 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Prior Knowledge Neural Network for Automatic Feature Construction in Financial Time Series
Dec 08, 2019
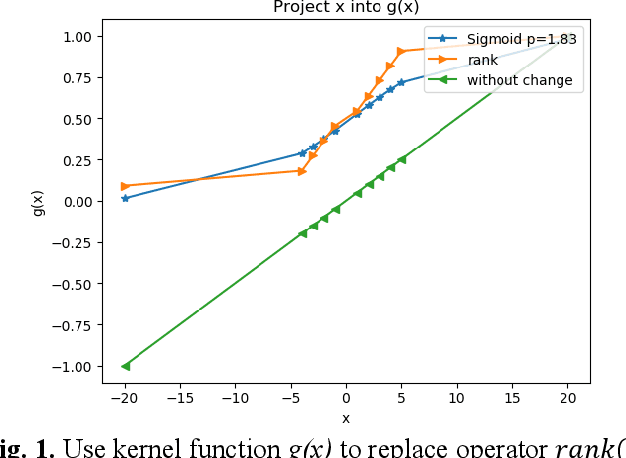
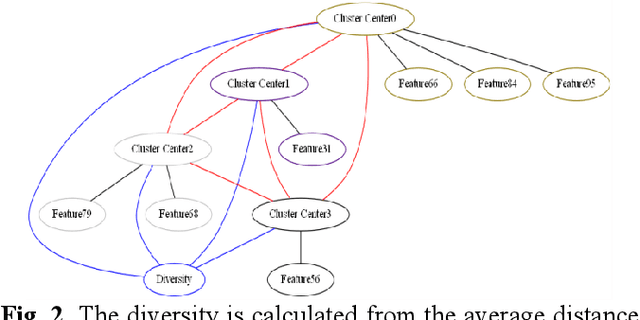
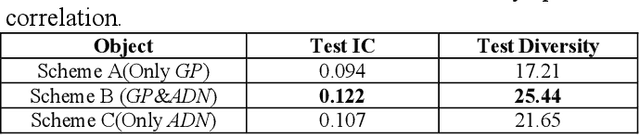
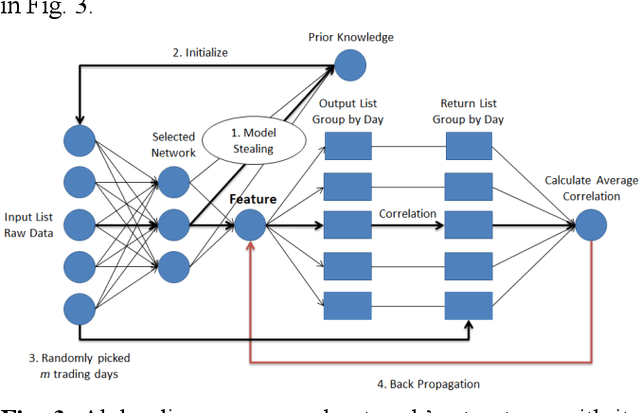
In quantitative finance, useful features are constructed by human experts. However, this method is of low efficient. Thus, automatic feature construction algorithms have received more and more attention. The SOTA technic in this field is to use reverse polish expression to represent the features, and then use genetic programming to reconstruct it. In this paper, we propose a new method, alpha discovery neural network, which can automatically construct features by using neural network. In this work, we made several contributions. Firstly, we put forward new object function by using empirical knowledge in financial signal processing, and we also fixed its undifferentiated problem. Secondly, we use model stealing technic to learn from other prior knowledge, which can bring enough diversity into our network. Thirdly, we come up with a method to measure the diversity of different financial features. Experiment shows that ADN can produce more diversified and higher informative features than GP. Besides, if we use GP's output to serve as prior knowledge, its final achievements will be significantly improved by using ADN.
Sequence-to-sequence models for workload interference
Jul 06, 2020

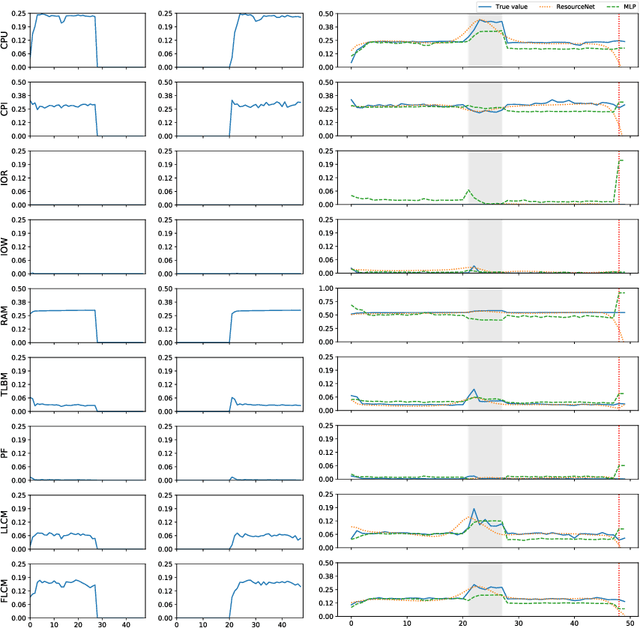
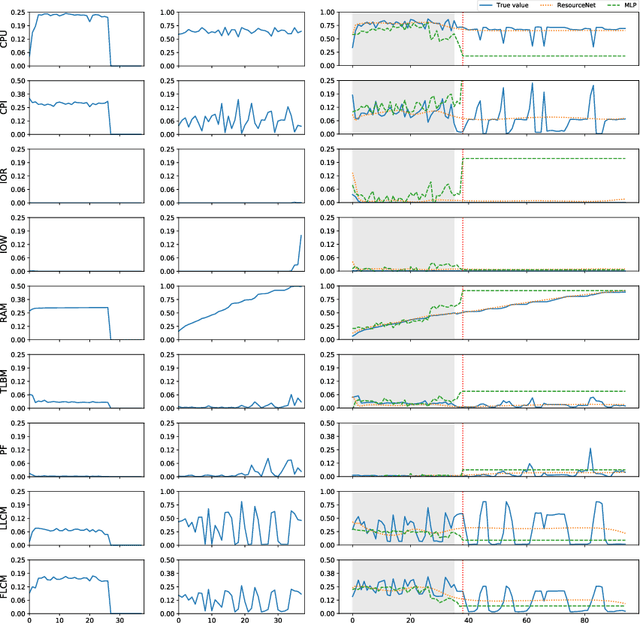
Co-scheduling of jobs in data-centers is a challenging scenario, where jobs can compete for resources yielding to severe slowdowns or failed executions. Efficient job placement on environments where resources are shared requires awareness on how jobs interfere during execution, to go far beyond ineffective resource overbooking techniques. Current techniques, most of them already involving machine learning and job modeling, are based on workload behavior summarization across time, instead of focusing on effective job requirements at each instant of the execution. In this work we propose a methodology for modeling co-scheduling of jobs on data-centers, based on their behavior towards resources and execution time, using sequence-to-sequence models based on recurrent neural networks. The goal is to forecast co-executed jobs footprint on resources along their execution time, from the profile shown by the individual jobs, to enhance resource managers and schedulers placement decisions. The methods here presented are validated using High Performance Computing benchmarks based on different frameworks (like Hadoop and Spark) and applications (CPU bound, IO bound, machine learning, SQL queries...). Experiments show that the model can correctly identify the resource usage trends from previously seen and even unseen co-scheduled jobs.
* artially funded by European Research Council (ERC) under the European Union's Horizon 2020 research and innovation programme (grant agreement No 639595) - HiEST Project
Few-Shot Font Generation with Deep Metric Learning
Nov 04, 2020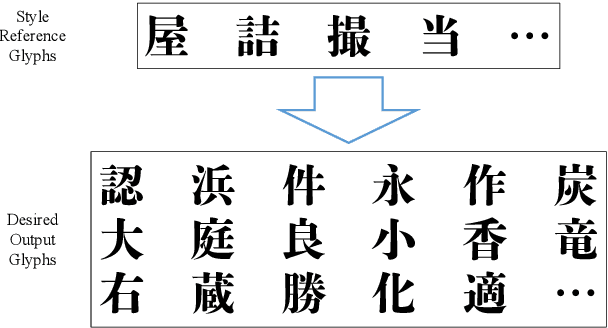
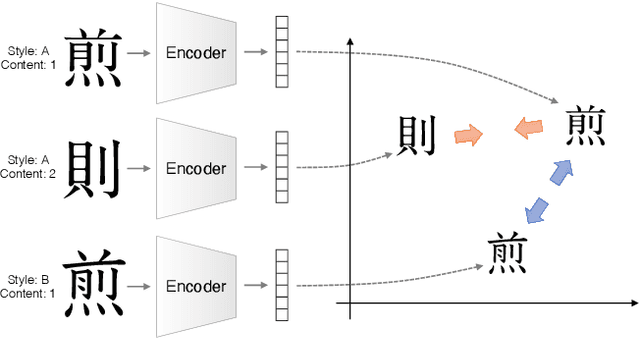
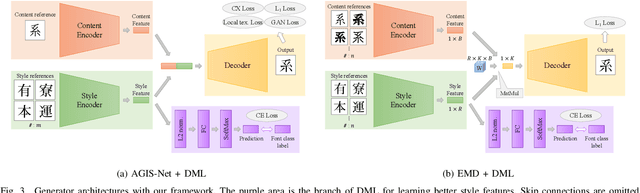

Designing fonts for languages with a large number of characters, such as Japanese and Chinese, is an extremely labor-intensive and time-consuming task. In this study, we addressed the problem of automatically generating Japanese typographic fonts from only a few font samples, where the synthesized glyphs are expected to have coherent characteristics, such as skeletons, contours, and serifs. Existing methods often fail to generate fine glyph images when the number of style reference glyphs is extremely limited. Herein, we proposed a simple but powerful framework for extracting better style features. This framework introduces deep metric learning to style encoders. We performed experiments using black-and-white and shape-distinctive font datasets and demonstrated the effectiveness of the proposed framework.
Investigating the significance of adversarial attacks and their relation to interpretability for radar-based human activity recognition systems
Jan 26, 2021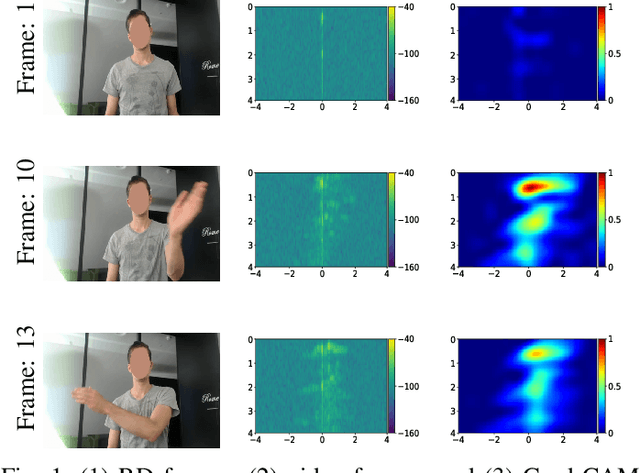
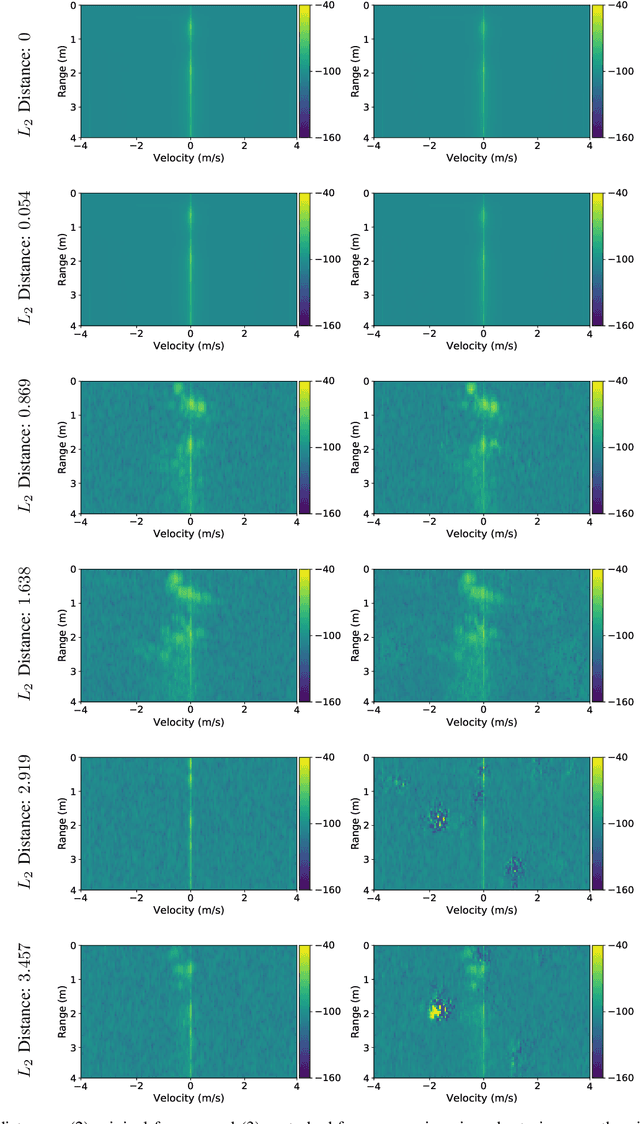
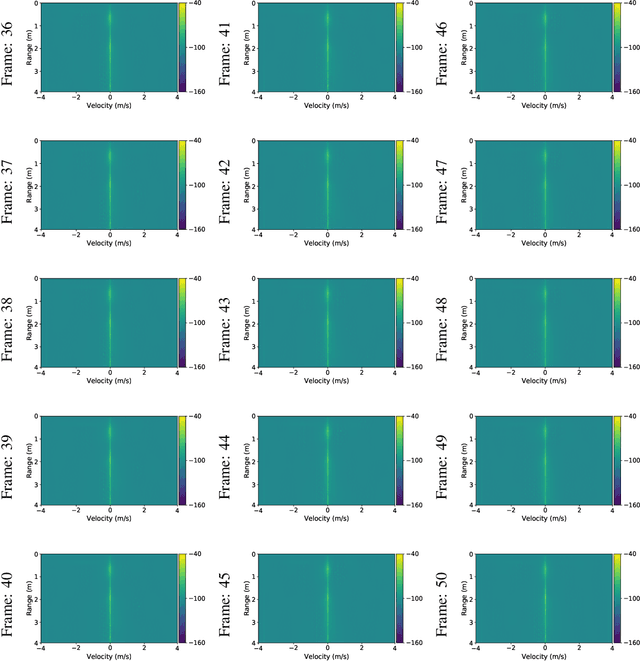
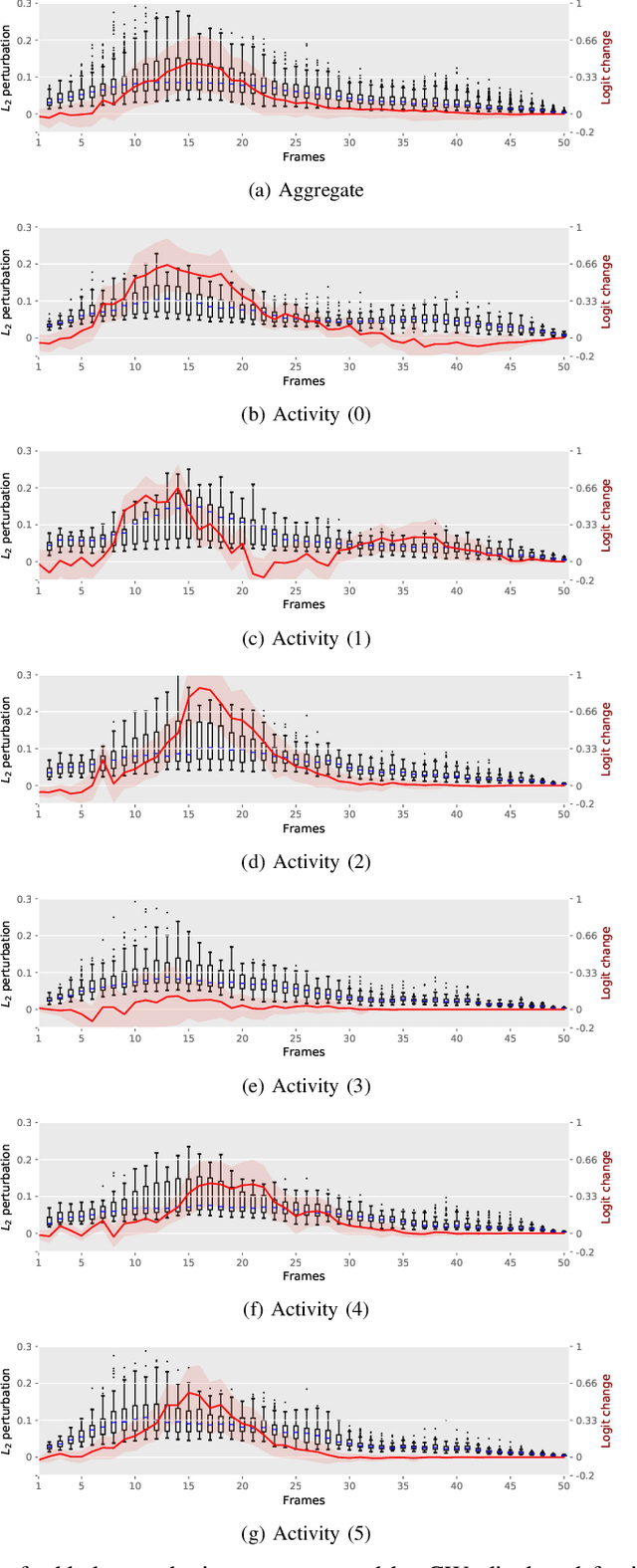
Given their substantial success in addressing a wide range of computer vision challenges, Convolutional Neural Networks (CNNs) are increasingly being used in smart home applications, with many of these applications relying on the automatic recognition of human activities. In this context, low-power radar devices have recently gained in popularity as recording sensors, given that the usage of these devices allows mitigating a number of privacy concerns, a key issue when making use of conventional video cameras. Another concern that is often cited when designing smart home applications is the resilience of these applications against cyberattacks. It is, for instance, well-known that the combination of images and CNNs is vulnerable against adversarial examples, mischievous data points that force machine learning models to generate wrong classifications during testing time. In this paper, we investigate the vulnerability of radar-based CNNs to adversarial attacks, and where these radar-based CNNs have been designed to recognize human gestures. Through experiments with four unique threat models, we show that radar-based CNNs are susceptible to both white- and black-box adversarial attacks. We also expose the existence of an extreme adversarial attack case, where it is possible to change the prediction made by the radar-based CNNs by only perturbing the padding of the inputs, without touching the frames where the action itself occurs. Moreover, we observe that gradient-based attacks exercise perturbation not randomly, but on important features of the input data. We highlight these important features by making use of Grad-CAM, a popular neural network interpretability method, hereby showing the connection between adversarial perturbation and prediction interpretability.
Bitcoin Transaction Forecasting with Deep Network Representation Learning
Jul 15, 2020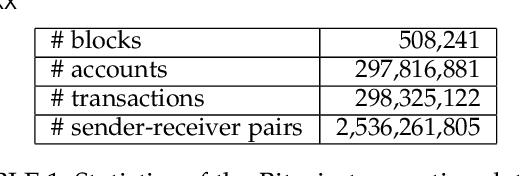
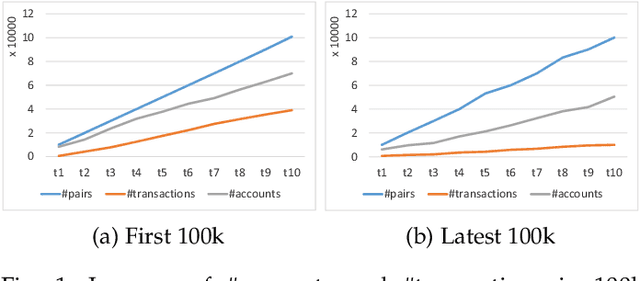
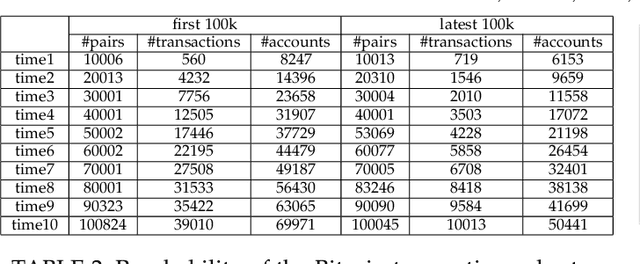
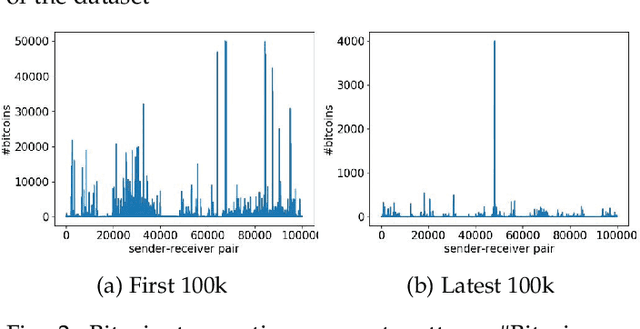
Bitcoin and its decentralized computing paradigm for digital currency trading are one of the most disruptive technology in the 21st century. This paper presents a novel approach to developing a Bitcoin transaction forecast model, DLForecast, by leveraging deep neural networks for learning Bitcoin transaction network representations. DLForecast makes three original contributions. First, we explore three interesting properties between Bitcoin transaction accounts: topological connectivity pattern of Bitcoin accounts, transaction amount pattern, and transaction dynamics. Second, we construct a time-decaying reachability graph and a time-decaying transaction pattern graph, aiming at capturing different types of spatial-temporal Bitcoin transaction patterns. Third, we employ node embedding on both graphs and develop a Bitcoin transaction forecasting system between user accounts based on historical transactions with built-in time-decaying factor. To maintain an effective transaction forecasting performance, we leverage the multiplicative model update (MMU) ensemble to combine prediction models built on different transaction features extracted from each corresponding Bitcoin transaction graph. Evaluated on real-world Bitcoin transaction data, we show that our spatial-temporal forecasting model is efficient with fast runtime and effective with forecasting accuracy over 60\% and improves the prediction performance by 50\% when compared to forecasting model built on the static graph baseline.
Data Programming by Demonstration: A Framework for Interactively Learning Labeling Functions
Sep 15, 2020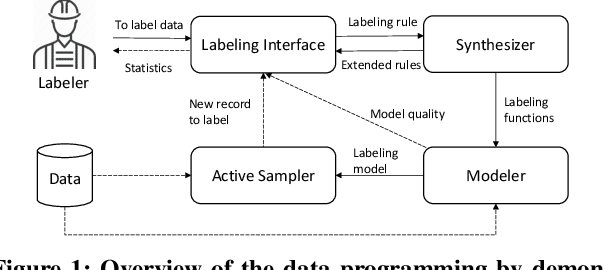
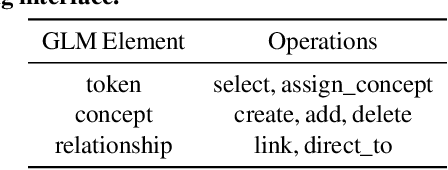
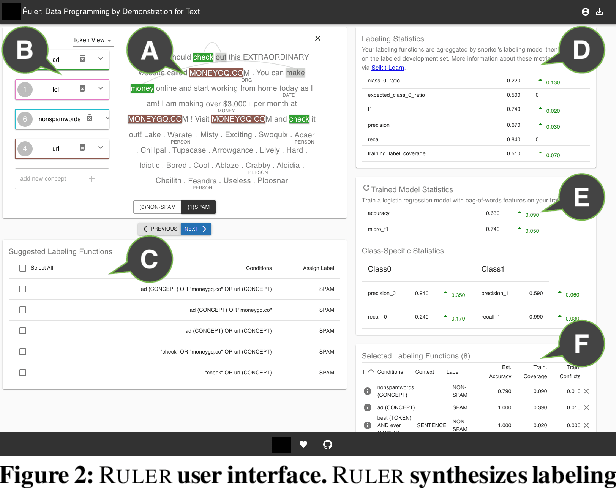

Data programming is a programmatic weak supervision approach to efficiently curate large-scale labeled training data. Writing data programs (labeling functions) requires, however, both programming literacy and domain expertise. Many subject matter experts have neither programming proficiency nor time to effectively write data programs. Furthermore, regardless of one's expertise in coding or machine learning, transferring domain expertise into labeling functions by enumerating rules and thresholds is not only time consuming but also inherently difficult. Here we propose a new framework, data programming by demonstration (DPBD), to generate labeling rules using interactive demonstrations of users. DPBD aims to relieve the burden of writing labeling functions from users, enabling them to focus on higher-level semantics such as identifying relevant signals for labeling tasks. We operationalize our framework with Ruler, an interactive system that synthesizes labeling rules for document classification by using span-level annotations of users on document examples. We compare Ruler with conventional data programming through a user study conducted with 10 data scientists creating labeling functions for sentiment and spam classification tasks. We find that Ruler is easier to use and learn and offers higher overall satisfaction, while providing discriminative model performances comparable to ones achieved by conventional data programming.
Automated Measurements of Key Morphological Features of Human Embryos for IVF
May 29, 2020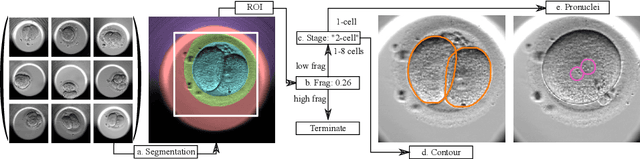
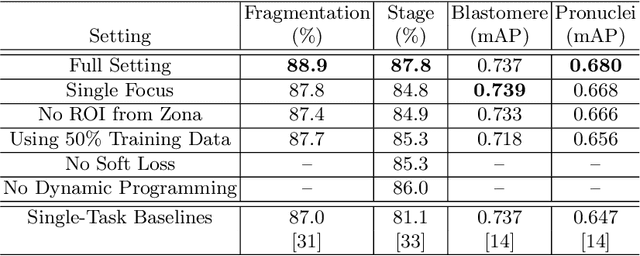
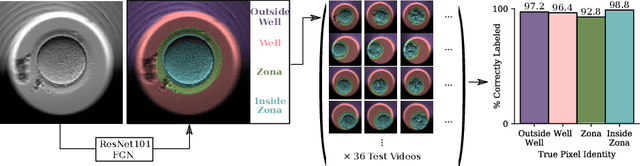

A major challenge in clinical In-Vitro Fertilization (IVF) is selecting the highest quality embryo to transfer to the patient in the hopes of achieving a pregnancy. Time-lapse microscopy provides clinicians with a wealth of information for selecting embryos. However, the resulting movies of embryos are currently analyzed manually, which is time consuming and subjective. Here, we automate feature extraction of time-lapse microscopy of human embryos with a machine-learning pipeline of five convolutional neural networks (CNNs). Our pipeline consists of (1) semantic segmentation of the regions of the embryo, (2) regression predictions of fragment severity, (3) classification of the developmental stage, and object instance segmentation of (4) cells and (5) pronuclei. Our approach greatly speeds up the measurement of quantitative, biologically relevant features that may aid in embryo selection.
Design of a Time Delay Reservoir Using Stochastic Logic: A Feasibility Study
Feb 13, 2017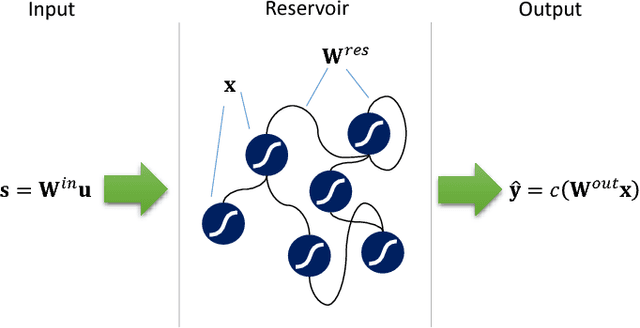
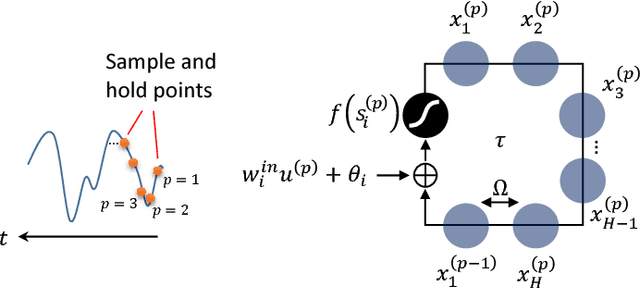
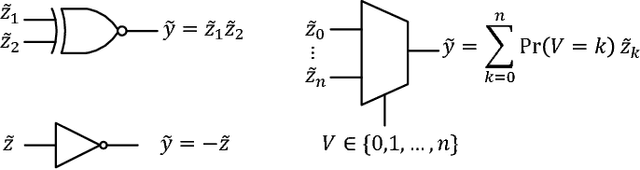
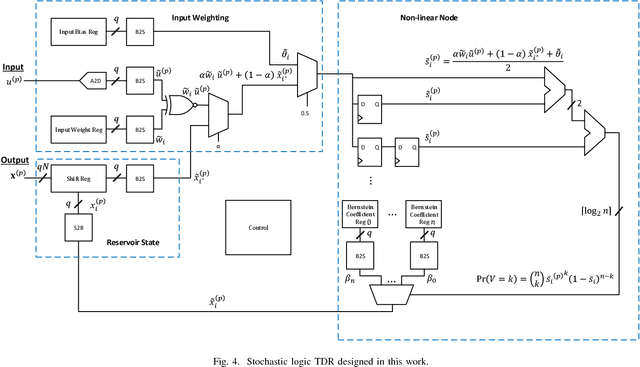
This paper presents a stochastic logic time delay reservoir design. The reservoir is analyzed using a number of metrics, such as kernel quality, generalization rank, performance on simple benchmarks, and is also compared to a deterministic design. A novel re-seeding method is introduced to reduce the adverse effects of stochastic noise, which may also be implemented in other stochastic logic reservoir computing designs, such as echo state networks. Benchmark results indicate that the proposed design performs well on noise-tolerant classification problems, but more work needs to be done to improve the stochastic logic time delay reservoir's robustness for regression problems.
Neural Network architectures to classify emotions in Indian Classical Music
Feb 01, 2021
Music is often considered as the language of emotions. It has long been known to elicit emotions in human being and thus categorizing music based on the type of emotions they induce in human being is a very intriguing topic of research. When the task comes to classify emotions elicited by Indian Classical Music (ICM), it becomes much more challenging because of the inherent ambiguity associated with ICM. The fact that a single musical performance can evoke a variety of emotional response in the audience is implicit to the nature of ICM renditions. With the rapid advancements in the field of Deep Learning, this Music Emotion Recognition (MER) task is becoming more and more relevant and robust, hence can be applied to one of the most challenging test case i.e. classifying emotions elicited from ICM. In this paper we present a new dataset called JUMusEmoDB which presently has 400 audio clips (30 seconds each) where 200 clips correspond to happy emotions and the remaining 200 clips correspond to sad emotion. For supervised classification purposes, we have used 4 existing deep Convolutional Neural Network (CNN) based architectures (resnet18, mobilenet v2.0, squeezenet v1.0 and vgg16) on corresponding music spectrograms of the 2000 sub-clips (where every clip was segmented into 5 sub-clips of about 5 seconds each) which contain both time as well as frequency domain information. The initial results are quite inspiring, and we look forward to setting the baseline values for the dataset using this architecture. This type of CNN based classification algorithm using a rich corpus of Indian Classical Music is unique even in the global perspective and can be replicated in other modalities of music also. This dataset is still under development and we plan to include more data containing other emotional features as well. We plan to make the dataset publicly available soon.
Visualizing Deep Graph Generative Models for Drug Discovery
Jul 20, 2020
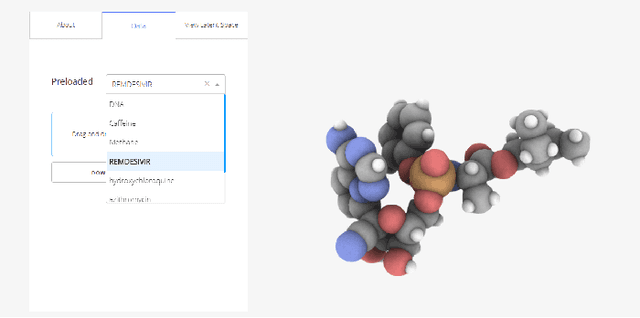
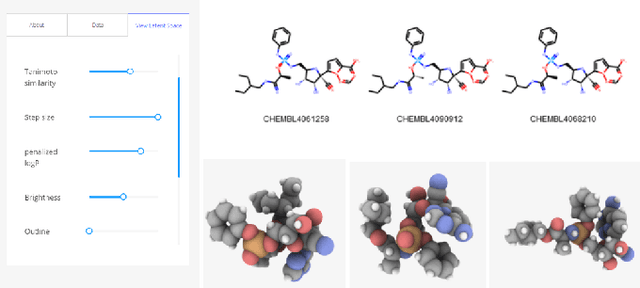
Drug discovery aims at designing novel molecules with specific desired properties for clinical trials. Over past decades, drug discovery and development have been a costly and time consuming process. Driven by big chemical data and AI, deep generative models show great potential to accelerate the drug discovery process. Existing works investigate different deep generative frameworks for molecular generation, however, less attention has been paid to the visualization tools to quickly demo and evaluate model's results. Here, we propose a visualization framework which provides interactive visualization tools to visualize molecules generated during the encoding and decoding process of deep graph generative models, and provide real time molecular optimization functionalities. Our work tries to empower black box AI driven drug discovery models with some visual interpretabilities.