 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilE: Distiling Knowledge Graph Embeddings for Faster and Cheaper Reasoning
Paper and Code
Sep 13, 2020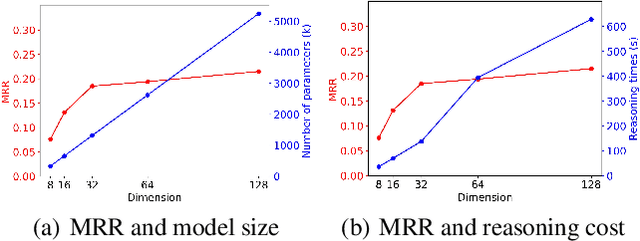
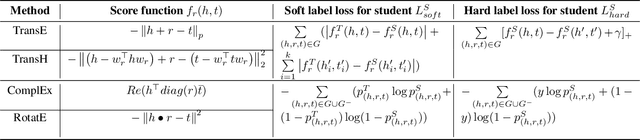

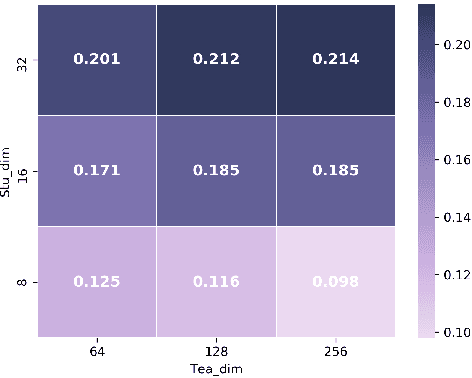
Knowledge Graph Embedding (KGE) is a popular method for KG reasoning and usually a higher dimensional one ensures better reasoning capability. However, high-dimensional KGEs pose huge challenges to storage and computing resources and are not suitable for resource-limited or time-constrained applications, for which faster and cheaper reasoning is necessary. To address this problem, we propose DistilE, a knowledge distillation method to build low-dimensional student KGE from pre-trained high-dimensional teacher KGE. We take the original KGE loss as hard label loss and design specific soft label loss for different KGEs in DistilE. We also propose a two-stage distillation approach to make the student and teacher adapt to each other and further improve the reasoning capability of the student. Our DistilE is general enough to be applied to various KGEs. Experimental results of link prediction show that our method successfully distills a good student which performs better than a same dimensional one directly trained, and sometimes even better than the teacher, and it can achieve 2 times - 8 times embedding compression rate and more than 10 times faster inference speed than the teacher with a small performance loss. We also experimentally prove the effectiveness of our two-stage training proposal via ablation study.