 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListen Attentively, and Spell Once: Whole Sentence Generation via a Non-Autoregressive Architecture for Low-Latency Speech Recognition
Paper and Code
May 30, 2020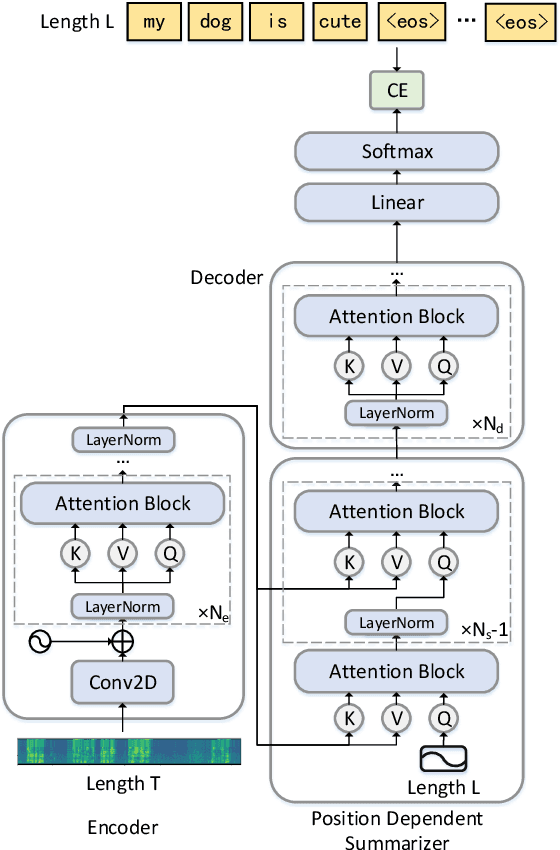
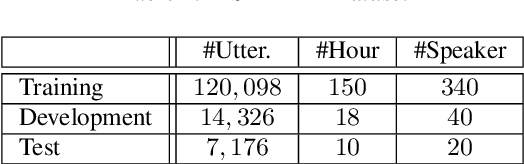
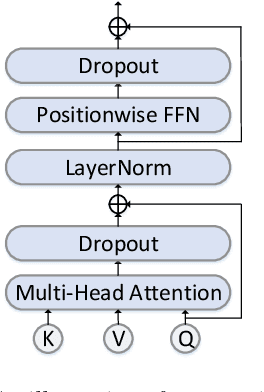
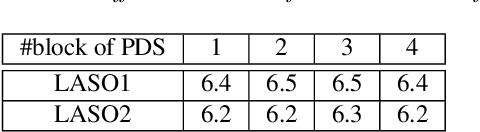
Although attention based end-to-end models have achieved promising performance in speech recognition, the multi-pass forward computation in beam-search increases inference time cost, which limits their practical applications. To address this issue, we propose a non-autoregressive end-to-end speech recognition system called LASO (listen attentively, and spell once). Because of the non-autoregressive property, LASO predicts a textual token in the sequence without the dependence on other tokens. Without beam-search, the one-pass propagation much reduces inference time cost of LASO. And because the model is based on the attention based feedforward structure, the computation can be implemented in parallel efficiently. We conduct experiments on publicly available Chinese dataset AISHELL-1. LASO achieves a character error rate of 6.4%, which outperforms the state-of-the-art autoregressive transformer model (6.7%). The average inference latency is 21 ms, which is 1/50 of the autoregressive transformer model.