 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Networks in Evolutionary Dynamic Constrained Optimization: Computational Cost and Benefits
Jan 22, 2020
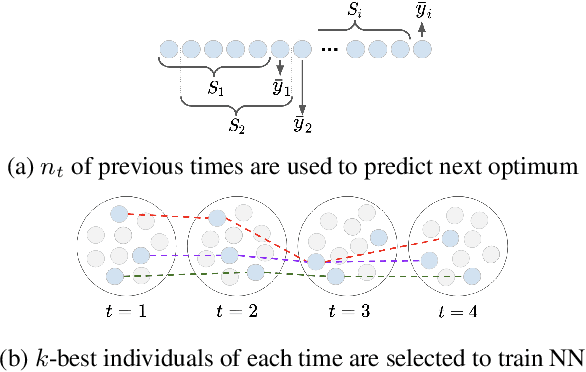

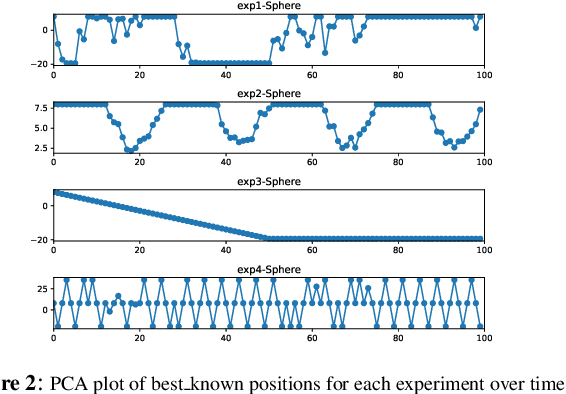
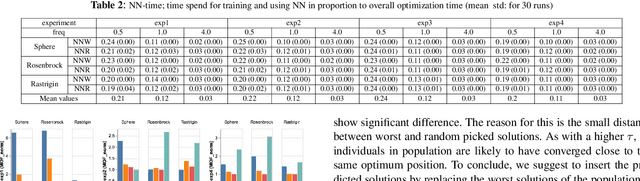
Neural networks (NN) have been recently applied together with evolutionary algorithms (EAs) to solve dynamic optimization problems. The applied NN estimates the position of the next optimum based on the previous time best solutions. After detecting a change, the predicted solution can be employed to move the EA's population to a promising region of the solution space in order to accelerate convergence and improve accuracy in tracking the optimum. While previous works show improvement of the results, they neglect the overhead created by NN. In this work, we reflect the time spent on training NN in the optimization time and compare the results with a baseline EA. We explore if by considering the generated overhead, NN is still able to improve the results, and under which condition is able to do so. The main difficulties to train the NN are: 1) to get enough samples to generalize predictions for new data, and 2) to obtain reliable samples. As NN needs to collect data at each time step, if the time horizon is short, we will not be able to collect enough samples to train the NN. To alleviate this, we propose to consider more individuals on each change to speed up sample collection in shorter time steps. In environments with a high frequency of changes, the solutions produced by EA are likely to be far from the real optimum. Using unreliable train data for the NN will, in consequence, produce unreliable predictions. Also, as the time spent for NN stays fixed regardless of the frequency, a higher frequency of change will mean a higher produced overhead by the NN in proportion to the EA. In general, after considering the generated overhead, we conclude that NN is not suitable in environments with a high frequency of changes and/or short time horizons. However, it can be promising for the low frequency of changes, and especially for the environments that changes have a pattern.
Non-Sparse PCA in High Dimensions via Cone Projected Power Iteration
May 15, 2020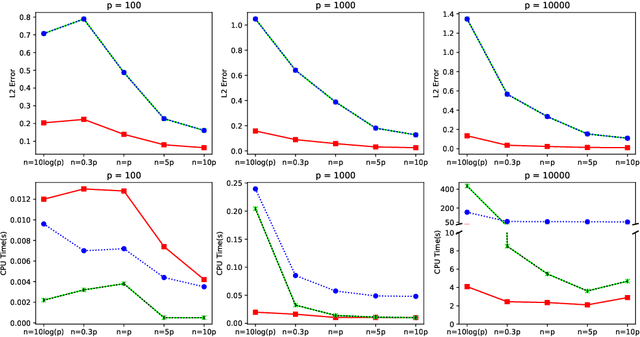
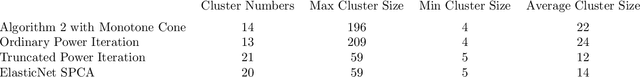
In this paper, we propose a cone projected power iteration algorithm to recover the principal eigenvector from a noisy positive semidefinite matrix. When the true principal eigenvector is assumed to belong to a convex cone, the proposed algorithm is fast and has a tractable error. Specifically, the method achieves polynomial time complexity for certain convex cones equipped with fast projection such as the monotone cone. It attains a small error when the noisy matrix has a small cone-restricted operator norm. We supplement the above results with a minimax lower bound of the error under the spiked covariance model. Our numerical experiments on simulated and real data, show that our method achieves shorter run time and smaller error in comparison to the ordinary power iteration and some sparse principal component analysis algorithms if the principal eigenvector is in a convex cone.
Multi-Slice Fusion for Sparse-View and Limited-Angle 4D CT Reconstruction
Aug 01, 2020

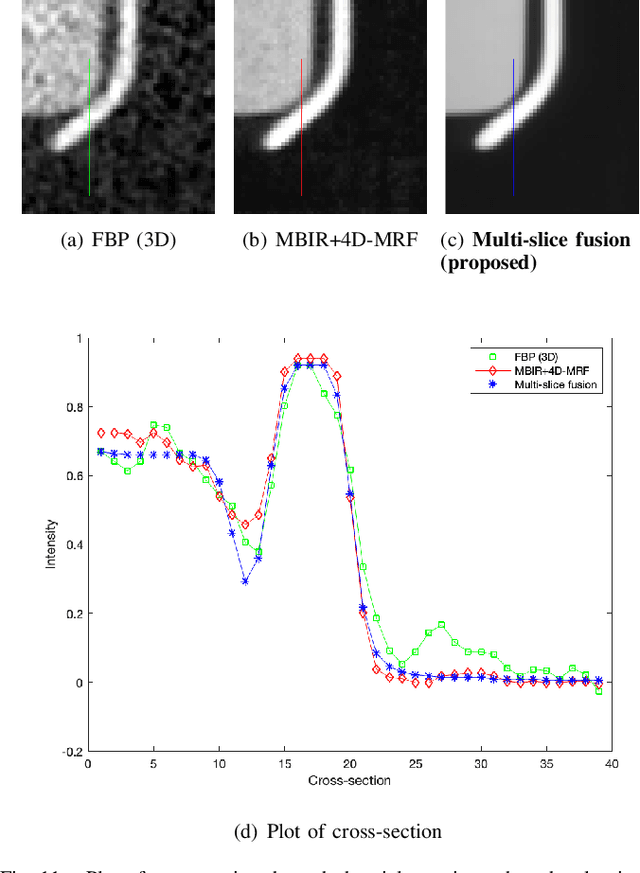
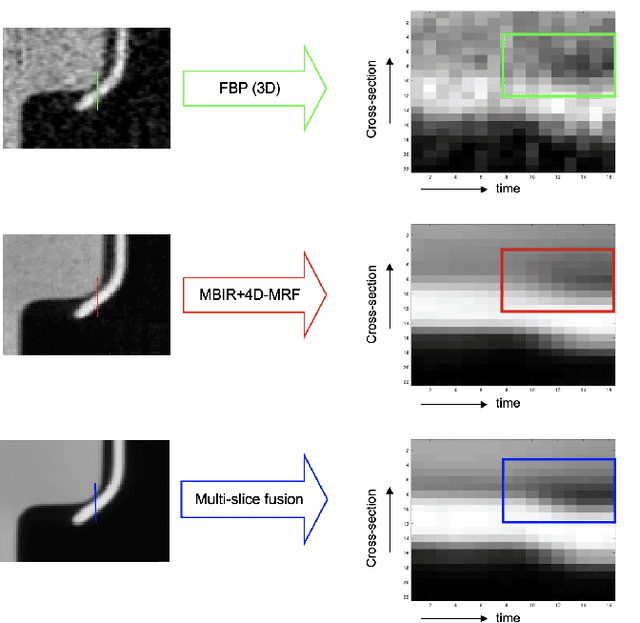
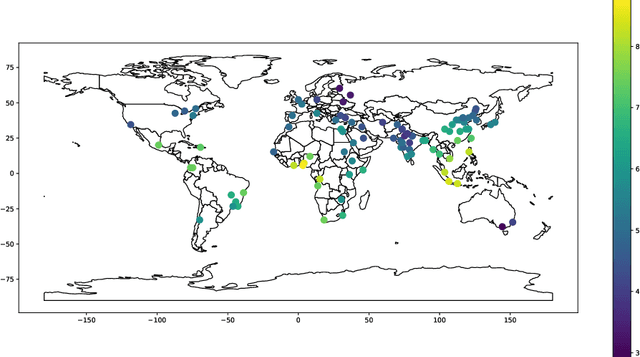
Inverse problems spanning four or more dimensions such as space, time and other independent parameters have become increasingly important. State-of-the-art 4D reconstruction methods use model based iterative reconstruction (MBIR), but depend critically on the quality of the prior modeling. Recently, plug-and-play (PnP) methods have been shown to be an effective way to incorporate advanced prior models using state-of-the-art denoising algorithms. However, state-of-the-art denoisers such as BM4D and deep convolutional neural networks (CNNs) are primarily available for 2D or 3D images and extending them to higher dimensions is difficult due to algorithmic complexity and the increased difficulty of effective training. In this paper, we present multi-slice fusion, a novel algorithm for 4D reconstruction, based on the fusion of multiple low-dimensional denoisers. Our approach uses multi-agent consensus equilibrium (MACE), an extension of plug-and-play, as a framework for integrating the multiple lower-dimensional models. We apply our method to 4D cone-beam X-ray CT reconstruction for non destructive evaluation (NDE) of samples that are dynamically moving during acquisition. We implement multi-slice fusion on distributed, heterogeneous clusters in order to reconstruct large 4D volumes in reasonable time and demonstrate the inherent parallelizable nature of the algorithm. We present simulated and real experimental results on sparse-view and limited-angle CT data to demonstrate that multi-slice fusion can substantially improve the quality of reconstructions relative to traditional methods, while also being practical to implement and train.
Estimates of daily ground-level NO2 concentrations in China based on big data and machine learning approaches
Nov 18, 2020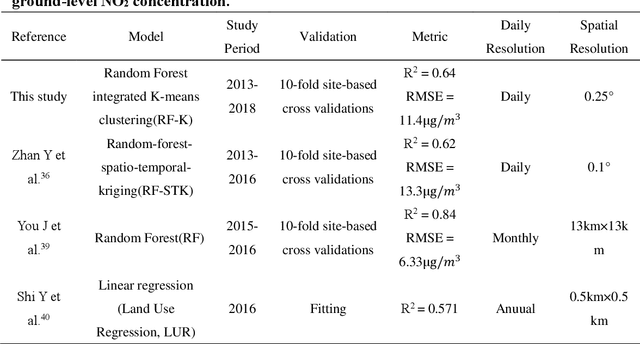
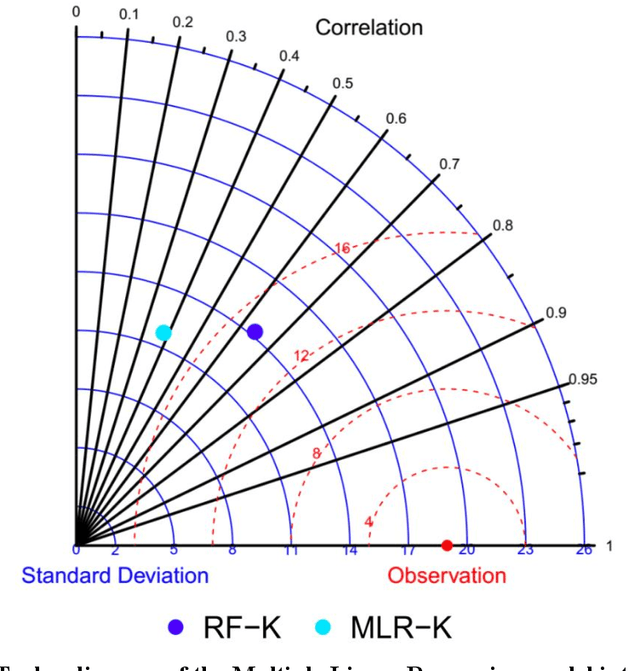
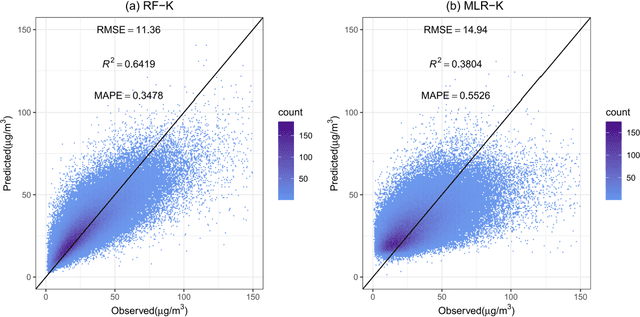
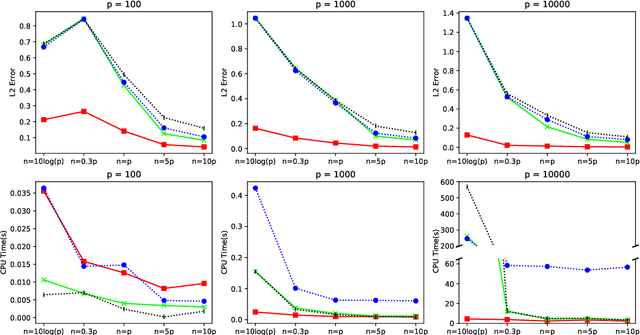
Nitrogen dioxide (NO2) is one of the most important atmospheric pollutants. However, current ground-level NO2 concentration data are lack of either high-resolution coverage or full coverage national wide, due to the poor quality of source data and the computing power of the models. To our knowledge, this study is the first to estimate the ground-level NO2 concentration in China with national coverage as well as relatively high spatiotemporal resolution (0.25 degree; daily intervals) over the newest past 6 years (2013-2018). We advanced a Random Forest model integrated K-means (RF-K) for the estimates with multi-source parameters. Besides meteorological parameters, satellite retrievals parameters, we also, for the first time, introduce socio-economic parameters to assess the impact by human activities. The results show that: (1) the RF-K model we developed shows better prediction performance than other models, with cross-validation R2 = 0.64 (MAPE = 34.78%). (2) The annual average concentration of NO2 in China showed a weak increasing trend . While in the economic zones such as Beijing-Tianjin-Hebei region, Yangtze River Delta, and Pearl River Delta, the NO2 concentration there even decreased or remained unchanged, especially in spring. Our dataset has verified that pollutant controlling targets have been achieved in these areas. With mapping daily nationwide ground-level NO2 concentrations, this study provides timely data with high quality for air quality management for China. We provide a universal model framework to quickly generate a timely national atmospheric pollutants concentration map with a high spatial-temporal resolution, based on improved machine learning methods.
Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding
Nov 10, 2020
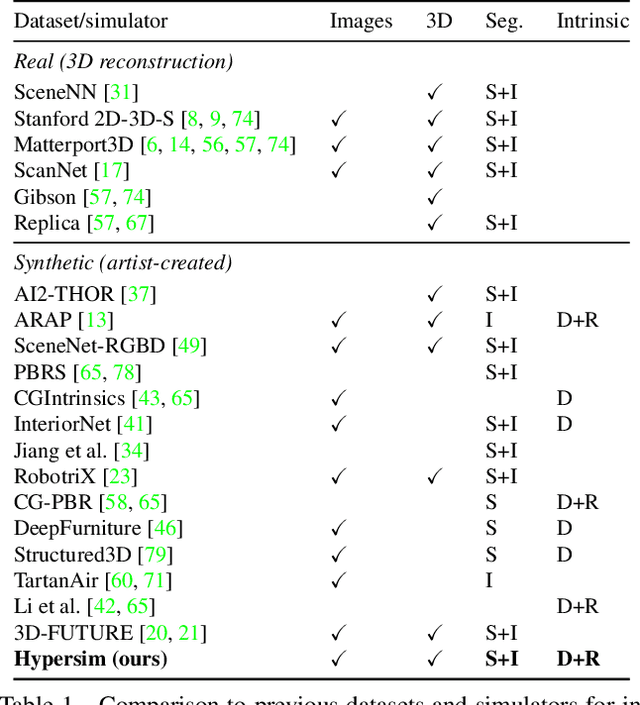
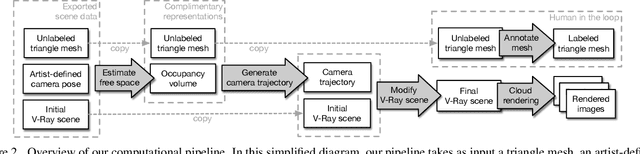

For many fundamental scene understanding tasks, it is difficult or impossible to obtain per-pixel ground truth labels from real images. We address this challenge by introducing Hypersim, a photorealistic synthetic dataset for holistic indoor scene understanding. To create our dataset, we leverage a large repository of synthetic scenes created by professional artists, and we generate 77,400 images of 461 indoor scenes with detailed per-pixel labels and corresponding ground truth geometry. Our dataset: (1) relies exclusively on publicly available 3D assets; (2) includes complete scene geometry, material information, and lighting information for every scene; (3) includes dense per-pixel semantic instance segmentations for every image; and (4) factors every image into diffuse reflectance, diffuse illumination, and a non-diffuse residual term that captures view-dependent lighting effects. Together, these features make our dataset well-suited for geometric learning problems that require direct 3D supervision, multi-task learning problems that require reasoning jointly over multiple input and output modalities, and inverse rendering problems. We analyze our dataset at the level of scenes, objects, and pixels, and we analyze costs in terms of money, annotation effort, and computation time. Remarkably, we find that it is possible to generate our entire dataset from scratch, for roughly half the cost of training a state-of-the-art natural language processing model. All the code we used to generate our dataset will be made available online.
Autocalibration of a Mobile UWB Localization System for Ad-Hoc Multi-Robot Deployments in GNSS-Denied Environments
Apr 14, 2020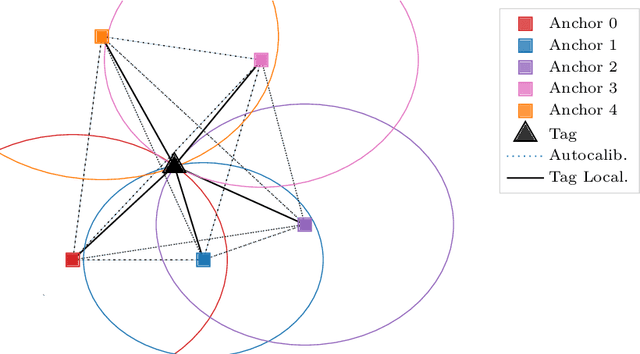



Ultra-wideband (UWB) wireless technology has seen an increased penetration in the robotics field as a robust localization method in recent years. UWB enables high accuracy distance estimation from time-of-flight measurements of wireless signals, even in non-line-of-sight measurements. UWB-based localization systems have been utilized in various types of GNSS-denied environments for ground or aerial autonomous robots. However, most of the existing solutions rely on a fixed and well-calibrated set of UWB nodes, or anchors, to estimate accurately the position of other mobile nodes, or tags, through multilateration. This limits the applicability of such systems for dynamic and ad-hoc deployments, such as post-disaster scenarios where the UWB anchors could be mounted on mobile robots to aid the navigation of UAVs or other robots. We introduce a collaborative algorithm for online autocalibration of anchor positions, enabling not only ad-hoc deployments but also movable anchors, based on Decawave's DWM1001 UWB module. Compared to the built-in autocalibration process from Decawave, we drastically reduce the amount of calibration time and increase the accuracy at the same time. We provide both experimental measurements and simulation results to demonstrate the usability of this algorithm.
Active Voice Authentication
Apr 25, 2020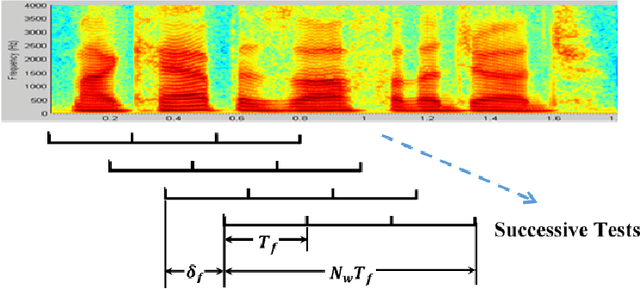
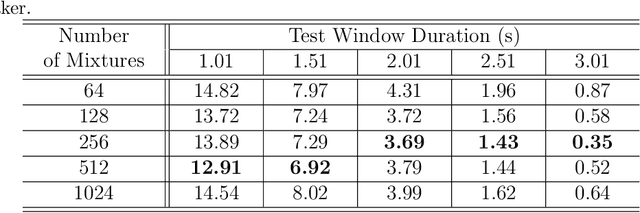
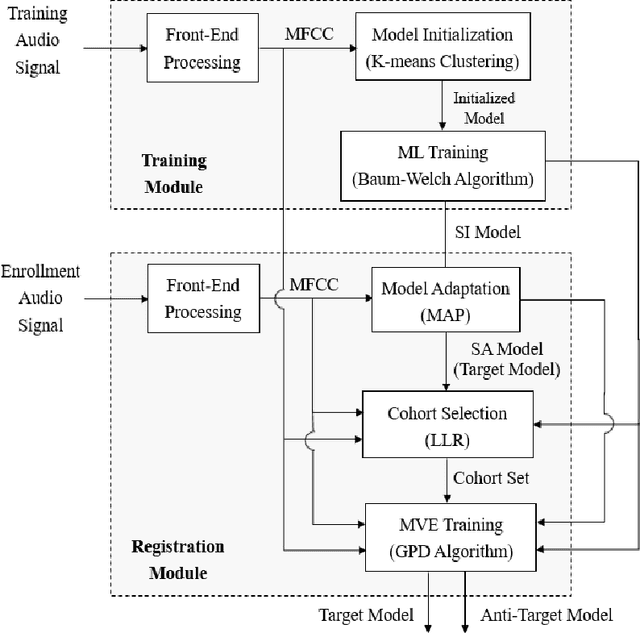
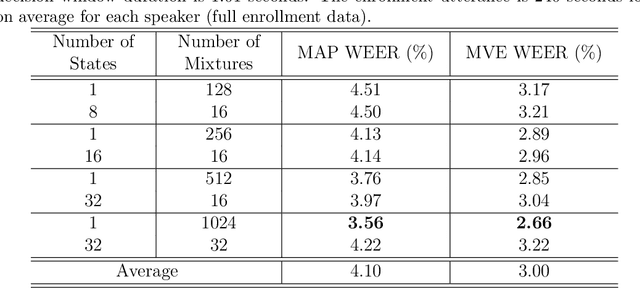
Active authentication refers to a new mode of identity verification in which biometric indicators are continuously tested to provide real-time or near real-time monitoring of an authorized access to a service or use of a device. This is in contrast to the conventional authentication systems where a single test in form of a verification token such as a password is performed. In active voice authentication (AVA), voice is the biometric modality. This paper describes an ensemble of techniques that make reliable speaker verification possible using unconventionally short voice test signals. These techniques include model adaptation and minimum verification error (MVE) training that are tailored for the extremely short training and testing requirements. A database of 25 speakers is recorded for developing this system. In our off-line evaluation on this dataset, the system achieves an average windowed-based equal error rates of 3-4% depending on the model configuration, which is remarkable considering that only 1 second of voice data is used to make every single authentication decision. On the NIST SRE 2001 Dataset, the system provides a 3.88% absolute gain over i-vector when the duration of test segment is 1 second. A real-time demonstration system has been implemented on Microsoft Surface Pro.
* 39 pages, 4 figures
Fast and Accurate Forecasting of COVID-19 Deaths Using the SIkJ$α$ Model
Jul 13, 2020
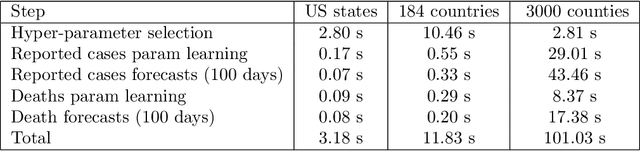
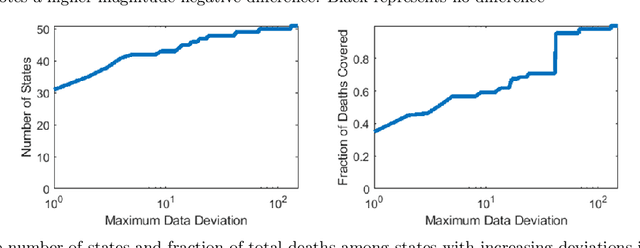
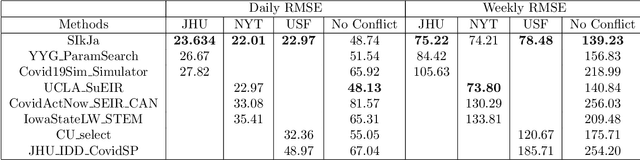
Forecasting the effect of COVID-19 is essential to design policies that may prepare us to handle the pandemic. Many methods have already been proposed, particularly, to forecast reported cases and deaths at country-level and state-level. Many of these methods are based on traditional epidemiological model which rely on simulations or Bayesian inference to simultaneously learn many parameters at a time. This makes them prone to over-fitting and slow execution. We propose an extension to our model SIkJ$\alpha$ to forecast deaths and show that it can consider the effect of many complexities of the epidemic process and yet be simplified to a few parameters that are learned using fast linear regressions. We also present an evaluation of our method against seven approaches currently being used by the CDC, based on their two weeks forecast at various times during the pandemic. We demonstrate that our method achieves better root mean squared error compared to these seven approaches during majority of the evaluation period. Further, on a 2 core desktop machine, our approach takes only 3.18s to tune hyper-parameters, learn parameters and generate 100 days of forecasts of reported cases and deaths for all the states in the US. The total execution time for 184 countries is 11.83s and for all the US counties ($>$ 3000) is 101.03s.
On Generation of Time-based Label Refinements
Sep 12, 2016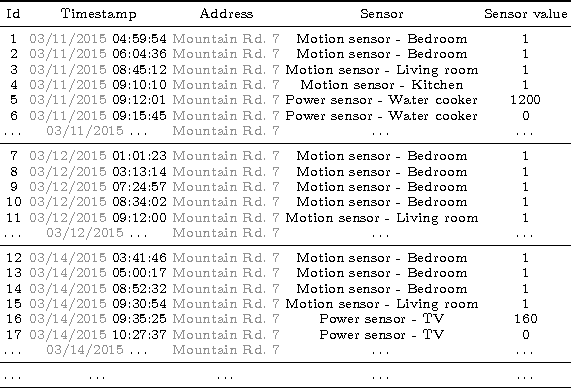
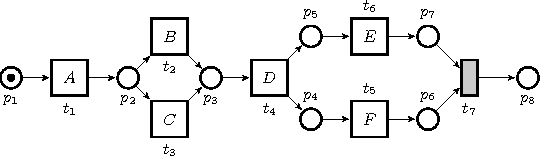
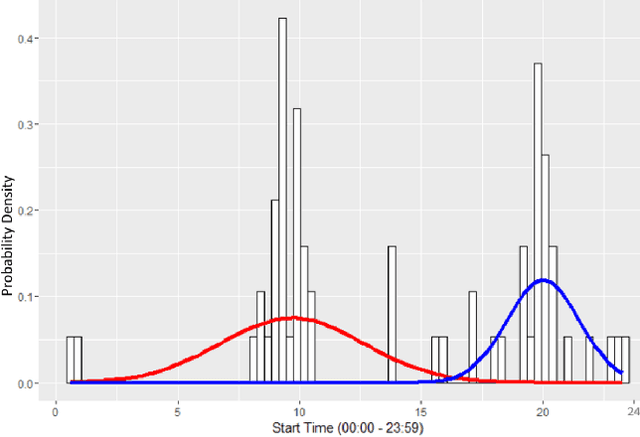
Process mining is a research field focused on the analysis of event data with the aim of extracting insights in processes. Applying process mining techniques on data from smart home environments has the potential to provide valuable insights in (un)healthy habits and to contribute to ambient assisted living solutions. Finding the right event labels to enable application of process mining techniques is however far from trivial, as simply using the triggering sensor as the label for sensor events results in uninformative models that allow for too much behavior (overgeneralizing). Refinements of sensor level event labels suggested by domain experts have shown to enable discovery of more precise and insightful process models. However, there exist no automated approach to generate refinements of event labels in the context of process mining. In this paper we propose a framework for automated generation of label refinements based on the time attribute of events. We show on a case study with real life smart home event data that behaviorally more specific, and therefore more insightful, process models can be found by using automatically generated refined labels in process discovery.
DNA mixture deconvolution using an evolutionary algorithm with multiple populations, hill-climbing, and guided mutation
Dec 01, 2020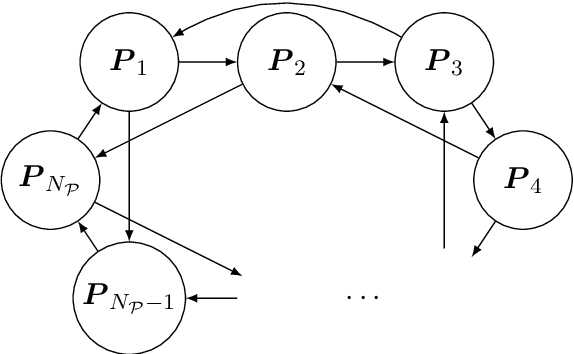
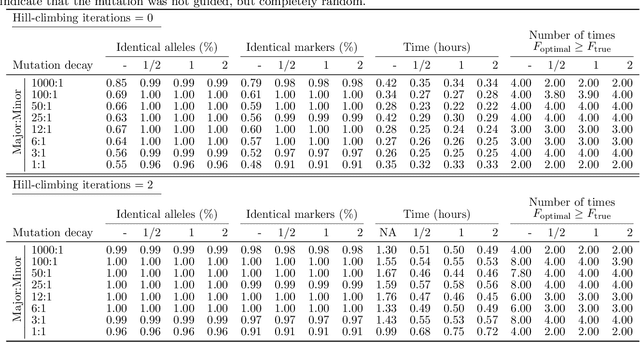
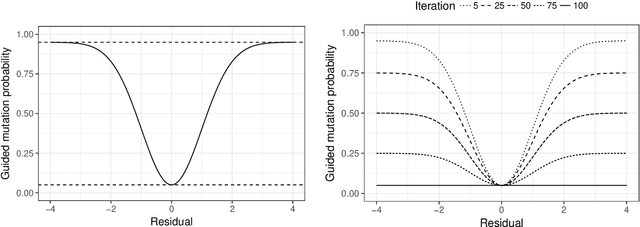
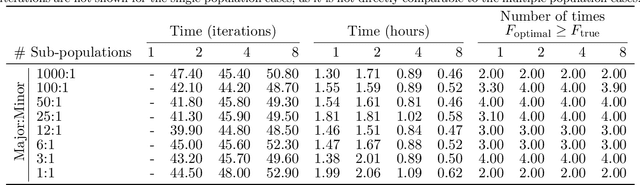
DNA samples crime cases analysed in forensic genetics, frequently contain DNA from multiple contributors. These occur as convolutions of the DNA profiles of the individual contributors to the DNA sample. Thus, in cases where one or more of the contributors were unknown, an objective of interest would be the separation, often called deconvolution, of these unknown profiles. In order to obtain deconvolutions of the unknown DNA profiles, we introduced a multiple population evolutionary algorithm (MEA). We allowed the mutation operator of the MEA to utilise that the fitness is based on a probabilistic model and guide it by using the deviations between the observed and the expected value for every element of the encoded individual. This guided mutation operator (GM) was designed such that the larger the deviation the higher probability of mutation. Furthermore, the GM was inhomogeneous in time, decreasing to a specified lower bound as the number of iterations increased. We analysed 102 two-person DNA mixture samples in varying mixture proportions. The samples were quantified using two different DNA prep. kits: (1) Illumina ForenSeq Panel B (30 samples), and (2) Applied Biosystems Precision ID Globalfiler NGS STR panel (72 samples). The DNA mixtures were deconvoluted by the MEA and compared to the true DNA profiles of the sample. We analysed three scenarios where we assumed: (1) the DNA profile of the major contributor was unknown, (2) DNA profile of the minor was unknown, and (3) both DNA profiles were unknown. Furthermore, we conducted a series of sensitivity experiments on the ForenSeq panel by varying the sub-population size, comparing a completely random homogeneous mutation operator to the guided operator with varying mutation decay rates, and allowing for hill-climbing of the parent population.