 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManga109-v2026: Revisiting Manga109 Annotations for Modern Manga Understanding
May 20, 2026Manga is a culturally distinctive multimodal medium and one of the most influential forms of Japanese popular culture. As AI systems increasingly target manga understanding, OCR, and translation, Manga109 has become a foundational dataset for manga-related AI research. However, the current Manga109 dataset contains transcription errors and coarse annotations, which do not align well with modern OCR and multimodal manga understanding tasks. In this work, we revisit the dialogue text annotations of Manga109 and identify five categories of annotation issues, including transcription errors, missing text regions, overlapping dialogue and onomatopoeia, and under-segmented speech balloons. To address these issues, we combine OCR-based issue detection and manual revision to construct Manga109-v2026, revising approximately 29,000 dialogue annotations. Our revisions better align Manga109 with modern OCR and multimodal manga understanding systems while preserving expressive structures characteristic of manga.
MangaVQA and MangaLMM: A Benchmark and Specialized Model for Multimodal Manga Understanding
May 26, 2025Manga, or Japanese comics, is a richly multimodal narrative form that blends images and text in complex ways. Teaching large multimodal models (LMMs) to understand such narratives at a human-like level could help manga creators reflect on and refine their stories. To this end, we introduce two benchmarks for multimodal manga understanding: MangaOCR, which targets in-page text recognition, and MangaVQA, a novel benchmark designed to evaluate contextual understanding through visual question answering. MangaVQA consists of 526 high-quality, manually constructed question-answer pairs, enabling reliable evaluation across diverse narrative and visual scenarios. Building on these benchmarks, we develop MangaLMM, a manga-specialized model finetuned from the open-source LMM Qwen2.5-VL to jointly handle both tasks. Through extensive experiments, including comparisons with proprietary models such as GPT-4o and Gemini 2.5, we assess how well LMMs understand manga. Our benchmark and model provide a comprehensive foundation for evaluating and advancing LMMs in the richly narrative domain of manga.
MangaUB: A Manga Understanding Benchmark for Large Multimodal Models
Jul 26, 2024Manga is a popular medium that combines stylized drawings and text to convey stories. As manga panels differ from natural images, computational systems traditionally had to be designed specifically for manga. Recently, the adaptive nature of modern large multimodal models (LMMs) shows possibilities for more general approaches. To provide an analysis of the current capability of LMMs for manga understanding tasks and identifying areas for their improvement, we design and evaluate MangaUB, a novel manga understanding benchmark for LMMs. MangaUB is designed to assess the recognition and understanding of content shown in a single panel as well as conveyed across multiple panels, allowing for a fine-grained analysis of a model's various capabilities required for manga understanding. Our results show strong performance on the recognition of image content, while understanding the emotion and information conveyed across multiple panels is still challenging, highlighting future work towards LMMs for manga understanding.
Few-Shot Font Generation with Deep Metric Learning
Nov 04, 2020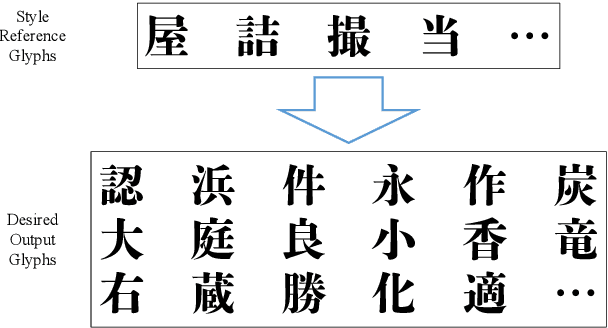
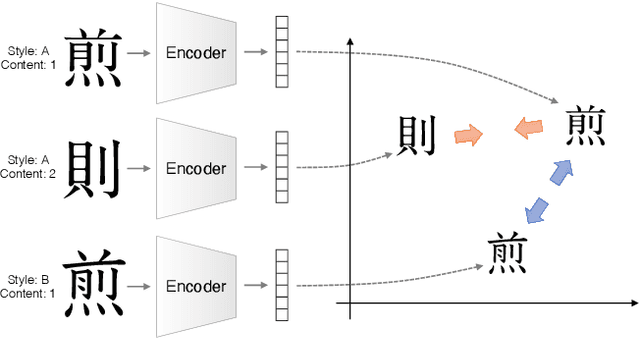
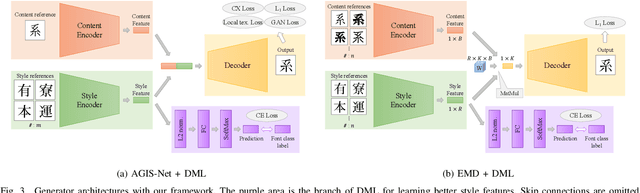

Designing fonts for languages with a large number of characters, such as Japanese and Chinese, is an extremely labor-intensive and time-consuming task. In this study, we addressed the problem of automatically generating Japanese typographic fonts from only a few font samples, where the synthesized glyphs are expected to have coherent characteristics, such as skeletons, contours, and serifs. Existing methods often fail to generate fine glyph images when the number of style reference glyphs is extremely limited. Herein, we proposed a simple but powerful framework for extracting better style features. This framework introduces deep metric learning to style encoders. We performed experiments using black-and-white and shape-distinctive font datasets and demonstrated the effectiveness of the proposed framework.
Building a Manga Dataset "Manga109" with Annotations for Multimedia Applications
May 12, 2020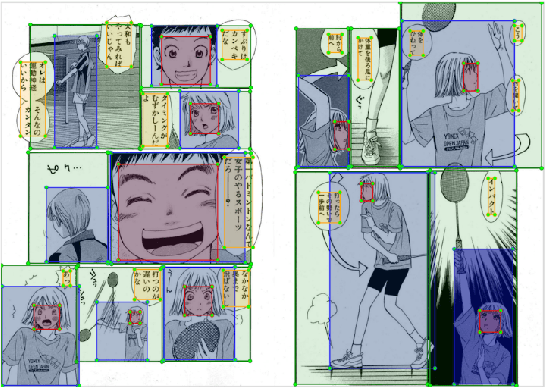
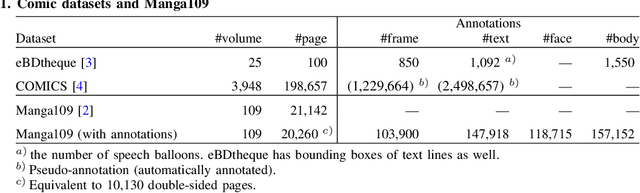
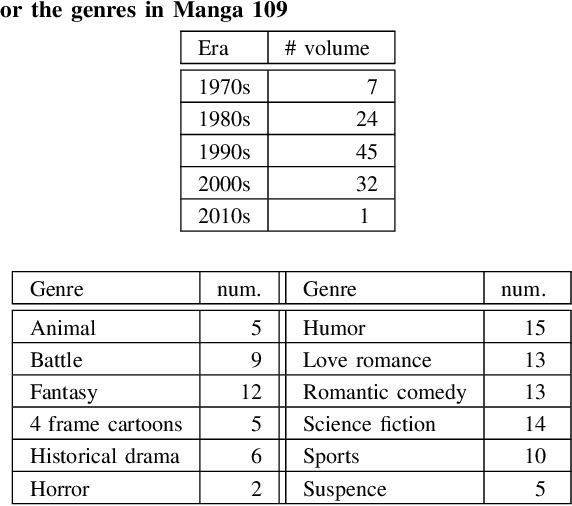
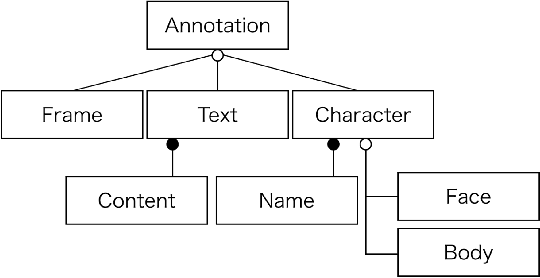
Manga, or comics, which are a type of multimodal artwork, have been left behind in the recent trend of deep learning applications because of the lack of a proper dataset. Hence, we built Manga109, a dataset consisting of a variety of 109 Japanese comic books (94 authors and 21,142 pages) and made it publicly available by obtaining author permissions for academic use. We carefully annotated the frames, speech texts, character faces, and character bodies; the total number of annotations exceeds 500k. This dataset provides numerous manga images and annotations, which will be beneficial for use in machine learning algorithms and their evaluation. In addition to academic use, we obtained further permission for a subset of the dataset for industrial use. In this article, we describe the details of the dataset and present a few examples of multimedia processing applications (detection, retrieval, and generation) that apply existing deep learning methods and are made possible by the dataset.
* 10 pages, 8 figures