 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-World Deployment of a Lane Change Prediction Architecture Based on Knowledge Graph Embeddings and Bayesian Inference
Jun 13, 2025



Research on lane change prediction has gained a lot of momentum in the last couple of years. However, most research is confined to simulation or results obtained from datasets, leaving a gap between algorithmic advances and on-road deployment. This work closes that gap by demonstrating, on real hardware, a lane-change prediction system based on Knowledge Graph Embeddings (KGEs) and Bayesian inference. Moreover, the ego-vehicle employs a longitudinal braking action to ensure the safety of both itself and the surrounding vehicles. Our architecture consists of two modules: (i) a perception module that senses the environment, derives input numerical features, and converts them into linguistic categories; and communicates them to the prediction module; (ii) a pretrained prediction module that executes a KGE and Bayesian inference model to anticipate the target vehicle's maneuver and transforms the prediction into longitudinal braking action. Real-world hardware experimental validation demonstrates that our prediction system anticipates the target vehicle's lane change three to four seconds in advance, providing the ego vehicle sufficient time to react and allowing the target vehicle to make the lane change safely.
Explainable Lane Change Prediction for Near-Crash Scenarios Using Knowledge Graph Embeddings and Retrieval Augmented Generation
Jan 20, 2025



Lane-changing maneuvers, particularly those executed abruptly or in risky situations, are a significant cause of road traffic accidents. However, current research mainly focuses on predicting safe lane changes. Furthermore, existing accident datasets are often based on images only and lack comprehensive sensory data. In this work, we focus on predicting risky lane changes using the CRASH dataset (our own collected dataset specifically for risky lane changes), and safe lane changes (using the HighD dataset). Then, we leverage KG and Bayesian inference to predict these maneuvers using linguistic contextual information, enhancing the model's interpretability and transparency. The model achieved a 91.5% f1-score with anticipation time extending to four seconds for risky lane changes, and a 90.0% f1-score for predicting safe lane changes with the same anticipation time. We validate our model by integrating it into a vehicle within the CARLA simulator in scenarios that involve risky lane changes. The model managed to anticipate sudden lane changes, thus providing automated vehicles with further time to plan and execute appropriate safe reactions. Finally, to enhance the explainability of our model, we utilize RAG to provide clear and natural language explanations for the given prediction.
Vehicle Lane Change Prediction based on Knowledge Graph Embeddings and Bayesian Inference
Dec 11, 2023



Prediction of vehicle lane change maneuvers has gained a lot of momentum in the last few years. Some recent works focus on predicting a vehicle's intention by predicting its trajectory first. This is not enough, as it ignores the context of the scene and the state of the surrounding vehicles (as they might be risky to the target vehicle). Other works assessed the risk made by the surrounding vehicles only by considering their existence around the target vehicle, or by considering the distance and relative velocities between them and the target vehicle as two separate numerical features. In this work, we propose a solution that leverages Knowledge Graphs (KGs) to anticipate lane changes based on linguistic contextual information in a way that goes well beyond the capabilities of current perception systems. Our solution takes the Time To Collision (TTC) with surrounding vehicles as input to assess the risk on the target vehicle. Moreover, our KG is trained on the HighD dataset using the TransE model to obtain the Knowledge Graph Embeddings (KGE). Then, we apply Bayesian inference on top of the KG using the embeddings learned during training. Finally, the model can predict lane changes two seconds ahead with 97.95% f1-score, which surpassed the state of the art, and three seconds before changing lanes with 93.60% f1-score.
Predicting Vehicles Trajectories in Urban Scenarios with Transformer Networks and Augmented Information
Jun 07, 2021
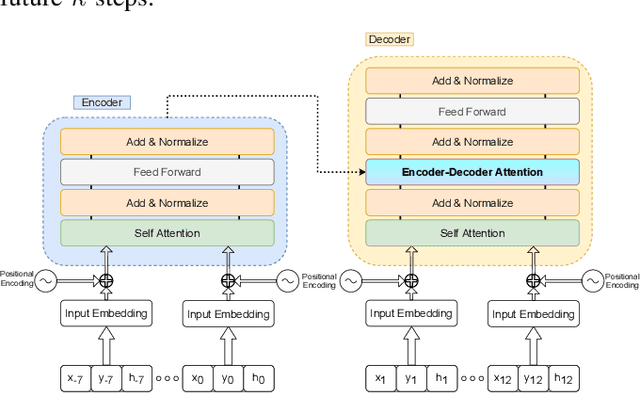
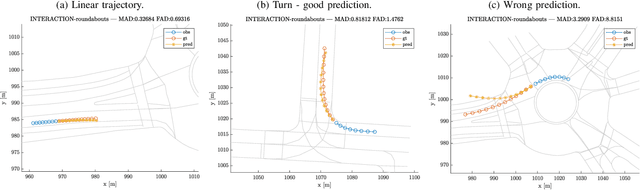
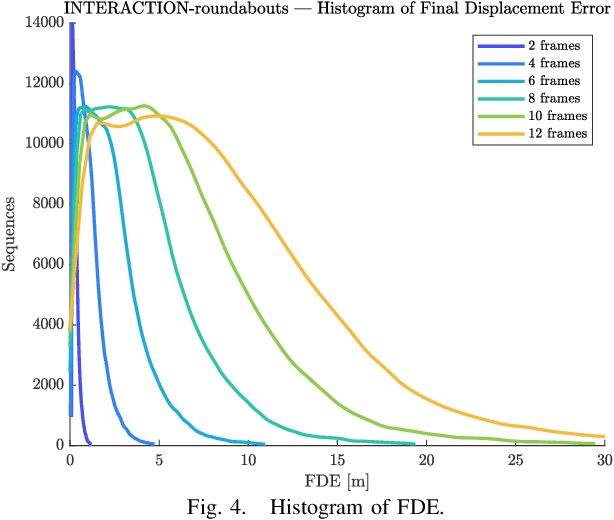
Understanding the behavior of road users is of vital importance for the development of trajectory prediction systems. In this context, the latest advances have focused on recurrent structures, establishing the social interaction between the agents involved in the scene. More recently, simpler structures have also been introduced for predicting pedestrian trajectories, based on Transformer Networks, and using positional information. They allow the individual modelling of each agent's trajectory separately without any complex interaction terms. Our model exploits these simple structures by adding augmented data (position and heading), and adapting their use to the problem of vehicle trajectory prediction in urban scenarios in prediction horizons up to 5 seconds. In addition, a cross-performance analysis is performed between different types of scenarios, including highways, intersections and roundabouts, using recent datasets (inD, rounD, highD and INTERACTION). Our model achieves state-of-the-art results and proves to be flexible and adaptable to different types of urban contexts.
The PREVENTION Challenge: How Good Are Humans Predicting Lane Changes?
Sep 11, 2020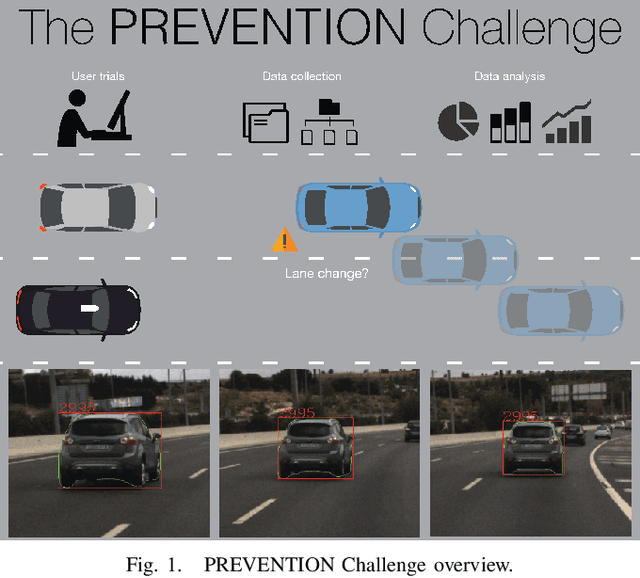
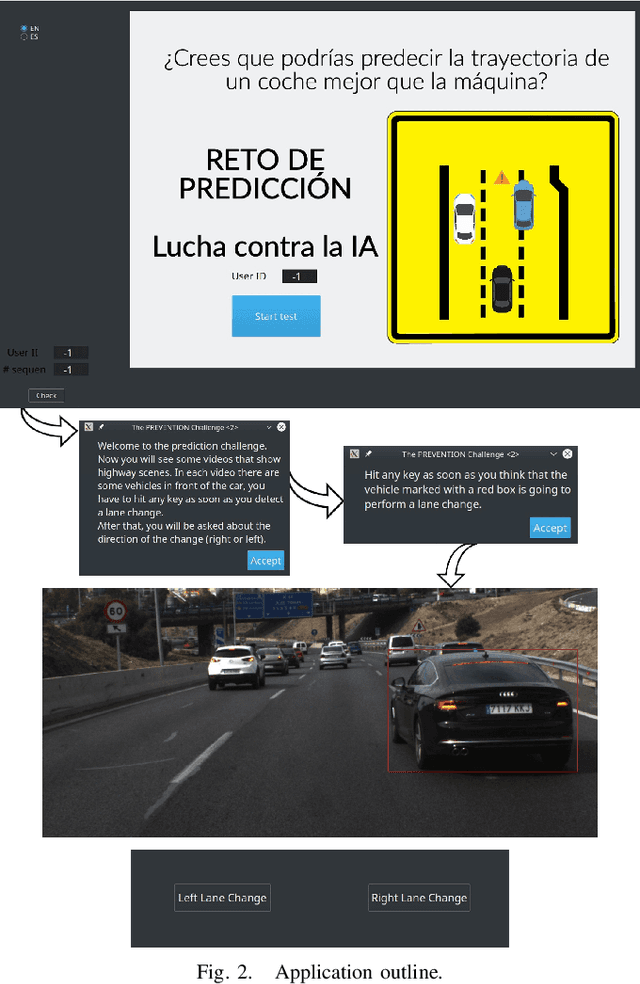

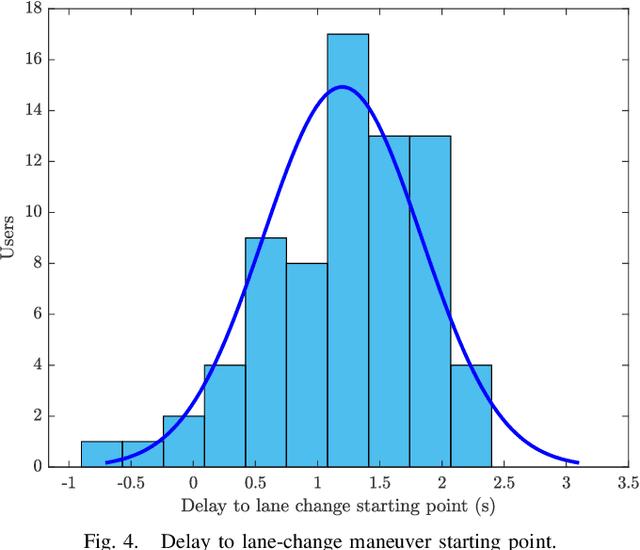
While driving on highways, every driver tries to be aware of the behavior of surrounding vehicles, including possible emergency braking, evasive maneuvers trying to avoid obstacles, unexpected lane changes, or other emergencies that could lead to an accident. In this paper, human's ability to predict lane changes in highway scenarios is analyzed through the use of video sequences extracted from the PREVENTION dataset, a database focused on the development of research on vehicle intention and trajectory prediction. Thus, users had to indicate the moment at which they considered that a lane change maneuver was taking place in a target vehicle, subsequently indicating its direction: left or right. The results retrieved have been carefully analyzed and compared to ground truth labels, evaluating statistical models to understand whether humans can actually predict. The study has revealed that most participants are unable to anticipate lane-change maneuvers, detecting them after they have started. These results might serve as a baseline for AI's prediction ability evaluation, grading if those systems can outperform human skills by analyzing hidden cues that seem unnoticed, improving the detection time, and even anticipating maneuvers in some cases.
Vehicle Trajectory Prediction in Crowded Highway Scenarios Using Bird Eye View Representations and CNNs
Aug 26, 2020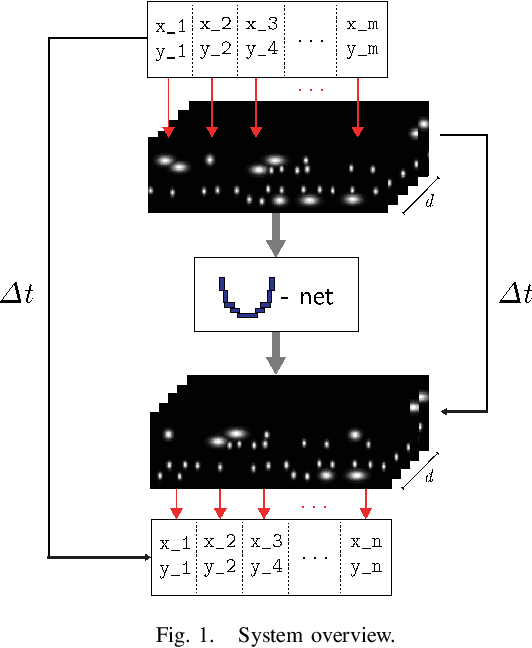
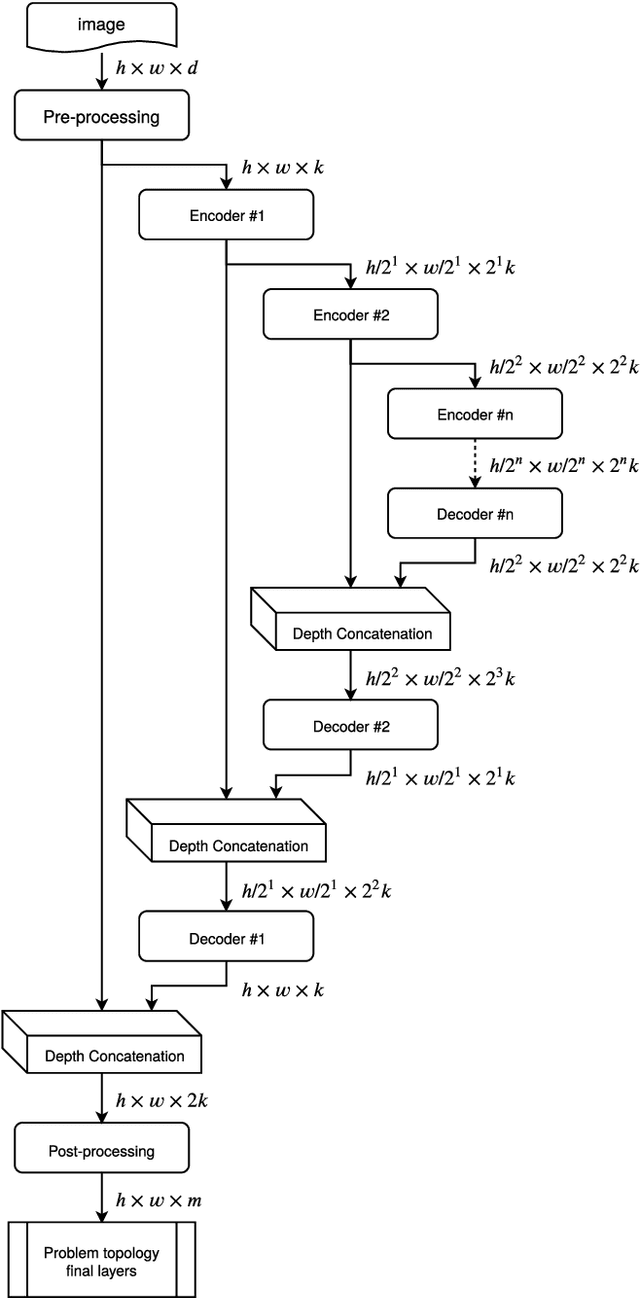

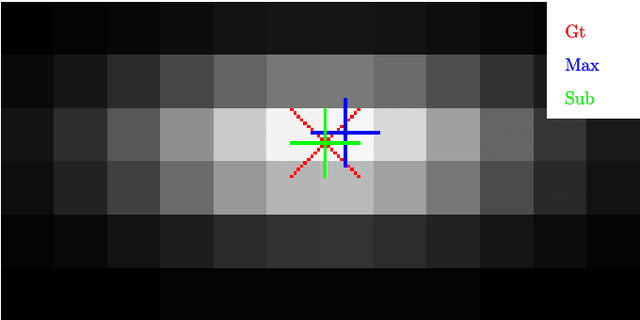
This paper describes a novel approach to perform vehicle trajectory predictions employing graphic representations. The vehicles are represented using Gaussian distributions into a Bird Eye View. Then the U-net model is used to perform sequence to sequence predictions. This deep learning-based methodology has been trained using the HighD dataset, which contains vehicles' detection in a highway scenario from aerial imagery. The problem is faced as an image to image regression problem training the network to learn the underlying relations between the traffic participants. This approach generates an estimation of the future appearance of the input scene, not trajectories or numeric positions. An extra step is conducted to extract the positions from the predicted representation with subpixel resolution. Different network configurations have been tested, and prediction error up to three seconds ahead is in the order of the representation resolution. The model has been tested in highway scenarios with more than 30 vehicles simultaneously in two opposite traffic flow streams showing good qualitative and quantitative results.