 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ORCSolver: An Efficient Solver for Adaptive GUI Layout with OR-Constraints
Feb 23, 2020
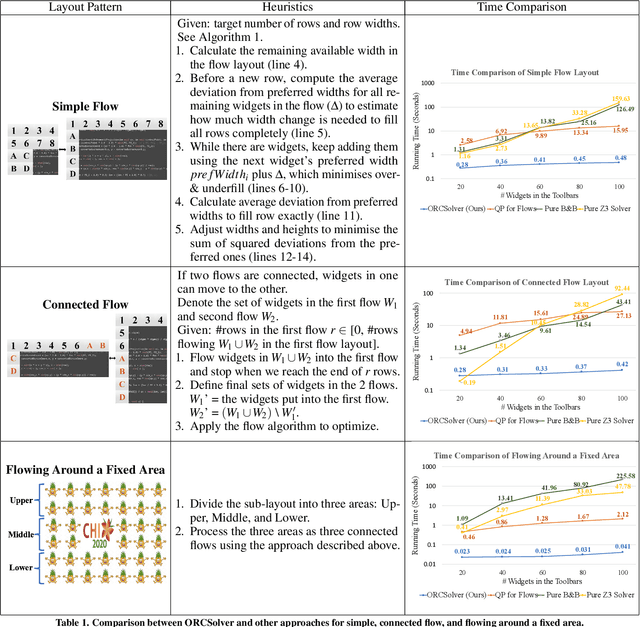
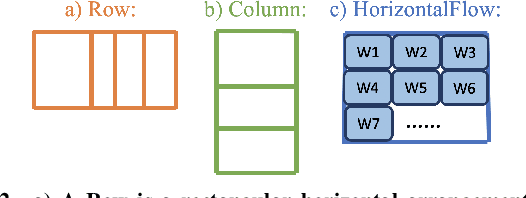

OR-constrained (ORC) graphical user interface layouts unify conventional constraint-based layouts with flow layouts, which enables the definition of flexible layouts that adapt to screens with different sizes, orientations, or aspect ratios with only a single layout specification. Unfortunately, solving ORC layouts with current solvers is time-consuming and the needed time increases exponentially with the number of widgets and constraints. To address this challenge, we propose ORCSolver, a novel solving technique for adaptive ORC layouts, based on a branch-and-bound approach with heuristic preprocessing. We demonstrate that ORCSolver simplifies ORC specifications at runtime and our approach can solve ORC layout specifications efficiently at near-interactive rates.
The Adversarial Resilience Learning Architecture for AI-based Modelling, Exploration, and Operation of Complex Cyber-Physical Systems
May 27, 2020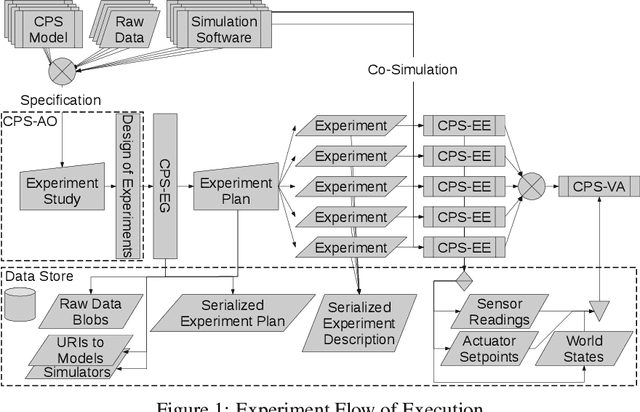
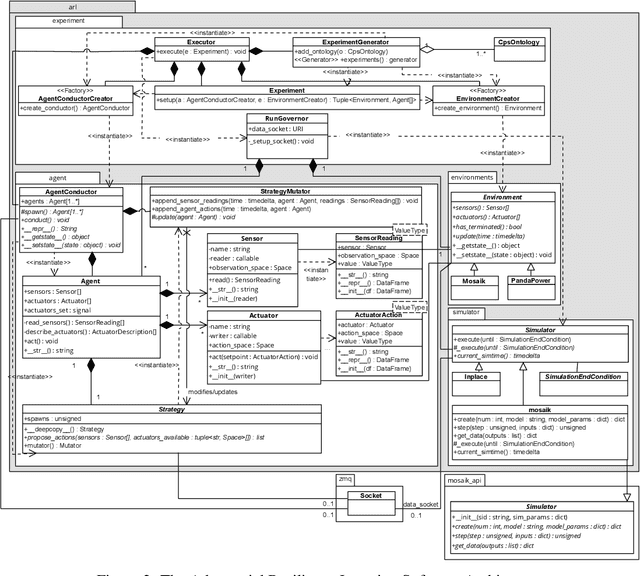
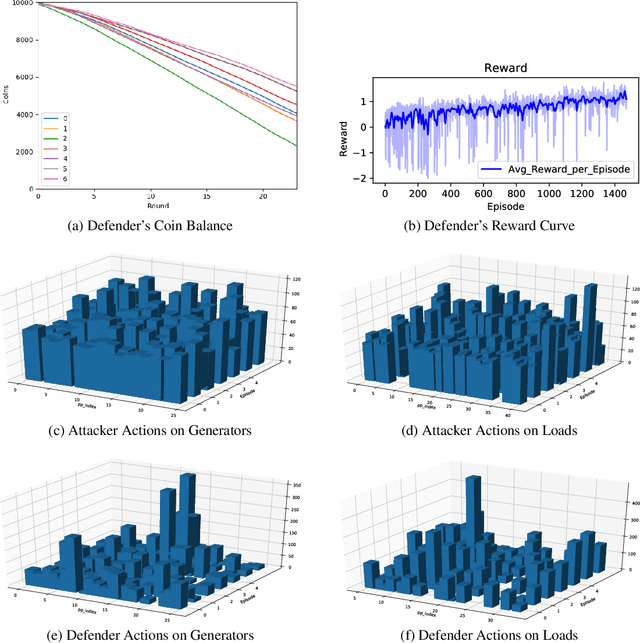
Modern algorithms in the domain of Deep Reinforcement Learning (DRL) demonstrated remarkable successes; most widely known are those in game-based scenarios, from ATARI video games to Go and the StarCraft~\textsc{II} real-time strategy game. However, applications in the domain of modern Cyber-Physical Systems (CPS) that take advantage a vast variety of DRL algorithms are few. We assume that the benefits would be considerable: Modern CPS have become increasingly complex and evolved beyond traditional methods of modelling and analysis. At the same time, these CPS are confronted with an increasing amount of stochastic inputs, from volatile energy sources in power grids to broad user participation stemming from markets. Approaches of system modelling that use techniques from the domain of Artificial Intelligence (AI) do not focus on analysis and operation. In this paper, we describe the concept of Adversarial Resilience Learning (ARL) that formulates a new approach to complex environment checking and resilient operation: It defines two agent classes, attacker and defender agents. The quintessence of ARL lies in both agents exploring the system and training each other without any domain knowledge. Here, we introduce the ARL software architecture that allows to use a wide range of model-free as well as model-based DRL-based algorithms, and document results of concrete experiment runs on a complex power grid.
DSDANet: Deep Siamese Domain Adaptation Convolutional Neural Network for Cross-domain Change Detection
Jun 16, 2020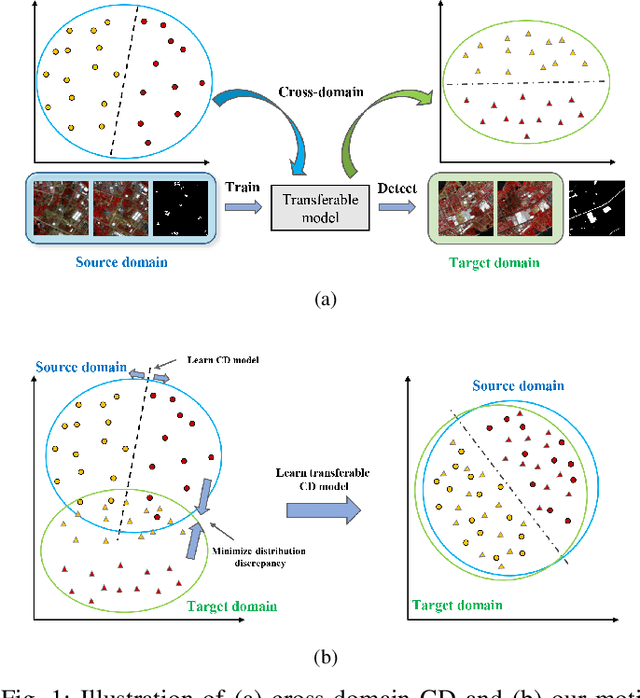
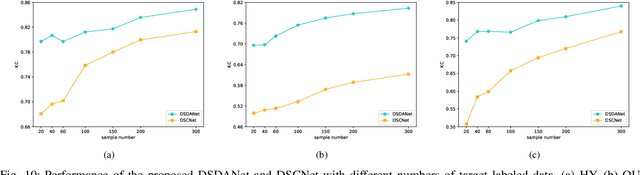
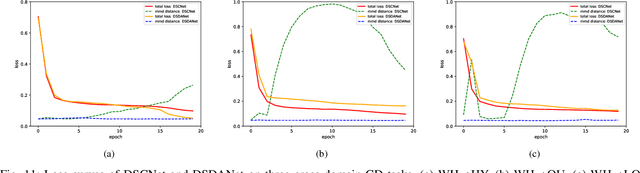
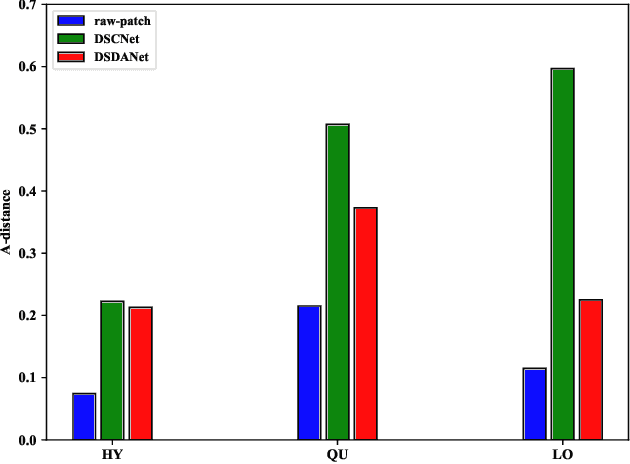
Change detection (CD) is one of the most vital applications in remote sensing. Recently, deep learning has achieved promising performance in the CD task. However, the deep models are task-specific and CD data set bias often exists, hence it is inevitable that deep CD models would suffer degraded performance after transferring it from original CD data set to new ones, making manually label numerous samples in the new data set unavoidable, which costs a large amount of time and human labor. How to learn a transferable CD model in the data set with enough labeled data (original domain) but can well detect changes in another data set without labeled data (target domain)? This is defined as the cross-domain change detection problem. In this paper, we propose a novel deep siamese domain adaptation convolutional neural network (DSDANet) architecture for cross-domain CD. In DSDANet, a siamese convolutional neural network first extracts spatial-spectral features from multi-temporal images. Then, through multi-kernel maximum mean discrepancy (MK-MMD), the learned feature representation is embedded into a reproducing kernel Hilbert space (RKHS), in which the distribution of two domains can be explicitly matched. By optimizing the network parameters and kernel coefficients with the source labeled data and target unlabeled data, DSDANet can learn transferrable feature representation that can bridge the discrepancy between two domains. To the best of our knowledge, it is the first time that such a domain adaptation-based deep network is proposed for CD. The theoretical analysis and experimental results demonstrate the effectiveness and potential of the proposed method.
Harnessing adversarial examples with a surprisingly simple defense
Jun 03, 2020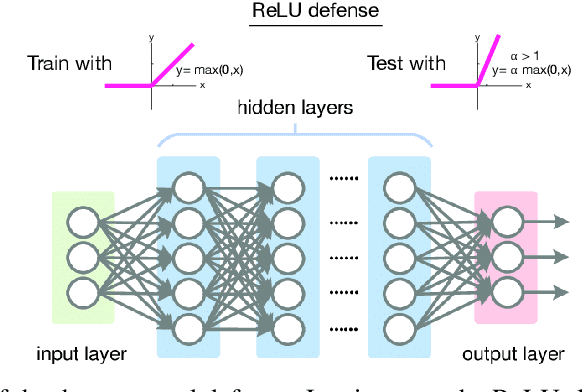
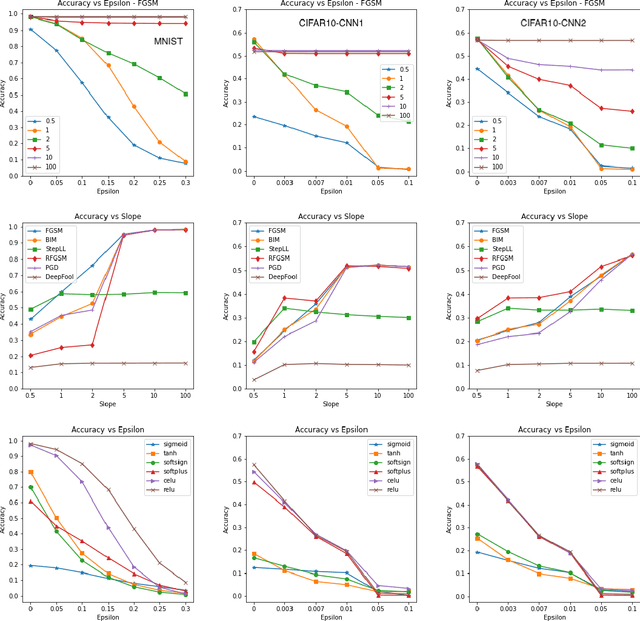
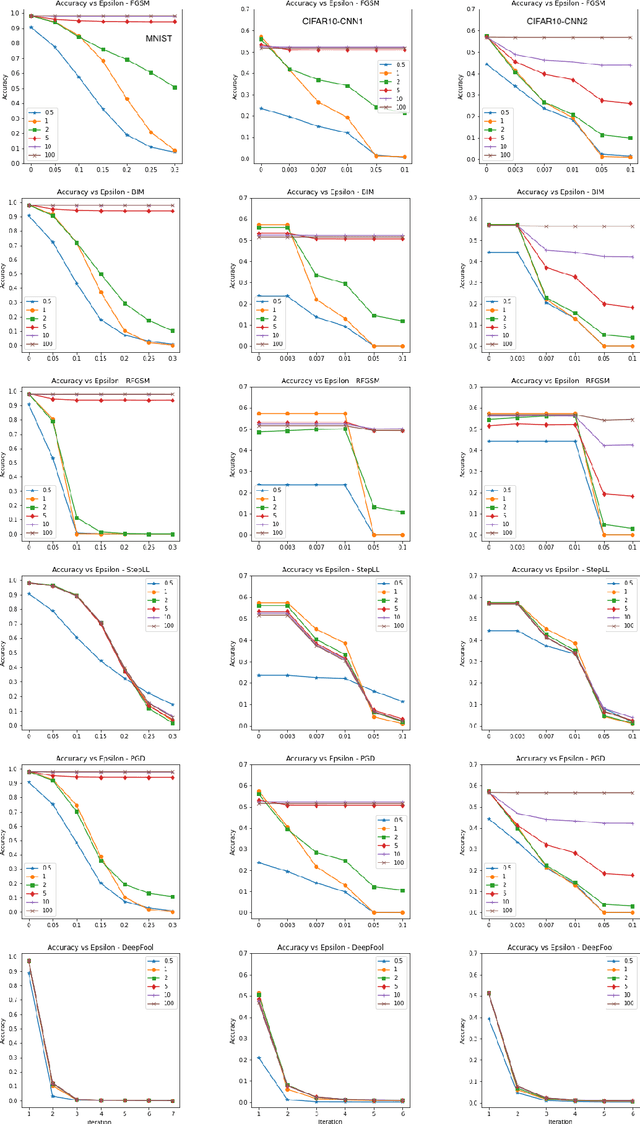
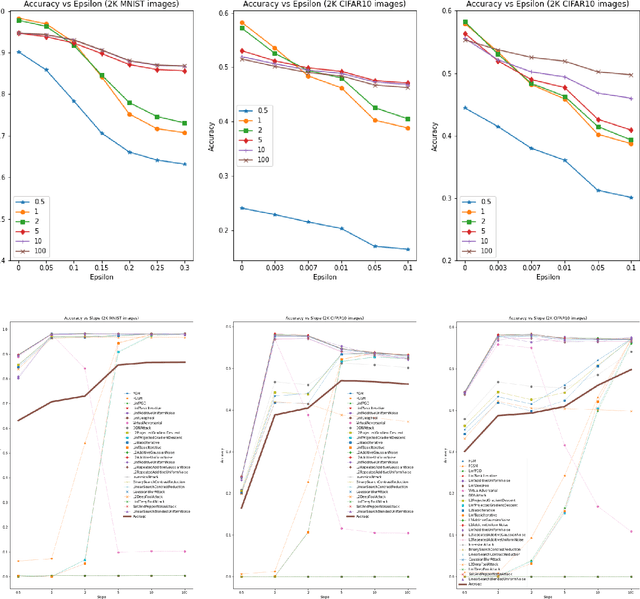
I introduce a very simple method to defend against adversarial examples. The basic idea is to raise the slope of the ReLU function at the test time. Experiments over MNIST and CIFAR-10 datasets demonstrate the effectiveness of the proposed defense against a number of strong attacks in both untargeted and targeted settings. While perhaps not as effective as the state of the art adversarial defenses, this approach can provide insights to understand and mitigate adversarial attacks. It can also be used in conjunction with other defenses.
Understanding Information Processing in Human Brain by Interpreting Machine Learning Models
Oct 17, 2020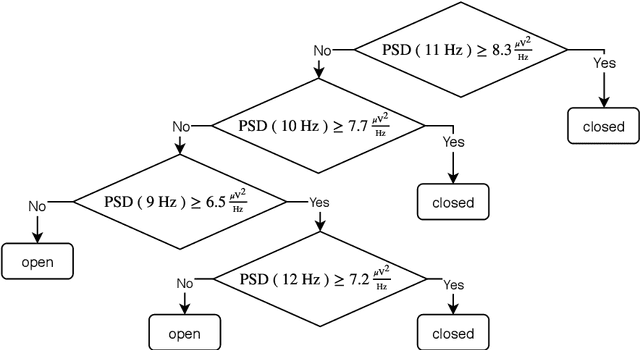
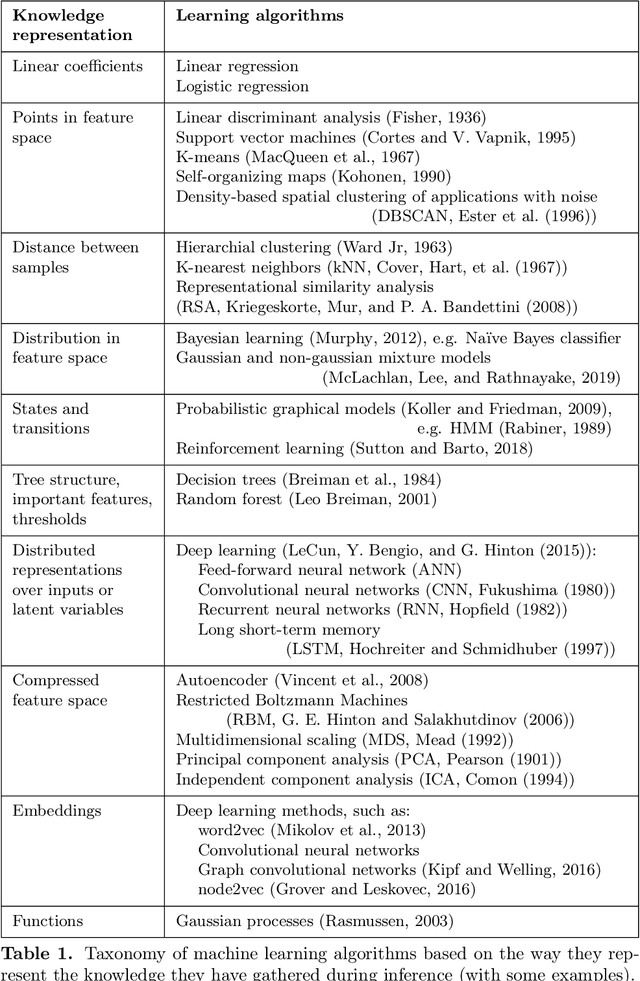
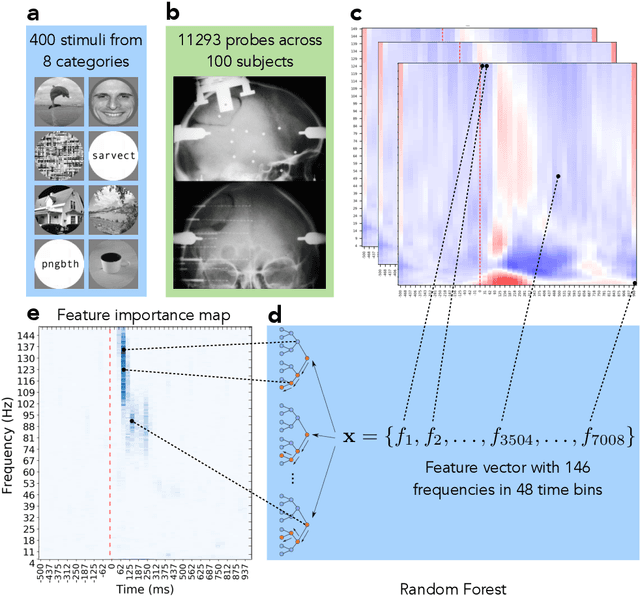

The thesis explores the role machine learning methods play in creating intuitive computational models of neural processing. Combined with interpretability techniques, machine learning could replace human modeler and shift the focus of human effort to extracting the knowledge from the ready-made models and articulating that knowledge into intuitive descroptions of reality. This perspective makes the case in favor of the larger role that exploratory and data-driven approach to computational neuroscience could play while coexisting alongside the traditional hypothesis-driven approach. We exemplify the proposed approach in the context of the knowledge representation taxonomy with three research projects that employ interpretability techniques on top of machine learning methods at three different levels of neural organization. The first study (Chapter 3) explores feature importance analysis of a random forest decoder trained on intracerebral recordings from 100 human subjects to identify spectrotemporal signatures that characterize local neural activity during the task of visual categorization. The second study (Chapter 4) employs representation similarity analysis to compare the neural responses of the areas along the ventral stream with the activations of the layers of a deep convolutional neural network. The third study (Chapter 5) proposes a method that allows test subjects to visually explore the state representation of their neural signal in real time. This is achieved by using a topology-preserving dimensionality reduction technique that allows to transform the neural data from the multidimensional representation used by the computer into a two-dimensional representation a human can grasp. The approach, the taxonomy, and the examples, present a strong case for the applicability of machine learning methods to automatic knowledge discovery in neuroscience.
Robust and Scalable Techniques for TWR and TDoA based localization using Ultra Wide Band Radios
Aug 10, 2020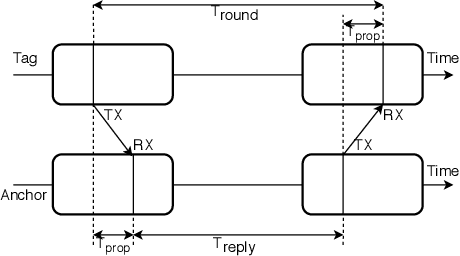
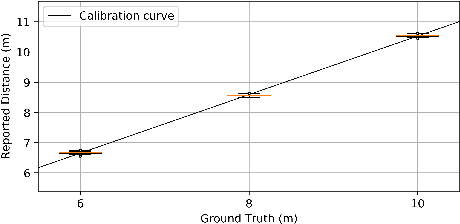
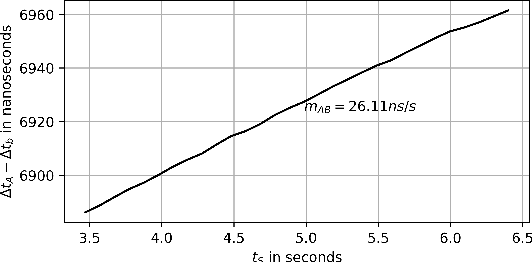
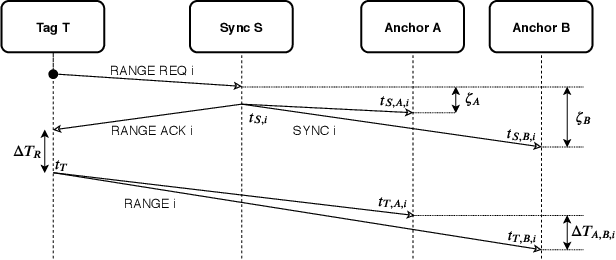
Current trends in autonomous vehicles and their applications indicates an increasing need in positioning at low battery and compute cost. Lidars provide accurate localization at the cost of high compute and power consumption which could be detrimental for drones. Modern requirements for autonomous drones such as No-Permit-No-Takeoff (NPNT) and applications restricting drones to a corridor require the infrastructure to constantly determine the location of the drone. Ultra Wide Band Radios (UWB) fulfill such requirements and offer high precision localization and fast position update rates at a fraction of the cost and battery consumption as compared to lidars and also have greater network availability than GPS in a dense forested campus or an indoor setting. We present in this paper a novel protocol and technique to localize a drone for such applications using a Time Difference of Arrival (TDoA) approach. This further increases the position update rates without sacrificing on accuracy and compare it to traditional methods
SLAYER: Spike Layer Error Reassignment in Time
Sep 05, 2018
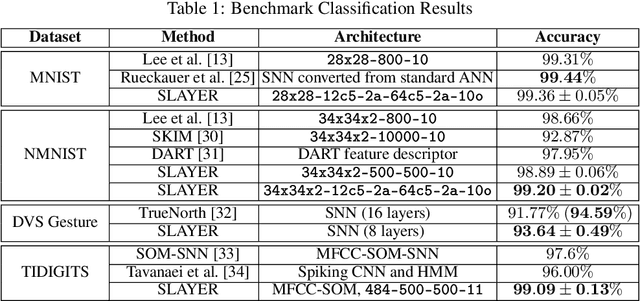
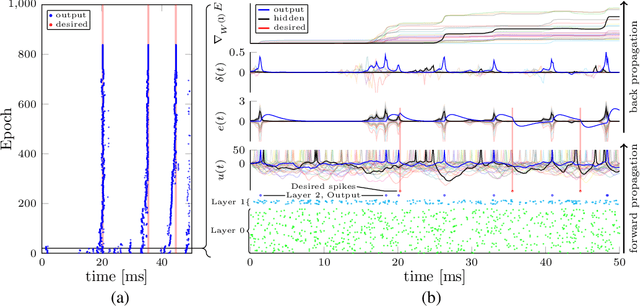
Configuring deep Spiking Neural Networks (SNNs) is an exciting research avenue for low power spike event based computation. However, the spike generation function is non-differentiable and therefore not directly compatible with the standard error backpropagation algorithm. In this paper, we introduce a new general backpropagation mechanism for learning synaptic weights and axonal delays which overcomes the problem of non-differentiability of the spike function and uses a temporal credit assignment policy for backpropagating error to preceding layers. We describe and release a GPU accelerated software implementation of our method which allows training both fully connected and convolutional neural network (CNN) architectures. Using our software, we compare our method against existing SNN based learning approaches and standard ANN to SNN conversion techniques and show that our method achieves state of the art performance for an SNN on the MNIST, NMNIST, DVS Gesture, and TIDIGITS datasets.
Handwriting Quality Analysis using Online-Offline Models
Oct 09, 2020
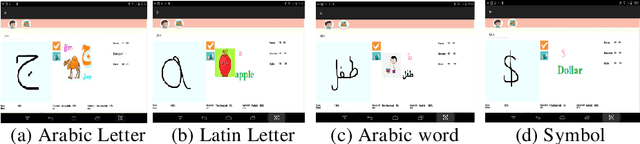
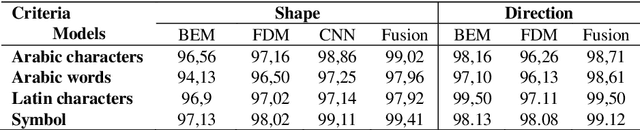
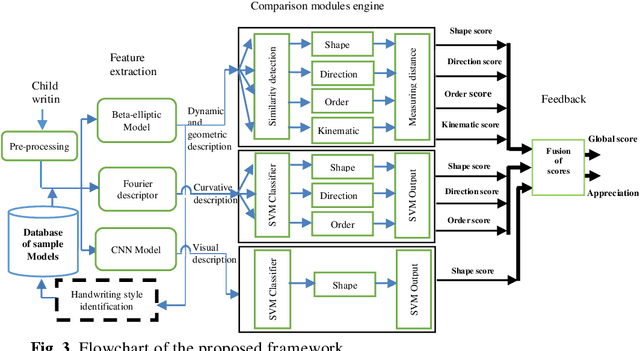
This work is part of an innovative e-learning project allowing the development of an advanced digital educational tool that provides feedback during the process of learning handwriting for young school children (three to eight years old). In this paper, we describe a new method for children handwriting quality analysis. It automatically detects mistakes, gives real-time on-line feedback for children's writing, and helps teachers comprehend and evaluate children's writing skills. The proposed method adjudges five main criteria shape, direction, stroke order, position respect to the reference lines, and kinematics of the trace. It analyzes the handwriting quality and automatically gives feedback based on the combination of three extracted models: Beta-Elliptic Model (BEM) using similarity detection (SD) and dissimilarity distance (DD) measure, Fourier Descriptor Model (FDM), and perceptive Convolutional Neural Network (CNN) with Support Vector Machine (SVM) comparison engine. The originality of our work lies partly in the system architecture which apprehends complementary dynamic, geometric, and visual representation of the examined handwritten scripts and in the efficient selected features adapted to various handwriting styles and multiple script languages such as Arabic, Latin, digits, and symbol drawing. The application offers two interactive interfaces respectively dedicated to learners, educators, experts or teachers and allows them to adapt it easily to the specificity of their disciples. The evaluation of our framework is enhanced by a database collected in Tunisia primary school with 400 children. Experimental results show the efficiency and robustness of our suggested framework that helps teachers and children by offering positive feedback throughout the handwriting learning process using tactile digital devices.
Community embeddings reveal large-scale cultural organization of online platforms
Oct 01, 2020
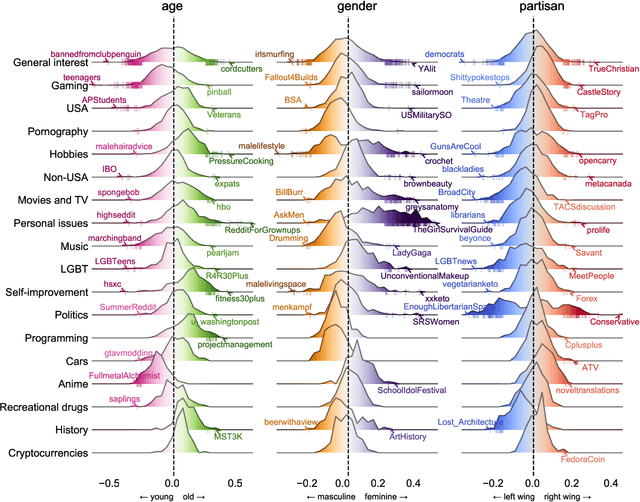
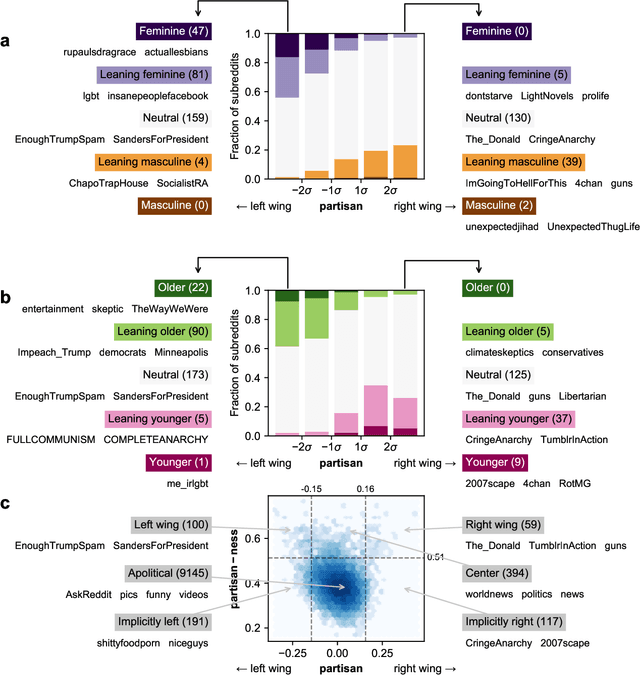
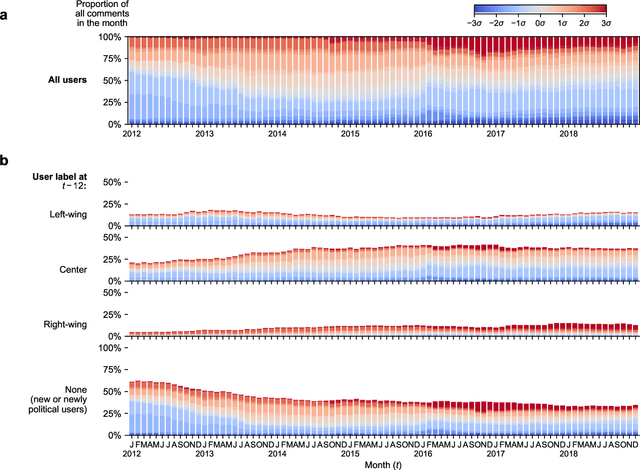
Optimism about the Internet's potential to bring the world together has been tempered by concerns about its role in inflaming the 'culture wars'. Via mass selection into like-minded groups, online society may be becoming more fragmented and polarized, particularly with respect to partisan differences. However, our ability to measure the cultural makeup of online communities, and in turn understand the cultural structure of online platforms, is limited by the pseudonymous, unstructured, and large-scale nature of digital discussion. Here we develop a neural embedding methodology to quantify the positioning of online communities along cultural dimensions by leveraging large-scale patterns of aggregate behaviour. Applying our methodology to 4.8B Reddit comments made in 10K communities over 14 years, we find that the macro-scale community structure is organized along cultural lines, and that relationships between online cultural concepts are more complex than simply reflecting their offline analogues. Examining political content, we show Reddit underwent a significant polarization event around the 2016 U.S. presidential election, and remained highly polarized for years afterward. Contrary to conventional wisdom, however, instances of individual users becoming more polarized over time are rare; the majority of platform-level polarization is driven by the arrival of new and newly political users. Our methodology is broadly applicable to the study of online culture, and our findings have implications for the design of online platforms, understanding the cultural contexts of online content, and quantifying cultural shifts in online behaviour.
Optimal Trajectory Planning for Flexible Robots with Large Deformation
Jun 25, 2020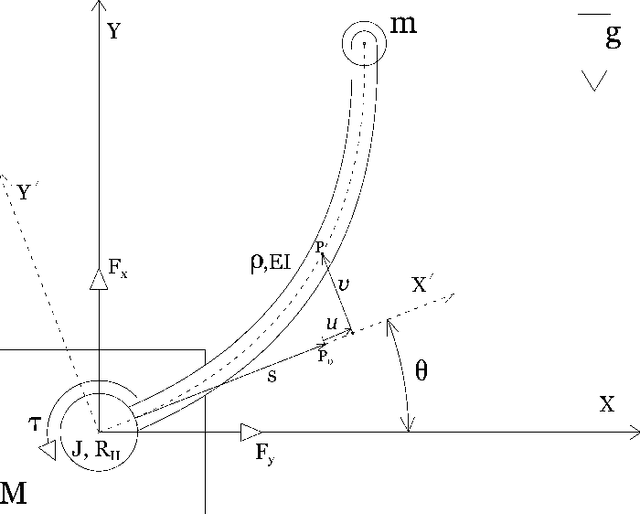
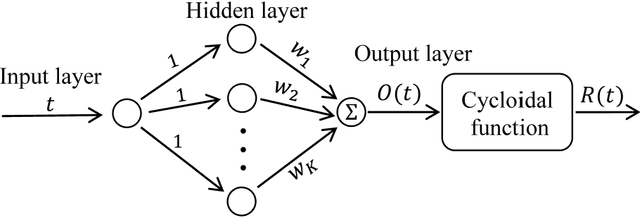
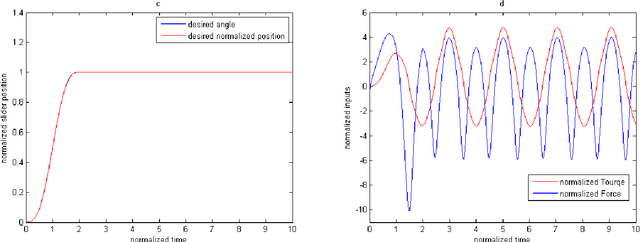
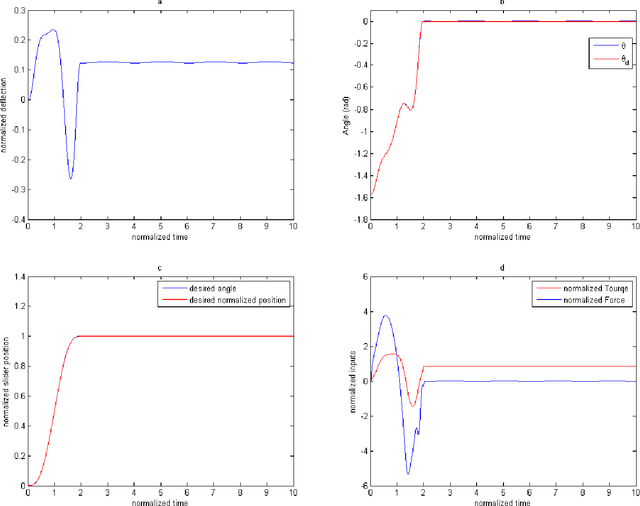
Robot arms with lighter weight can reduce unnecessary energy consumption which is desirable in robotic industry. However, lightweight arms undergo undesirable elastic deformation. In this paper, the planar motion of a lightweight flexible arm is investigated. In order to obtain a precise mathematical model, the axial displacement and nonlinear curvature of flexible arm arising from large bending deformation is taken into consideration. An in-extensional condition, the axial displacement is related to transverse displacement of the flexible beam, is applied. This leads to a robotic model with three rigid modes and one elastic mode. The elastic mode depends on time and position. An Assume Mode Method is used to remove the spatial dependence. The governing equations is derived using Lagrange Method. The effects of nonlinear terms due to the large deformation, gravity, and tip-mass are considered. Control inputs include forces and moment exerted at the joint between slider and arm (see Fig. 1). The conventional computed torque control laws cannot stabilize the system, since there are not as many control inputs as states of the system. A Particle Swarm Optimization (PSO) technique is then used to obtain a suitable trajectory with the aim of minimizing excitations of the elastic mode. Two methods are considered for generating a trajectory function, either to use a three-layer Artificial Neural Network (ANN) or to use spline interpolation. A sliding mode control strategy is proposed in which the sliding surfaces include elastic mode in order to guarantee robustness. The simulations show that the three-layer ANN technique provides arbitrary small settling time, and also the optimization algorithm converges faster and generates smooth trajectories unlike spline function technique.