 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
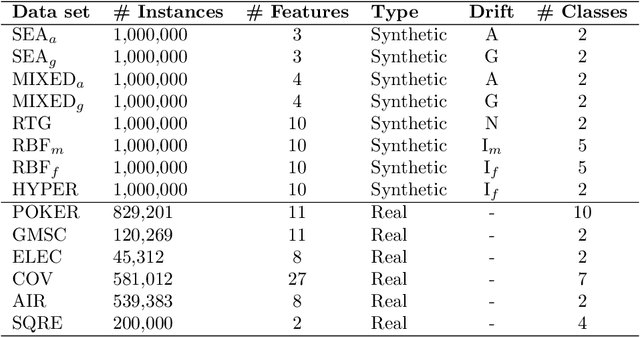
ORBIT: Ordering Based Information Transfer Across Space and Time for Global Surface Water Monitoring
Nov 15, 2017

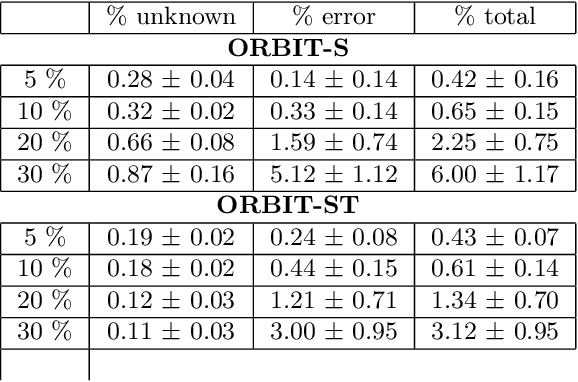
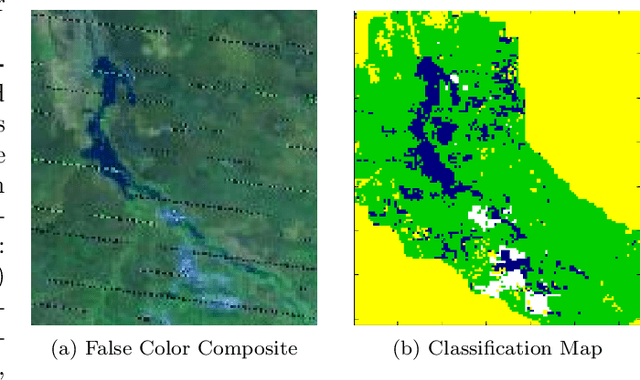
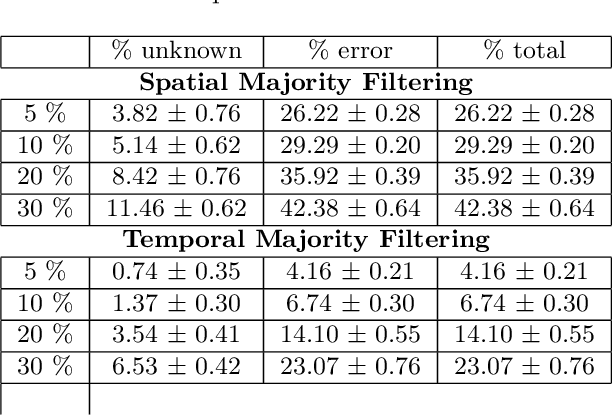
Many earth science applications require data at both high spatial and temporal resolution for effective monitoring of various ecosystem resources. Due to practical limitations in sensor design, there is often a trade-off in different resolutions of spatio-temporal datasets and hence a single sensor alone cannot provide the required information. Various data fusion methods have been proposed in the literature that mainly rely on individual timesteps when both datasets are available to learn a mapping between features values at different resolutions using local relationships between pixels. Earth observation data is often plagued with spatially and temporally correlated noise, outliers and missing data due to atmospheric disturbances which pose a challenge in learning the mapping from a local neighborhood at individual timesteps. In this paper, we aim to exploit time-independent global relationships between pixels for robust transfer of information across different scales. Specifically, we propose a new framework, ORBIT (Ordering Based Information Transfer) that uses relative ordering constraint among pixels to transfer information across both time and scales. The effectiveness of the framework is demonstrated for global surface water monitoring using both synthetic and real-world datasets.
Enhancing Balanced Graph Edge Partition with Effective Local Search
Dec 17, 2020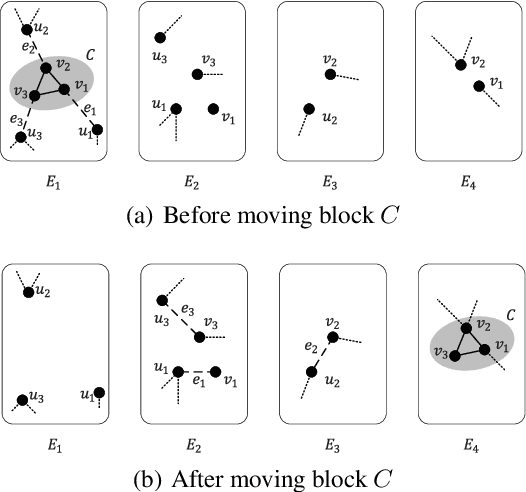
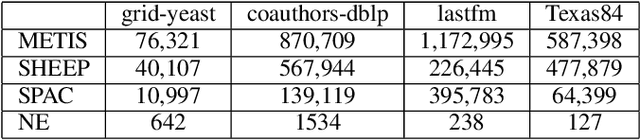
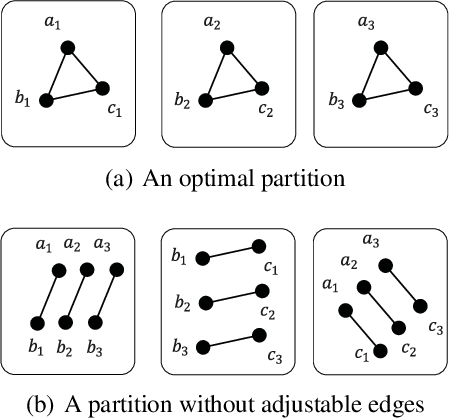
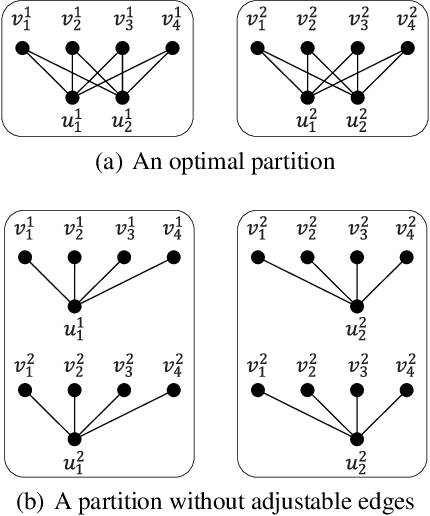
Graph partition is a key component to achieve workload balance and reduce job completion time in parallel graph processing systems. Among the various partition strategies, edge partition has demonstrated more promising performance in power-law graphs than vertex partition and thereby has been more widely adopted as the default partition strategy by existing graph systems. The graph edge partition problem, which is to split the edge set into multiple balanced parts to minimize the total number of copied vertices, has been widely studied from the view of optimization and algorithms. In this paper, we study local search algorithms for this problem to further improve the partition results from existing methods. More specifically, we propose two novel concepts, namely adjustable edges and blocks. Based on these, we develop a greedy heuristic as well as an improved search algorithm utilizing the property of the max-flow model. To evaluate the performance of our algorithms, we first provide adequate theoretical analysis in terms of the approximation quality. We significantly improve the previously known approximation ratio for this problem. Then we conduct extensive experiments on a large number of benchmark datasets and state-of-the-art edge partition strategies. The results show that our proposed local search framework can further improve the quality of graph partition by a wide margin.
Reactive Soft Prototype Computing for Concept Drift Streams
Jul 10, 2020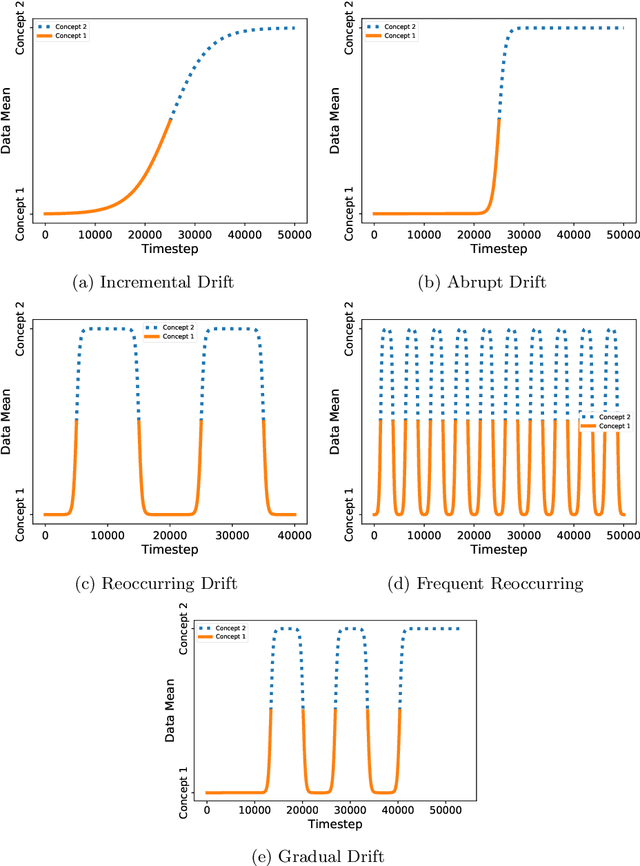
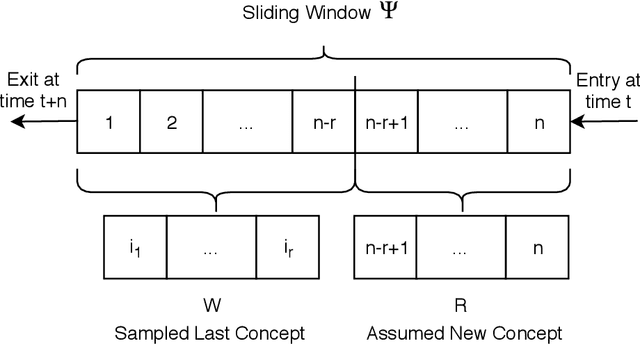

The amount of real-time communication between agents in an information system has increased rapidly since the beginning of the decade. This is because the use of these systems, e. g. social media, has become commonplace in today's society. This requires analytical algorithms to learn and predict this stream of information in real-time. The nature of these systems is non-static and can be explained, among other things, by the fast pace of trends. This creates an environment in which algorithms must recognize changes and adapt. Recent work shows vital research in the field, but mainly lack stable performance during model adaptation. In this work, a concept drift detection strategy followed by a prototype-based adaptation strategy is proposed. Validated through experimental results on a variety of typical non-static data, our solution provides stable and quick adjustments in times of change.
Faster Differentially Private Samplers via Rényi Divergence Analysis of Discretized Langevin MCMC
Oct 27, 2020
Various differentially private algorithms instantiate the exponential mechanism, and require sampling from the distribution $\exp(-f)$ for a suitable function $f$. When the domain of the distribution is high-dimensional, this sampling can be computationally challenging. Using heuristic sampling schemes such as Gibbs sampling does not necessarily lead to provable privacy. When $f$ is convex, techniques from log-concave sampling lead to polynomial-time algorithms, albeit with large polynomials. Langevin dynamics-based algorithms offer much faster alternatives under some distance measures such as statistical distance. In this work, we establish rapid convergence for these algorithms under distance measures more suitable for differential privacy. For smooth, strongly-convex $f$, we give the first results proving convergence in R\'enyi divergence. This gives us fast differentially private algorithms for such $f$. Our techniques and simple and generic and apply also to underdamped Langevin dynamics.
Succinct Trit-array Trie for Scalable Trajectory Similarity Search
May 21, 2020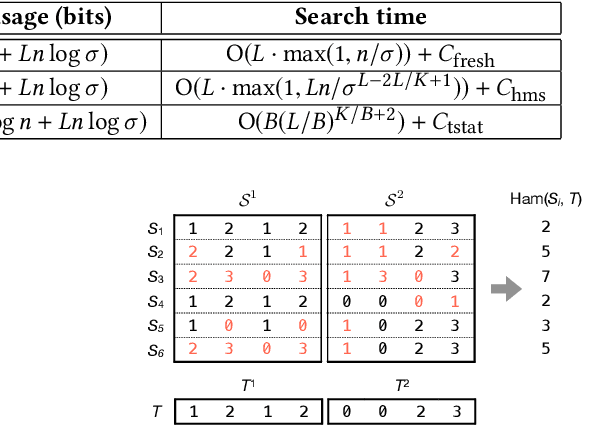

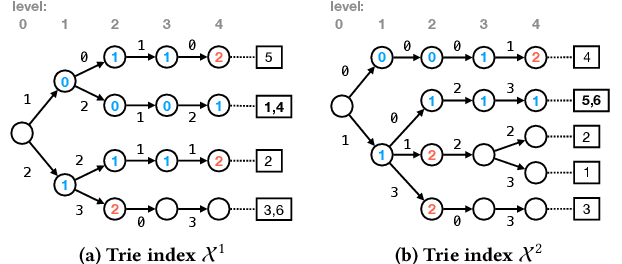
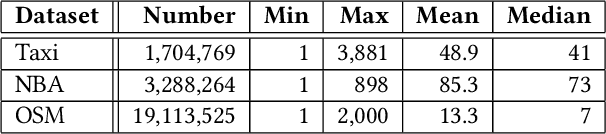
Massive datasets of spatial trajectories representing the mobility of a diversity of moving objects are ubiquitous in research and industry. Similarity search of a large collection of trajectories is indispensable for turning these datasets into knowledge. Current methods for similarity search of trajectories are inefficient in terms of search time and memory when applied to massive datasets. In this paper, we address this problem by presenting a scalable similarity search for Fr\'echet distance on trajectories, which we call trajectory-indexing succinct trit-array trie (tSTAT). tSTAT achieves time and memory efficiency by leveraging locality sensitive hashing (LSH) for Fr\'echet distance and a trie data structure. We also present two novel techniques of node reduction and a space-efficient representation for tries, which enable to dramatically enhance a memory efficiency of tries. We experimentally test tSTAT on its ability to retrieve similar trajectories for a query from large collections of trajectories and show that tSTAT performs superiorly with respect to search time and memory efficiency.
Frame-To-Frame Consistent Semantic Segmentation
Aug 03, 2020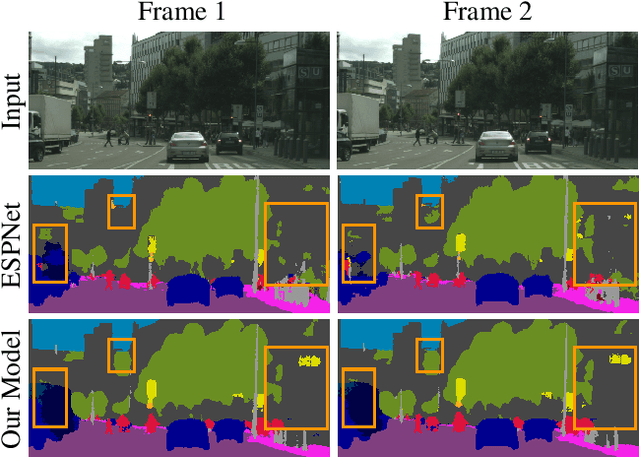
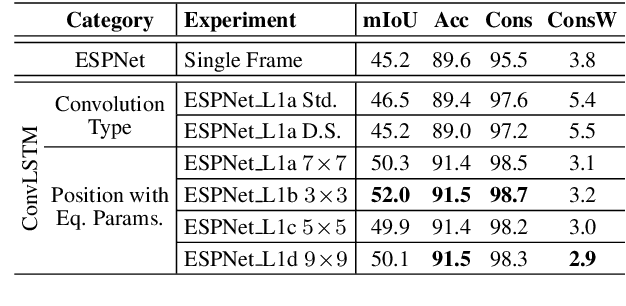
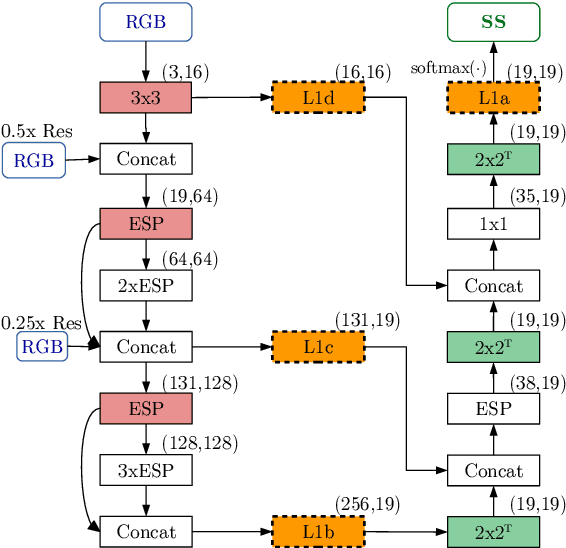
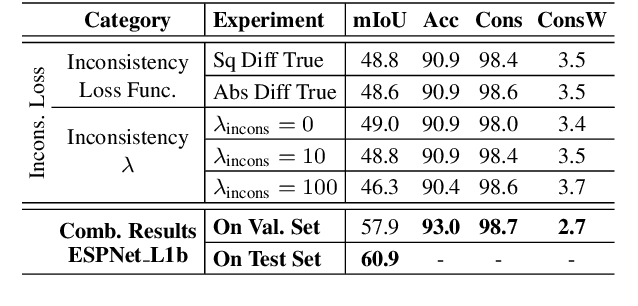
In this work, we aim for temporally consistent semantic segmentation throughout frames in a video. Many semantic segmentation algorithms process images individually which leads to an inconsistent scene interpretation due to illumination changes, occlusions and other variations over time. To achieve a temporally consistent prediction, we train a convolutional neural network (CNN) which propagates features through consecutive frames in a video using a convolutional long short term memory (ConvLSTM) cell. Besides the temporal feature propagation, we penalize inconsistencies in our loss function. We show in our experiments that the performance improves when utilizing video information compared to single frame prediction. The mean intersection over union (mIoU) metric on the Cityscapes validation set increases from 45.2 % for the single frames to 57.9 % for video data after implementing the ConvLSTM to propagate features trough time on the ESPNet. Most importantly, inconsistency decreases from 4.5 % to 1.3 % which is a reduction by 71.1 %. Our results indicate that the added temporal information produces a frame-to-frame consistent and more accurate image understanding compared to single frame processing.
DiverseNet: When One Right Answer is not Enough
Aug 24, 2020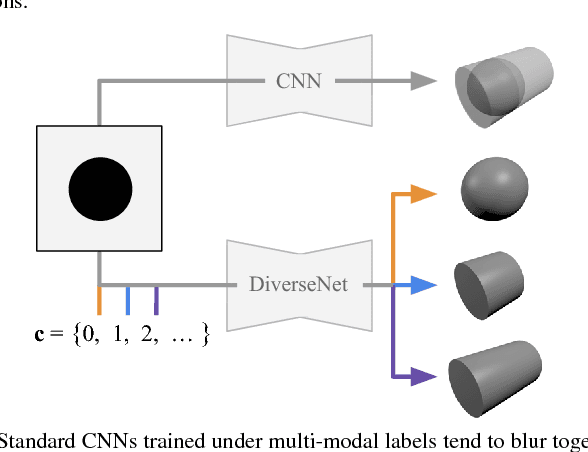
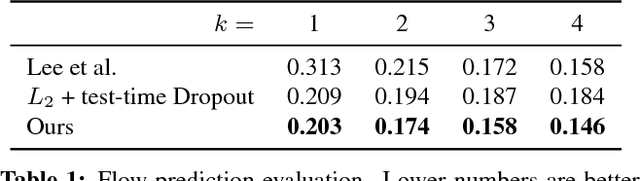
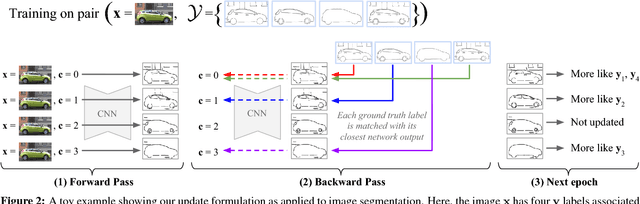
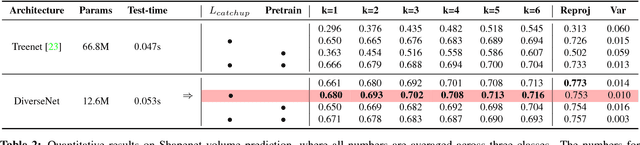
Many structured prediction tasks in machine vision have a collection of acceptable answers, instead of one definitive ground truth answer. Segmentation of images, for example, is subject to human labeling bias. Similarly, there are multiple possible pixel values that could plausibly complete occluded image regions. State-of-the art supervised learning methods are typically optimized to make a single test-time prediction for each query, failing to find other modes in the output space. Existing methods that allow for sampling often sacrifice speed or accuracy. We introduce a simple method for training a neural network, which enables diverse structured predictions to be made for each test-time query. For a single input, we learn to predict a range of possible answers. We compare favorably to methods that seek diversity through an ensemble of networks. Such stochastic multiple choice learning faces mode collapse, where one or more ensemble members fail to receive any training signal. Our best performing solution can be deployed for various tasks, and just involves small modifications to the existing single-mode architecture, loss function, and training regime. We demonstrate that our method results in quantitative improvements across three challenging tasks: 2D image completion, 3D volume estimation, and flow prediction.
Semi-Global Shape-aware Network
Dec 17, 2020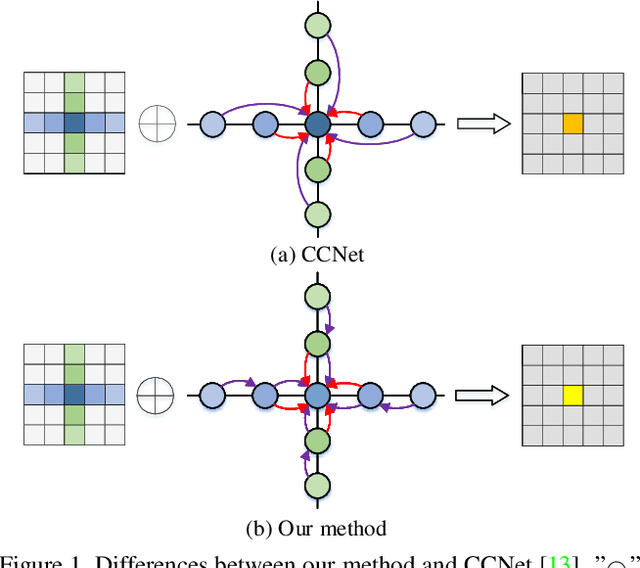

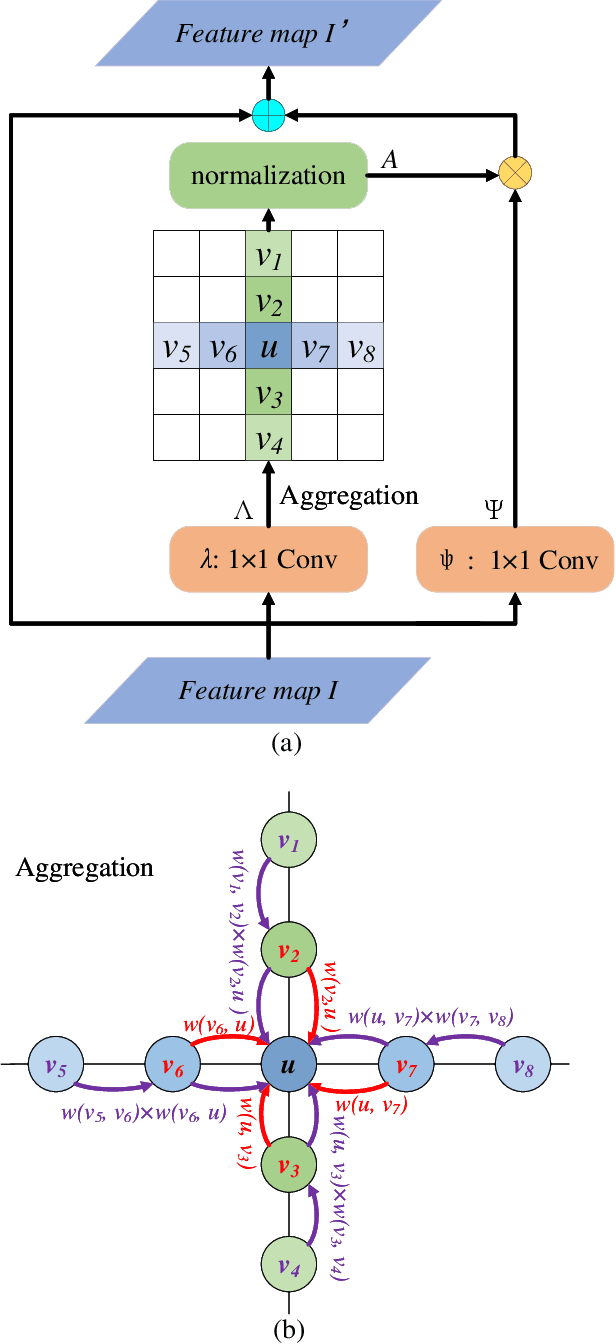
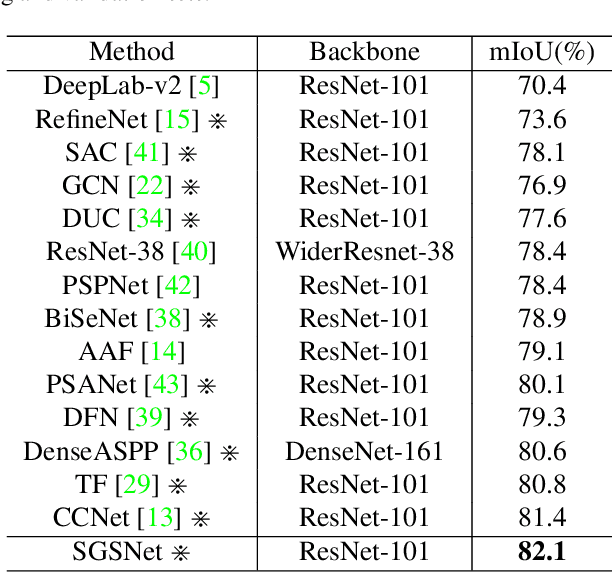
Non-local operations are usually used to capture long-range dependencies via aggregating global context to each position recently. However, most of the methods cannot preserve object shapes since they only focus on feature similarity but ignore proximity between central and other positions for capturing long-range dependencies, while shape-awareness is beneficial to many computer vision tasks. In this paper, we propose a Semi-Global Shape-aware Network (SGSNet) considering both feature similarity and proximity for preserving object shapes when modeling long-range dependencies. A hierarchical way is taken to aggregate global context. In the first level, each position in the whole feature map only aggregates contextual information in vertical and horizontal directions according to both similarity and proximity. And then the result is input into the second level to do the same operations. By this hierarchical way, each central position gains supports from all other positions, and the combination of similarity and proximity makes each position gain supports mostly from the same semantic object. Moreover, we also propose a linear time algorithm for the aggregation of contextual information, where each of rows and columns in the feature map is treated as a binary tree to reduce similarity computation cost. Experiments on semantic segmentation and image retrieval show that adding SGSNet to existing networks gains solid improvements on both accuracy and efficiency.
Automatic Microprocessor Performance Bug Detection
Nov 19, 2020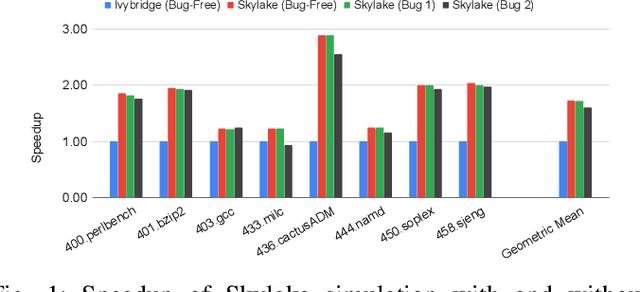
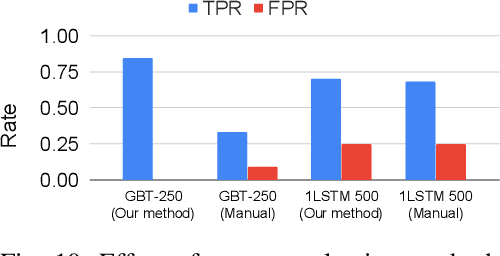
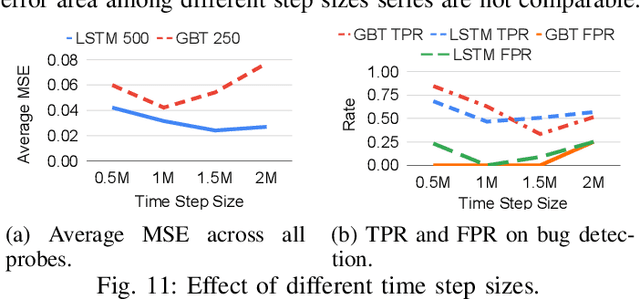
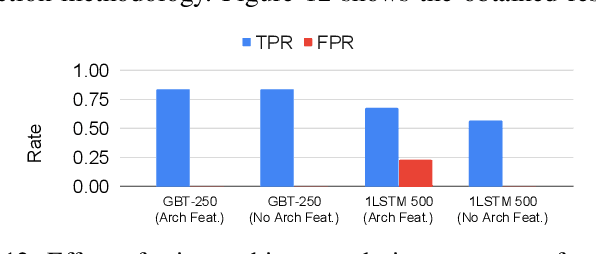
Processor design validation and debug is a difficult and complex task, which consumes the lion's share of the design process. Design bugs that affect processor performance rather than its functionality are especially difficult to catch, particularly in new microarchitectures. This is because, unlike functional bugs, the correct processor performance of new microarchitectures on complex, long-running benchmarks is typically not deterministically known. Thus, when performance benchmarking new microarchitectures, performance teams may assume that the design is correct when the performance of the new microarchitecture exceeds that of the previous generation, despite significant performance regressions existing in the design. In this work, we present a two-stage, machine learning-based methodology that is able to detect the existence of performance bugs in microprocessors. Our results show that our best technique detects 91.5% of microprocessor core performance bugs whose average IPC impact across the studied applications is greater than 1% versus a bug-free design with zero false positives. When evaluated on memory system bugs, our technique achieves 100% detection with zero false positives. Moreover, the detection is automatic, requiring very little performance engineer time.
Constraining Volume Change in Learned Image Registration for Lung CTs
Nov 29, 2020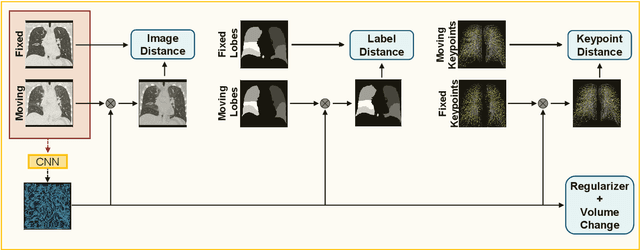
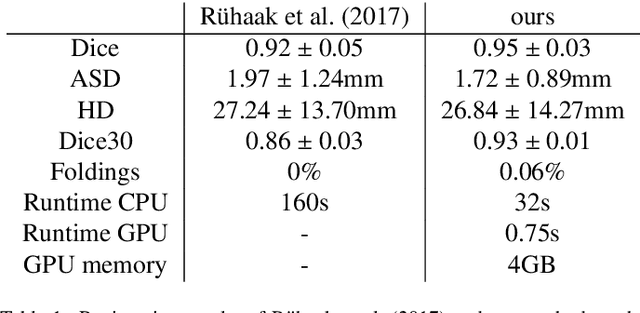
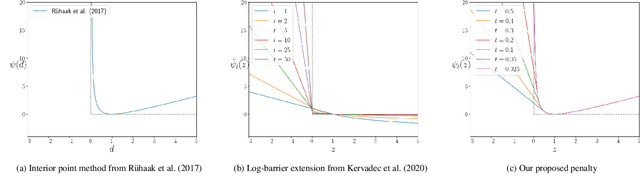

Deep-learning-based registration methods emerged as a fast alternative to conventional registration methods. However, these methods often still cannot achieve the same performance as conventional registration methods, because they are either limited to small deformation or they fail to handle a superposition of large and small deformations without producing implausible deformation fields with foldings inside. In this paper, we identify important strategies of conventional registration methods for lung registration and successfully developed the deep-learning counterpart. We employ a Gaussian-pyramid-based multilevel framework that can solve the image registration optimization in a coarse-to-fine fashion. Furthermore, we prevent foldings of the deformation field and restrict the determinant of the Jacobian to physiologically meaningful values by combining a volume change penalty with a curvature regularizer in the loss function. Keypoint correspondences are integrated to focus on the alignment of smaller structures. We perform an extensive evaluation to assess the accuracy, the robustness, the plausibility of the estimated deformation fields, and the transferability of our registration approach. We show that it archives state-of-the-art results on the COPDGene dataset compared to the challenge winning conventional registration method with much shorter execution time.