 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Continual Class Incremental Learning for CT Thoracic Segmentation
Aug 12, 2020
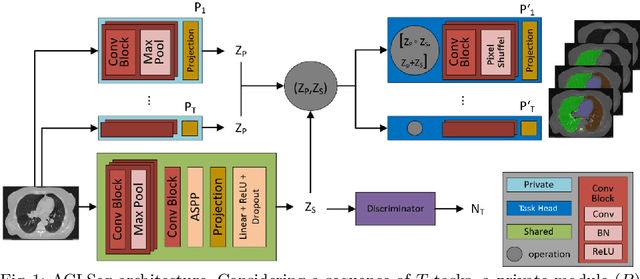


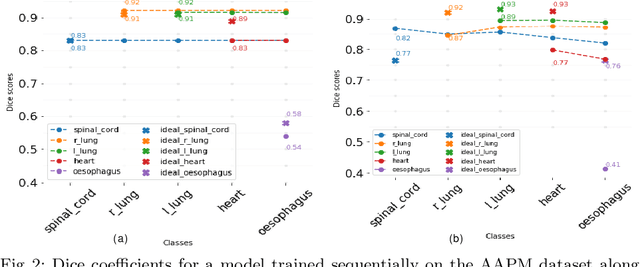
Deep learning organ segmentation approaches require large amounts of annotated training data, which is limited in supply due to reasons of confidentiality and the time required for expert manual annotation. Therefore, being able to train models incrementally without having access to previously used data is desirable. A common form of sequential training is fine tuning (FT). In this setting, a model learns a new task effectively, but loses performance on previously learned tasks. The Learning without Forgetting (LwF) approach addresses this issue via replaying its own prediction for past tasks during model training. In this work, we evaluate FT and LwF for class incremental learning in multi-organ segmentation using the publicly available AAPM dataset. We show that LwF can successfully retain knowledge on previous segmentations, however, its ability to learn a new class decreases with the addition of each class. To address this problem we propose an adversarial continual learning segmentation approach (ACLSeg), which disentangles feature space into task-specific and task-invariant features. This enables preservation of performance on past tasks and effective acquisition of new knowledge.
Optimal Assistance for Object-Rearrangement Tasks in Augmented Reality
Oct 14, 2020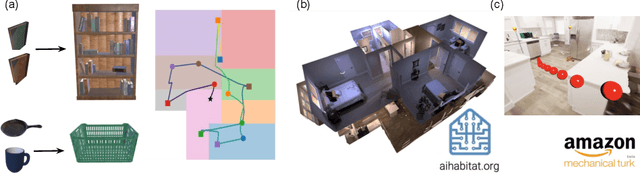
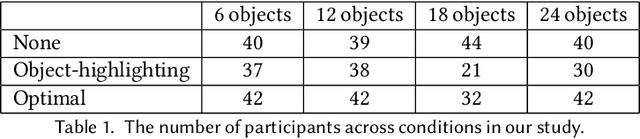
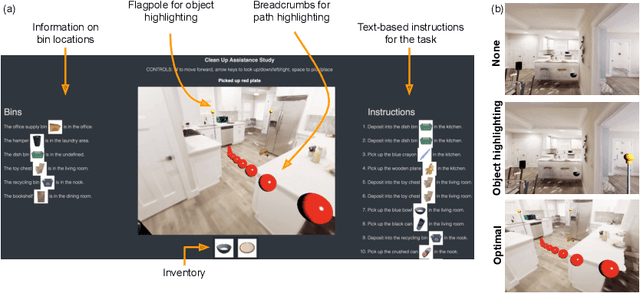
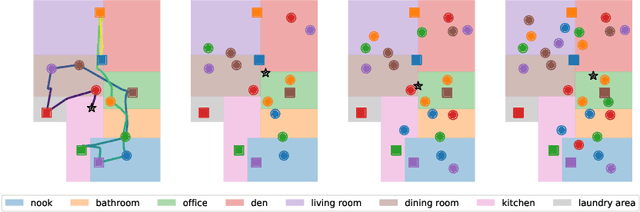
Augmented-reality (AR) glasses that will have access to onboard sensors and an ability to display relevant information to the user present an opportunity to provide user assistance in quotidian tasks. Many such tasks can be characterized as object-rearrangement tasks. We introduce a novel framework for computing and displaying AR assistance that consists of (1) associating an optimal action sequence with the policy of an embodied agent and (2) presenting this sequence to the user as suggestions in the AR system's heads-up display. The embodied agent comprises a "hybrid" between the AR system and the user, with the AR system's observation space (i.e., sensors) and the user's action space (i.e., task-execution actions); its policy is learned by minimizing the task-completion time. In this initial study, we assume that the AR system's observations include the environment's map and localization of the objects and the user. These choices allow us to formalize the problem of computing AR assistance for any object-rearrangement task as a planning problem, specifically as a capacitated vehicle-routing problem. Further, we introduce a novel AR simulator that can enable web-based evaluation of AR-like assistance and associated at-scale data collection via the Habitat simulator for embodied artificial intelligence. Finally, we perform a study that evaluates user response to the proposed form of AR assistance on a specific quotidian object-rearrangement task, house cleaning, using our proposed AR simulator on mechanical turk. In particular, we study the effect of the proposed AR assistance on users' task performance and sense of agency over a range of task difficulties. Our results indicate that providing users with such assistance improves their overall performance and while users report a negative impact to their agency, they may still prefer the proposed assistance to having no assistance at all.
Simulation of an Elevator Group Control Using Generative Adversarial Networks and Related AI Tools
Sep 03, 2020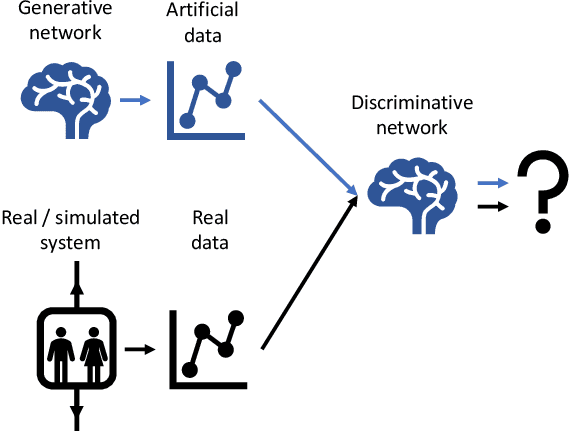

Testing new, innovative technologies is a crucial task for safety and acceptance. But how can new systems be tested if no historical real-world data exist? Simulation provides an answer to this important question. Classical simulation tools such as event-based simulation are well accepted. But most of these established simulation models require the specification of many parameters. Furthermore, simulation runs, e.g., CFD simulations, are very time consuming. Generative Adversarial Networks (GANs) are powerful tools for generating new data for a variety of tasks. Currently, their most frequent application domain is image generation. This article investigates the applicability of GANs for imitating simulations. We are comparing the simulation output of a technical system with the output of a GAN. To exemplify this approach, a well-known multi-car elevator system simulator was chosen. Our study demonstrates the feasibility of this approach. It also discusses pitfalls and technical problems that occurred during the implementation. Although we were able to show that in principle, GANs can be used as substitutes for expensive simulation runs, we also show that they cannot be used "out of the box". Fine tuning is needed. We present a proof-of-concept, which can serve as a starting point for further research.
Exploiting the Surrogate Gap in Online Multiclass Classification
Jul 24, 2020
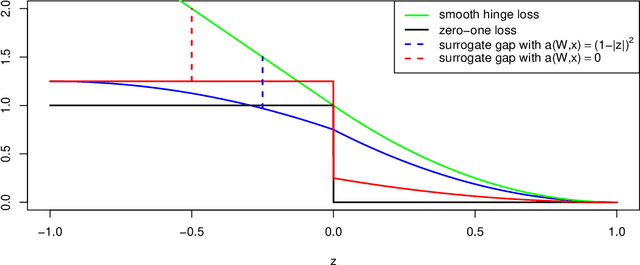
We present Gaptron, a randomized first-order algorithm for online multiclass classification. In the full information setting we show expected mistake bounds with respect to the logistic loss, hinge loss, and the smooth hinge loss with constant regret, where the expectation is with respect to the learner's randomness. In the bandit classification setting we show that Gaptron is the first linear time algorithm with $O(K\sqrt{T})$ expected regret, where $K$ is the number of classes. Additionally, the expected mistake bound of Gaptron does not depend on the dimension of the feature vector, contrary to previous algorithms with $O(K\sqrt{T})$ regret in the bandit classification setting. We present a new proof technique that exploits the gap between the zero-one loss and surrogate losses rather than exploiting properties such as exp-concavity or mixability, which are traditionally used to prove logarithmic or constant regret bounds.
A Study on Effects of Implicit and Explicit Language Model Information for DBLSTM-CTC Based Handwriting Recognition
Jul 31, 2020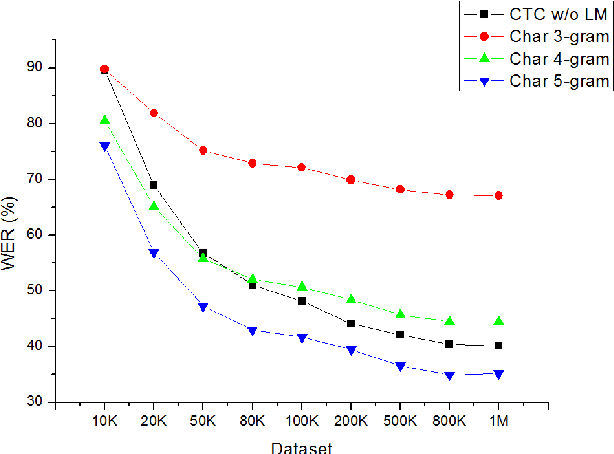


Deep Bidirectional Long Short-Term Memory (D-BLSTM) with a Connectionist Temporal Classification (CTC) output layer has been established as one of the state-of-the-art solutions for handwriting recognition. It is well known that the DBLSTM trained by using a CTC objective function will learn both local character image dependency for character modeling and long-range contextual dependency for implicit language modeling. In this paper, we study the effects of implicit and explicit language model information for DBLSTM-CTC based handwriting recognition by comparing the performance of using or without using an explicit language model in decoding. It is observed that even using one million lines of training sentences to train the DBLSTM, using an explicit language model is still helpful. To deal with such a large-scale training problem, a GPU-based training tool has been developed for CTC training of DBLSTM by using a mini-batch based epochwise Back Propagation Through Time (BPTT) algorithm.
Towards Deep Robot Learning with Optimizer applicable to Non-stationary Problems
Jul 31, 2020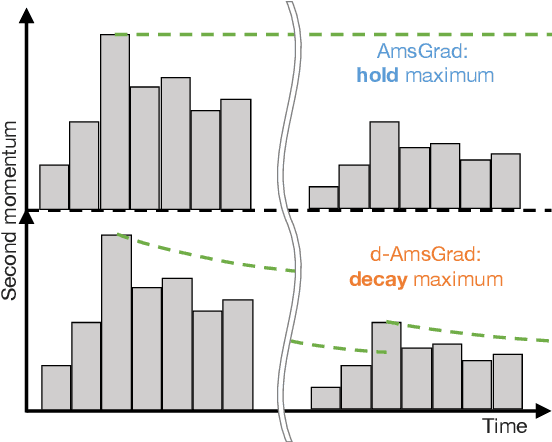
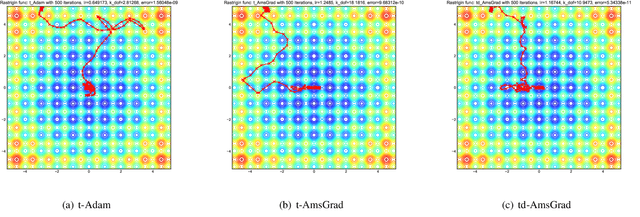
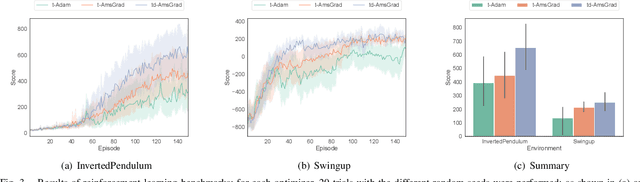
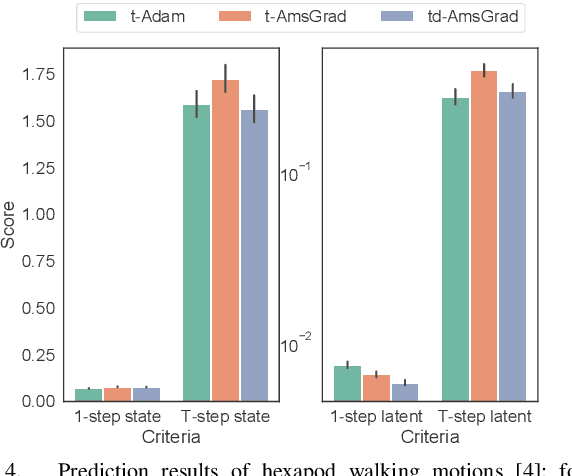
This paper proposes a new optimizer for deep learning, named d-AmsGrad. In the real-world data, noise and outliers cannot be excluded from dataset to be used for learning robot skills. This problem is especially striking for robots that learn by collecting data in real time, which cannot be sorted manually. Several noise-robust optimizers have therefore been developed to resolve this problem, and one of them, named AmsGrad, which is a variant of Adam optimizer, has a proof of its convergence. However, in practice, it does not improve learning performance in robotics scenarios. This reason is hypothesized that most of robot learning problems are non-stationary, but AmsGrad assumes the maximum second momentum during learning to be stationarily given. In order to adapt to the non-stationary problems, an improved version, which slowly decays the maximum second momentum, is proposed. The proposed optimizer has the same capability of reaching the global optimum as baselines, and its performance outperformed that of the baselines in robotics problems.
Polyrhythmic Bimanual Coordination Training using Haptic Force Feedback
May 11, 2020
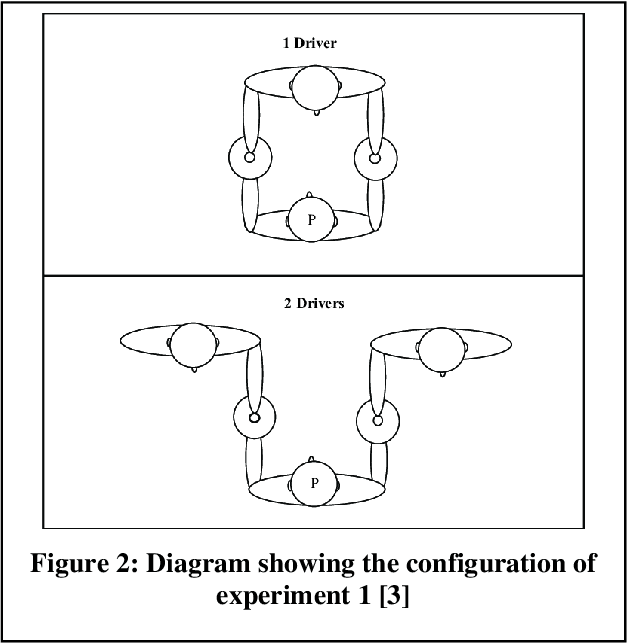
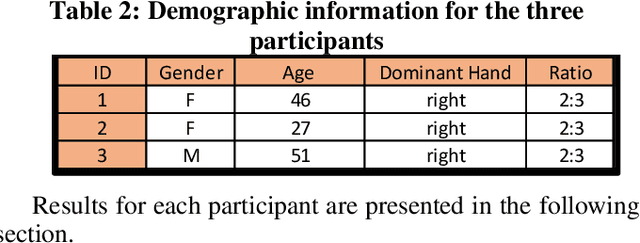
It is challenging to develop two thoughts at the same time or perform two uncorrelated motions simultaneously. This work looks specifically towards training humans to perform a 2:3 polyrhythmic bimanual ratio using haptic force feedback devices (SensAble Phantom OMNI). We implemented an interactive training session to help participants learn to decouple their hand motions quickly. Three subjects (2 Females, 1 Male) were tested and have successfully increased their scores after adaptive training durations of under five minutes.
Iterative Bounding Box Annotation for Object Detection
Jul 02, 2020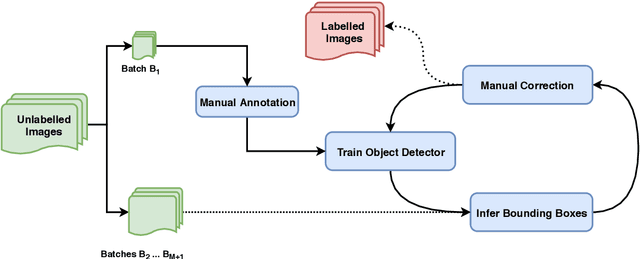
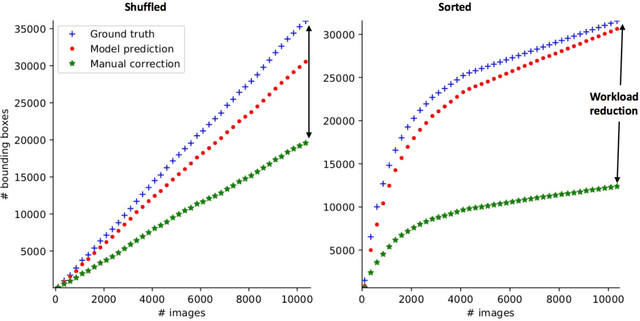
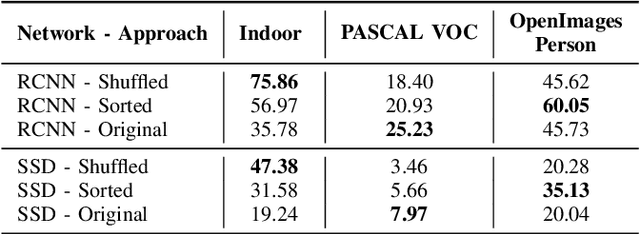
Manual annotation of bounding boxes for object detection in digital images is tedious, and time and resource consuming. In this paper, we propose a semi-automatic method for efficient bounding box annotation. The method trains the object detector iteratively on small batches of labeled images and learns to propose bounding boxes for the next batch, after which the human annotator only needs to correct possible errors. We propose an experimental setup for simulating the human actions and use it for comparing different iteration strategies, such as the order in which the data is presented to the annotator. We experiment on our method with three datasets and show that it can reduce the human annotation effort significantly, saving up to 75% of total manual annotation work.
Rethinking PointNet Embedding for Faster and Compact Model
Jul 31, 2020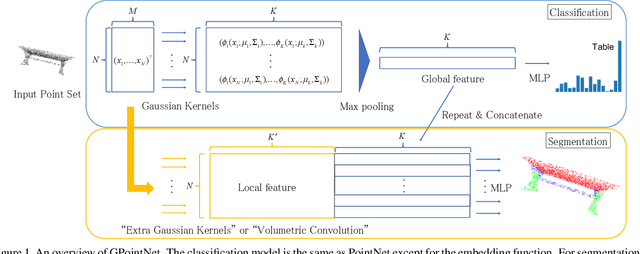
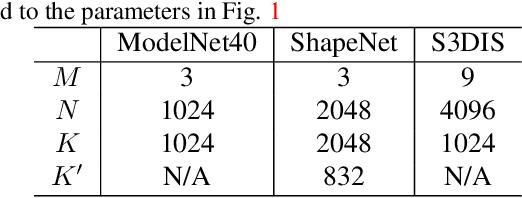
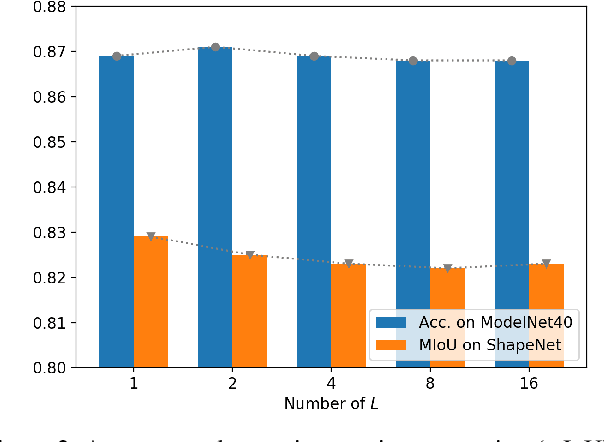
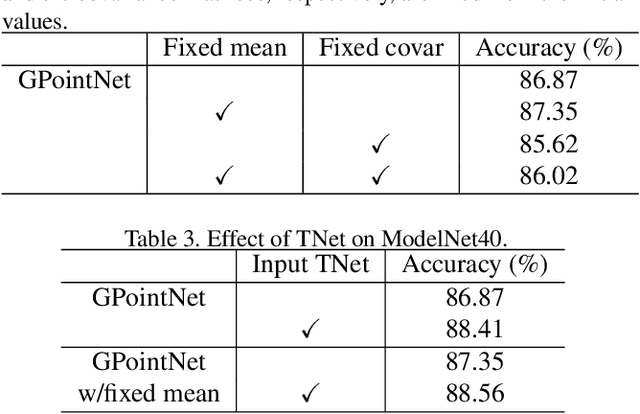
PointNet, which is the widely used point-wise embedding method and known as a universal approximator for continuous set functions, can process one million points per second. Nevertheless, real-time inference for the recent development of high-performing sensors is still challenging with existing neural network-based methods, including PointNet. In ordinary cases, the embedding function of PointNet behaves like a soft-indicator function that is activated when the input points exist in a certain local region of the input space. Leveraging this property, we reduce the computational costs of point-wise embedding by replacing the embedding function of PointNet with the soft-indicator function by Gaussian kernels. Moreover, we show that the Gaussian kernels also satisfy the universal approximation theorem that PointNet satisfies. In experiments, we verify that our model using the Gaussian kernels achieves comparable results to baseline methods, but with much fewer floating-point operations per sample up to 92\% reduction from PointNet.
Renal Cell Carcinoma Detection and Subtyping with Minimal Point-Based Annotation in Whole-Slide Images
Aug 12, 2020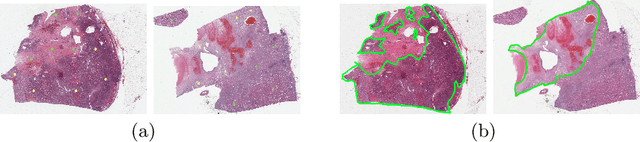
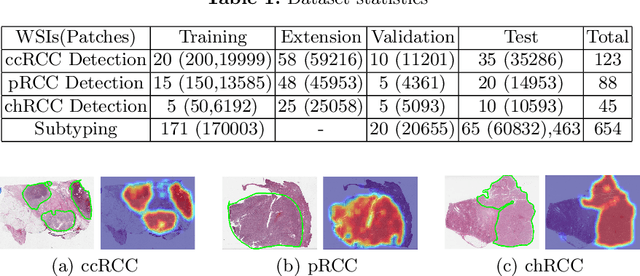
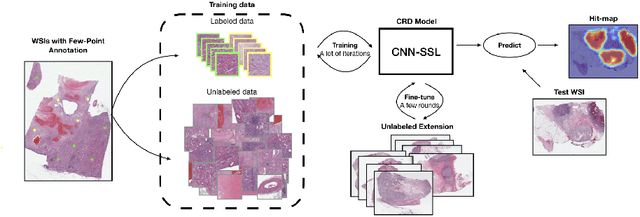
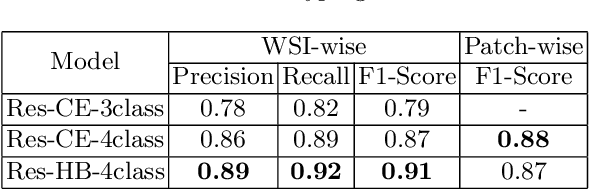
Obtaining a large amount of labeled data in medical imaging is laborious and time-consuming, especially for histopathology. However, it is much easier and cheaper to get unlabeled data from whole-slide images (WSIs). Semi-supervised learning (SSL) is an effective way to utilize unlabeled data and alleviate the need for labeled data. For this reason, we proposed a framework that employs an SSL method to accurately detect cancerous regions with a novel annotation method called Minimal Point-Based annotation, and then utilize the predicted results with an innovative hybrid loss to train a classification model for subtyping. The annotator only needs to mark a few points and label them are cancer or not in each WSI. Experiments on three significant subtypes of renal cell carcinoma (RCC) proved that the performance of the classifier trained with the Min-Point annotated dataset is comparable to a classifier trained with the segmentation annotated dataset for cancer region detection. And the subtyping model outperforms a model trained with only diagnostic labels by 12% in terms of f1-score for testing WSIs.