 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Animated Cassie: A Dynamic Relatable Robotic Character
Sep 07, 2020
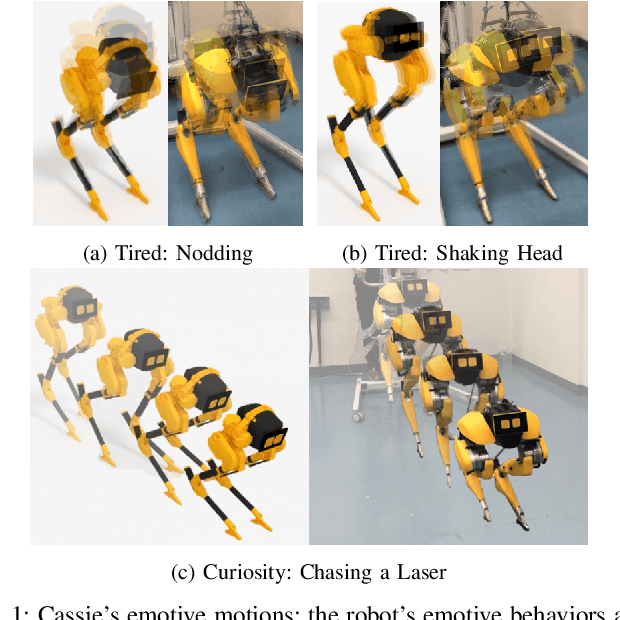
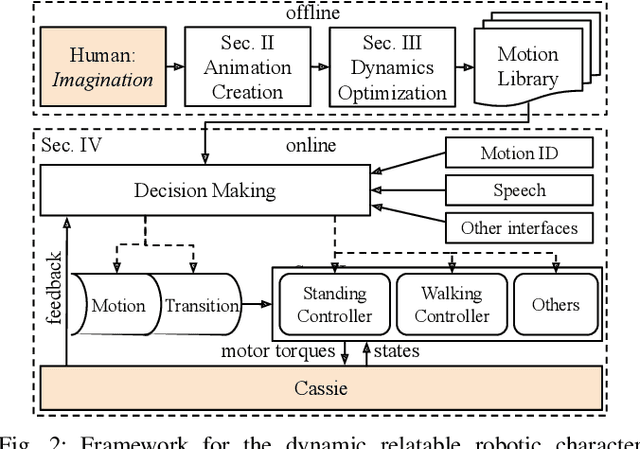
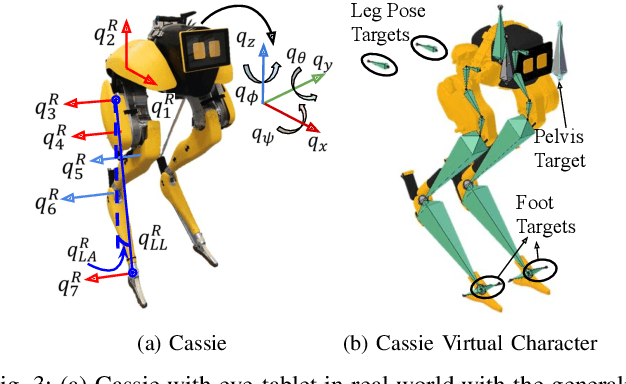
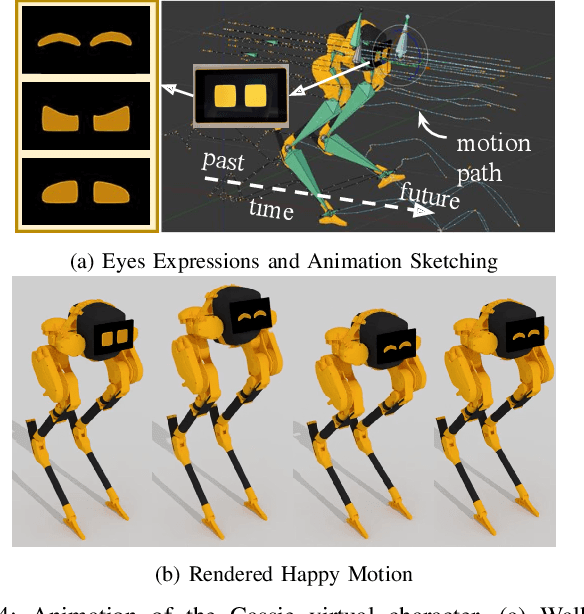
Creating robots with emotional personalities will transform the usability of robots in the real world. As previous emotive social robots are mostly based on statically stable robots whose mobility is limited, this paper develops an animation to real world pipeline that enables dynamic bipedal robots that can twist, wiggle, and walk to behave with emotions. First, an animation method is introduced to design emotive motions for the virtual robot character. Second, a dynamics optimizer is used to convert the animated motion to dynamically feasible motion. Third, real time standing and walking controllers and an automaton are developed to bring the virtual character to life. This framework is deployed on a bipedal robot Cassie and validated in experiments. To the best of our knowledge, this paper is one of the first to present an animatronic dynamic legged robot that is able to perform motions with desired emotional attributes. We term robots that use dynamic motions to convey emotions as Dynamic Relatable Robotic Characters.
Quantifying and Reducing Bias in Maximum Likelihood Estimation of Structured Anomalies
Jul 15, 2020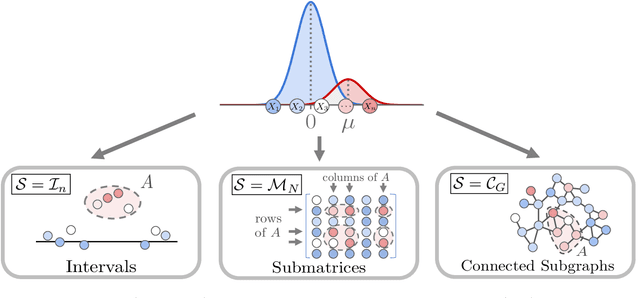
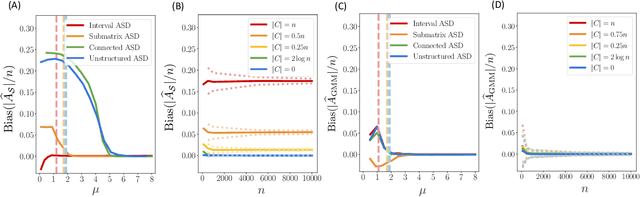
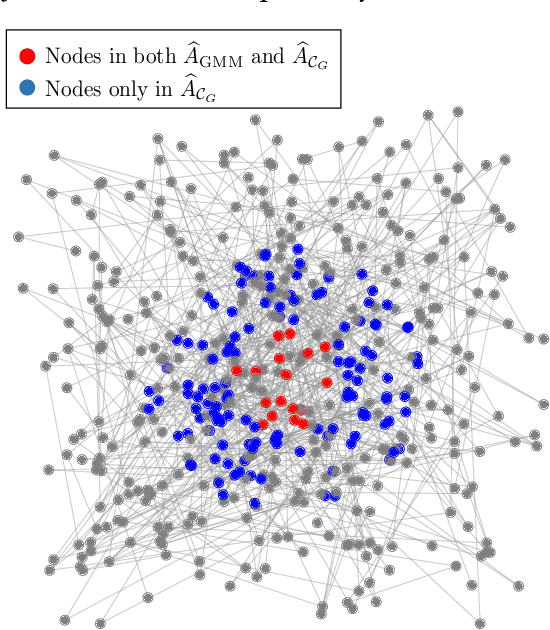
Anomaly estimation, or the problem of finding a subset of a dataset that differs from the rest of the dataset, is a classic problem in machine learning and data mining. In both theoretical work and in applications, the anomaly is assumed to have a specific structure defined by membership in an $\textit{anomaly family}$. For example, in temporal data the anomaly family may be time intervals, while in network data the anomaly family may be connected subgraphs. The most prominent approach for anomaly estimation is to compute the Maximum Likelihood Estimator (MLE) of the anomaly. However, it was recently observed that for some anomaly families, the MLE is an asymptotically $\textit{biased}$ estimator of the anomaly. Here, we demonstrate that the bias of the MLE depends on the size of the anomaly family. We prove that if the number of sets in the anomaly family that contain the anomaly is sub-exponential, then the MLE is asymptotically unbiased. At the same time, we provide empirical evidence that the converse is also true: if the number of such sets is exponential, then the MLE is asymptotically biased. Our analysis unifies a number of earlier results on the bias of the MLE for specific anomaly families, including intervals, submatrices, and connected subgraphs. Next, we derive a new anomaly estimator using a mixture model, and we empirically demonstrate that our estimator is asymptotically unbiased regardless of the size of the anomaly family. We illustrate the benefits of our estimator on both simulated disease outbreak data and a real-world highway traffic dataset.
Listen Attentively, and Spell Once: Whole Sentence Generation via a Non-Autoregressive Architecture for Low-Latency Speech Recognition
May 11, 2020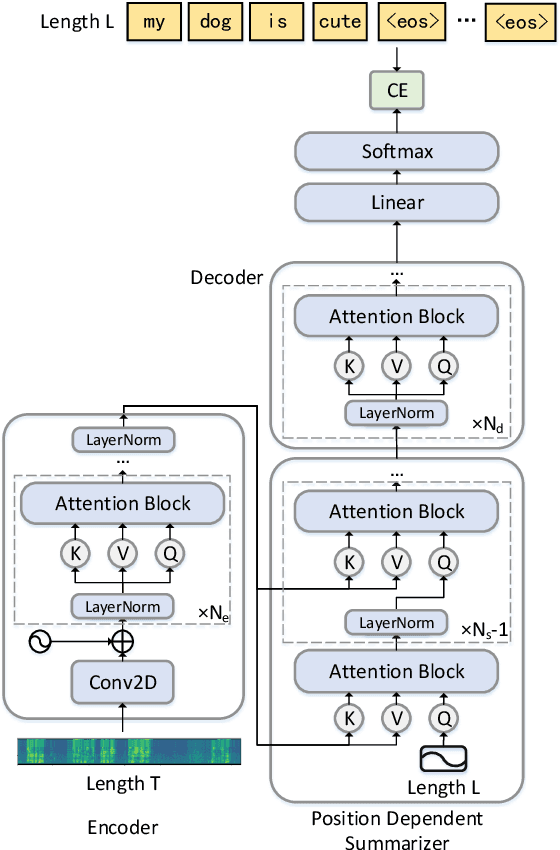
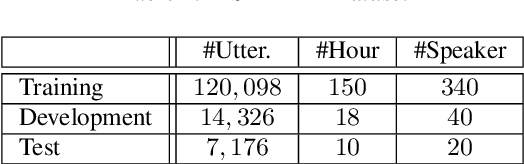
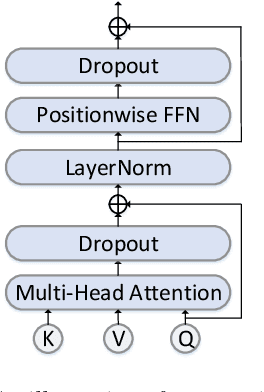
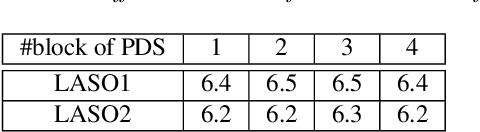
Although attention based end-to-end models have achieved promising performance in speech recognition, the multi-pass forward computation in beam-search increases inference time cost, which limits their practical applications. To address this issue, we propose a non-autoregressive end-to-end speech recognition system called LASO (listen attentively, and spell once). Because of the non-autoregressive property, LASO predicts a textual token in the sequence without the dependence on other tokens. Without beam-search, the one-pass propagation much reduces inference time cost of LASO. And because the model is based on the attention based feedforward structure, the computation can be implemented in parallel efficiently. We conduct experiments on publicly available Chinese dataset AISHELL-1. LASO achieves a character error rate of 6.4%, which outperforms the state-of-the-art autoregressive transformer model (6.7%). The average inference latency is 21 ms, which is 1/50 of the autoregressive transformer model.
Spoken Language Interaction with Robots: Research Issues and Recommendations, Report from the NSF Future Directions Workshop
Nov 11, 2020
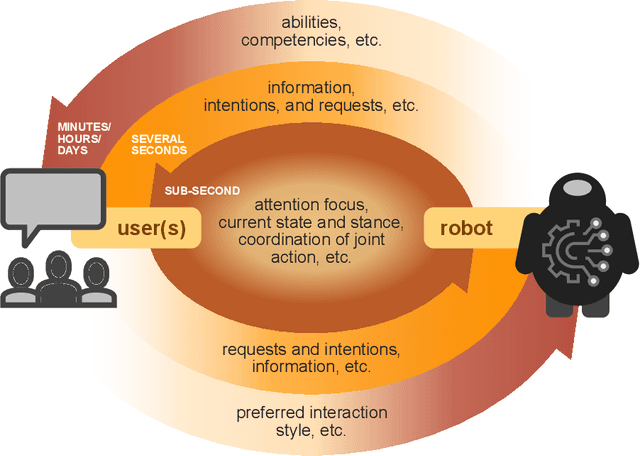
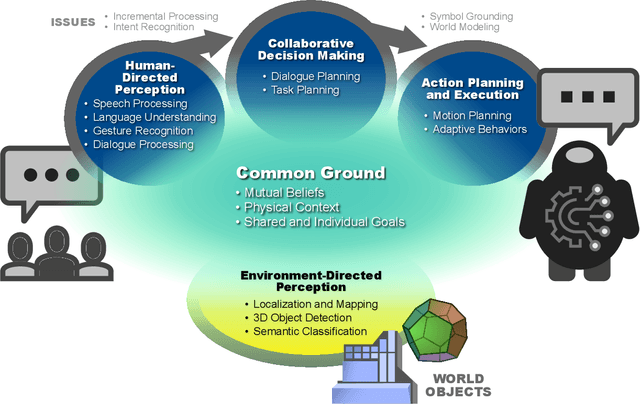
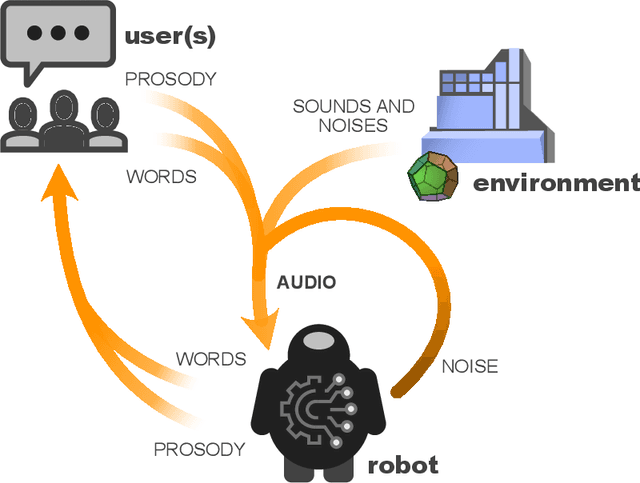
With robotics rapidly advancing, more effective human-robot interaction is increasingly needed to realize the full potential of robots for society. While spoken language must be part of the solution, our ability to provide spoken language interaction capabilities is still very limited. The National Science Foundation accordingly convened a workshop, bringing together speech, language, and robotics researchers to discuss what needs to be done. The result is this report, in which we identify key scientific and engineering advances needed. Our recommendations broadly relate to eight general themes. First, meeting human needs requires addressing new challenges in speech technology and user experience design. Second, this requires better models of the social and interactive aspects of language use. Third, for robustness, robots need higher-bandwidth communication with users and better handling of uncertainty, including simultaneous consideration of multiple hypotheses and goals. Fourth, more powerful adaptation methods are needed, to enable robots to communicate in new environments, for new tasks, and with diverse user populations, without extensive re-engineering or the collection of massive training data. Fifth, since robots are embodied, speech should function together with other communication modalities, such as gaze, gesture, posture, and motion. Sixth, since robots operate in complex environments, speech components need access to rich yet efficient representations of what the robot knows about objects, locations, noise sources, the user, and other humans. Seventh, since robots operate in real time, their speech and language processing components must also. Eighth, in addition to more research, we need more work on infrastructure and resources, including shareable software modules and internal interfaces, inexpensive hardware, baseline systems, and diverse corpora.
Adaptive and Momentum Methods on Manifolds Through Trivializations
Oct 09, 2020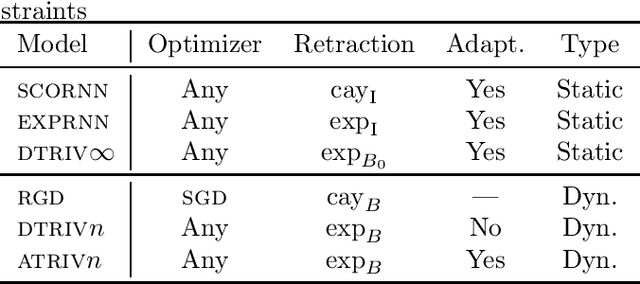
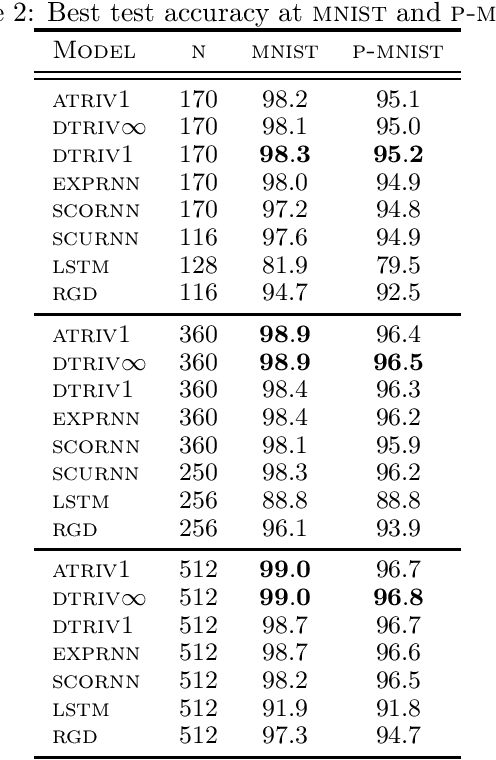
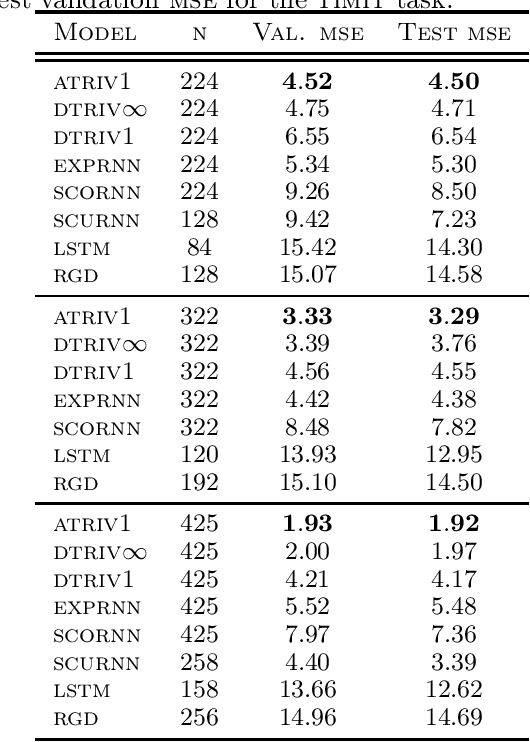

Adaptive methods do not have a direct generalization to manifolds as the adaptive term is not invariant. Momentum methods on manifolds suffer from efficiency problems stemming from the curvature of the manifold. We introduce a framework to generalize adaptive and momentum methods to arbitrary manifolds by noting that for every differentiable manifold, there exists a radially convex open set that covers almost all the manifold. Being radially convex, this set is diffeomorphic to $\mathbb{R}^n$. This gives a natural generalization of any adaptive and momentum-based algorithm to a set that covers almost all the manifold in an arbitrary manifolds. We also show how to extend these methods to the context of gradient descent methods with a retraction. For its implementation, we bring an approximation to the exponential of matrices that needs just of 5 matrix multiplications, making it particularly efficient on GPUs. In practice, we see that this family of algorithms closes the numerical gap created by an incorrect use of momentum and adaptive methods on manifolds. At the same time, we see that the most efficient algorithm of this family is given by simply pulling back the problem to the tangent space at the initial point via the exponential map.
EEG to fMRI Synthesis: Is Deep Learning a candidate?
Sep 29, 2020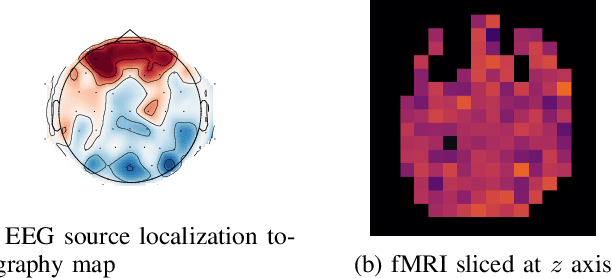
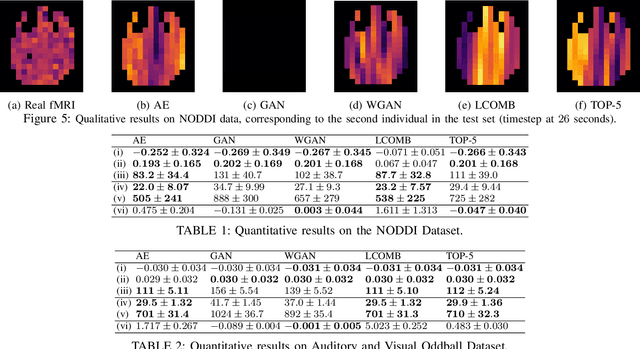
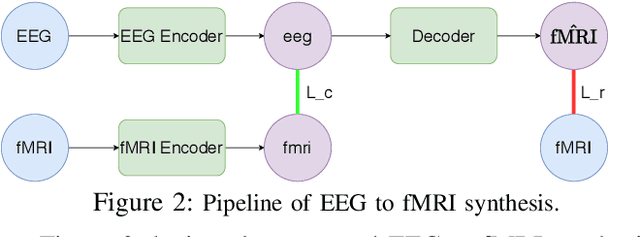
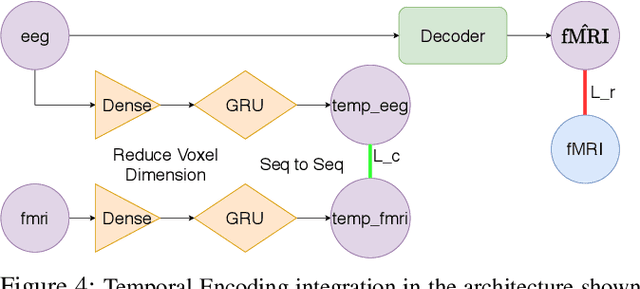
Advances on signal, image and video generation underly major breakthroughs on generative medical imaging tasks, including Brain Image Synthesis. Still, the extent to which functional Magnetic Ressonance Imaging (fMRI) can be mapped from the brain electrophysiology remains largely unexplored. This work provides the first comprehensive view on how to use state-of-the-art principles from Neural Processing to synthesize fMRI data from electroencephalographic (EEG) data. Given the distinct spatiotemporal nature of haemodynamic and electrophysiological signals, this problem is formulated as the task of learning a mapping function between multivariate time series with highly dissimilar structures. A comparison of state-of-the-art synthesis approaches, including Autoencoders, Generative Adversarial Networks and Pairwise Learning, is undertaken. Results highlight the feasibility of EEG to fMRI brain image mappings, pinpointing the role of current advances in Machine Learning and showing the relevance of upcoming contributions to further improve performance. EEG to fMRI synthesis offers a way to enhance and augment brain image data, and guarantee access to more affordable, portable and long-lasting protocols of brain activity monitoring. The code used in this manuscript is available in Github and the datasets are open source.
HAMLET -- A Learning Curve-Enabled Multi-Armed Bandit for Algorithm Selection
Jan 30, 2020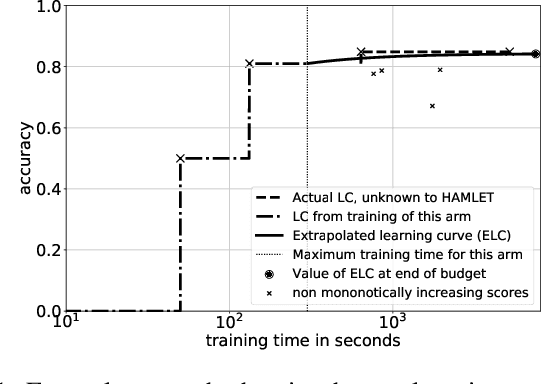
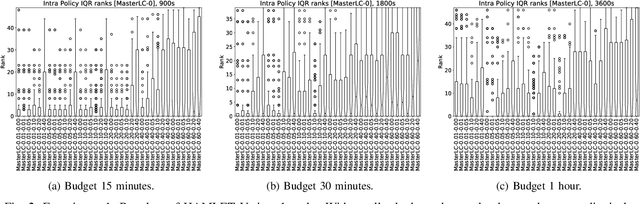
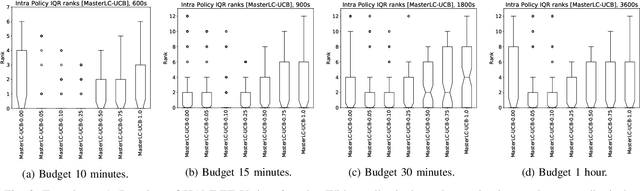
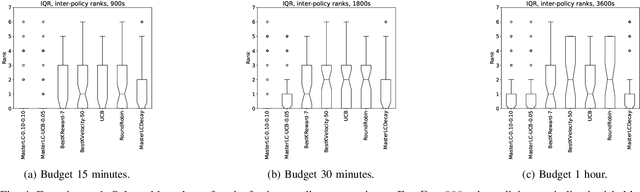
Automated algorithm selection and hyperparameter tuning facilitates the application of machine learning. Traditional multi-armed bandit strategies look to the history of observed rewards to identify the most promising arms for optimizing expected total reward in the long run. When considering limited time budgets and computational resources, this backward view of rewards is inappropriate as the bandit should look into the future for anticipating the highest final reward at the end of a specified time budget. This work addresses that insight by introducing HAMLET, which extends the bandit approach with learning curve extrapolation and computation time-awareness for selecting among a set of machine learning algorithms. Results show that the HAMLET Variants 1-3 exhibit equal or better performance than other bandit-based algorithm selection strategies in experiments with recorded hyperparameter tuning traces for the majority of considered time budgets. The best performing HAMLET Variant 3 combines learning curve extrapolation with the well-known upper confidence bound exploration bonus. That variant performs better than all non-HAMLET policies with statistical significance at the 95% level for 1,485 runs.
Continuous-time Intensity Estimation Using Event Cameras
Nov 01, 2018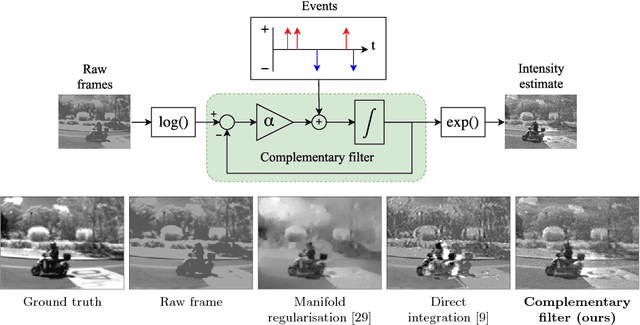



Event cameras provide asynchronous, data-driven measurements of local temporal contrast over a large dynamic range with extremely high temporal resolution. Conventional cameras capture low-frequency reference intensity information. These two sensor modalities provide complementary information. We propose a computationally efficient, asynchronous filter that continuously fuses image frames and events into a single high-temporal-resolution, high-dynamic-range image state. In absence of conventional image frames, the filter can be run on events only. We present experimental results on high-speed, high-dynamic-range sequences, as well as on new ground truth datasets we generate to demonstrate the proposed algorithm outperforms existing state-of-the-art methods.
Video Interpolation via Generalized Deformable Convolution
Aug 24, 2020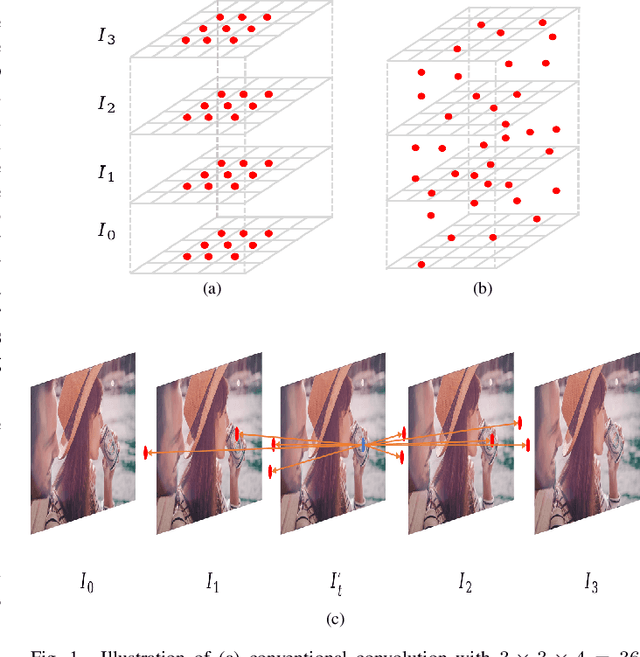
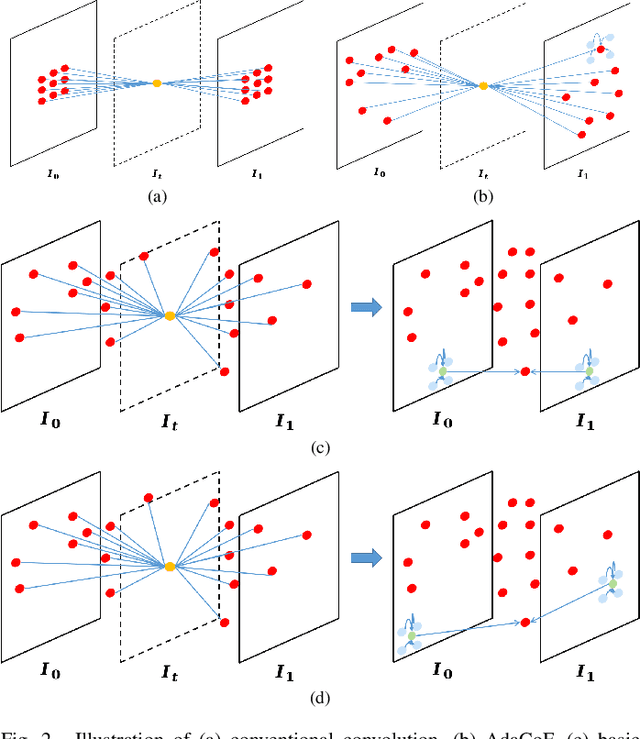
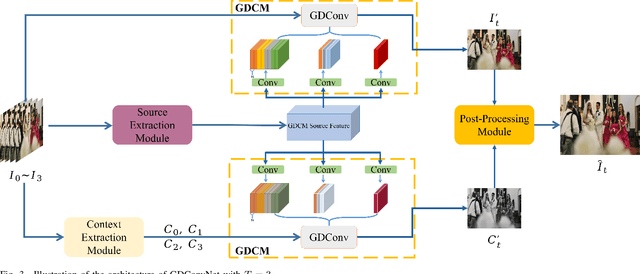
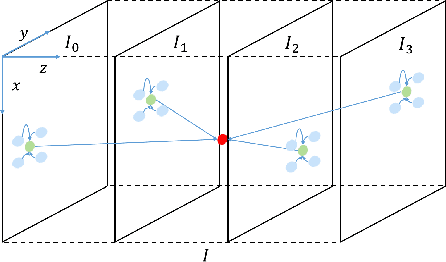
Video interpolation aims at increasing the frame rate of a given video by synthesizing intermediate frames. The existing video interpolation methods can be roughly divided into two categories: flow-based methods and kernel-based methods. The performance of flow-based methods is often jeopardized by the inaccuracy of flow map estimation due to oversimplified motion models while that of kernel-based methods tends to be constrained by the rigidity of kernel shape. To address these performance-limiting issues, a novel mechanism named generalized deformable convolution is proposed, which can effectively learn motion information in a data-driven manner and freely select sampling points in space-time. We further develop a new video interpolation method based on this mechanism. Our extensive experiments demonstrate that the new method performs favorably against the state-of-the-art, especially when dealing with complex motions.
The bi-objective multimodal car-sharing problem
Oct 18, 2020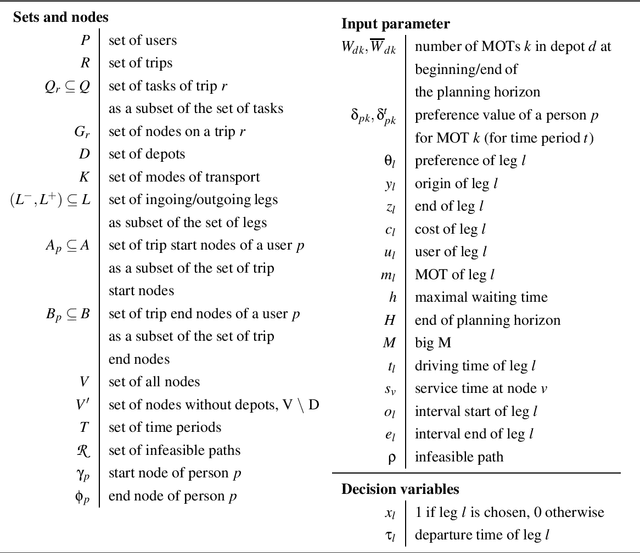
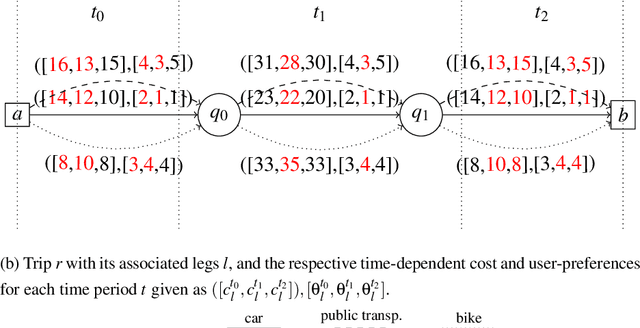
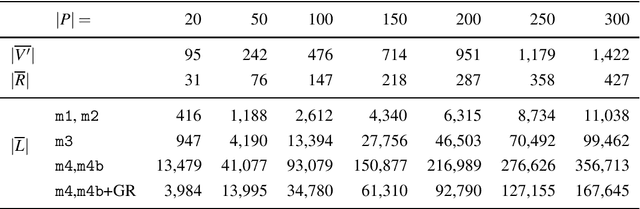
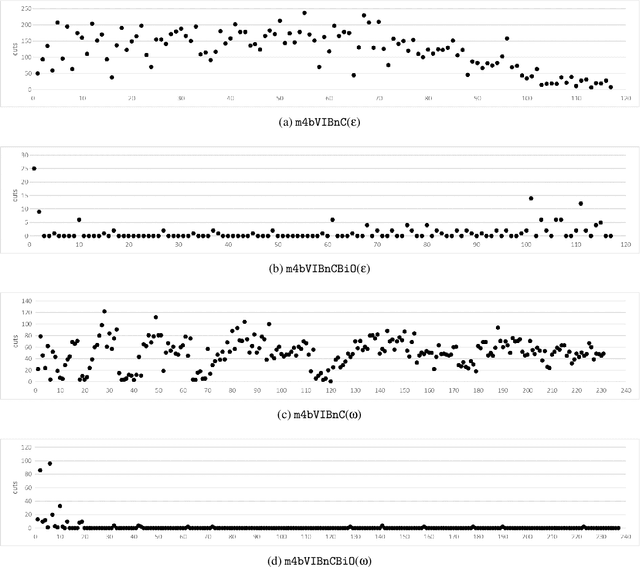
The aim of the bi-objective multimodal car-sharing problem (BiO-MMCP) is to determine the optimal mode of transport assignment for trips and to schedule the routes of available cars and users whilst minimizing cost and maximizing user satisfaction. We investigate the BiO-MMCP from a user-centred point of view. As user satisfaction is a crucial aspect in shared mobility systems, we consider user preferences in a second objective. Users may choose and rank their preferred modes of transport for different times of the day. In this way we account for, e.g., different traffic conditions throughout the planning horizon. We study different variants of the problem. In the base problem, the sequence of tasks a user has to fulfill is fixed in advance and travel times as well as preferences are constant over the planning horizon. In variant 2, time-dependent travel times and preferences are introduced. In variant 3, we examine the challenges when allowing additional routing decisions. Variant 4 integrates variants 2 and 3. For this last variant, we develop a branch-and-cut algorithm which is embedded in two bi-objective frameworks, namely the $\epsilon$-constraint method and a weighting binary search method. Computational experiments show that the branch-and cut algorithm outperforms the MIP formulation and we discuss changing solutions along the Pareto frontier.