 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Deep Clustering of Human Activities from Wearables
Aug 19, 2020
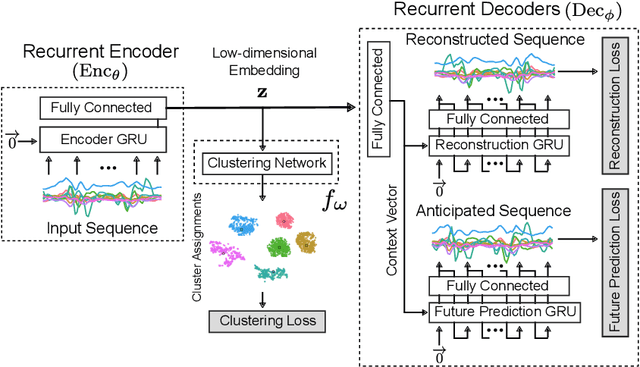
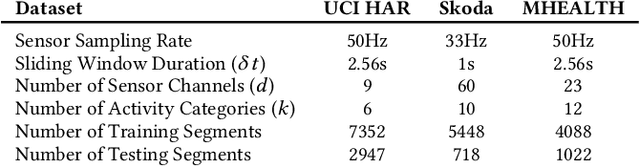
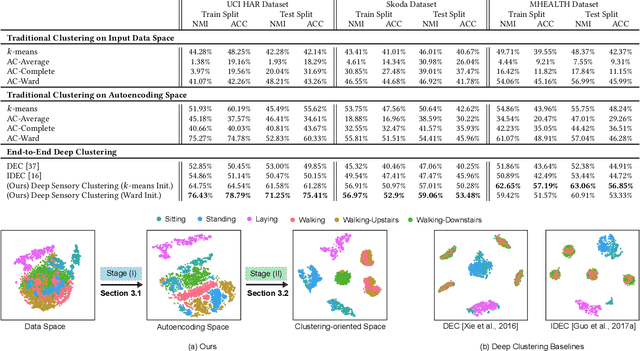
Our ability to exploit low-cost wearable sensing modalities for critical human behaviour and activity monitoring applications in health and wellness is reliant on supervised learning regimes; here, deep learning paradigms have proven extremely successful in learning activity representations from annotated data. However, the costly work of gathering and annotating sensory activity datasets is labor-intensive, time consuming and not scalable to large volumes of data. While existing unsupervised remedies of deep clustering leverage network architectures and optimization objectives that are tailored for static image datasets, deep architectures to uncover cluster structures from raw sequence data captured by on-body sensors remains largely unexplored. In this paper, we develop an unsupervised end-to-end learning strategy for the fundamental problem of human activity recognition (HAR) from wearables. Through extensive experiments, including comparisons with existing methods, we show the effectiveness of our approach to jointly learn unsupervised representations for sensory data and generate cluster assignments with strong semantic correspondence to distinct human activities.
The PREVENTION Challenge: How Good Are Humans Predicting Lane Changes?
Sep 11, 2020
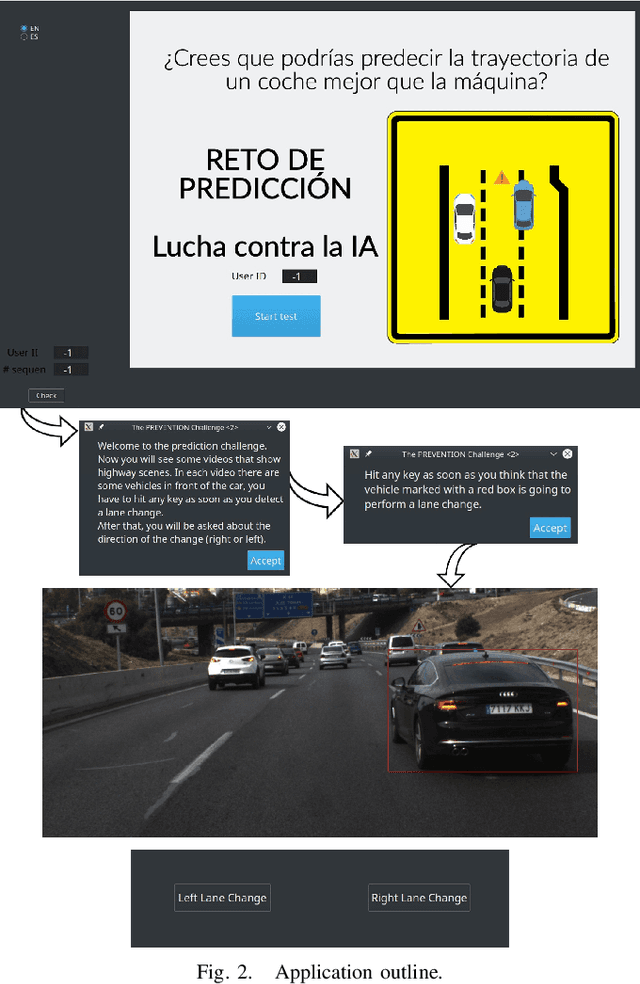

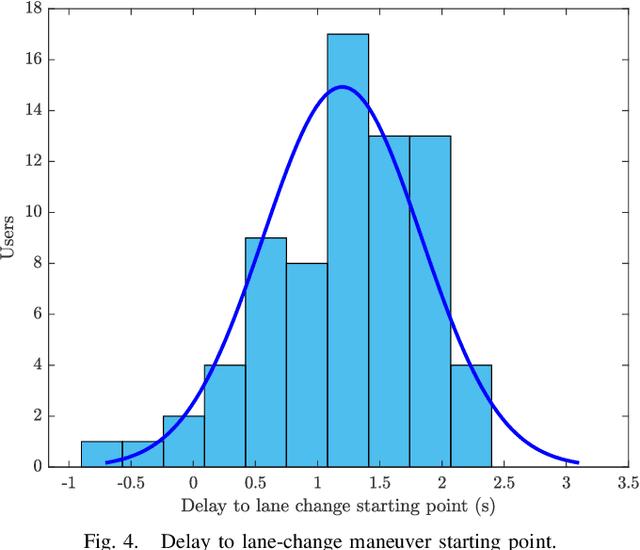
While driving on highways, every driver tries to be aware of the behavior of surrounding vehicles, including possible emergency braking, evasive maneuvers trying to avoid obstacles, unexpected lane changes, or other emergencies that could lead to an accident. In this paper, human's ability to predict lane changes in highway scenarios is analyzed through the use of video sequences extracted from the PREVENTION dataset, a database focused on the development of research on vehicle intention and trajectory prediction. Thus, users had to indicate the moment at which they considered that a lane change maneuver was taking place in a target vehicle, subsequently indicating its direction: left or right. The results retrieved have been carefully analyzed and compared to ground truth labels, evaluating statistical models to understand whether humans can actually predict. The study has revealed that most participants are unable to anticipate lane-change maneuvers, detecting them after they have started. These results might serve as a baseline for AI's prediction ability evaluation, grading if those systems can outperform human skills by analyzing hidden cues that seem unnoticed, improving the detection time, and even anticipating maneuvers in some cases.
Real-Time Anomalous Behavior Detection and Localization in Crowded Scenes
Jan 02, 2016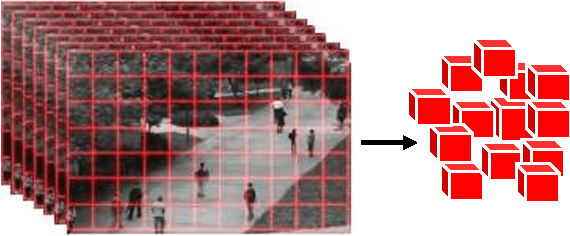


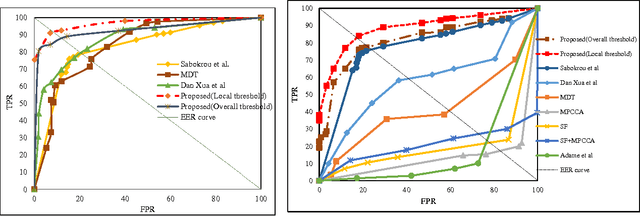
In this paper, we propose an accurate and real-time anomaly detection and localization in crowded scenes, and two descriptors for representing anomalous behavior in video are proposed. We consider a video as being a set of cubic patches. Based on the low likelihood of an anomaly occurrence, and the redundancy of structures in normal patches in videos, two (global and local) views are considered for modeling the video. Our algorithm has two components, for (1) representing the patches using local and global descriptors, and for (2) modeling the training patches using a new representation. We have two Gaussian models for all training patches respect to global and local descriptors. The local and global features are based on structure similarity between adjacent patches and the features that are learned in an unsupervised way. We propose a fusion strategy to combine the two descriptors as the output of our system. Experimental results show that our algorithm performs like a state-of-the-art method on several standard datasets, but even is more time-efficient.
Integrative Object and Pose to Task Detection for an Augmented-Reality-based Human Assistance System using Neural Networks
Aug 31, 2020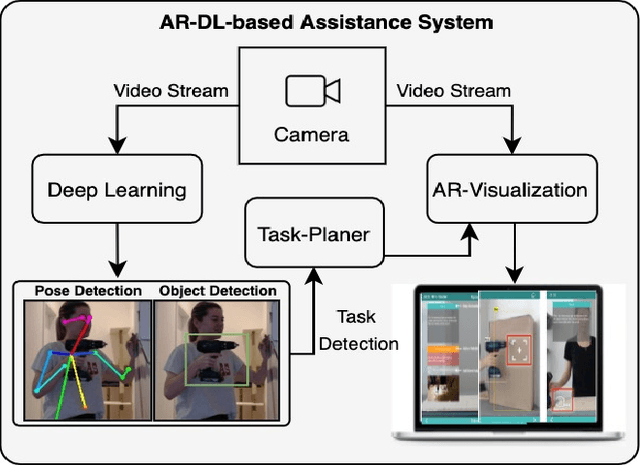
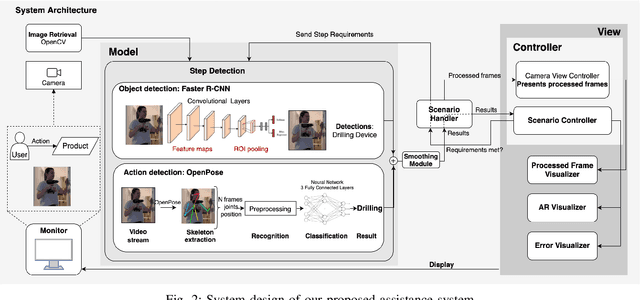

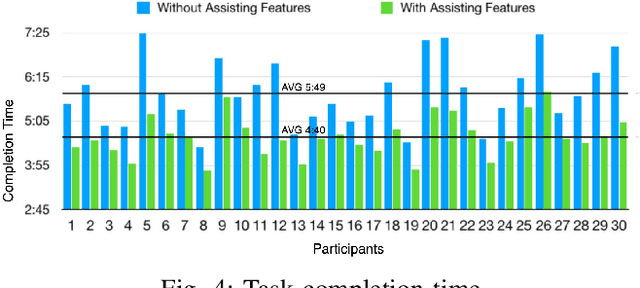
As a result of an increasingly automatized and digitized industry, processes are becoming more complex. Augmented Reality has shown considerable potential in assisting workers with complex tasks by enhancing user understanding and experience with spatial information. However, the acceptance and integration of AR into industrial processes is still limited due to the lack of established methods and tedious integration efforts. Meanwhile, deep neural networks have achieved remarkable results in computer vision tasks and bear great prospects to enrich Augmented Reality applications . In this paper, we propose an Augmented-Reality-based human assistance system to assist workers in complex manual tasks where we incorporate deep neural networks for computer vision tasks. More specifically, we combine Augmented Reality with object and action detectors to make workflows more intuitive and flexible. To evaluate our system in terms of user acceptance and efficiency, we conducted several user studies. We found a significant reduction in time to task completion in untrained workers and a decrease in error rate. Furthermore, we investigated the users learning curve with our assistance system.
Target Tracking In Real Time Surveillance Cameras and Videos
Jun 22, 2015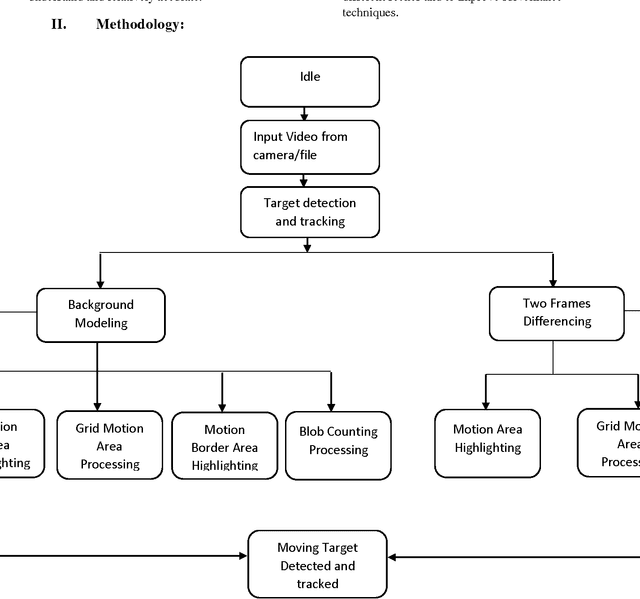

Security concerns has been kept on increasing, so it is important for everyone to keep their property safe from thefts and destruction. So the need for surveillance techniques are also increasing. The system has been developed to detect the motion in a video. A system has been developed for real time applications by using the techniques of background subtraction and frame differencing. In this system, motion is detected from the webcam or from the real time video. Background subtraction and frames differencing method has been used to detect the moving target. In background subtraction method, current frame is subtracted from the referenced frame and then the threshold is applied. If the difference is greater than the threshold then it is considered as the pixel from the moving object, otherwise it is considered as background pixel. Similarly, two frames difference method takes difference between two continuous frames. Then that resultant difference frame is thresholded and the amount of difference pixels is calculated.
Distance Correlation Based Brain Functional Connectivity Estimation and Non-Convex Multi-Task Learning for Developmental fMRI Studies
Sep 30, 2020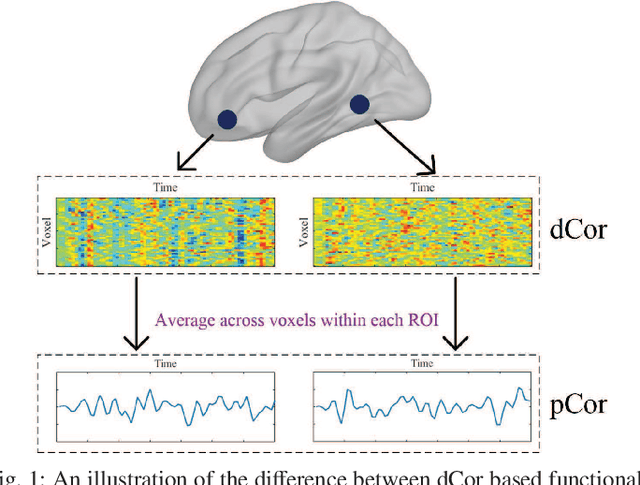
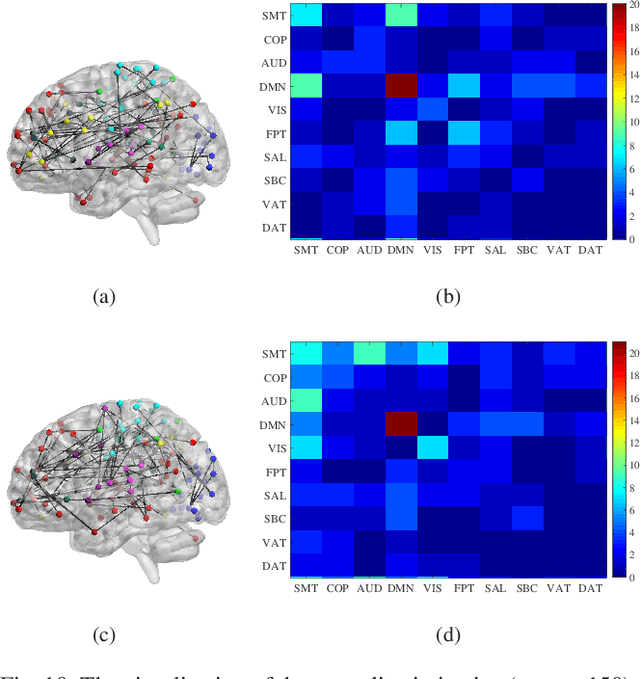
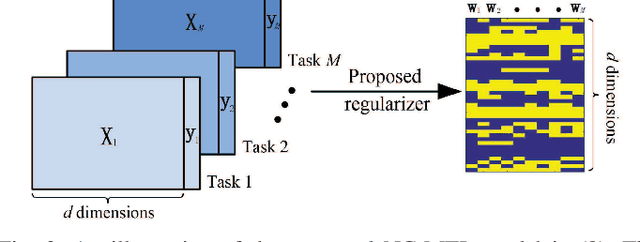
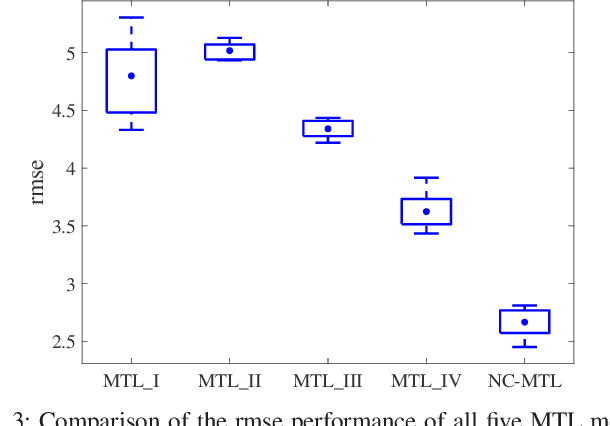
Resting-state functional magnetic resonance imaging (rs-fMRI)-derived functional connectivity patterns have been extensively utilized to delineate global functional organization of the human brain in health, development, and neuropsychiatric disorders. In this paper, we investigate how functional connectivity in males and females differs in an age prediction framework. We first estimate functional connectivity between regions-of-interest (ROIs) using distance correlation instead of Pearson's correlation. Distance correlation, as a multivariate statistical method, explores spatial relations of voxel-wise time courses within individual ROIs and measures both linear and nonlinear dependence, capturing more complex information of between-ROI interactions. Then, a novel non-convex multi-task learning (NC-MTL) model is proposed to study age-related gender differences in functional connectivity, where age prediction for each gender group is viewed as one task. Specifically, in the proposed NC-MTL model, we introduce a composite regularizer with a combination of non-convex $\ell_{2,1-2}$ and $\ell_{1-2}$ regularization terms for selecting both common and task-specific features. Finally, we validate the proposed NC-MTL model along with distance correlation based functional connectivity on rs-fMRI of the Philadelphia Neurodevelopmental Cohort for predicting ages of both genders. The experimental results demonstrate that the proposed NC-MTL model outperforms other competing MTL models in age prediction, as well as characterizing developmental gender differences in functional connectivity patterns.
Direct Adversarial Training for GANs
Aug 19, 2020
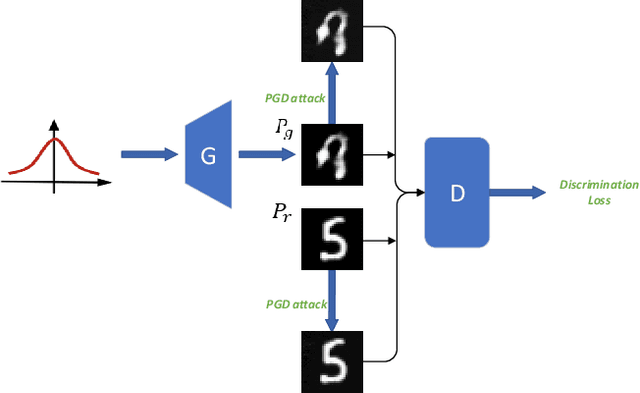
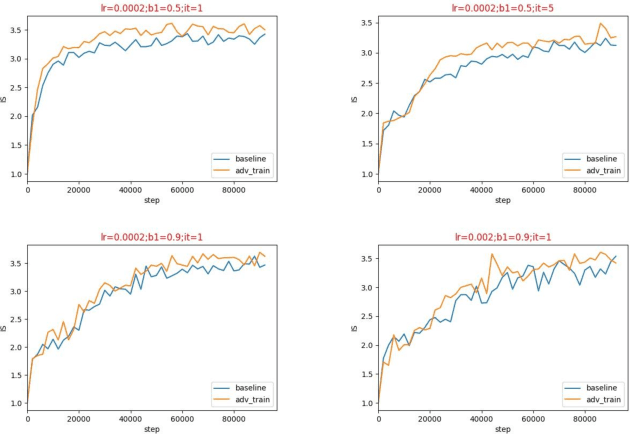
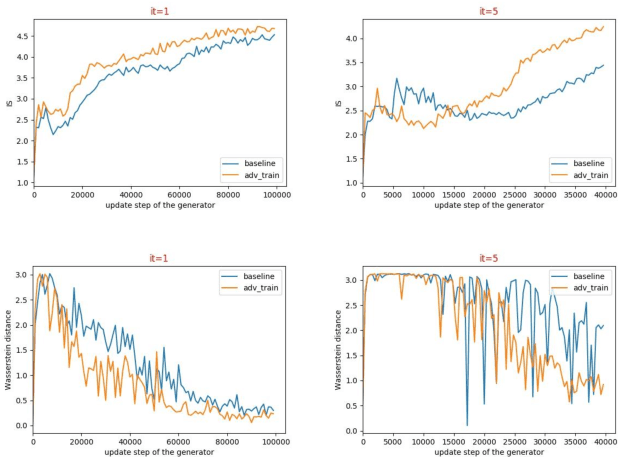
There is an interesting discovery that several neural networks are vulnerable to adversarial examples. That is, many machines learning models misclassify the samples with only a little change which will not be noticed by human eyes. Generative adversarial networks (GANs) are the most popular models for image generation by jointly optimizing discriminator and generator. With stability train, some regularization and normalization have been used to let the discriminator satisfy Lipschitz consistency. In this paper, we have analyzed that the generator may produce adversarial examples for discriminator during the training process, which may cause the unstable training of GANs. For this reason, we propose a direct adversarial training method for GANs. At the same time, we prove that this direct adversarial training can limit the lipschitz constant of the discriminator and accelerate the convergence of the generator. We have verified the advanced performs of the method on multiple baseline networks, such as DCGAN, WGAN, WGAN-GP, and WGAN-LP.
Rethinking Supervised Learning and Reinforcement Learning in Task-Oriented Dialogue Systems
Sep 21, 2020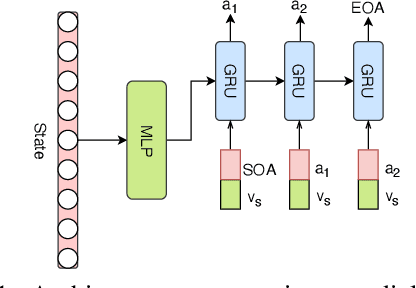
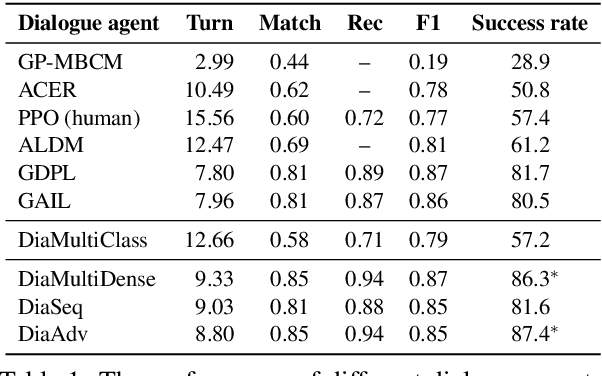
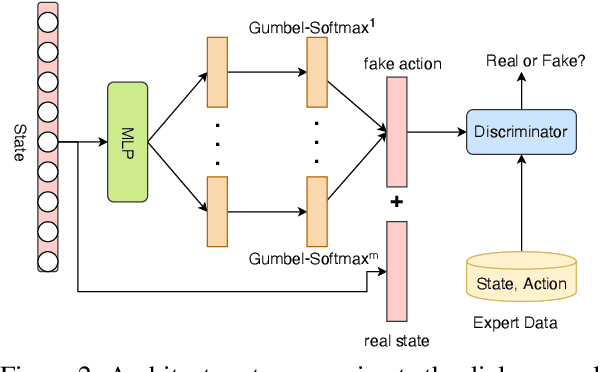

Dialogue policy learning for task-oriented dialogue systems has enjoyed great progress recently mostly through employing reinforcement learning methods. However, these approaches have become very sophisticated. It is time to re-evaluate it. Are we really making progress developing dialogue agents only based on reinforcement learning? We demonstrate how (1)~traditional supervised learning together with (2)~a simulator-free adversarial learning method can be used to achieve performance comparable to state-of-the-art RL-based methods. First, we introduce a simple dialogue action decoder to predict the appropriate actions. Then, the traditional multi-label classification solution for dialogue policy learning is extended by adding dense layers to improve the dialogue agent performance. Finally, we employ the Gumbel-Softmax estimator to alternatively train the dialogue agent and the dialogue reward model without using reinforcement learning. Based on our extensive experimentation, we can conclude the proposed methods can achieve more stable and higher performance with fewer efforts, such as the domain knowledge required to design a user simulator and the intractable parameter tuning in reinforcement learning. Our main goal is not to beat reinforcement learning with supervised learning, but to demonstrate the value of rethinking the role of reinforcement learning and supervised learning in optimizing task-oriented dialogue systems.
* 10 pages
Solving Stochastic Compositional Optimization is Nearly as Easy as Solving Stochastic Optimization
Aug 31, 2020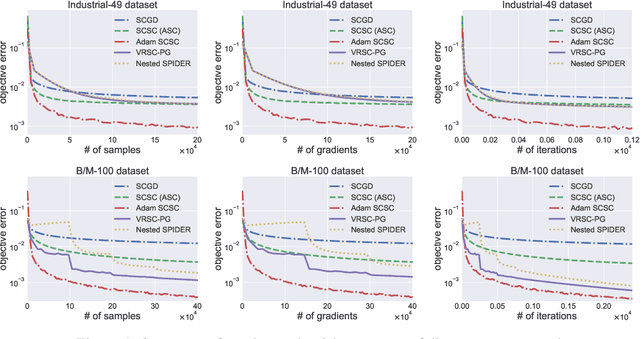
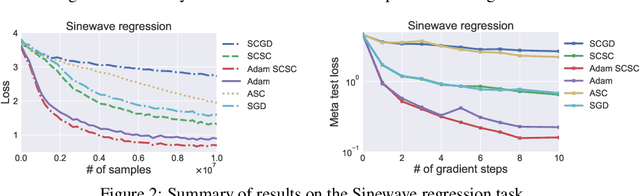
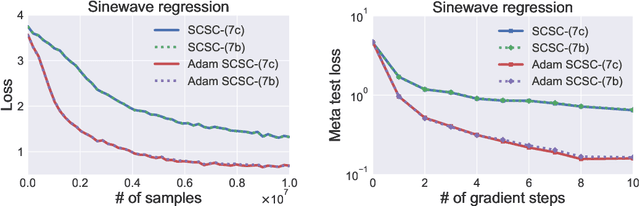
Stochastic compositional optimization generalizes classic (non-compositional) stochastic optimization to the minimization of compositions of functions. Each composition may introduce an additional expectation. The series of expectations may be nested. Stochastic compositional optimization is gaining popularity in applications such as reinforcement learning and meta learning. This paper presents a new Stochastically Corrected Stochastic Compositional gradient method (SCSC). SCSC runs in a single-time scale with a single loop, uses a fixed batch size, and guarantees to converge at the same rate as the stochastic gradient descent (SGD) method for non-compositional stochastic optimization. This is achieved by making a careful improvement to a popular stochastic compositional gradient method. It is easy to apply SGD-improvement techniques to accelerate SCSC. This helps SCSC achieve state-of-the-art performance for stochastic compositional optimization. In particular, we apply Adam to SCSC, and the exhibited rate of convergence matches that of the original Adam on non-compositional stochastic optimization. We test SCSC using the portfolio management and model-agnostic meta-learning tasks.
Demand Prediction Using Machine Learning Methods and Stacked Generalization
Sep 21, 2020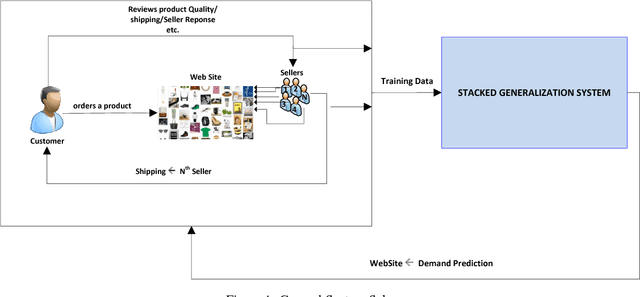
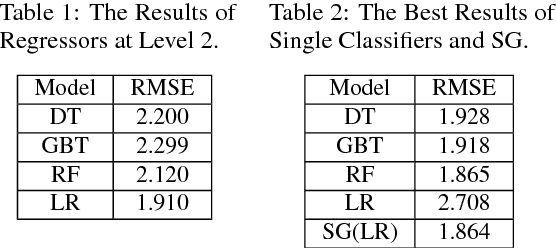
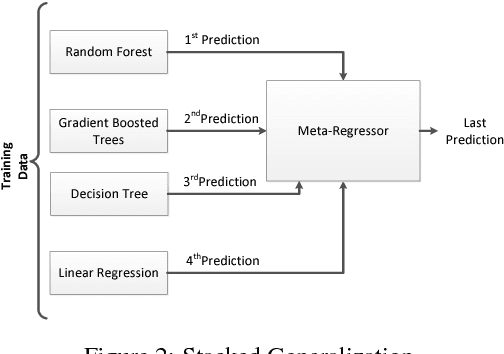
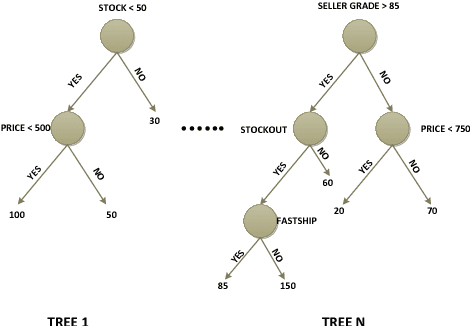
Supply and demand are two fundamental concepts of sellers and customers. Predicting demand accurately is critical for organizations in order to be able to make plans. In this paper, we propose a new approach for demand prediction on an e-commerce web site. The proposed model differs from earlier models in several ways. The business model used in the e-commerce web site, for which the model is implemented, includes many sellers that sell the same product at the same time at different prices where the company operates a market place model. The demand prediction for such a model should consider the price of the same product sold by competing sellers along the features of these sellers. In this study we first applied different regression algorithms for specific set of products of one department of a company that is one of the most popular online e-commerce companies in Turkey. Then we used stacked generalization or also known as stacking ensemble learning to predict demand. Finally, all the approaches are evaluated on a real world data set obtained from the e-commerce company. The experimental results show that some of the machine learning methods do produce almost as good results as the stacked generalization method.