 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Solution for Large Scale Nonlinear Regression with High Rank and Degree at Constant Memory Complexity via Latent Tensor Reconstruction
May 04, 2020

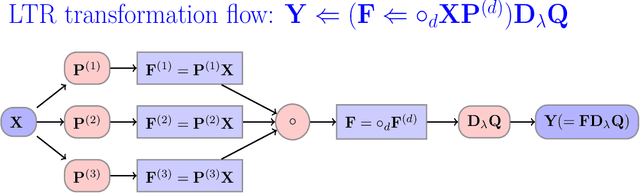

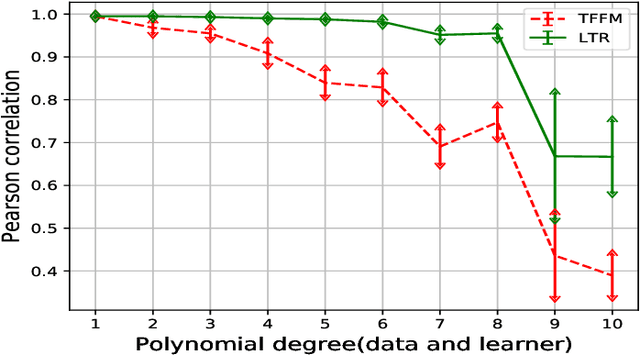
This paper proposes a novel method for learning highly nonlinear, multivariate functions from examples. Our method takes advantage of the property that continuous functions can be approximated by polynomials, which in turn are representable by tensors. Hence the function learning problem is transformed into a tensor reconstruction problem, an inverse problem of the tensor decomposition. Our method incrementally builds up the unknown tensor from rank-one terms, which lets us control the complexity of the learned model and reduce the chance of overfitting. For learning the models, we present an efficient gradient-based algorithm that can be implemented in linear time in the sample size, order, rank of the tensor and the dimension of the input. In addition to regression, we present extensions to classification, multi-view learning and vector-valued output as well as a multi-layered formulation. The method can work in an online fashion via processing mini-batches of the data with constant memory complexity. Consequently, it can fit into systems equipped only with limited resources such as embedded systems or mobile phones. Our experiments demonstrate a favorable accuracy and running time compared to competing methods.
Non-parametric generalized linear model
Sep 02, 2020A fundamental problem in statistical neuroscience is to model how neurons encode information by analyzing electrophysiological recordings. A popular and widely-used approach is to fit the spike trains with an autoregressive point process model. These models are characterized by a set of convolutional temporal filters, whose subsequent analysis can help reveal how neurons encode stimuli, interact with each other, and process information. In practice a sufficiently rich but small ensemble of temporal basis functions needs to be chosen to parameterize the filters. However, obtaining a satisfactory fit often requires burdensome model selection and fine tuning the form of the basis functions and their temporal span. In this paper we propose a nonparametric approach for jointly inferring the filters and hyperparameters using the Gaussian process framework. Our method is computationally efficient taking advantage of the sparse variational approximation while being flexible and rich enough to characterize arbitrary filters in continuous time lag. Moreover, our method automatically learns the temporal span of the filter. For the particular application in neuroscience, we designed priors for stimulus and history filters useful for the spike trains. We compare and validate our method on simulated and real neural spike train data.
DistilE: Distiling Knowledge Graph Embeddings for Faster and Cheaper Reasoning
Sep 13, 2020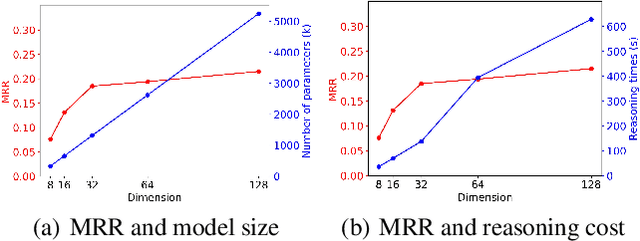
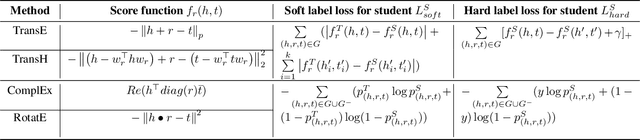

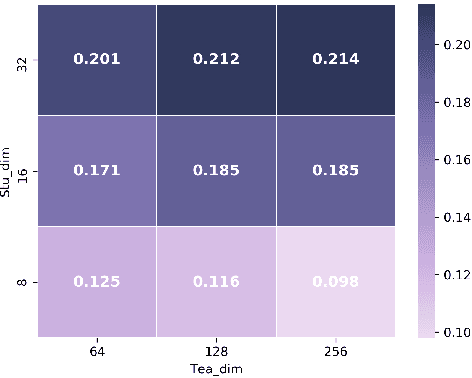
Knowledge Graph Embedding (KGE) is a popular method for KG reasoning and usually a higher dimensional one ensures better reasoning capability. However, high-dimensional KGEs pose huge challenges to storage and computing resources and are not suitable for resource-limited or time-constrained applications, for which faster and cheaper reasoning is necessary. To address this problem, we propose DistilE, a knowledge distillation method to build low-dimensional student KGE from pre-trained high-dimensional teacher KGE. We take the original KGE loss as hard label loss and design specific soft label loss for different KGEs in DistilE. We also propose a two-stage distillation approach to make the student and teacher adapt to each other and further improve the reasoning capability of the student. Our DistilE is general enough to be applied to various KGEs. Experimental results of link prediction show that our method successfully distills a good student which performs better than a same dimensional one directly trained, and sometimes even better than the teacher, and it can achieve 2 times - 8 times embedding compression rate and more than 10 times faster inference speed than the teacher with a small performance loss. We also experimentally prove the effectiveness of our two-stage training proposal via ablation study.
Characterization of surface motion patterns in highly deformable soft tissue organs from dynamic Magnetic Resonance Imaging
Oct 09, 2020

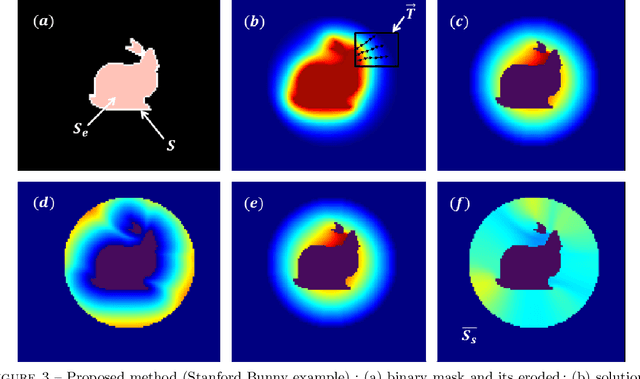
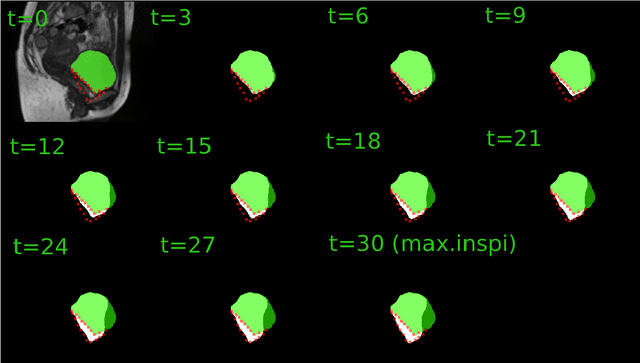
In this work, we present a pipeline for characterization of bladder surface dynamics during deep respiratory movements from dynamic Magnetic Resonance Imaging (MRI). Dynamic MRI may capture temporal anatomical changes in soft tissue organs with high-contrast but the obtained sequences usually suffer from limited volume coverage which makes the high resolution reconstruction of organ shape trajectories a major challenge in temporal studies. For a compact shape representation, the reconstructed temporal data with full volume coverage are first used to establish a subject-specific dynamical 4D mesh sequences using the large deformation diffeomorphic metric mapping (LDDMM) framework. Then, we performed a statistical characterization of organ shape changes from mechanical parameters such as mesh elongations and distortions. Since shape space is curved, we have also used the intrinsic curvature changes as metric to quantify surface evolution. However, the numerical computation of curvature is strongly dependant on the surface parameterization (i.e. the mesh resolution). To cope with this dependency, we propose a non-parametric level set method to evaluate spatio-temporal surface evolution. Independent of parameterization and minimizing the length of the geodesic curves, it shrinks smoothly the surface curves towards a sphere by minimizing a Dirichlet energy. An Eulerian PDE approach is used for evaluation of surface dynamics from the curve-shortening flow. Results demonstrate the numerical stability of the derived descriptor throughout smooth continuous-time organ trajectories. Intercorrelations between individuals' motion patterns from different geometric features are computed using the Laplace-Beltrami Operator (LBO) eigenfunctions for spherical mapping.
Project to Adapt: Domain Adaptation for Depth Completion from Noisy and Sparse Sensor Data
Aug 03, 2020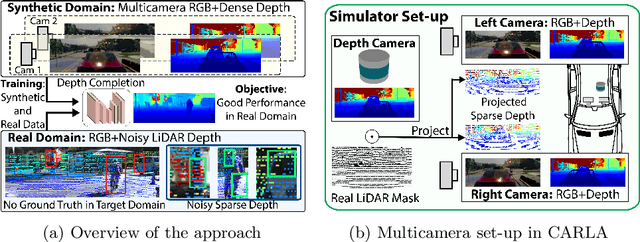
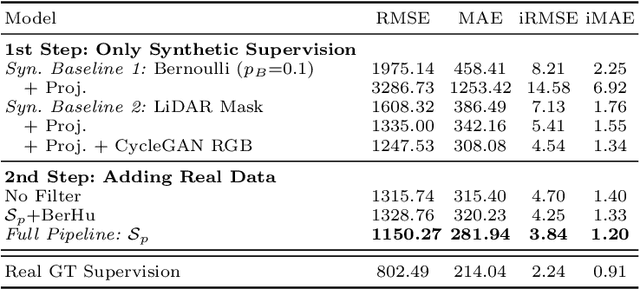
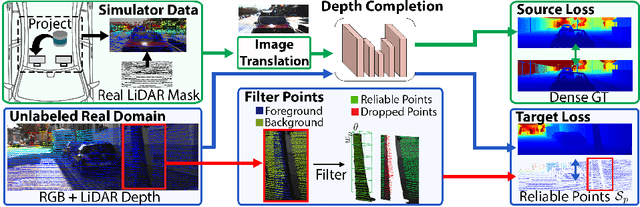
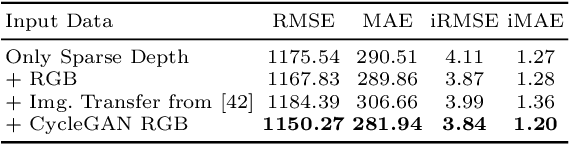
Depth completion aims to predict a dense depth map from a sparse depth input. The acquisition of dense ground truth annotations for depth completion settings can be difficult and, at the same time, a significant domain gap between real LiDAR measurements and synthetic data has prevented from successful training of models in virtual settings. We propose a domain adaptation approach for sparse-to-dense depth completion that is trained from synthetic data, without annotations in the real domain or additional sensors. Our approach simulates the real sensor noise in an RGB+LiDAR set-up, and consists of three modules: simulating the real LiDAR input in the synthetic domain via projections, filtering the real noisy LiDAR for supervision and adapting the synthetic RGB image using a CycleGAN approach. We extensively evaluate these modules against the state-of-the-art in the KITTI depth completion benchmark, showing significant improvements.
Identifying Stable Patterns over Time for Emotion Recognition from EEG
Jan 10, 2016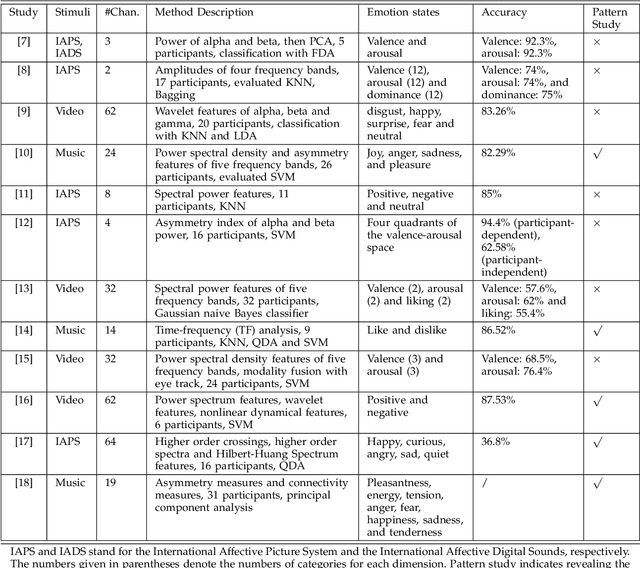
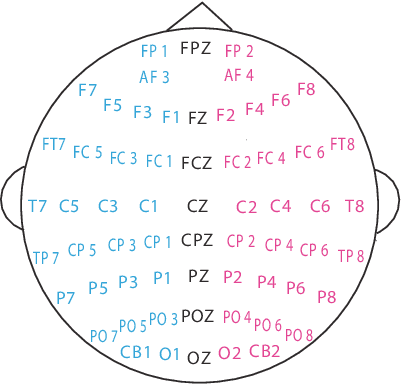
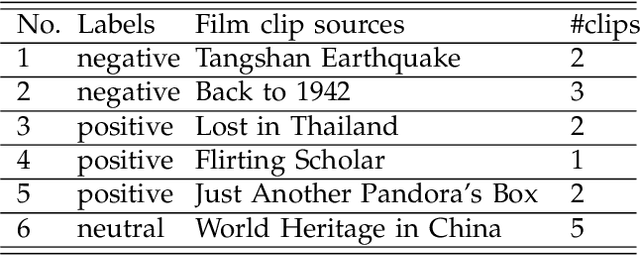
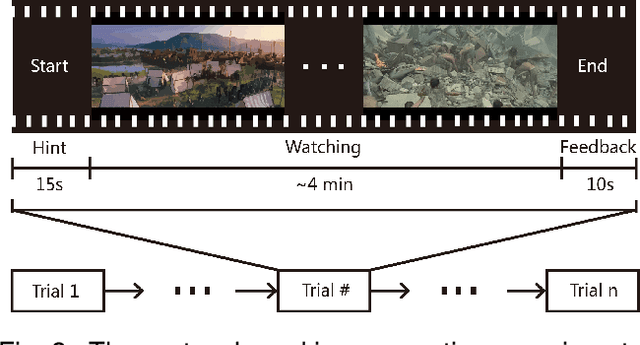
In this paper, we investigate stable patterns of electroencephalogram (EEG) over time for emotion recognition using a machine learning approach. Up to now, various findings of activated patterns associated with different emotions have been reported. However, their stability over time has not been fully investigated yet. In this paper, we focus on identifying EEG stability in emotion recognition. To validate the efficiency of the machine learning algorithms used in this study, we systematically evaluate the performance of various popular feature extraction, feature selection, feature smoothing and pattern classification methods with the DEAP dataset and a newly developed dataset for this study. The experimental results indicate that stable patterns exhibit consistency across sessions; the lateral temporal areas activate more for positive emotion than negative one in beta and gamma bands; the neural patterns of neutral emotion have higher alpha responses at parietal and occipital sites; and for negative emotion, the neural patterns have significant higher delta responses at parietal and occipital sites and higher gamma responses at prefrontal sites. The performance of our emotion recognition system shows that the neural patterns are relatively stable within and between sessions.
Speed of Social Learning from Reviews in Non-Stationary Environments
Jul 20, 2020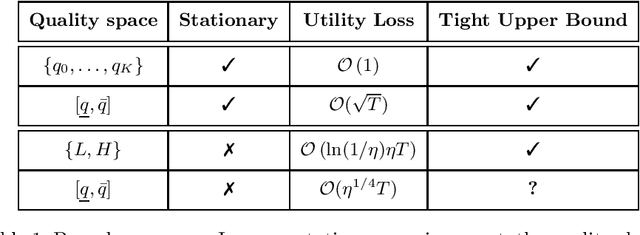
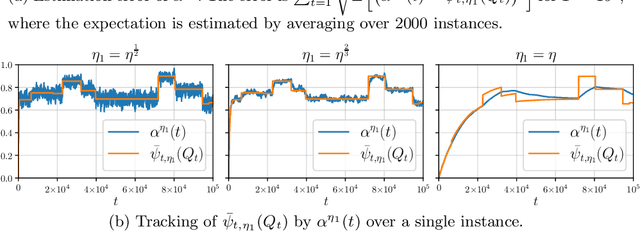
Potential buyers of a product or service tend to first browse feedback from previous consumers through review platforms. This behavior is modeled by a market of Bayesian consumers with heterogeneous preferences, who sequentially decide whether to buy an item based on reviews of previous buyers. While the belief of the item quality in simple settings is known to converge to its true value, this paper extends this result to more general cases, besides providing convergence rates. In practice, the quality of an item may change over time as new competitors can appear in the market or the product/service can undergo modifications. This paper studies such dynamics with changing points model and shows that the cost of learning remains low, when expressed in total utility earned by consumers.
Self-Supervised Monocular Scene Flow Estimation
Apr 08, 2020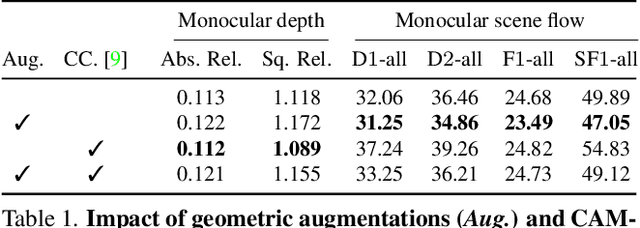
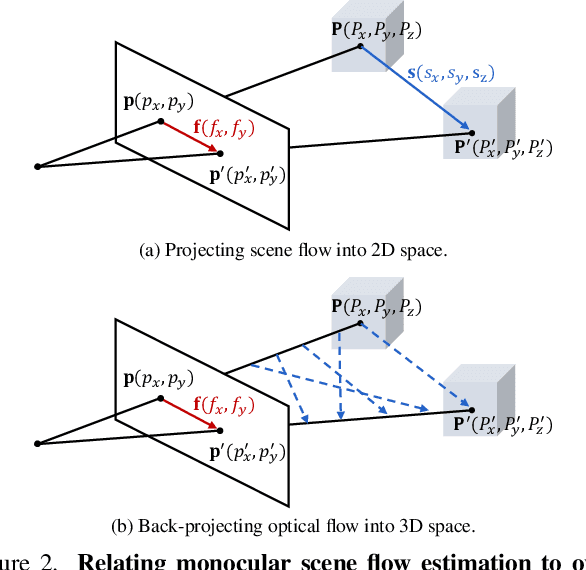
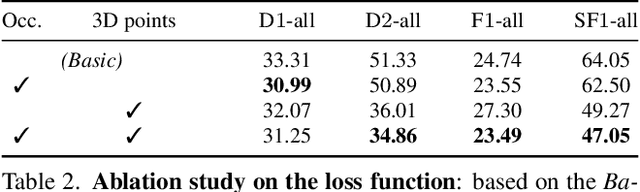
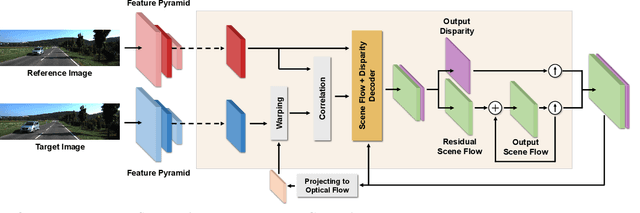
Scene flow estimation has been receiving increasing attention for 3D environment perception. Monocular scene flow estimation -- obtaining 3D structure and 3D motion from two temporally consecutive images -- is a highly ill-posed problem, and practical solutions are lacking to date. We propose a novel monocular scene flow method that yields competitive accuracy and real-time performance. By taking an inverse problem view, we design a single convolutional neural network (CNN) that successfully estimates depth and 3D motion simultaneously from a classical optical flow cost volume. We adopt self-supervised learning with 3D loss functions and occlusion reasoning to leverage unlabeled data. We validate our design choices, including the proxy loss and augmentation setup. Our model achieves state-of-the-art accuracy among unsupervised/self-supervised learning approaches to monocular scene flow, and yields competitive results for the optical flow and monocular depth estimation sub-tasks. Semi-supervised fine-tuning further improves the accuracy and yields promising results in real-time.
Graphing Contributions in Natural Language Processing Research: Intra-Annotator Agreement on a Trial Dataset
Oct 09, 2020
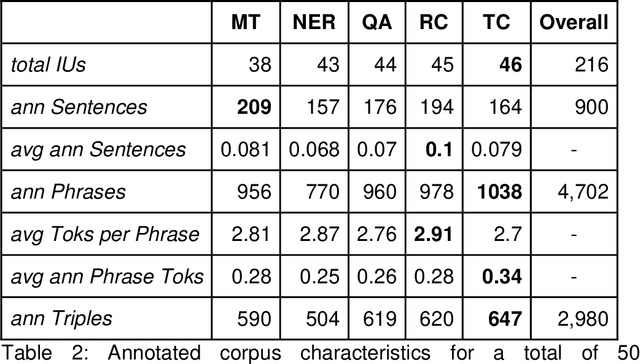
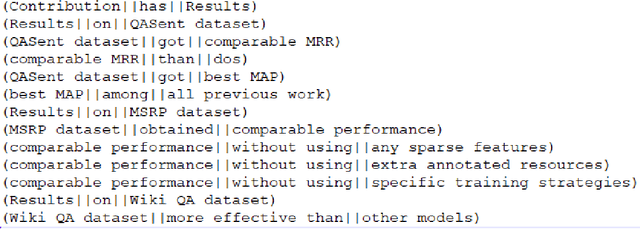
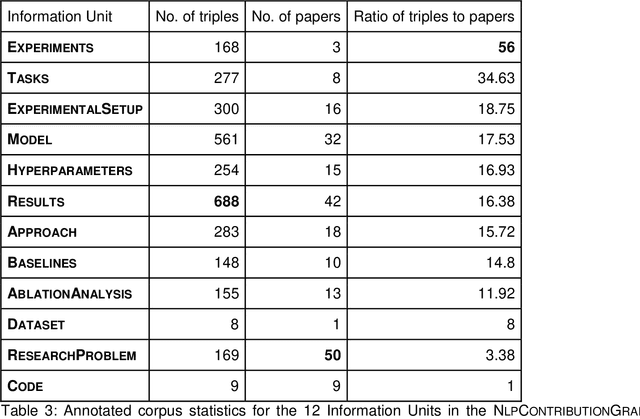
Purpose: To stabilize the NLPContributionGraph scheme for the surface structuring of contributions information in Natural Language Processing (NLP) scholarly articles via a two-stage annotation methodology: first stage - to define the scheme; and second stage - to stabilize the graphing model. Approach: Re-annotate, a second time, the contributions-pertinent information across 50 prior-annotated NLP scholarly articles in terms of a data pipeline comprising: contribution-centered sentences, phrases, and triples. To this end specifically, care was taken in the second annotation stage to reduce annotation noise while formulating the guidelines for our proposed novel NLP contributions structuring scheme. Findings: The application of NLPContributionGraph on the 50 articles resulted in finally in a dataset of 900 contribution-focused sentences, 4,702 contribution-information-centered phrases, and 2,980 surface-structured triples. The intra-annotation agreement between the first and second stages, in terms of F1, was 67.92% for sentences, 41.82% for phrases, and 22.31% for triples indicating that with an increased granularity of the information, the annotation decision variance is greater. Practical Implications: Demonstrate NLPContributionGraph data integrated in the Open Research Knowledge Graph (ORKG), a next-generation KG-based digital library with compute enabled over structured scholarly knowledge, as a viable aid to assist researchers in their day-to-day tasks. Value: NLPContributionGraph is a novel scheme to obtain research contribution-centered graphs from NLP articles which to the best of our knowledge does not exist in the community. And our quantitative evaluations over the two-stage annotation tasks offer insights into task difficulty.
Anomaly Detection Under Controlled Sensing Using Actor-Critic Reinforcement Learning
May 26, 2020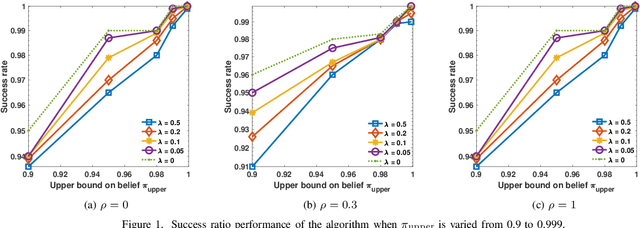
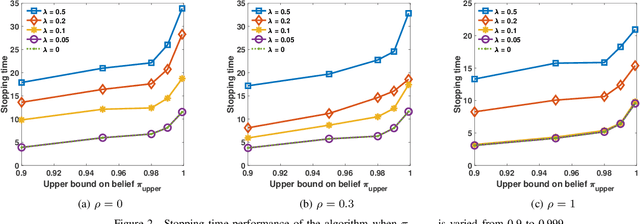
We consider the problem of detecting anomalies among a given set of processes using their noisy binary sensor measurements. The noiseless sensor measurement corresponding to a normal process is 0, and the measurement is 1 if the process is anomalous. The decision-making algorithm is assumed to have no knowledge of the number of anomalous processes. The algorithm is allowed to choose a subset of the sensors at each time instant until the confidence level on the decision exceeds the desired value. Our objective is to design a sequential sensor selection policy that dynamically determines which processes to observe at each time and when to terminate the detection algorithm. The selection policy is designed such that the anomalous processes are detected with the desired confidence level while incurring minimum cost which comprises the delay in detection and the cost of sensing. We cast this problem as a sequential hypothesis testing problem within the framework of Markov decision processes, and solve it using the actor-critic deep reinforcement learning algorithm. This deep neural network-based algorithm offers a low complexity solution with good detection accuracy. We also study the effect of statistical dependence between the processes on the algorithm performance. Through numerical experiments, we show that our algorithm is able to adapt to any unknown statistical dependence pattern of the processes.