the promising performance of this method in downstream tasks including trip time prediction task and data compression.
Pointer Networks Trained Better via Evolutionary Algorithms
Dec 06, 2023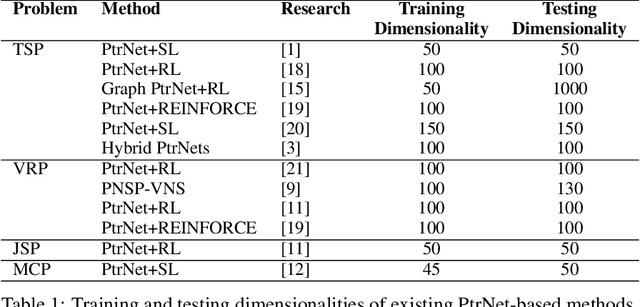
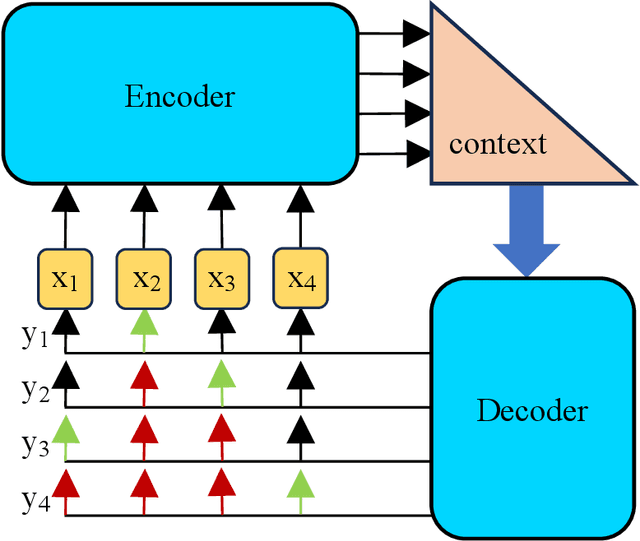
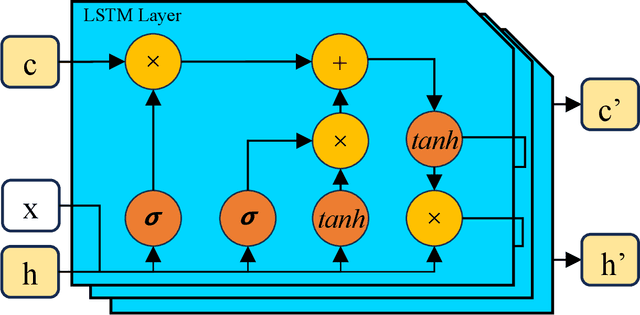
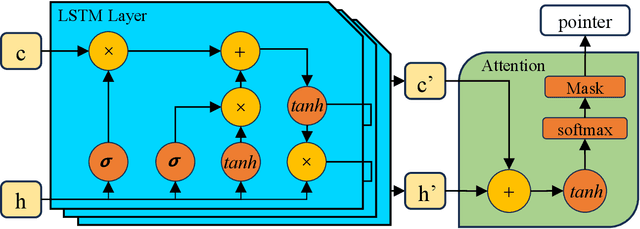
Pointer Network (PtrNet) is a specific neural network for solving Combinatorial Optimization Problems (COPs). While PtrNets offer real-time feed-forward inference for complex COPs instances, its quality of the results tends to be less satisfactory. One possible reason is that such issue suffers from the lack of global search ability of the gradient descent, which is frequently employed in traditional PtrNet training methods including both supervised learning and reinforcement learning. To improve the performance of PtrNet, this paper delves deeply into the advantages of training PtrNet with Evolutionary Algorithms (EAs), which have been widely acknowledged for not easily getting trapped by local optima. Extensive empirical studies based on the Travelling Salesman Problem (TSP) have been conducted. Results demonstrate that PtrNet trained with EA can consistently perform much better inference results than eight state-of-the-art methods on various problem scales. Compared with gradient descent based PtrNet training methods, EA achieves up to 30.21\% improvement in quality of the solution with the same computational time. With this advantage, this paper is able to at the first time report the results of solving 1000-dimensional TSPs by training a PtrNet on the same dimensionality, which strongly suggests that scaling up the training instances is in need to improve the performance of PtrNet on solving higher-dimensional COPs.
Variational Auto-Encoder Based Deep Learning Technique For Filling Gaps in Reacting PIV Data
Dec 11, 2023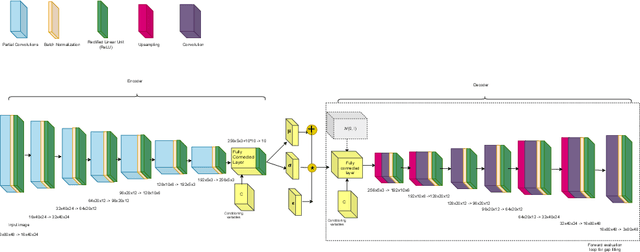
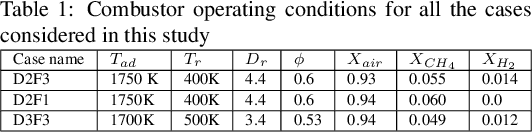
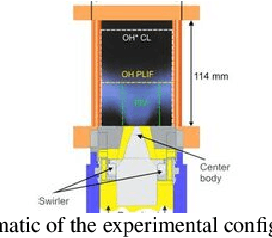
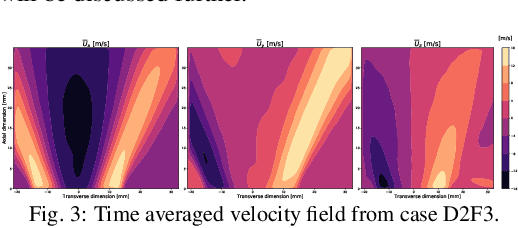
In this study, a deep learning based conditional density estimation technique known as conditional variational auto-encoder (CVAE) is used to fill gaps typically observed in particle image velocimetry (PIV) measurements in combustion systems. The proposed CVAE technique is trained using time resolved gappy PIV fields, typically observed in industrially relevant combustors. Stereo-PIV (SPIV) data from a swirl combustor with very a high vector yield is used to showcase the accuracy of the proposed CVAE technique. Various error metrics evaluated on the reconstructed velocity field in the gaps are presented from data sets corresponding to three sets of combustor operating conditions. In addition to accurate data reproduction, the proposed CVAE technique offers data compression by reducing the latent space dimension, enabling the efficient processing of large-scale PIV data.
Self-supervised Machine Learning Based Approach to Orbit Modelling Applied to Space Traffic Management
Dec 11, 2023This paper presents a novel methodology for improving the performance of machine learning based space traffic management tasks through the use of a pre-trained orbit model. Taking inspiration from BERT-like self-supervised language models in the field of natural language processing, we introduce ORBERT, and demonstrate the ability of such a model to leverage large quantities of readily available orbit data to learn meaningful representations that can be used to aid in downstream tasks. As a proof of concept of this approach we consider the task of all vs. all conjunction screening, phrased here as a machine learning time series classification task. We show that leveraging unlabelled orbit data leads to improved performance, and that the proposed approach can be particularly beneficial for tasks where the availability of labelled data is limited.
* Presented at the 2021 International Association for the Advancement of Space Safety (IAASS) Conf
Personalized Pose Forecasting
Dec 06, 2023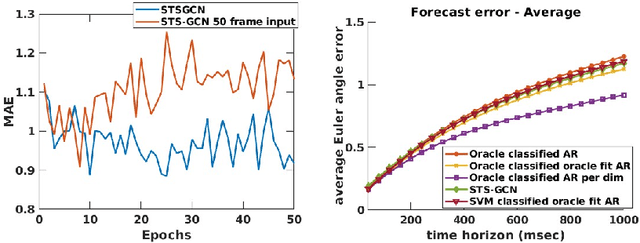
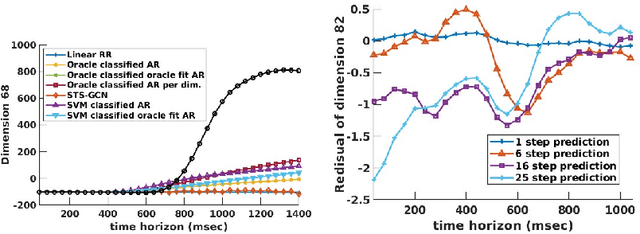
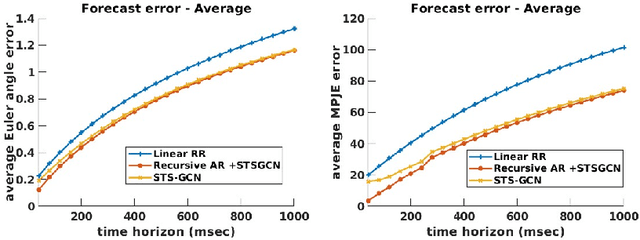
Human pose forecasting is the task of predicting articulated human motion given past human motion. There exists a number of popular benchmarks that evaluate an array of different models performing human pose forecasting. These benchmarks do not reflect that a human interacting system, such as a delivery robot, observes and plans for the motion of the same individual over an extended period of time. Every individual has unique and distinct movement patterns. This is however not reflected in existing benchmarks that evaluate a model's ability to predict an average human's motion rather than a particular individual's. We reformulate the human motion forecasting problem and present a model-agnostic personalization method. Motion forecasting personalization can be performed efficiently online by utilizing a low-parametric time-series analysis model that personalizes neural network pose predictions.
Learning Time-Invariant Representations for Individual Neurons from Population Dynamics
Nov 03, 2023Neurons can display highly variable dynamics. While such variability presumably supports the wide range of behaviors generated by the organism, their gene expressions are relatively stable in the adult brain. This suggests that neuronal activity is a combination of its time-invariant identity and the inputs the neuron receives from the rest of the circuit. Here, we propose a self-supervised learning based method to assign time-invariant representations to individual neurons based on permutation-, and population size-invariant summary of population recordings. We fit dynamical models to neuronal activity to learn a representation by considering the activity of both the individual and the neighboring population. Our self-supervised approach and use of implicit representations enable robust inference against imperfections such as partial overlap of neurons across sessions, trial-to-trial variability, and limited availability of molecular (transcriptomic) labels for downstream supervised tasks. We demonstrate our method on a public multimodal dataset of mouse cortical neuronal activity and transcriptomic labels. We report > 35% improvement in predicting the transcriptomic subclass identity and > 20% improvement in predicting class identity with respect to the state-of-the-art.
Energy-Efficient Analog Beamforming for RF-WET with Charging Time Constraint
Nov 09, 2023Internet of Things (IoT) sustainability may hinge on radio frequency wireless energy transfer (RF-WET). However, energy-efficient charging strategies are still needed, motivating our work. Specifically, this letter proposes a time division scheme to efficiently charge low-power devices in an IoT network. For this, a multi-antenna power beacon (PB) drives the devices' energy harvesting circuit to the highest power conversion efficiency point via energy beamforming, thus achieving minimum energy consumption. Herein, we adopt the analog multi-antenna architecture due to its low complexity, cost, and energy consumption. The proposal includes a simple yet accurate model for the transfer characteristic of the energy harvesting circuit, enabling the optimization framework. The results evince the effectiveness of our RF-WET strategy over a benchmark scheme where the PB charges all the IoT devices simultaneously. Furthermore, the performance increases with the number of PB antennas.
Brain Diffuser with Hierarchical Transformer for MCI Causality Analysis
Dec 14, 2023Effective connectivity estimation plays a crucial role in understanding the interactions and information flow between different brain regions. However, the functional time series used for estimating effective connentivity is derived from certain software, which may lead to large computing errors because of different parameter settings and degrade the ability to model complex causal relationships between brain regions. In this paper, a brain diffuser with hierarchical transformer (BDHT) is proposed to estimate effective connectivity for mild cognitive impairment (MCI) analysis. To our best knowledge, the proposed brain diffuer is the first generative model to apply diffusion models in the application of generating and analyzing multimodal brain networks. Specifically, the BDHT leverages the structural connectivity to guide the reverse processes in an efficient way. It makes the denoising process more reliable and guarantees effective connectivity estimation accuracy. To improve denoising quality, the hierarchical denoising transformer is designed to learn multi-scale features in topological space. Furthermore, the GraphConFormer block can concentrate on both global and adjacent connectivity information. By stacking the multi-head attention and graph convolutional network, the proposed model enhances structure-function complementarity and improves the ability in noise estimation. Experimental evaluations of the denoising diffusion model demonstrate its effectiveness in estimating effective connectivity. The method achieves superior performance in terms of accuracy and robustness compared to existing approaches. It can captures both unidirectal and bidirectional interactions between brain regions, providing a comprehensive understanding of the brain's information processing mechanisms.
Automating reward function configuration for drug design
Dec 15, 2023Designing reward functions that guide generative molecular design (GMD) algorithms to desirable areas of chemical space is of critical importance in AI-driven drug discovery. Traditionally, this has been a manual and error-prone task; the selection of appropriate computational methods to approximate biological assays is challenging and the aggregation of computed values into a single score even more so, leading to potential reliance on trial-and-error approaches. We propose a novel approach for automated reward configuration that relies solely on experimental data, mitigating the challenges of manual reward adjustment on drug discovery projects. Our method achieves this by constructing a ranking over experimental data based on Pareto dominance over the multi-objective space, then training a neural network to approximate the reward function such that rankings determined by the predicted reward correlate with those determined by the Pareto dominance relation. We validate our method using two case studies. In the first study we simulate Design-Make-Test-Analyse (DMTA) cycles by alternating reward function updates and generative runs guided by that function. We show that the learned function adapts over time to yield compounds that score highly with respect to evaluation functions taken from the literature. In the second study we apply our algorithm to historical data from four real drug discovery projects. We show that our algorithm yields reward functions that outperform the predictive accuracy of human-defined functions, achieving an improvement of up to 0.4 in Spearman's correlation against a ground truth evaluation function that encodes the target drug profile for that project. Our method provides an efficient data-driven way to configure reward functions for GMD, and serves as a strong baseline for future research into transformative approaches for the automation of drug discovery.