 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Data Programming by Demonstration: A Framework for Interactively Learning Labeling Functions
Sep 03, 2020
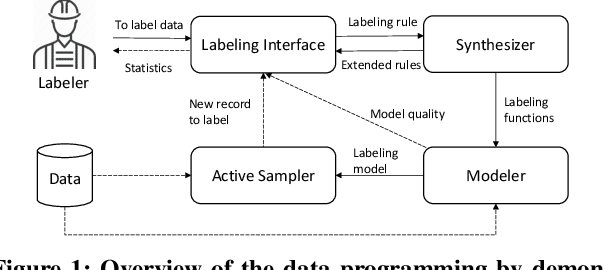
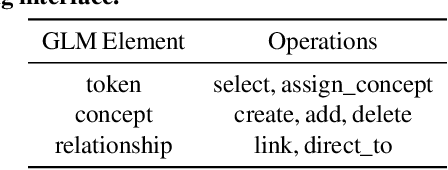
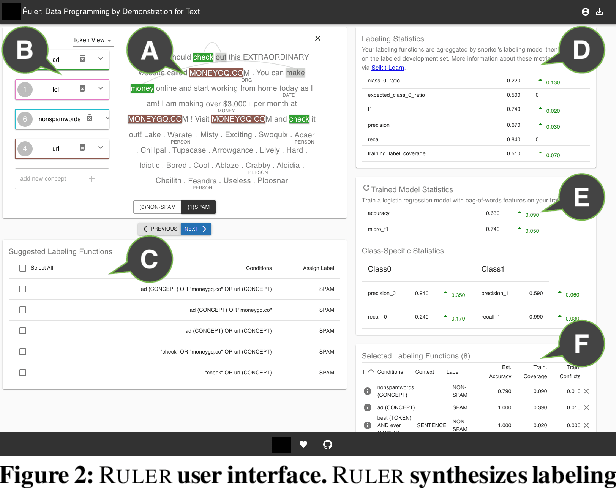

Data programming is a programmatic weak supervision approach to efficiently curate large-scale labeled training data. Writing data programs (labeling functions) requires, however, both programming literacy and domain expertise. Many subject matter experts have neither programming proficiency nor time to effectively write data programs. Furthermore, regardless of one's expertise in coding or machine learning, transferring domain expertise into labeling functions by enumerating rules and thresholds is not only time consuming but also inherently difficult. Here we propose a new framework, data programming by demonstration (DPBD), to generate labeling rules using interactive demonstrations of users. DPBD aims to relieve the burden of writing labeling functions from users, enabling them to focus on higher-level semantics such as identifying relevant signals for labeling tasks. We operationalize our framework with Ruler, an interactive system that synthesizes labeling rules for document classification by using span-level annotations of users on document examples. We compare Ruler with conventional data programming through a user study conducted with 10 data scientists creating labeling functions for sentiment and spam classification tasks. We find that Ruler is easier to use and learn and offers higher overall satisfaction, while providing discriminative model performances comparable to ones achieved by conventional data programming.
A Lagrangian Dual-based Theory-guided Deep Neural Network
Aug 24, 2020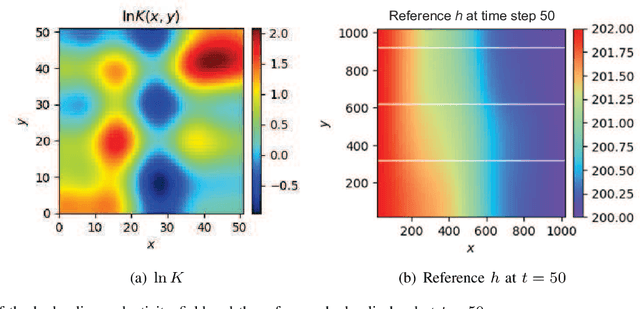
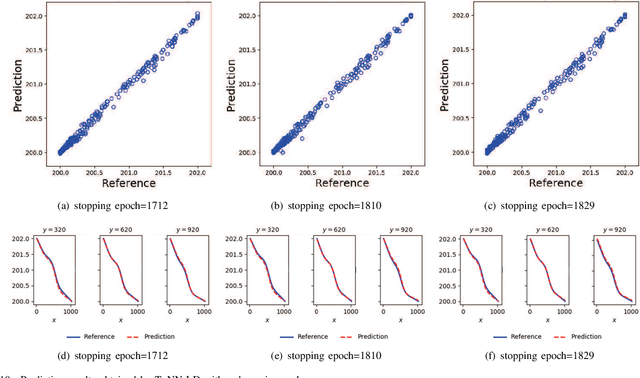
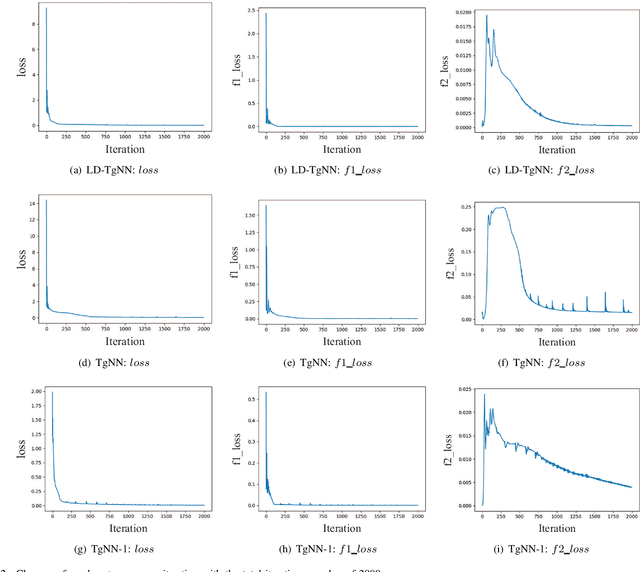
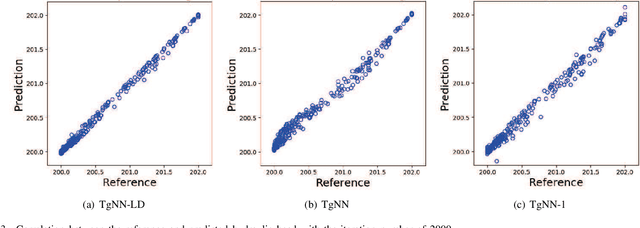
The theory-guided neural network (TgNN) is a kind of method which improves the effectiveness and efficiency of neural network architectures by incorporating scientific knowledge or physical information. Despite its great success, the theory-guided (deep) neural network possesses certain limits when maintaining a tradeoff between training data and domain knowledge during the training process. In this paper, the Lagrangian dual-based TgNN (TgNN-LD) is proposed to improve the effectiveness of TgNN. We convert the original loss function into a constrained form with fewer items, in which partial differential equations (PDEs), engineering controls (ECs), and expert knowledge (EK) are regarded as constraints, with one Lagrangian variable per constraint. These Lagrangian variables are incorporated to achieve an equitable tradeoff between observation data and corresponding constraints, in order to improve prediction accuracy, and conserve time and computational resources adjusted by an ad-hoc procedure. To investigate the performance of the proposed method, the original TgNN model with a set of optimized weight values adjusted by ad-hoc procedures is compared on a subsurface flow problem, with their L2 error, R square (R2), and computational time being analyzed. Experimental results demonstrate the superiority of the Lagrangian dual-based TgNN.
Evaluating Real-time Anomaly Detection Algorithms - the Numenta Anomaly Benchmark
Nov 17, 2015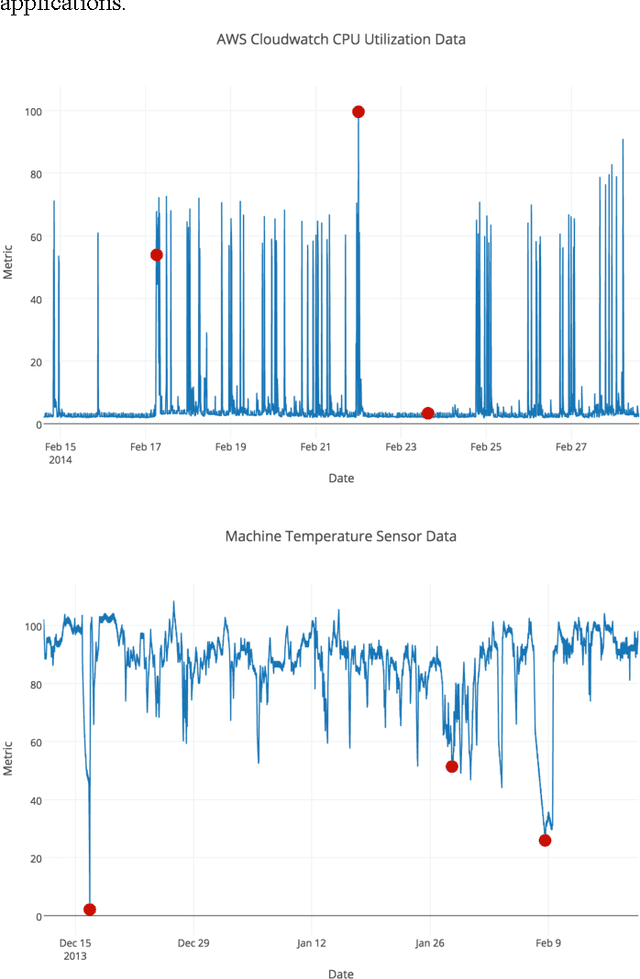
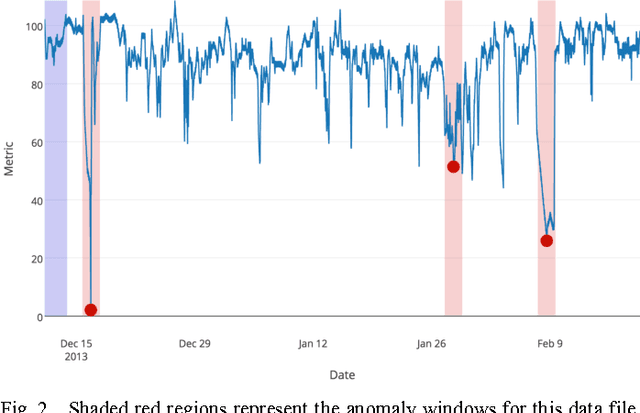
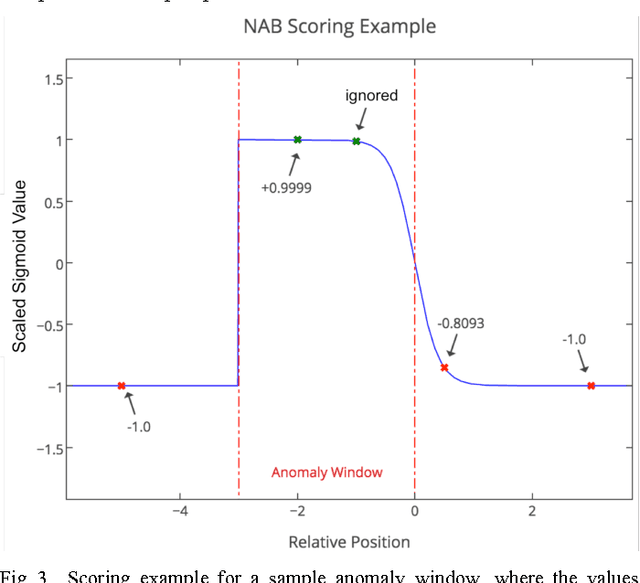
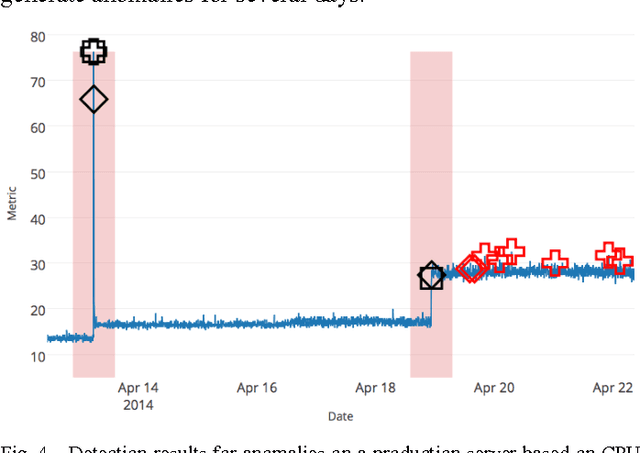
Much of the world's data is streaming, time-series data, where anomalies give significant information in critical situations; examples abound in domains such as finance, IT, security, medical, and energy. Yet detecting anomalies in streaming data is a difficult task, requiring detectors to process data in real-time, not batches, and learn while simultaneously making predictions. There are no benchmarks to adequately test and score the efficacy of real-time anomaly detectors. Here we propose the Numenta Anomaly Benchmark (NAB), which attempts to provide a controlled and repeatable environment of open-source tools to test and measure anomaly detection algorithms on streaming data. The perfect detector would detect all anomalies as soon as possible, trigger no false alarms, work with real-world time-series data across a variety of domains, and automatically adapt to changing statistics. Rewarding these characteristics is formalized in NAB, using a scoring algorithm designed for streaming data. NAB evaluates detectors on a benchmark dataset with labeled, real-world time-series data. We present these components, and give results and analyses for several open source, commercially-used algorithms. The goal for NAB is to provide a standard, open source framework with which the research community can compare and evaluate different algorithms for detecting anomalies in streaming data.
Learning Sparse Polymatrix Games in Polynomial Time and Sample Complexity
Nov 20, 2017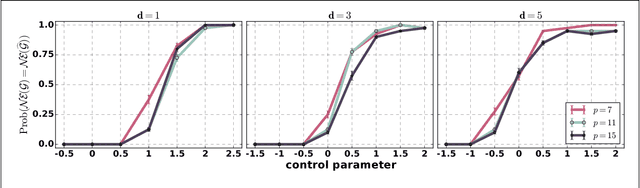
We consider the problem of learning sparse polymatrix games from observations of strategic interactions. We show that a polynomial time method based on $\ell_{1,2}$-group regularized logistic regression recovers a game, whose Nash equilibria are the $\epsilon$-Nash equilibria of the game from which the data was generated (true game), in $\mathcal{O}(m^4 d^4 \log (pd))$ samples of strategy profiles --- where $m$ is the maximum number of pure strategies of a player, $p$ is the number of players, and $d$ is the maximum degree of the game graph. Under slightly more stringent separability conditions on the payoff matrices of the true game, we show that our method learns a game with the exact same Nash equilibria as the true game. We also show that $\Omega(d \log (pm))$ samples are necessary for any method to consistently recover a game, with the same Nash-equilibria as the true game, from observations of strategic interactions. We verify our theoretical results through simulation experiments.
Active Learning in CNNs via Expected Improvement Maximization
Nov 27, 2020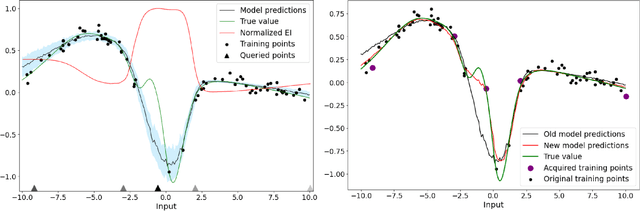

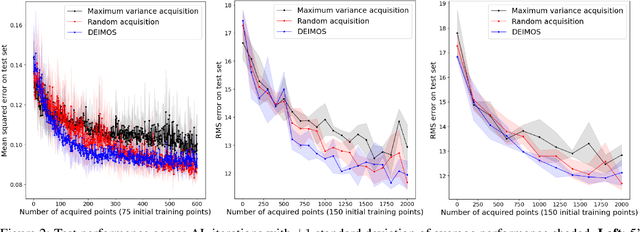

Deep learning models such as Convolutional Neural Networks (CNNs) have demonstrated high levels of effectiveness in a variety of domains, including computer vision and more recently, computational biology. However, training effective models often requires assembling and/or labeling large datasets, which may be prohibitively time-consuming or costly. Pool-based active learning techniques have the potential to mitigate these issues, leveraging models trained on limited data to selectively query unlabeled data points from a pool in an attempt to expedite the learning process. Here we present "Dropout-based Expected IMprOvementS" (DEIMOS), a flexible and computationally-efficient approach to active learning that queries points that are expected to maximize the model's improvement across a representative sample of points. The proposed framework enables us to maintain a prediction covariance matrix capturing model uncertainty, and to dynamically update this matrix in order to generate diverse batches of points in the batch-mode setting. Our active learning results demonstrate that DEIMOS outperforms several existing baselines across multiple regression and classification tasks taken from computer vision and genomics.
CycleQSM: Unsupervised QSM Deep Learning using Physics-Informed CycleGAN
Dec 07, 2020



Quantitative susceptibility mapping (QSM) is a useful magnetic resonance imaging (MRI) technique which provides spatial distribution of magnetic susceptibility values of tissues. QSMs can be obtained by deconvolving the dipole kernel from phase images, but the spectral nulls in the dipole kernel make the inversion ill-posed. In recent times, deep learning approaches have shown a comparable QSM reconstruction performance as the classic approaches, despite the fast reconstruction time. Most of the existing deep learning methods are, however, based on supervised learning, so matched pairs of input phase images and the ground-truth maps are needed. Moreover, it was reported that the supervised learning often leads to underestimated QSM values. To address this, here we propose a novel unsupervised QSM deep learning method using physics-informed cycleGAN, which is derived from optimal transport perspective. In contrast to the conventional cycleGAN, our novel cycleGAN has only one generator and one discriminator thanks to the known dipole kernel. Experimental results confirm that the proposed method provides more accurate QSM maps compared to the existing deep learning approaches, and provide competitive performance to the best classical approaches despite the ultra-fast reconstruction.
Deep ConvLSTM with self-attention for human activity decoding using wearables
May 02, 2020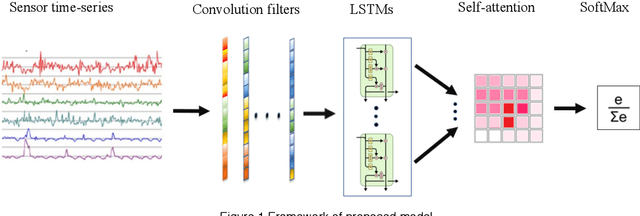
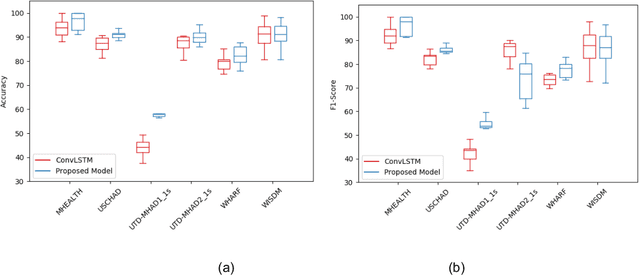

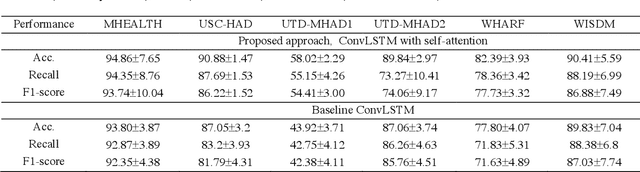
Decoding human activity accurately from wearable sensors can aid in applications related to healthcare and context awareness. The present approaches in this domain use recurrent and/or convolutional models to capture the spatio-temporal features from time series data from multiple sensors. We propose a deep neural network architecture that not only captures the spatio-temporal features of multiple sensor time series data, but also selects, learns important time points by utilizing a self-attention mechanism. We show the validity of the proposed approach across different data sampling strategies on six public datasets and demonstrate that the self-attention mechanism gave significant improvement in performance over deep networks using a combination of recurrent and convolution networks. We also show that the proposed approach gave a statistically significant performance enhancement over previous state-of-the-art methods for the tested datasets. The proposed methods open avenues for better decoding of human activity from multiple body sensors over extended periods of time. The code implementation for the proposed model is available at https://github.com/isukrit/encodingHumanActivity
Transfer Learning improves MI BCI models classification accuracy in Parkinson's disease patients
Oct 29, 2020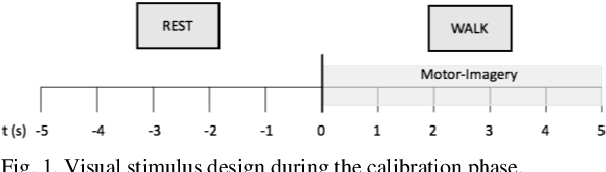
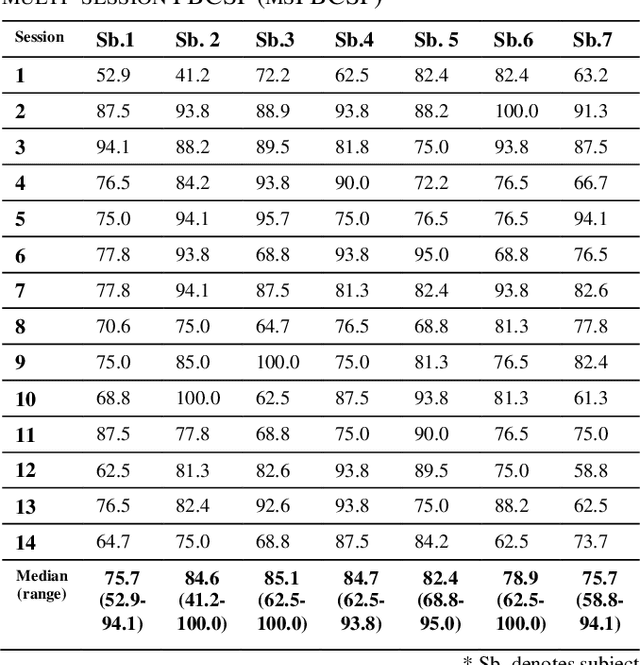
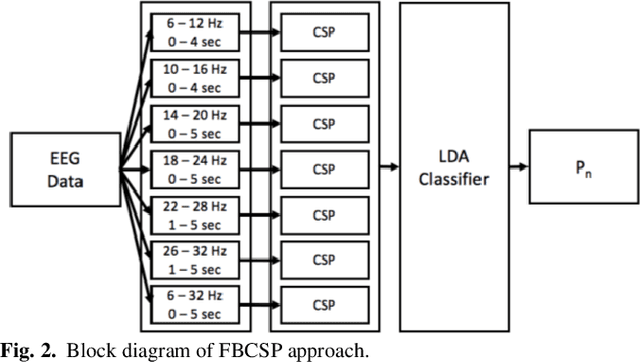
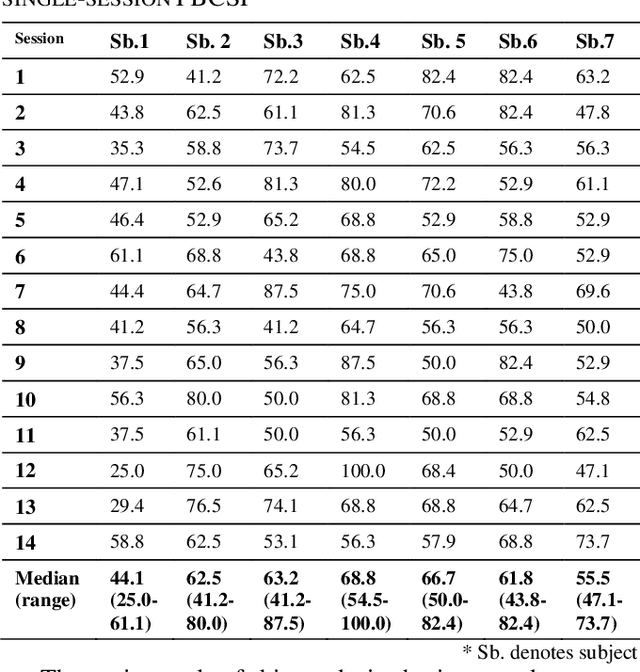
Motor-Imagery based BCI (MI-BCI) neurorehabilitation can improve locomotor ability and reduce the deficit symptoms in Parkinson's Disease patients. Advanced Motor-Imagery BCI methods are needed to overcome the accuracy and time-related MI BCI calibration challenges in such patients. In this study, we proposed a Multi-session FBCSP (msFBCSP) based on inter-session transfer learning and we investigated its performance compared to the single-session based FBSCP. The main result of this study is the significantly improved accuracy obtained by proposed msFBCSP compared to single-session FBCSP in PD patients (median 81.3%, range 41.2-100.0% vs median 61.1%, range 25.0-100.0%, respectively; p<0.001). In conclusion, this study proposes a transfer learning-based multi-session based FBCSP approach which allowed to significantly improve calibration accuracy in MI BCI performed on PD patients.
Optimizing Neural Networks via Koopman Operator Theory
Jun 11, 2020

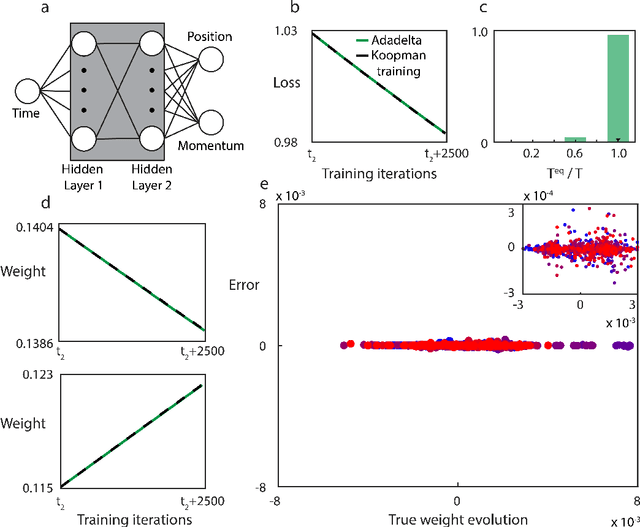

Koopman operator theory, a powerful framework for discovering the underlying dynamics of nonlinear dynamical systems, was recently shown to be intimately connected with neural network training. In this work, we take the first steps in making use of this connection. As Koopman operator theory is a linear theory, a successful implementation of it in evolving network weights and biases offers the promise of accelerated training, especially in the context of deep networks, where optimization is inherently a non-convex problem. We show that Koopman operator theory methods allow for accurate predictions of the weights and biases of a feedforward, fully connected deep network over a non-trivial range of training time. During this time window, we find that our approach is at least 10x faster than gradient descent based methods, in line with the results expected from our complexity analysis. We highlight additional methods by which our results can be expanded to broader classes of networks and larger time intervals, which shall be the focus of future work in this novel intersection between dynamical systems and neural network theory.
A Compact Gated-Synapse Model for Neuromorphic Circuits
Jun 29, 2020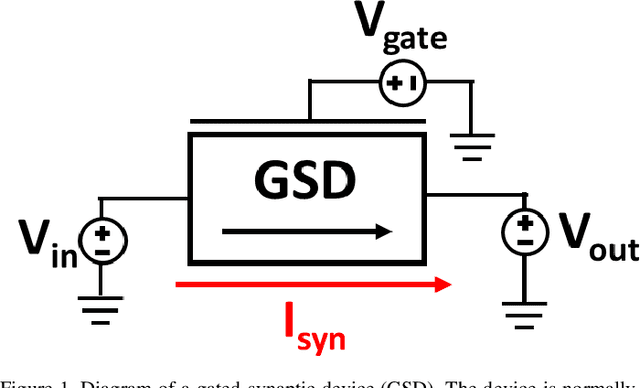
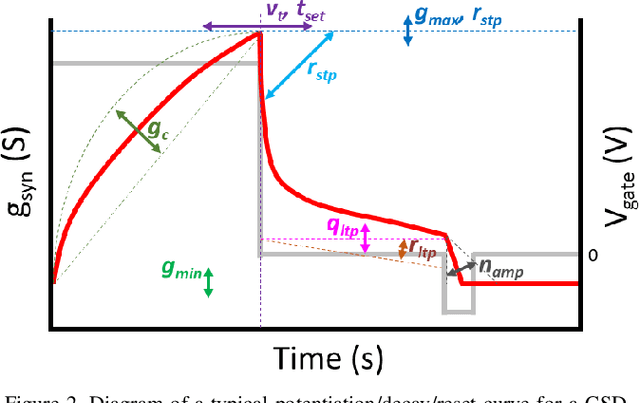
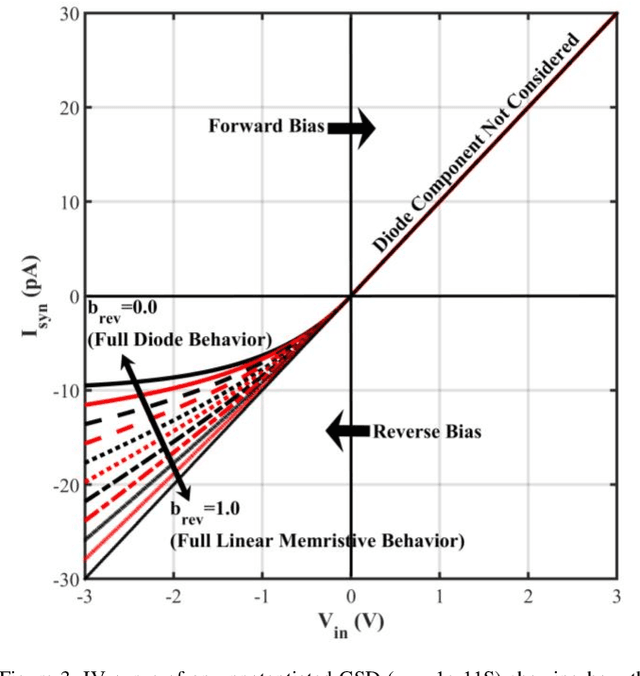
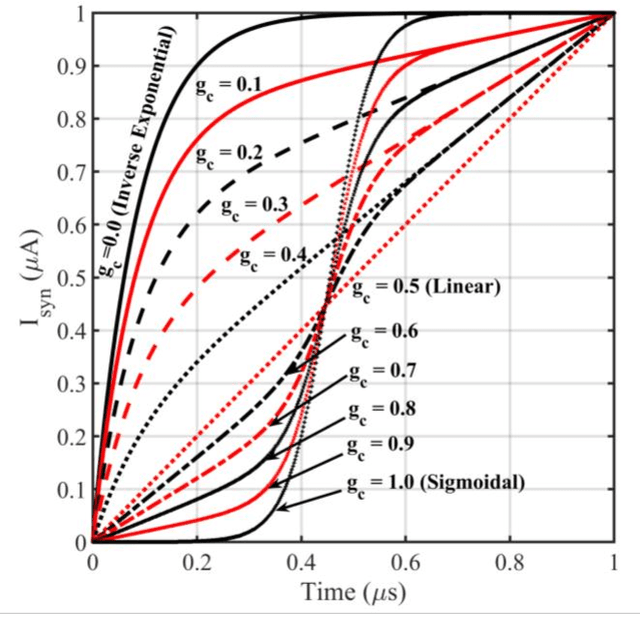
This work reports a compact behavioral model for gated-synaptic memory. The model is developed in Verilog-A for easy integration into computer-aided design of neuromorphic circuits using emerging memory. The model encompasses various forms of gated synapses within a single framework and is not restricted to only a single type. The behavioral theory of the model is described in detail along with a full list of the default parameter settings. The model includes parameters such as a device's ideal set time, threshold voltage, general evolution of the conductance with respect to time, decay of the device's state, etc. Finally, the model's validity is shown via extensive simulation and fitting to experimentally reported data on published gated-synapses.