 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Approximating intractable short ratemodel distribution with neural network
Jan 13, 2020
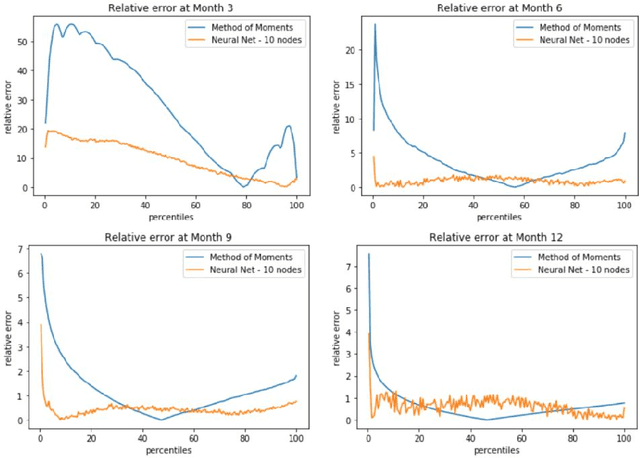
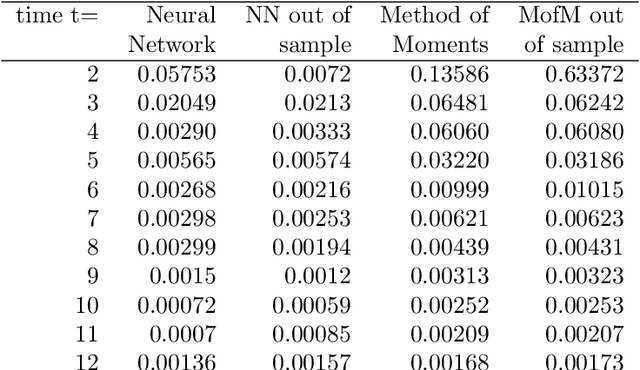
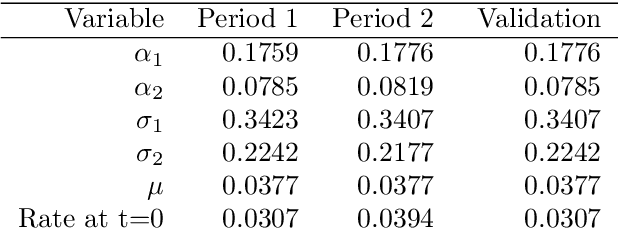
We propose an algorithm which predicts each subsequent time step relative to the previous time step of intractable short rate model (when adjusted for drift and overall distribution of previous percentile result) and show that the method achieves superior outcomes to the unbiased estimate both on the trained dataset and different validation data.
Toward Automated Virtual Assembly for Prefabricated Construction: Construction Sequencing through Simulated BIM
Mar 14, 2020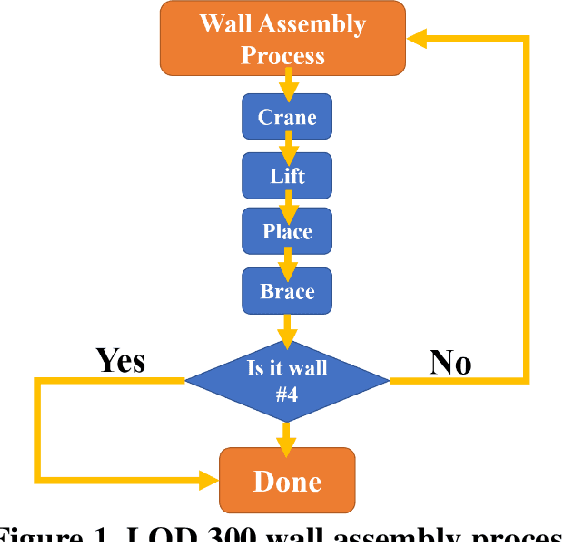
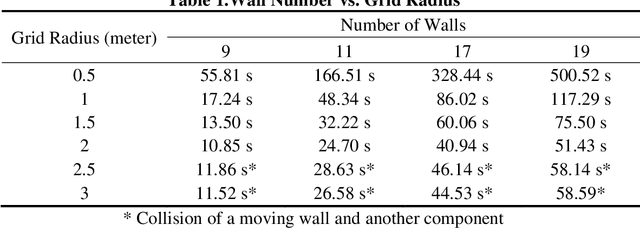
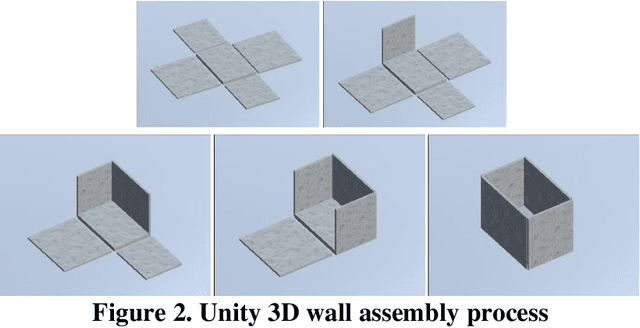
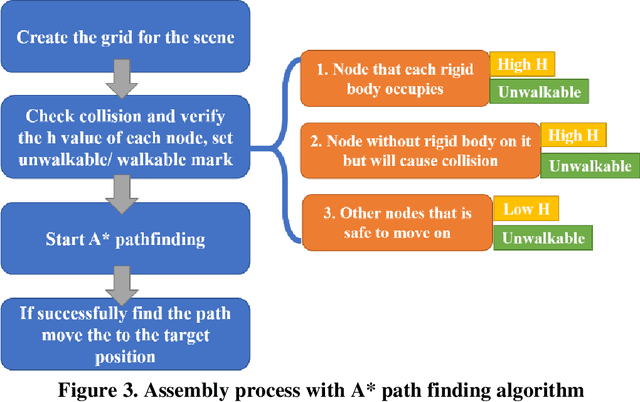
To adhere to the stringent time and budget requirements of construction projects, contractors are utilizing prefabricated construction methods to expedite the construction process. Prefabricated construction methods require an adequate schedule and understanding by the contractors and constructors to be successful. The specificity of prefabricated construction often leads to inefficient scheduling and costly rework time. The designer, contractor, and constructors must have a strong understanding of the assembly process to experience the full benefits of the method. At the root of understanding the assembly process is visualizing how the process is intended to be performed. Currently, a virtual construction model is used to explain and better visualize the construction process. However, creating a virtual construction model is currently time consuming and requires experienced personnel. The proposed simulation of the virtual assembly will increase the automation of virtual construction modeling by implementing the data available in a building information modeling (BIM) model. This paper presents various factors (i.e., formalization of construction sequence based on the level of development (LOD)) that needs to be addressed for the development of automated virtual assembly. Two case studies are presented to demonstrate these factors.
Fast nonparametric clustering of structured time-series
Apr 14, 2014
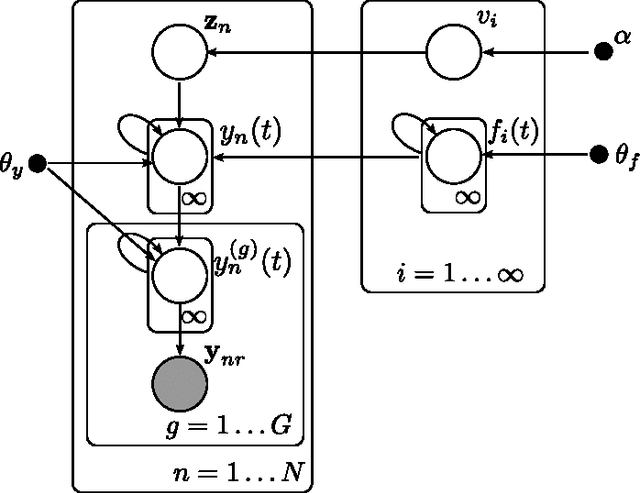
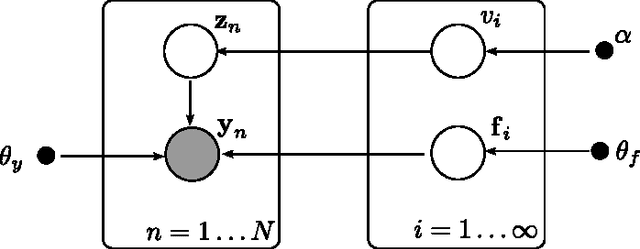
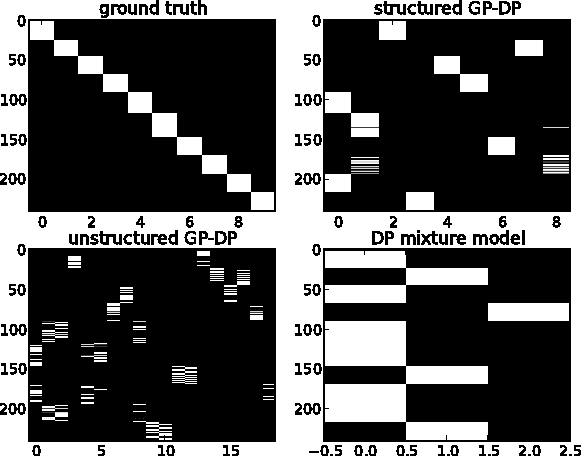
In this publication, we combine two Bayesian non-parametric models: the Gaussian Process (GP) and the Dirichlet Process (DP). Our innovation in the GP model is to introduce a variation on the GP prior which enables us to model structured time-series data, i.e. data containing groups where we wish to model inter- and intra-group variability. Our innovation in the DP model is an implementation of a new fast collapsed variational inference procedure which enables us to optimize our variationala pproximation significantly faster than standard VB approaches. In a biological time series application we show how our model better captures salient features of the data, leading to better consistency with existing biological classifications, while the associated inference algorithm provides a twofold speed-up over EM-based variational inference.
Sparse sketches with small inversion bias
Nov 21, 2020For a tall $n\times d$ matrix $A$ and a random $m\times n$ sketching matrix $S$, the sketched estimate of the inverse covariance matrix $(A^\top A)^{-1}$ is typically biased: $E[(\tilde A^\top\tilde A)^{-1}]\ne(A^\top A)^{-1}$, where $\tilde A=SA$. This phenomenon, which we call inversion bias, arises, e.g., in statistics and distributed optimization, when averaging multiple independently constructed estimates of quantities that depend on the inverse covariance. We develop a framework for analyzing inversion bias, based on our proposed concept of an $(\epsilon,\delta)$-unbiased estimator for random matrices. We show that when the sketching matrix $S$ is dense and has i.i.d. sub-gaussian entries, then after simple rescaling, the estimator $(\frac m{m-d}\tilde A^\top\tilde A)^{-1}$ is $(\epsilon,\delta)$-unbiased for $(A^\top A)^{-1}$ with a sketch of size $m=O(d+\sqrt d/\epsilon)$. This implies that for $m=O(d)$, the inversion bias of this estimator is $O(1/\sqrt d)$, which is much smaller than the $\Theta(1)$ approximation error obtained as a consequence of the subspace embedding guarantee for sub-gaussian sketches. We then propose a new sketching technique, called LEverage Score Sparsified (LESS) embeddings, which uses ideas from both data-oblivious sparse embeddings as well as data-aware leverage-based row sampling methods, to get $\epsilon$ inversion bias for sketch size $m=O(d\log d+\sqrt d/\epsilon)$ in time $O(\text{nnz}(A)\log n+md^2)$, where nnz is the number of non-zeros. The key techniques enabling our analysis include an extension of a classical inequality of Bai and Silverstein for random quadratic forms, which we call the Restricted Bai-Silverstein inequality; and anti-concentration of the Binomial distribution via the Paley-Zygmund inequality, which we use to prove a lower bound showing that leverage score sampling sketches generally do not achieve small inversion bias.
Temporally Folded Convolutional Neural Networks for Sequence Forecasting
Jan 10, 2020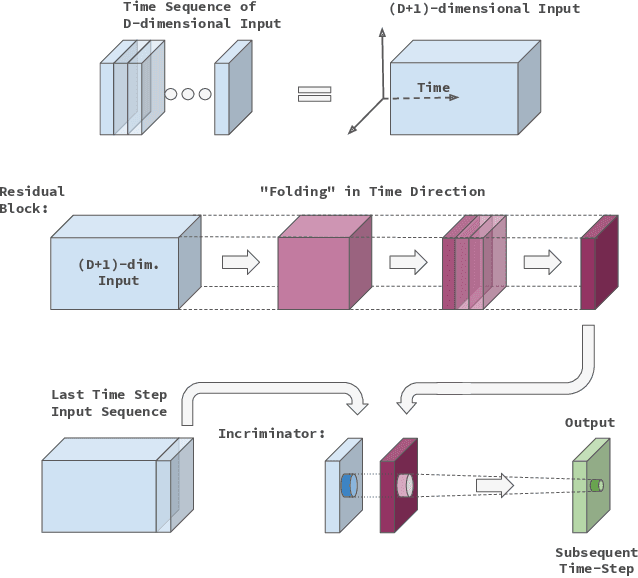
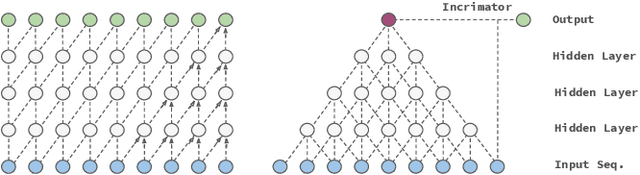
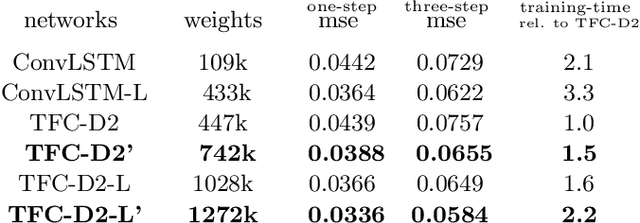

In this work we propose a novel approach to utilize convolutional neural networks for time series forecasting. The time direction of the sequential data with spatial dimensions $D=1,2$ is considered democratically as the input of a spatiotemporal $(D+1)$-dimensional convolutional neural network. Latter then reduces the data stream from $D +1 \to D$ dimensions followed by an incriminator cell which uses this information to forecast the subsequent time step. We empirically compare this strategy to convolutional LSTM's and LSTM's on their performance on the sequential MNIST and the JSB chorals dataset, respectively. We conclude that temporally folded convolutional neural networks (TFC's) may outperform the conventional recurrent strategies.
A comparative study of forecasting Corporate Credit Ratings using Neural Networks, Support Vector Machines, and Decision Trees
Jul 13, 2020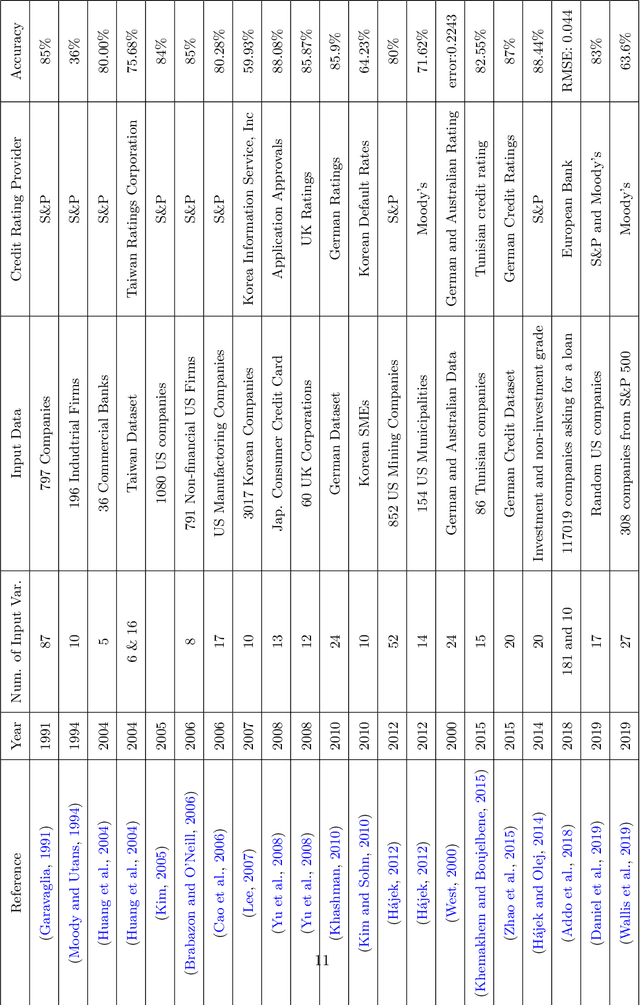
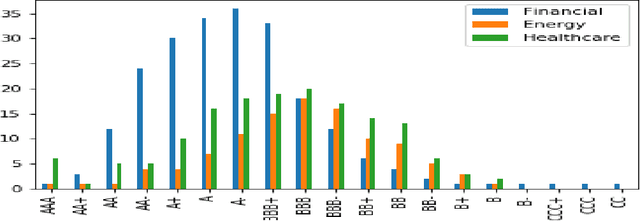
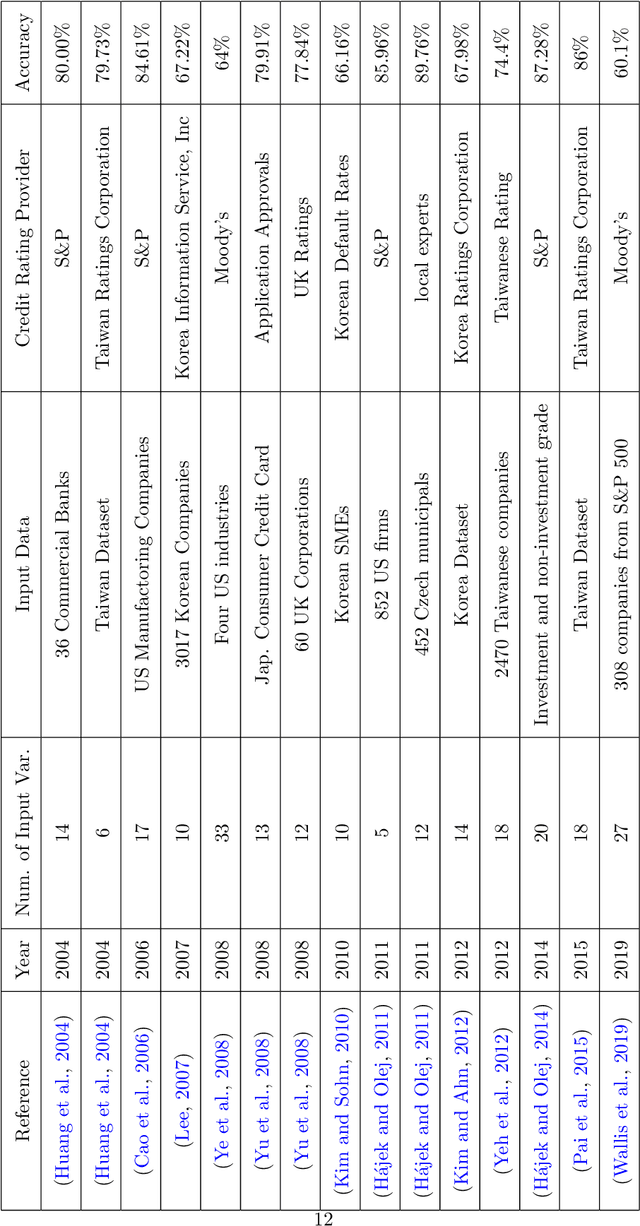

Credit ratings are one of the primary keys that reflect the level of riskiness and reliability of corporations to meet their financial obligations. Rating agencies tend to take extended periods of time to provide new ratings and update older ones. Therefore, credit scoring assessments using artificial intelligence has gained a lot of interest in recent years. Successful machine learning methods can provide rapid analysis of credit scores while updating older ones on a daily time scale. Related studies have shown that neural networks and support vector machines outperform other techniques by providing better prediction accuracy. The purpose of this paper is two fold. First, we provide a survey and a comparative analysis of results from literature applying machine learning techniques to predict credit rating. Second, we apply ourselves four machine learning techniques deemed useful from previous studies (Bagged Decision Trees, Random Forest, Support Vector Machine and Multilayer Perceptron) to the same datasets. We evaluate the results using a 10-fold cross validation technique. The results of the experiment for the datasets chosen show superior performance for decision tree based models. In addition to the conventional accuracy measure of classifiers, we introduce a measure of accuracy based on notches called "Notch Distance" to analyze the performance of the above classifiers in the specific context of credit rating. This measure tells us how far the predictions are from the true ratings. We further compare the performance of three major rating agencies, Standard $\&$ Poors, Moody's and Fitch where we show that the difference in their ratings is comparable with the decision tree prediction versus the actual rating on the test dataset.
SOLO: A Corpus of Tweets for Examining the State of Being Alone
Jun 04, 2020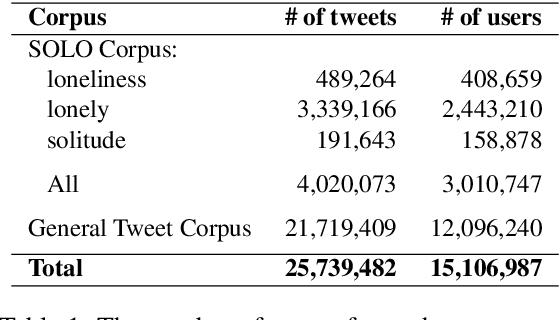
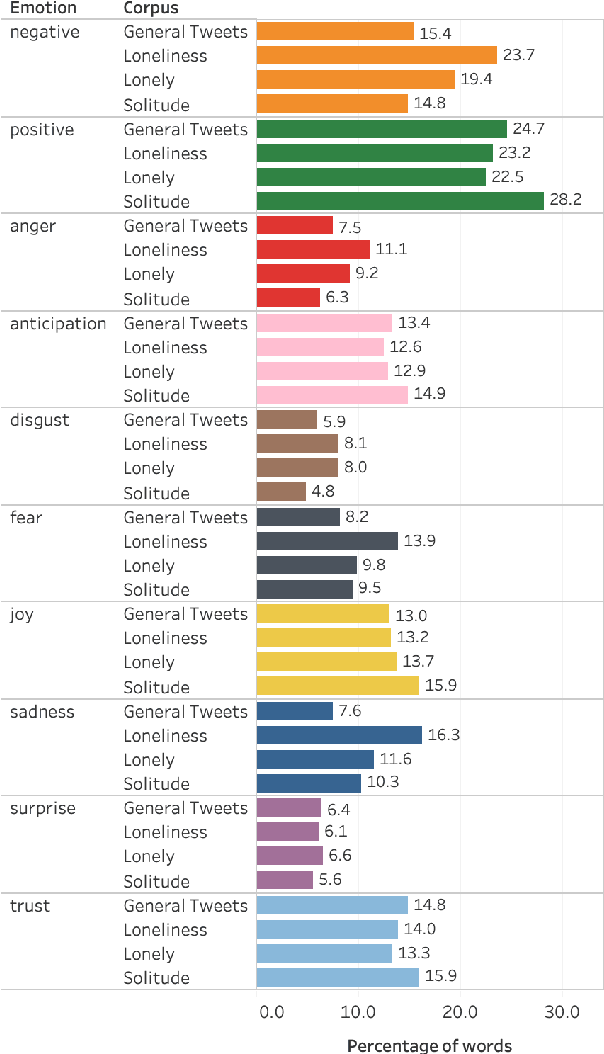

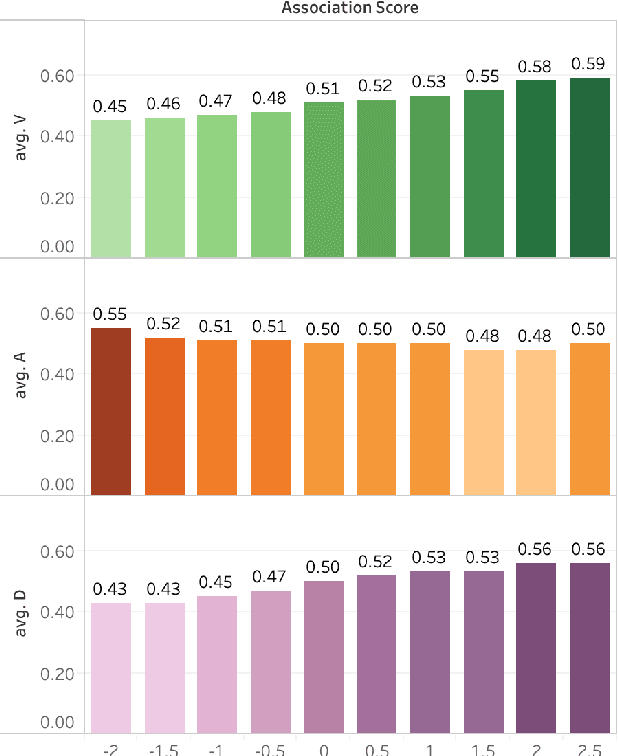
The state of being alone can have a substantial impact on our lives, though experiences with time alone diverge significantly among individuals. Psychologists distinguish between the concept of solitude, a positive state of voluntary aloneness, and the concept of loneliness, a negative state of dissatisfaction with the quality of one's social interactions. Here, for the first time, we conduct a large-scale computational analysis to explore how the terms associated with the state of being alone are used in online language. We present SOLO (State of Being Alone), a corpus of over 4 million tweets collected with query terms 'solitude', 'lonely', and 'loneliness'. We use SOLO to analyze the language and emotions associated with the state of being alone. We show that the term 'solitude' tends to co-occur with more positive, high-dominance words (e.g., enjoy, bliss) while the terms 'lonely' and 'loneliness' frequently co-occur with negative, low-dominance words (e.g., scared, depressed), which confirms the conceptual distinctions made in psychology. We also show that women are more likely to report on negative feelings of being lonely as compared to men, and there are more teenagers among the tweeters that use the word 'lonely' than among the tweeters that use the word 'solitude'.
Exploring BERT Parameter Efficiency on the Stanford Question Answering Dataset v2.0
Mar 03, 2020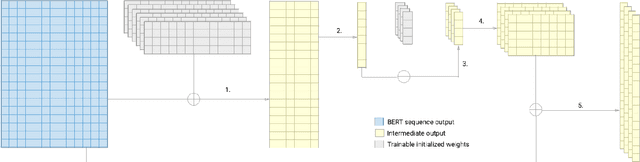
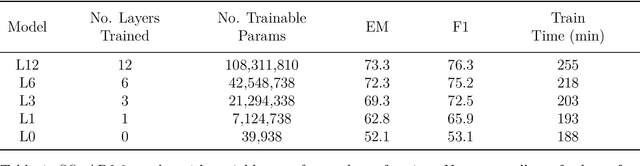
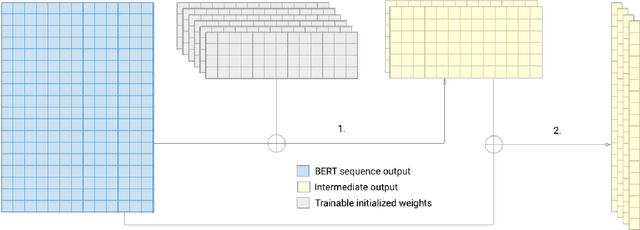

In this paper we explore the parameter efficiency of BERT arXiv:1810.04805 on version 2.0 of the Stanford Question Answering dataset (SQuAD2.0). We evaluate the parameter efficiency of BERT while freezing a varying number of final transformer layers as well as including the adapter layers proposed in arXiv:1902.00751. Additionally, we experiment with the use of context-aware convolutional (CACNN) filters, as described in arXiv:1709.08294v3, as a final augmentation layer for the SQuAD2.0 tasks. This exploration is motivated in part by arXiv:1907.10597, which made a compelling case for broadening the evaluation criteria of artificial intelligence models to include various measures of resource efficiency. While we do not evaluate these models based on their floating point operation efficiency as proposed in arXiv:1907.10597, we examine efficiency with respect to training time, inference time, and total number of model parameters. Our results largely corroborate those of arXiv:1902.00751 for adapter modules, while also demonstrating that gains in F1 score from adding context-aware convolutional filters are not practical due to the increase in training and inference time.
learn2learn: A Library for Meta-Learning Research
Aug 27, 2020Meta-learning researchers face two fundamental issues in their empirical work: prototyping and reproducibility. Researchers are prone to make mistakes when prototyping new algorithms and tasks because modern meta-learning methods rely on unconventional functionalities of machine learning frameworks. In turn, reproducing existing results becomes a tedious endeavour -- a situation exacerbated by the lack of standardized implementations and benchmarks. As a result, researchers spend inordinate amounts of time on implementing software rather than understanding and developing new ideas. This manuscript introduces learn2learn, a library for meta-learning research focused on solving those prototyping and reproducibility issues. learn2learn provides low-level routines common across a wide-range of meta-learning techniques (e.g. meta-descent, meta-reinforcement learning, few-shot learning), and builds standardized interfaces to algorithms and benchmarks on top of them. In releasing learn2learn under a free and open source license, we hope to foster a community around standardized software for meta-learning research.
Classification and Recognition of Encrypted EEG Data Neural Network
Jun 15, 2020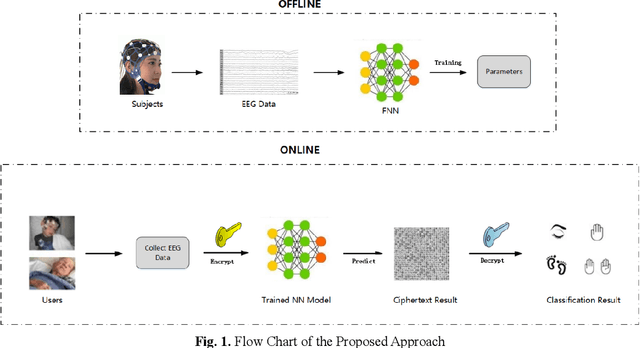

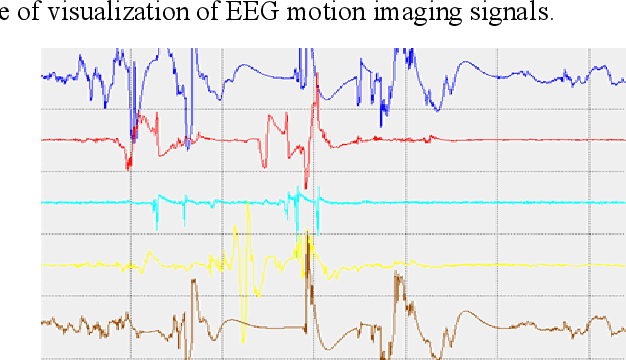
With the rapid development of Machine Learning technology applied in electroencephalography (EEG) signals, Brain-Computer Interface (BCI) has emerged as a novel and convenient human-computer interaction for smart home, intelligent medical and other Internet of Things (IoT) scenarios. However, security issues such as sensitive information disclosure and unauthorized operations have not received sufficient concerns. There are still some defects with the existing solutions to encrypted EEG data such as low accuracy, high time complexity or slow processing speed. For this reason, a classification and recognition method of encrypted EEG data based on neural network is proposed, which adopts Paillier encryption algorithm to encrypt EEG data and meanwhile resolves the problem of floating point operations. In addition, it improves traditional feed-forward neural network (FNN) by using the approximate function instead of activation function and realizes multi-classification of encrypted EEG data. Extensive experiments are conducted to explore the effect of several metrics (such as the hidden neuron size and the learning rate updated by improved simulated annealing algorithm) on the recognition results. Followed by security and time cost analysis, the proposed model and approach are validated and evaluated on public EEG datasets provided by PhysioNet, BCI Competition IV and EPILEPSIAE. The experimental results show that our proposal has the satisfactory accuracy, efficiency and feasibility compared with other solutions.