 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Exploration for Model-based Reinforcement Learning with Continuous States and Actions
Nov 20, 2020
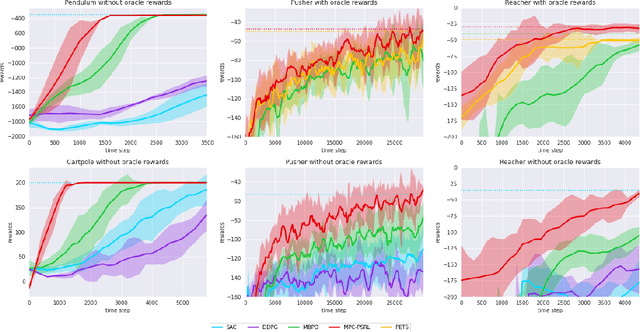
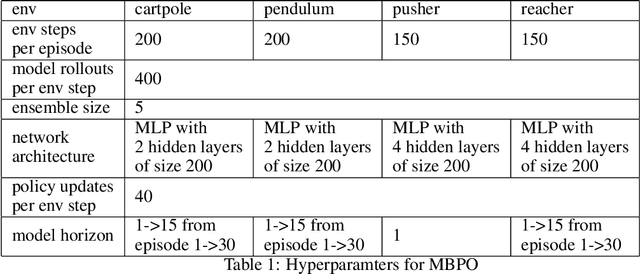
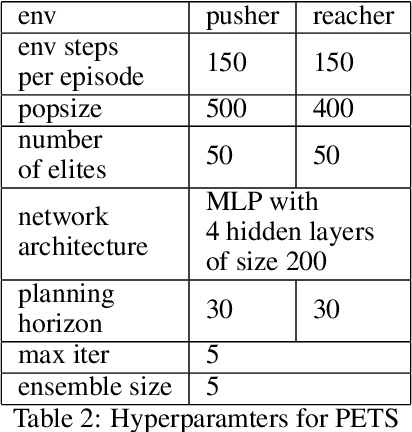
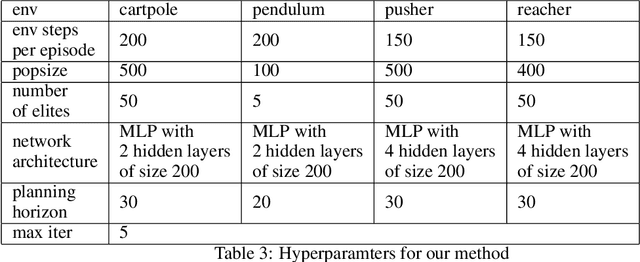
Balancing exploration and exploitation is crucial in reinforcement learning (RL). In this paper, we study the model-based posterior sampling algorithm in continuous state-action spaces theoretically and empirically. First, we improve the regret bound: with the assumption that reward and transition functions can be modeled as Gaussian Processes with linear kernels, we develop a Bayesian regret bound of $\tilde{O}(H^{3/2}d\sqrt{T})$, where $H$ is the episode length, $d$ is the dimension of the state-action space, and $T$ indicates the total time steps. Our bound can be extended to nonlinear cases as well: using linear kernels on the feature representation $\phi$, the Bayesian regret bound becomes $\tilde{O}(H^{3/2}d_{\phi}\sqrt{T})$, where $d_\phi$ is the dimension of the representation space. Moreover, we present MPC-PSRL, a model-based posterior sampling algorithm with model predictive control for action selection. To capture the uncertainty in models and realize posterior sampling, we use Bayesian linear regression on the penultimate layer (the feature representation layer $\phi$) of neural networks. Empirical results show that our algorithm achieves the best sample efficiency in benchmark control tasks compared to prior model-based algorithms, and matches the asymptotic performance of model-free algorithms.
Interference Distribution Prediction for Link Adaptation in Ultra-Reliable Low-Latency Communications
Jul 01, 2020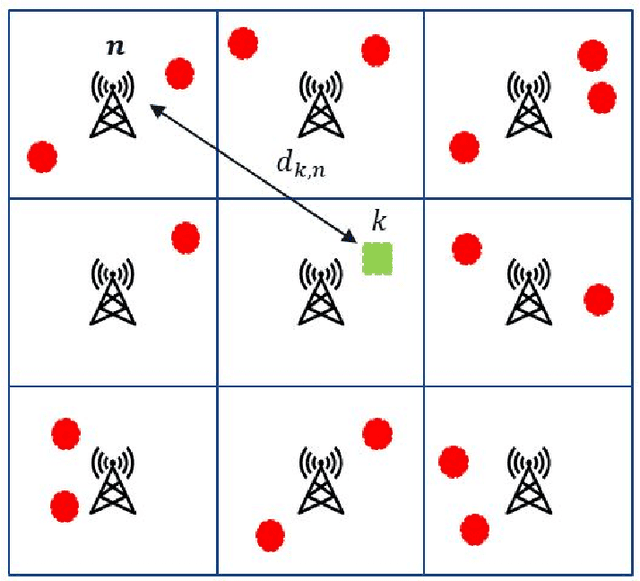
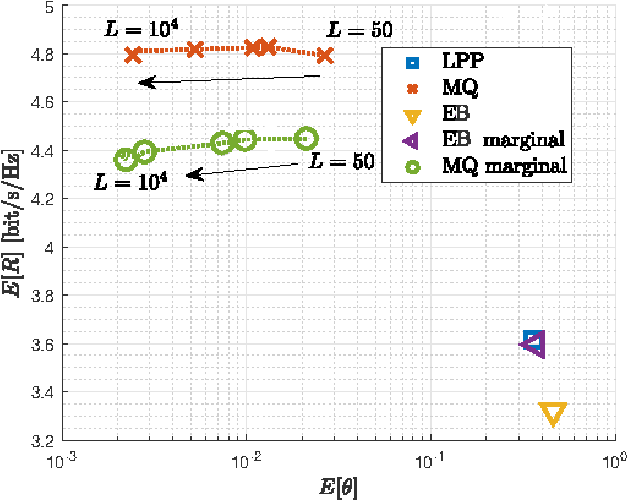
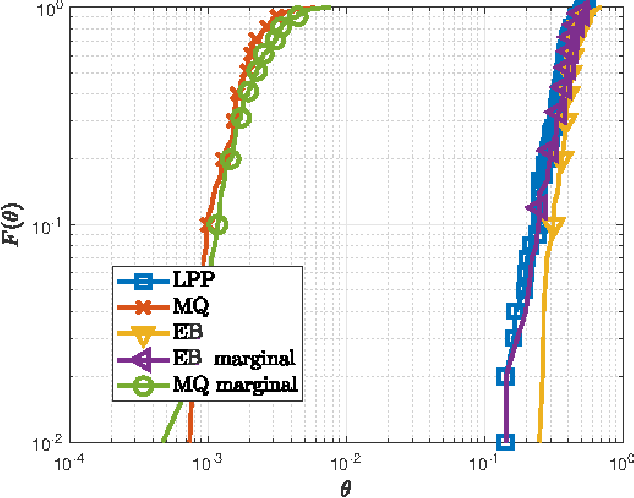
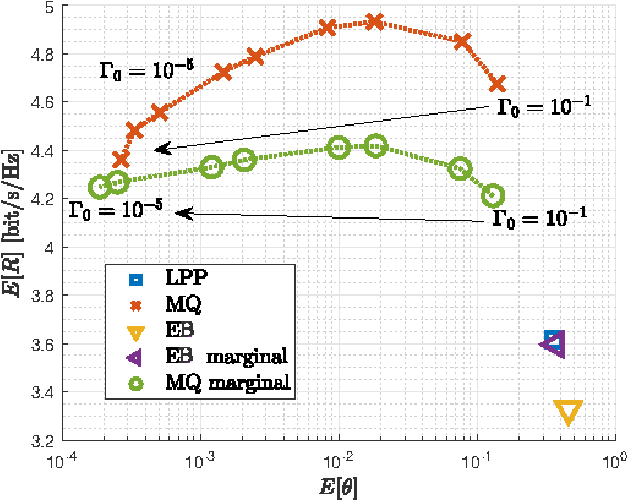
The strict latency and reliability requirements of ultra-reliable low-latency communications (URLLC) use cases are among the main drivers in fifth generation (5G) network design. Link adaptation (LA) is considered to be one of the bottlenecks to realize URLLC. In this paper, we focus on predicting the signal to interference plus noise ratio at the user to enhance the LA. Motivated by the fact that most of the URLLC use cases with most extreme latency and reliability requirements are characterized by semi-deterministic traffic, we propose to exploit the time correlation of the interference to compute useful statistics needed to predict the interference power in the next transmission. This prediction is exploited in the LA context to maximize the spectral efficiency while guaranteeing reliability at an arbitrary level. Numerical results are compared with state of the art interference prediction techniques for LA. We show that exploiting time correlation of the interference is an important enabler of URLLC.
Parameter Norm Growth During Training of Transformers
Nov 11, 2020
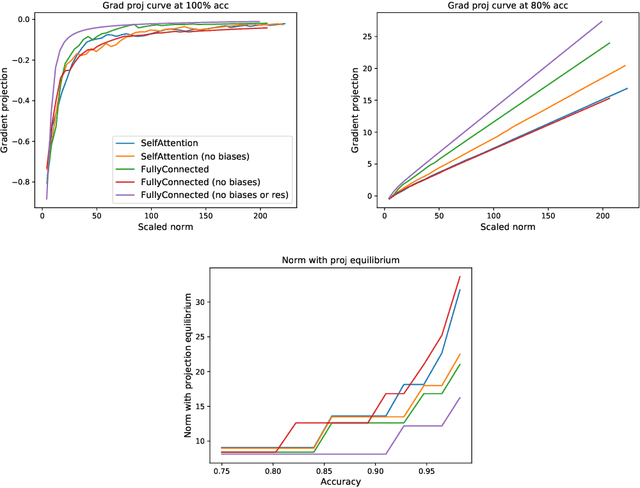
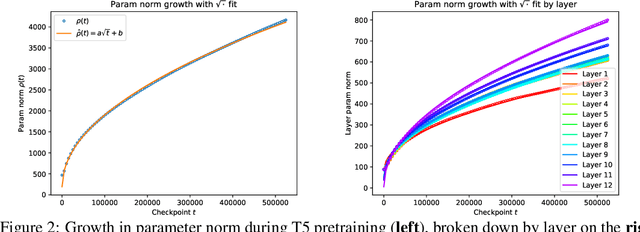
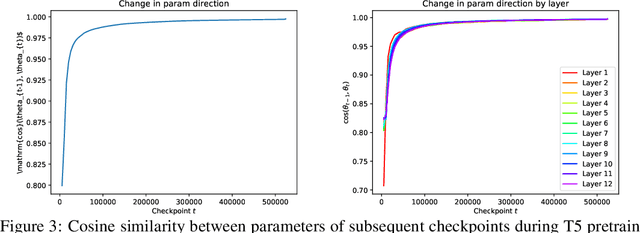
The capacity of neural networks like the widely adopted transformer is known to be very high. Evidence is emerging that they learn successfully due to inductive bias in the training routine, typically some variant of gradient descent (GD). To better understand this bias, we study the tendency of transformer parameters to grow in magnitude during training. We find, both theoretically and empirically, that, in certain contexts, GD increases the parameter $L_2$ norm up to a threshold that itself increases with training-set accuracy. This means increasing training accuracy over time enables the norm to increase. Empirically, we show that the norm grows continuously over pretraining for T5 (Raffel et al., 2019). We show that pretrained T5 approximates a semi-discretized network with saturated activation functions. Such "saturated" networks are known to have a reduced capacity compared to the original network family that can be described in automata-theoretic terms. This suggests saturation is a new characterization of an inductive bias implicit in GD that is of particular interest for NLP. While our experiments focus on transformers, our theoretical analysis extends to other architectures with similar formal properties, such as feedforward ReLU networks.
Sample-efficient Reinforcement Learning in Robotic Table Tennis
Nov 11, 2020
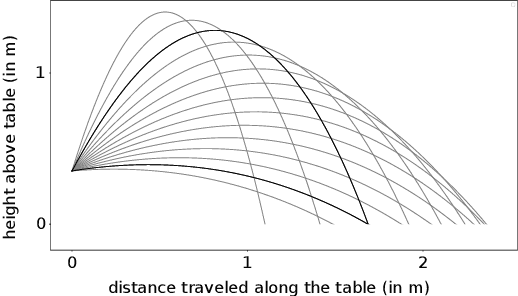
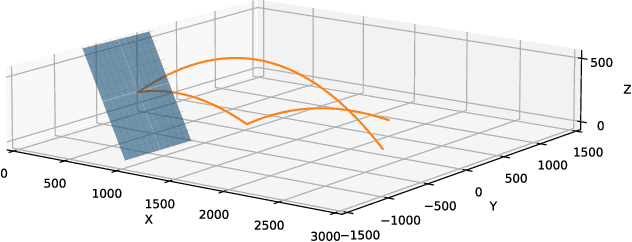
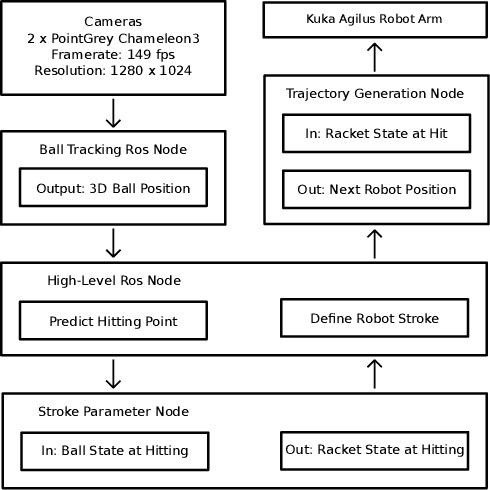
Reinforcement learning (RL) has recently shown impressive success in various computer games and simulations. Most of these successes are based on numerous episodes to be learned from. For typical robotic applications, however, the number of feasible attempts is very limited. In this paper we present a sample-efficient RL algorithm applied to the example of a table tennis robot. In table tennis every stroke is different, of varying placement, speed and spin. Therefore, an accurate return has be found depending on a high-dimensional continuous state space. To make learning in few trials possible the method is embedded into our robot system. In this way we can use a one-step environment. The state space depends on the ball at hitting time (position, velocity, spin) and the action is the racket state (orientation, velocity) at hitting. An actor-critic based deterministic policy gradient algorithm was developed for accelerated learning. Our approach shows competitive performance in both simulation and on the real robot in different challenging scenarios. Accurate results are always obtained within under 200 episodes of training. The video presenting our experiments is available at https://youtu.be/uRAtdoL6Wpw.
Distill2Vec: Dynamic Graph Representation Learning with Knowledge Distillation
Nov 11, 2020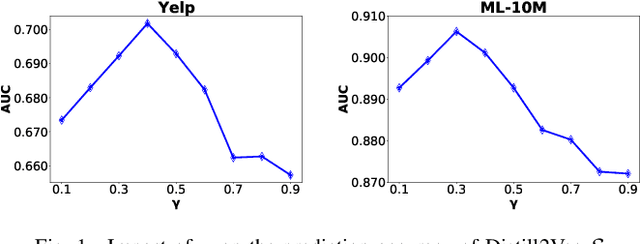
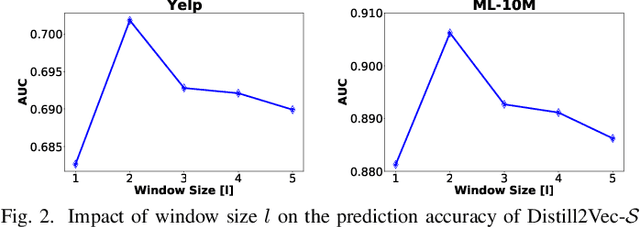
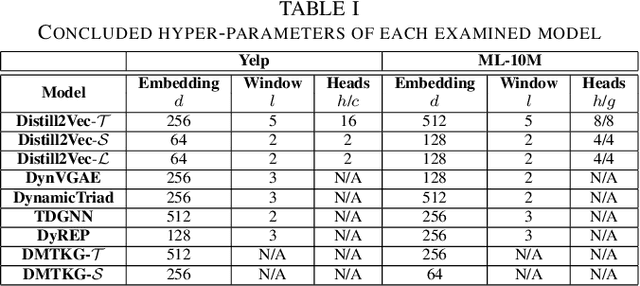
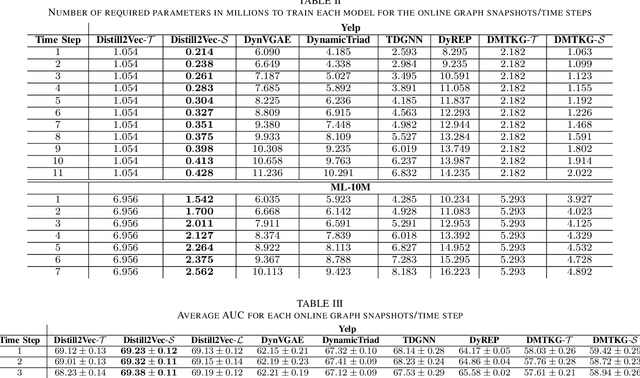
Dynamic graph representation learning strategies are based on different neural architectures to capture the graph evolution over time. However, the underlying neural architectures require a large amount of parameters to train and suffer from high online inference latency, that is several model parameters have to be updated when new data arrive online. In this study we propose Distill2Vec, a knowledge distillation strategy to train a compact model with a low number of trainable parameters, so as to reduce the latency of online inference and maintain the model accuracy high. We design a distillation loss function based on Kullback-Leibler divergence to transfer the acquired knowledge from a teacher model trained on offline data, to a small-size student model for online data. Our experiments with publicly available datasets show the superiority of our proposed model over several state-of-the-art approaches with relative gains up to 5% in the link prediction task. In addition, we demonstrate the effectiveness of our knowledge distillation strategy, in terms of number of required parameters, where Distill2Vec achieves a compression ratio up to 7:100 when compared with baseline approaches. For reproduction purposes, our implementation is publicly available at https://stefanosantaris.github.io/Distill2Vec.
LMB Filter Based Tracking Allowing for Multiple Hypotheses in Object Reference Point Association*
Nov 11, 2020
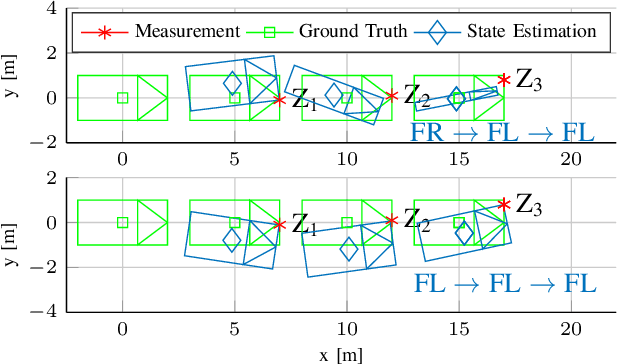
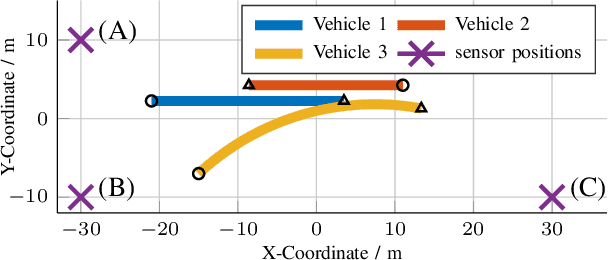
Autonomous vehicles need precise knowledge on dynamic objects in their surroundings. Especially in urban areas with many objects and possible occlusions, an infrastructure system based on a multi-sensor setup can provide the required environment model for the vehicles. Previously, we have published a concept of object reference points (e.g. the corners of an object), which allows for generic sensor "plug and play" interfaces and relatively cheap sensors. This paper describes a novel method to additionally incorporate multiple hypotheses for fusing the measurements of the object reference points using an extension to the previously presented Labeled Multi-Bernoulli (LMB) filter. In contrast to the previous work, this approach improves the tracking quality in the cases where the correct association of the measurement and the object reference point is unknown. Furthermore, this paper identifies options based on physical models to sort out inconsistent and unfeasible associations at an early stage in order to keep the method computationally tractable for real-time applications. The method is evaluated on simulations as well as on real scenarios. In comparison to comparable methods, the proposed approach shows a considerable performance increase, especially the number of non-continuous tracks is decreased significantly.
Efficient Neural Architecture Search for End-to-end Speech Recognition via Straight-Through Gradients
Nov 11, 2020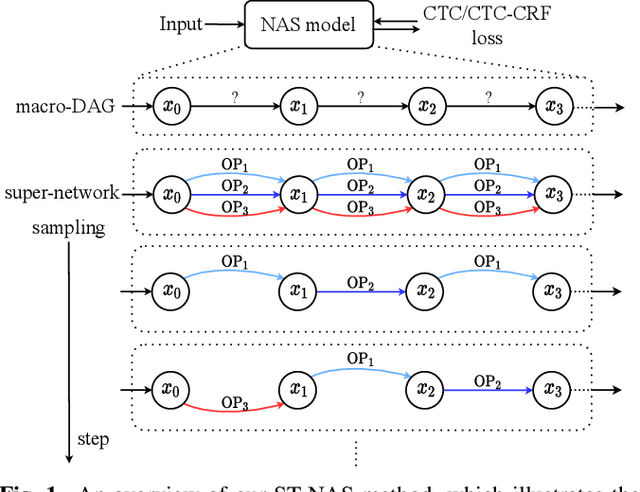
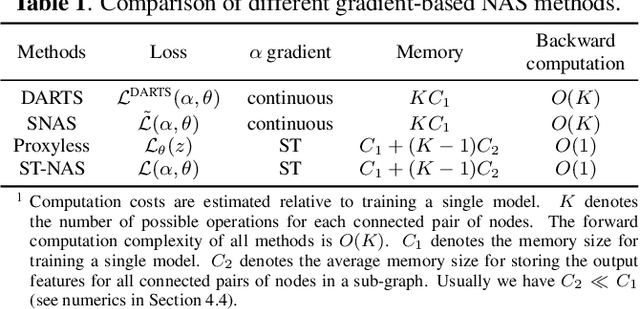
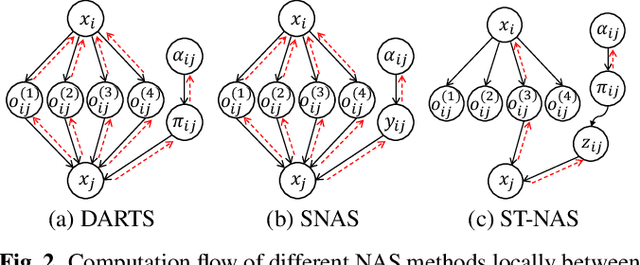
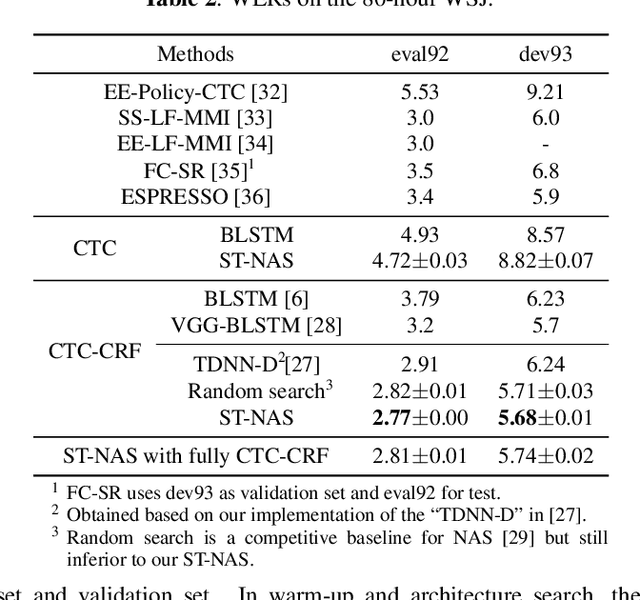
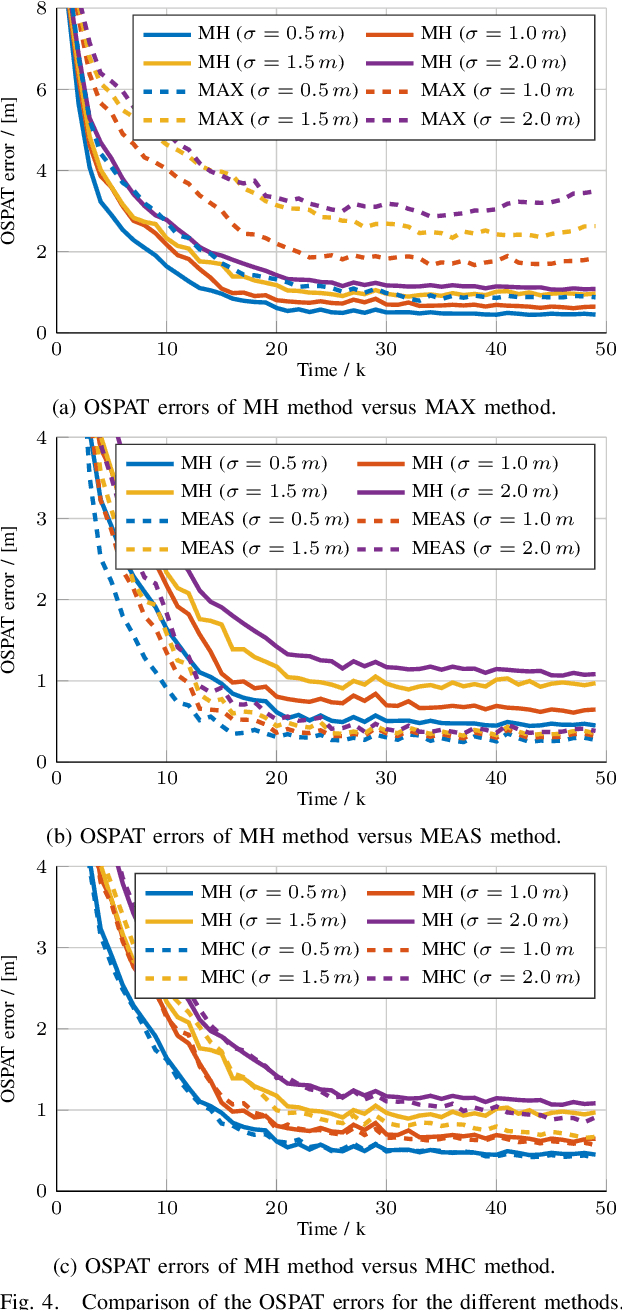
Neural Architecture Search (NAS), the process of automating architecture engineering, is an appealing next step to advancing end-to-end Automatic Speech Recognition (ASR), replacing expert-designed networks with learned, task-specific architectures. In contrast to early computational-demanding NAS methods, recent gradient-based NAS methods, e.g., DARTS (Differentiable ARchiTecture Search), SNAS (Stochastic NAS) and ProxylessNAS, significantly improve the NAS efficiency. In this paper, we make two contributions. First, we rigorously develop an efficient NAS method via Straight-Through (ST) gradients, called ST-NAS. Basically, ST-NAS uses the loss from SNAS but uses ST to back-propagate gradients through discrete variables to optimize the loss, which is not revealed in ProxylessNAS. Using ST gradients to support sub-graph sampling is a core element to achieve efficient NAS beyond DARTS and SNAS. Second, we successfully apply ST-NAS to end-to-end ASR. Experiments over the widely benchmarked 80-hour WSJ and 300-hour Switchboard datasets show that the ST-NAS induced architectures significantly outperform the human-designed architecture across the two datasets. Strengths of ST-NAS such as architecture transferability and low computation cost in memory and time are also reported.
Bayesian Learning for Deep Neural Network Adaptation
Dec 14, 2020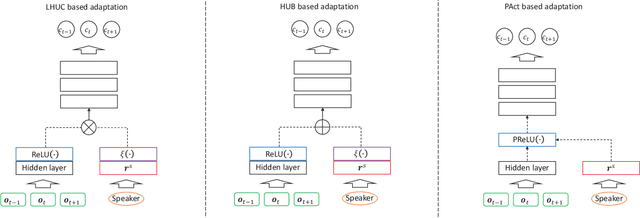
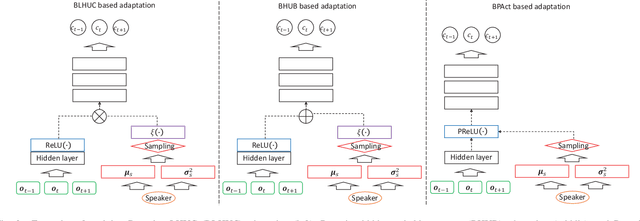
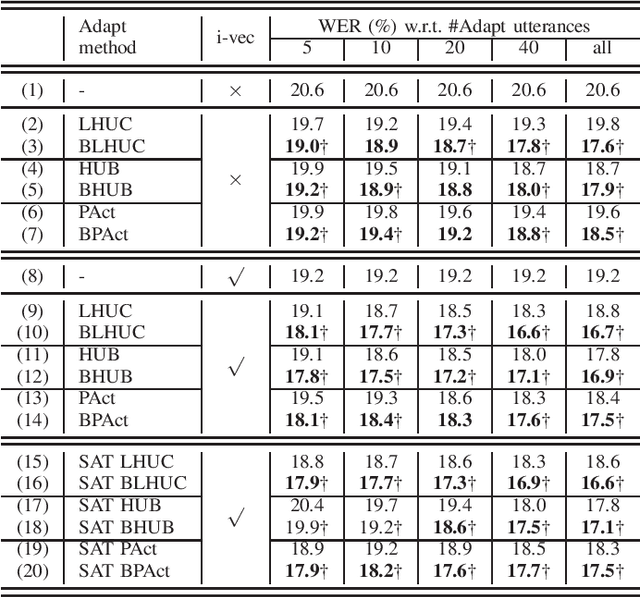

A key task for speech recognition systems is to reduce the mismatch between the training and evaluation data that is often attributable to speaker differences. To this end, speaker adaptation techniques play a vital role to reduce the mismatch. Model-based speaker adaptation approaches often require sufficient amounts of target speaker data to ensure robustness. When the amount of speaker level data is limited, speaker adaptation is prone to overfitting and poor generalization. To address the issue, this paper proposes a full Bayesian learning based DNN speaker adaptation framework to model speaker-dependent (SD) parameter uncertainty given limited speaker specific adaptation data. This framework is investigated in three forms of model based DNN adaptation techniques: Bayesian learning of hidden unit contributions (BLHUC), Bayesian parameterized activation functions (BPAct), and Bayesian hidden unit bias vectors (BHUB). In all three Bayesian adaptation methods, deterministic SD parameters are replaced by latent variable posterior distributions to be learned for each speaker, whose parameters are efficiently estimated using a variational inference based approach. Experiments conducted on 300-hour speed perturbed Switchboard corpus trained LF-MMI factored TDNN/CNN-TDNN systems featuring i-vector speaker adaptation suggest the proposed Bayesian adaptation approaches consistently outperform the adapted systems using deterministic parameters on the NIST Hub5'00 and RT03 evaluation sets in both unsupervised test time speaker adaptation and speaker adaptive training. The efficacy of the proposed Bayesian adaptation techniques is further demonstrated in a comparison against the state-of-the-art performance obtained on the same task using the most recent hybrid and end-to-end systems reported in the literature.
Smart Attendance System Usign CNN
Apr 22, 2020The research on the attendance system has been going for a very long time, numerous arrangements have been proposed in the last decade to make this system efficient and less time consuming, but all those systems have several flaws. In this paper, we are introducing a smart and efficient system for attendance using face detection and face recognition. This system can be used to take attendance in colleges or offices using real-time face recognition with the help of the Convolution Neural Network(CNN). The conventional methods like Eigenfaces and Fisher faces are sensitive to lighting, noise, posture, obstruction, illumination etc. Hence, we have used CNN to recognize the face and overcome such difficulties. The attendance records will be updated automatically and stored in an excel sheet as well as in a database. We have used MongoDB as a backend database for attendance records.
Identifying Properties of Real-World Optimisation Problems through a Questionnaire
Nov 11, 2020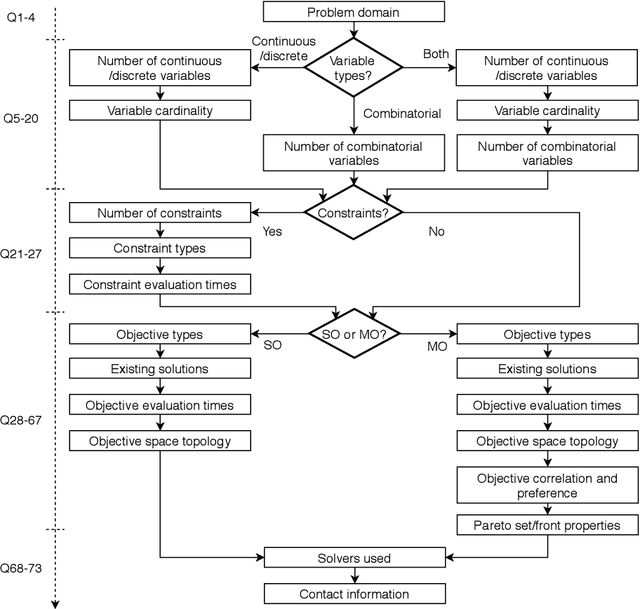
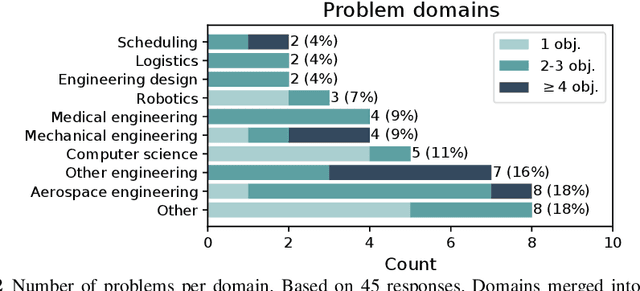
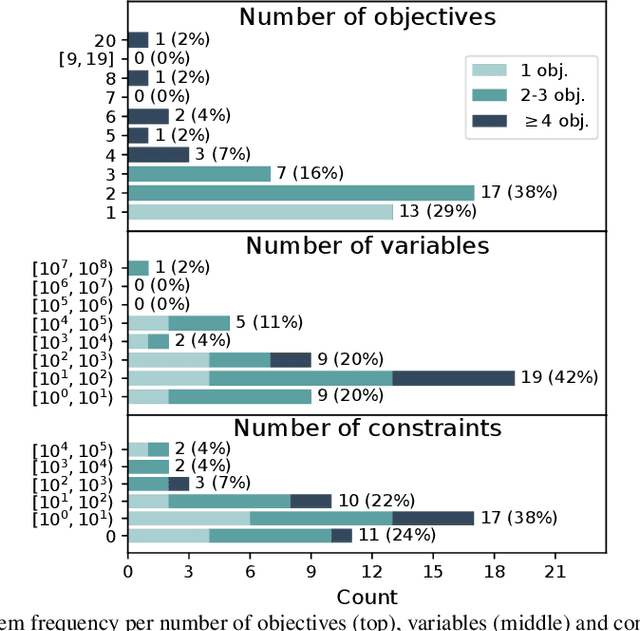
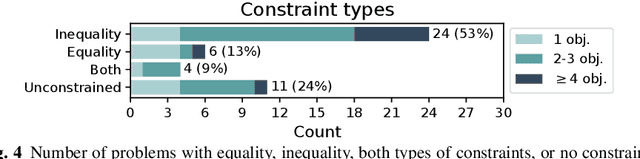
Optimisation algorithms are commonly compared on benchmarks to get insight into performance differences. However, it is not clear how closely benchmarks match the properties of real-world problems because these properties are largely unknown. This work investigates the properties of real-world problems through a questionnaire to enable the design of future benchmark problems that more closely resemble those found in the real world. The results, while not representative, show that many problems possess at least one of the following properties: they are constrained, deterministic, have only continuous variables, require substantial computation times for both the objectives and the constraints, or allow a limited number of evaluations. Properties like known optimal solutions and analytical gradients are rarely available, limiting the options in guiding the optimisation process. These are all important aspects to consider when designing realistic benchmark problems. At the same time, objective functions are often reported to be black-box and since many problem properties are unknown the design of realistic benchmarks is difficult. To further improve the understanding of real-world problems, readers working on a real-world optimisation problem are encouraged to fill out the questionnaire: https://tinyurl.com/opt-survey