 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Power Control for Cellular Systems with Heterogeneous Graph Neural Network
Nov 06, 2020
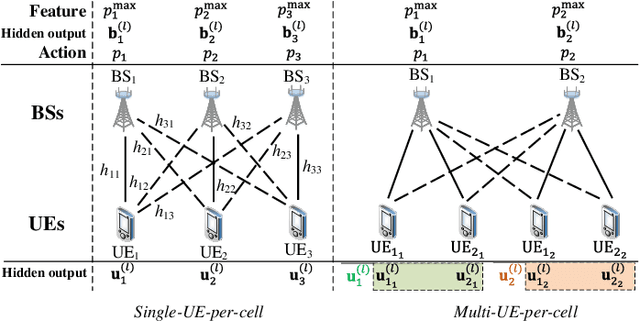
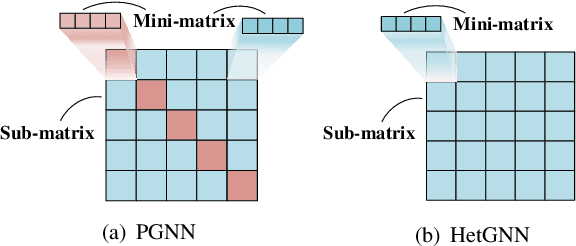
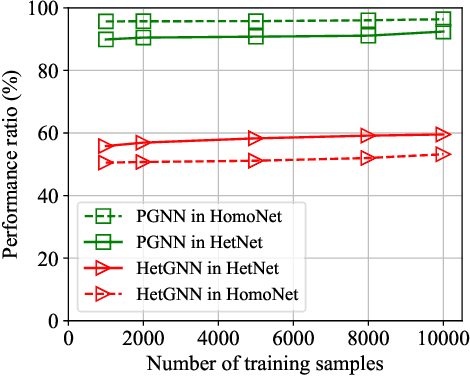
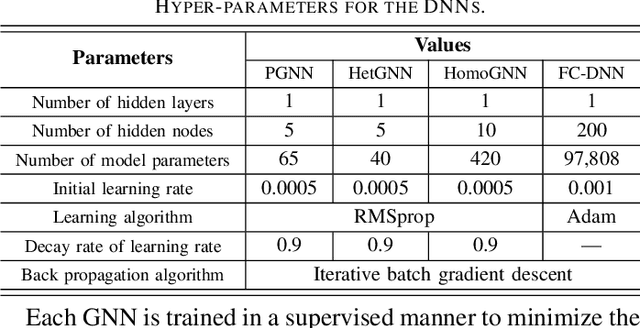
Optimizing power control in multi-cell cellular networks with deep learning enables such a non-convex problem to be implemented in real-time. When channels are time-varying, the deep neural networks (DNNs) need to be re-trained frequently, which calls for low training complexity. To reduce the number of training samples and the size of DNN required to achieve good performance, a promising approach is to embed the DNNs with priori knowledge. Since cellular networks can be modelled as a graph, it is natural to employ graph neural networks (GNNs) for learning, which exhibit permutation invariance (PI) and equivalence (PE) properties. Unlike the homogeneous GNNs that have been used for wireless problems, whose outputs are invariant or equivalent to arbitrary permutations of vertexes, heterogeneous GNNs (HetGNNs), which are more appropriate to model cellular networks, are only invariant or equivalent to some permutations. If the PI or PE properties of the HetGNN do not match the property of the task to be learned, the performance degrades dramatically. In this paper, we show that the power control policy has a combination of different PI and PE properties, and existing HetGNN does not satisfy these properties. We then design a parameter sharing scheme for HetGNN such that the learned relationship satisfies the desired properties. Simulation results show that the sample complexity and the size of designed GNN for learning the optimal power control policy in multi-user multi-cell networks are much lower than the existing DNNs, when achieving the same sum rate loss from the numerically obtained solutions.
A Sparse Sampling-based framework for Semantic Fast-Forward of First-Person Videos
Sep 21, 2020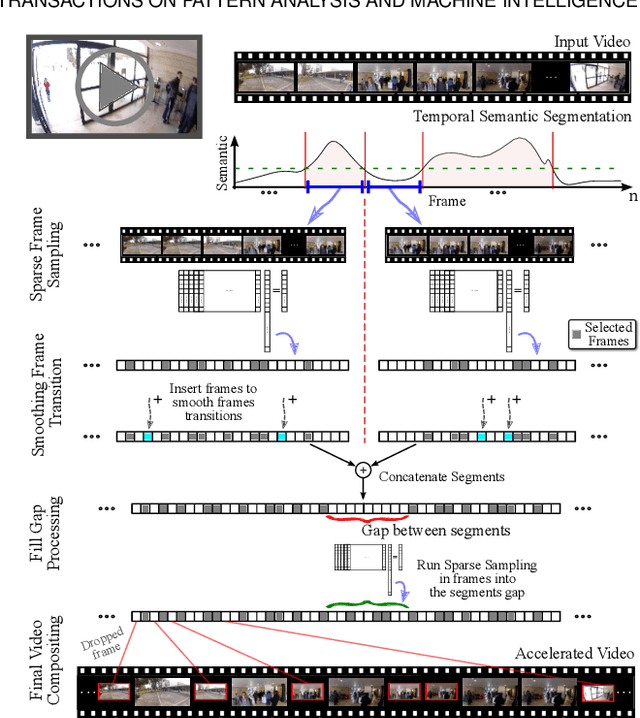
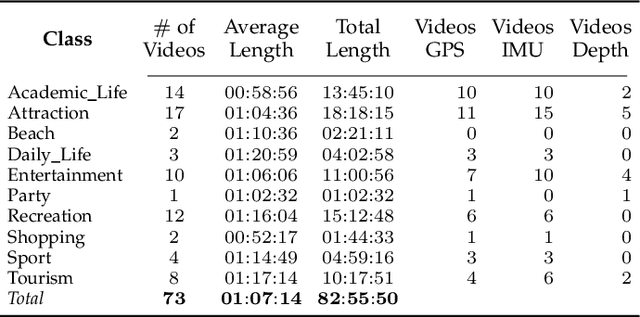
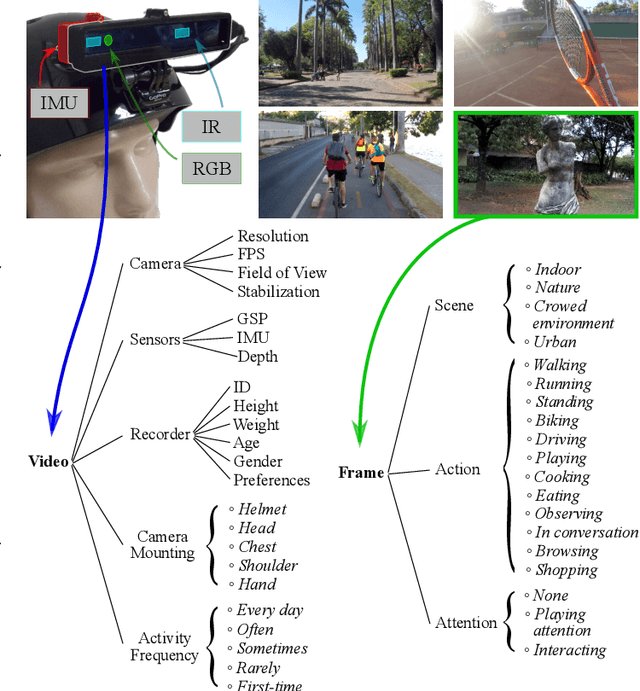
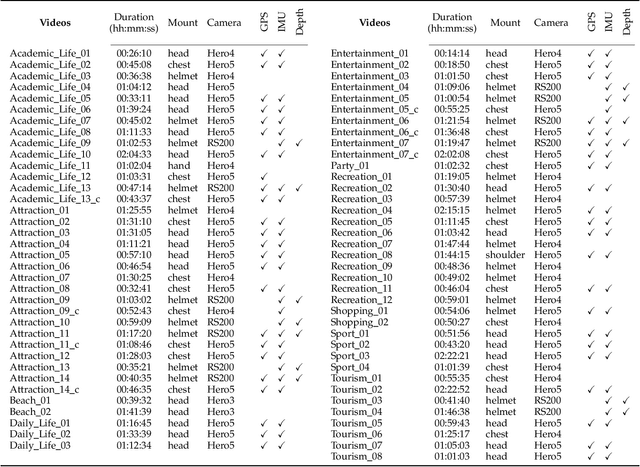
Technological advances in sensors have paved the way for digital cameras to become increasingly ubiquitous, which, in turn, led to the popularity of the self-recording culture. As a result, the amount of visual data on the Internet is moving in the opposite direction of the available time and patience of the users. Thus, most of the uploaded videos are doomed to be forgotten and unwatched stashed away in some computer folder or website. In this paper, we address the problem of creating smooth fast-forward videos without losing the relevant content. We present a new adaptive frame selection formulated as a weighted minimum reconstruction problem. Using a smoothing frame transition and filling visual gaps between segments, our approach accelerates first-person videos emphasizing the relevant segments and avoids visual discontinuities. Experiments conducted on controlled videos and also on an unconstrained dataset of First-Person Videos (FPVs) show that, when creating fast-forward videos, our method is able to retain as much relevant information and smoothness as the state-of-the-art techniques, but in less processing time.
Comparison of Model Predictive and Reinforcement Learning Methods for Fault Tolerant Control
Aug 10, 2020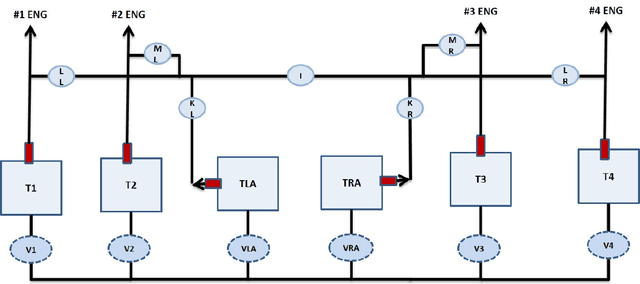

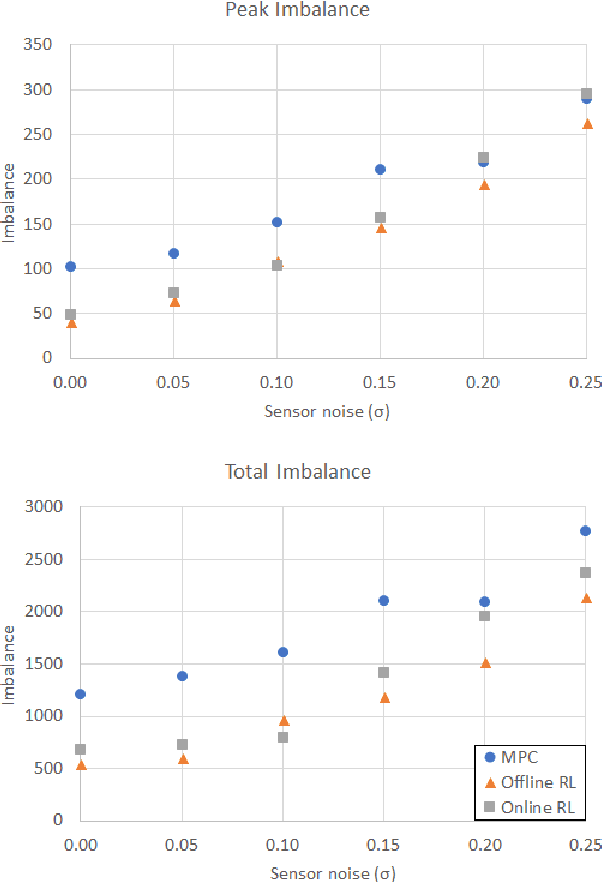

A desirable property in fault-tolerant controllers is adaptability to system changes as they evolve during systems operations. An adaptive controller does not require optimal control policies to be enumerated for possible faults. Instead it can approximate one in real-time. We present two adaptive fault-tolerant control schemes for a discrete time system based on hierarchical reinforcement learning. We compare their performance against a model predictive controller in presence of sensor noise and persistent faults. The controllers are tested on a fuel tank model of a C-130 plane. Our experiments demonstrate that reinforcement learning-based controllers perform more robustly than model predictive controllers under faults, partially observable system models, and varying sensor noise levels.
Finite Group Equivariant Neural Networks for Games
Sep 10, 2020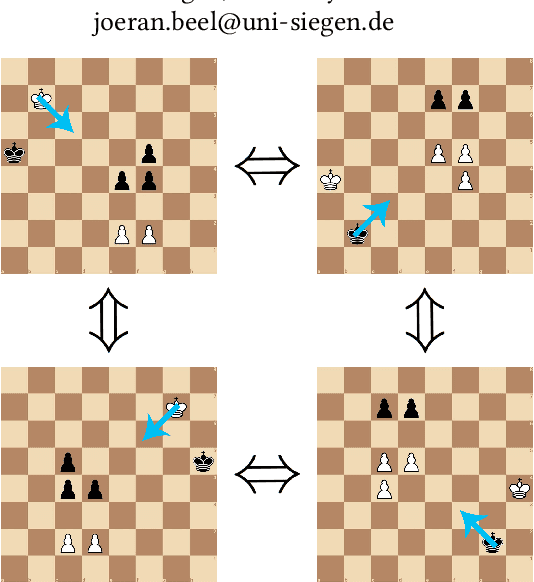
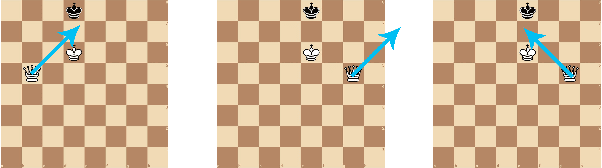
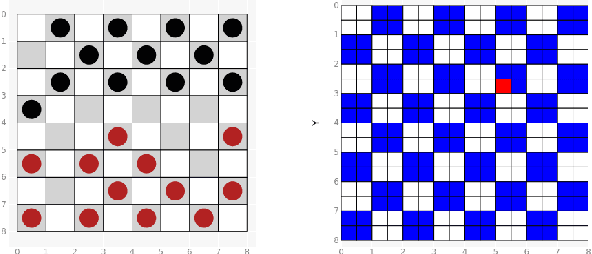
Games such as go, chess and checkers have multiple equivalent game states, i.e. multiple board positions where symmetrical and opposite moves should be made. These equivalences are not exploited by current state of the art neural agents which instead must relearn similar information, thereby wasting computing time. Group equivariant CNNs in existing work create networks which can exploit symmetries to improve learning, however, they lack the expressiveness to correctly reflect the move embeddings necessary for games. We introduce Finite Group Neural Networks (FGNNs), a method for creating agents with an innate understanding of these board positions. FGNNs are shown to improve the performance of networks playing checkers (draughts), and can be easily adapted to other games and learning problems. Additionally, FGNNs can be created from existing network architectures. These include, for the first time, those with skip connections and arbitrary layer types. We demonstrate that an equivariant version of U-Net (FGNN-U-Net) outperforms the unmodified network in image segmentation.
Do not repeat these mistakes -- a critical appraisal of applications of explainable artificial intelligence for image based COVID-19 detection
Dec 16, 2020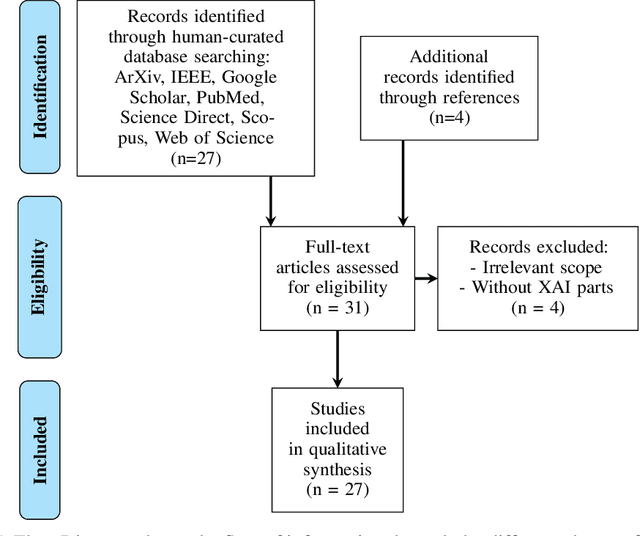
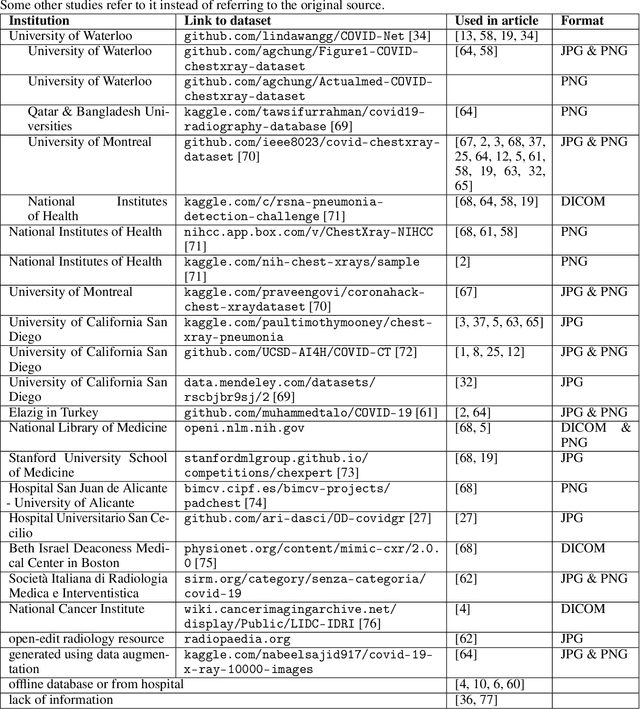
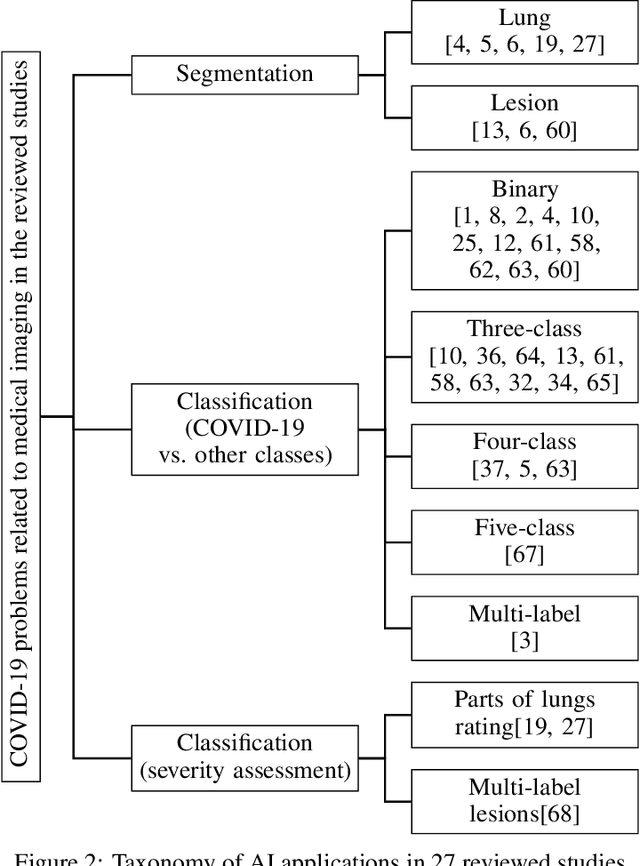
The sudden outbreak and uncontrolled spread of COVID-19 disease is one of the most important global problems today. In a short period of time, it has led to the development of many deep neural network models for COVID-19 detection with modules for explainability. In this work, we carry out a systematic analysis of various aspects of proposed models. Our analysis revealed numerous mistakes made at different stages of data acquisition, model development, and explanation construction. In this work, we overview the approaches proposed in the surveyed ML articles and indicate typical errors emerging from the lack of deep understanding of the radiography domain. We present the perspective of both: experts in the field - radiologists, and deep learning engineers dealing with model explanations. The final result is a proposed a checklist with the minimum conditions to be met by a reliable COVID-19 diagnostic model.
Full-Time Supervision based Bidirectional RNN for Factoid Question Answering
Jun 21, 2016
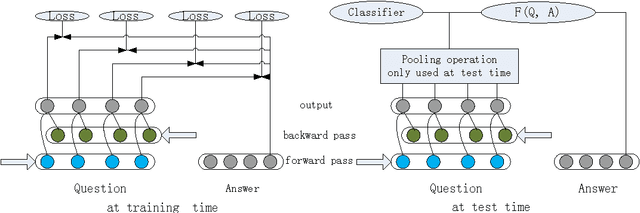
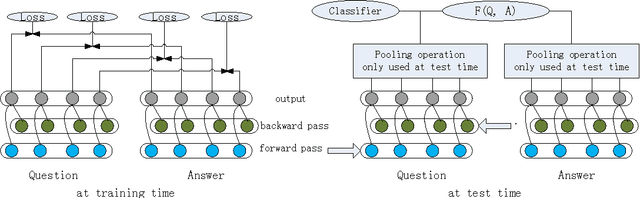

Recently, bidirectional recurrent neural network (BRNN) has been widely used for question answering (QA) tasks with promising performance. However, most existing BRNN models extract the information of questions and answers by directly using a pooling operation to generate the representation for loss or similarity calculation. Hence, these existing models don't put supervision (loss or similarity calculation) at every time step, which will lose some useful information. In this paper, we propose a novel BRNN model called full-time supervision based BRNN (FTS-BRNN), which can put supervision at every time step. Experiments on the factoid QA task show that our FTS-BRNN can outperform other baselines to achieve the state-of-the-art accuracy.
Deep Latent Variable Model for Longitudinal Group Factor Analysis
May 11, 2020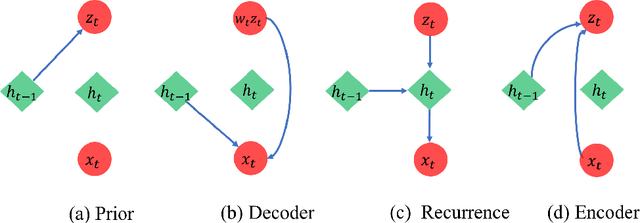
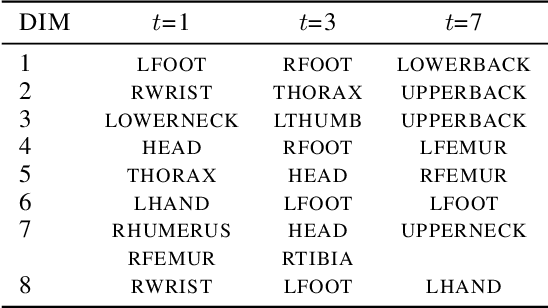
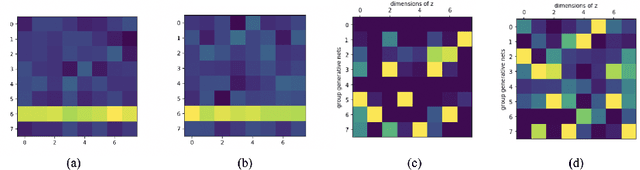

In many scientific problems such as video surveillance, modern genomic analysis, and clinical studies, data are often collected from diverse domains across time that exhibit time-dependent heterogeneous properties. It is important to not only integrate data from multiple sources (called multiview data), but also to incorporate time dependency for deep understanding of the underlying system. Latent factor models are popular tools for exploring multi-view data. However, it is frequently observed that these models do not perform well for complex systems and they are not applicable to time-series data. Therefore, we propose a generative model based on variational autoencoder and recurrent neural network to infer the latent dynamic factors for multivariate timeseries data. This approach allows us to identify the disentangled latent embeddings across multiple modalities while accounting for the time factor. We invoke our proposed model for analyzing three datasets on which we demonstrate the effectiveness and the interpretability of the model.
Uncertainty aware and explainable diagnosis of retinal disease
Jan 26, 2021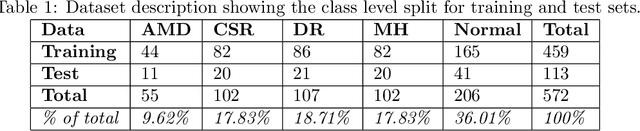
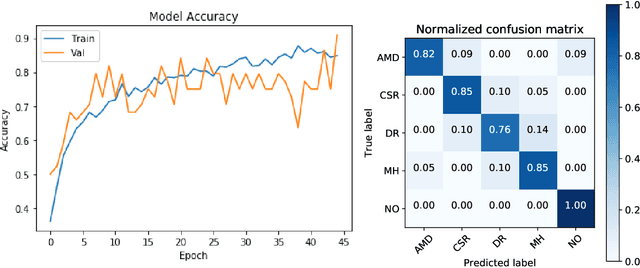
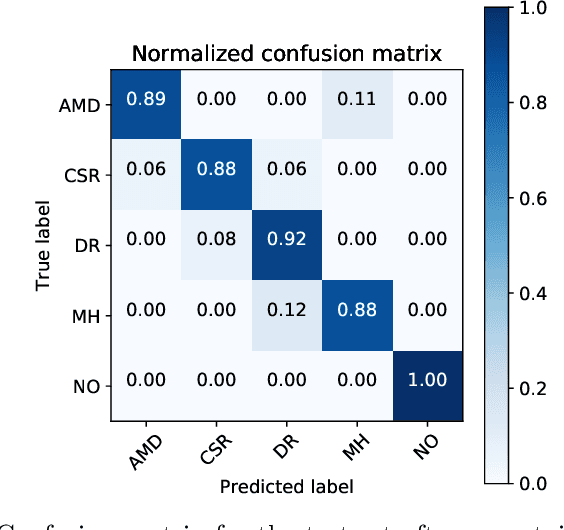
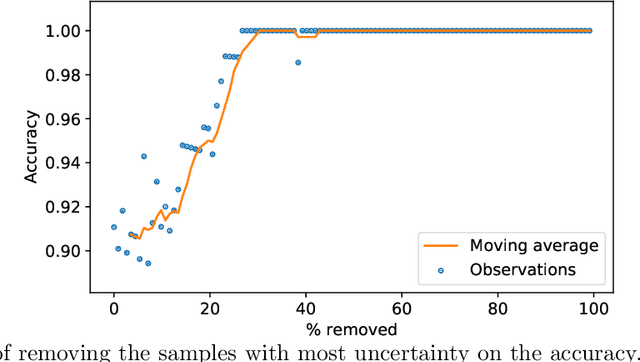
Deep learning methods for ophthalmic diagnosis have shown considerable success in tasks like segmentation and classification. However, their widespread application is limited due to the models being opaque and vulnerable to making a wrong decision in complicated cases. Explainability methods show the features that a system used to make prediction while uncertainty awareness is the ability of a system to highlight when it is not sure about the decision. This is one of the first studies using uncertainty and explanations for informed clinical decision making. We perform uncertainty analysis of a deep learning model for diagnosis of four retinal diseases - age-related macular degeneration (AMD), central serous retinopathy (CSR), diabetic retinopathy (DR), and macular hole (MH) using images from a publicly available (OCTID) dataset. Monte Carlo (MC) dropout is used at the test time to generate a distribution of parameters and the predictions approximate the predictive posterior of a Bayesian model. A threshold is computed using the distribution and uncertain cases can be referred to the ophthalmologist thus avoiding an erroneous diagnosis. The features learned by the model are visualized using a proven attribution method from a previous study. The effects of uncertainty on model performance and the relationship between uncertainty and explainability are discussed in terms of clinical significance. The uncertainty information along with the heatmaps make the system more trustworthy for use in clinical settings.
Short Text Classification Approach to Identify Child Sexual Exploitation Material
Nov 13, 2020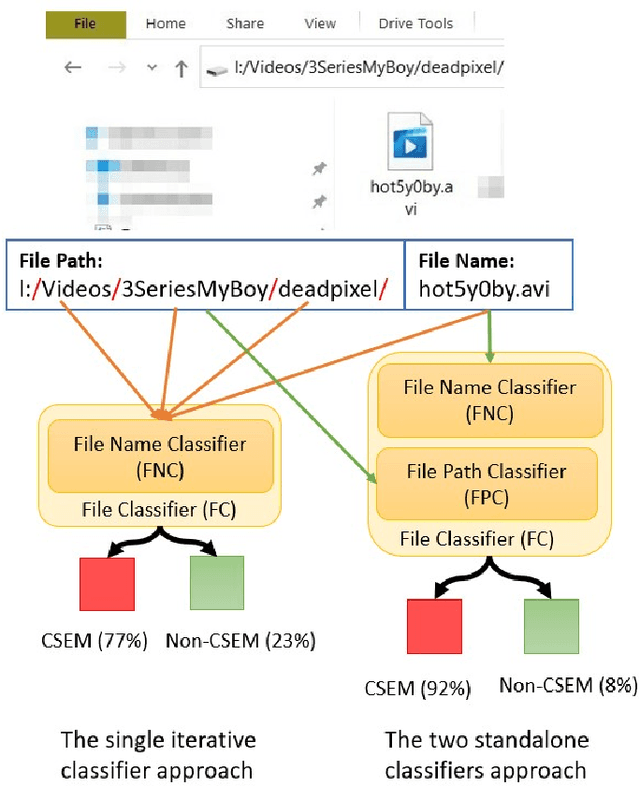
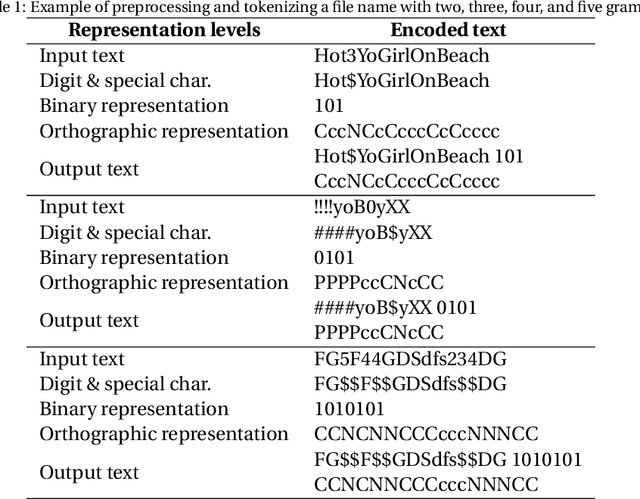
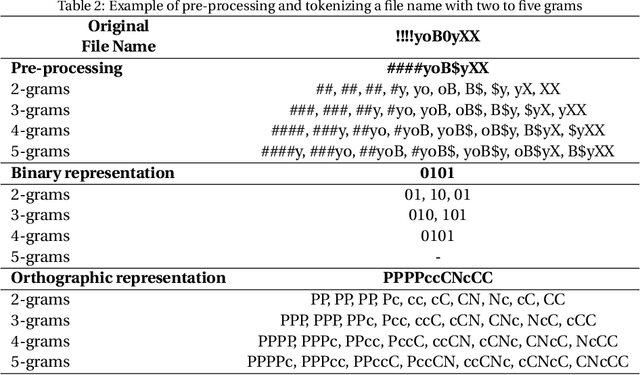

Producing or sharing Child Sexual Exploitation Material (CSEM) is a serious crime fought vigorously by Law Enforcement Agencies (LEAs). When an LEA seizes a computer from a potential producer or consumer of CSEM, they need to analyze the suspect's hard disk's files looking for pieces of evidence. However, a manual inspection of the file content looking for CSEM is a time-consuming task. In most cases, it is unfeasible in the amount of time available for the Spanish police using a search warrant. Instead of analyzing its content, another approach that can be used to speed up the process is to identify CSEM by analyzing the file names and their absolute paths. The main challenge for this task lies behind dealing with short text distorted deliberately by the owners of this material using obfuscated words and user-defined naming patterns. This paper presents and compares two approaches based on short text classification to identify CSEM files. The first one employs two independent supervised classifiers, one for the file name and the other for the path, and their outputs are later on fused into a single score. Conversely, the second approach uses only the file name classifier to iterate over the file's absolute path. Both approaches operate at the character n-grams level, while binary and orthographic features enrich the file name representation, and a binary Logistic Regression model is used for classification. The presented file classifier achieved an average class recall of 0.98. This solution could be integrated into forensic tools and services to support Law Enforcement Agencies to identify CSEM without tackling every file's visual content, which is computationally much more highly demanding.
Deep Reinforcement Learning Optimizes Graphene Nanopores for Efficient Desalination
Jan 19, 2021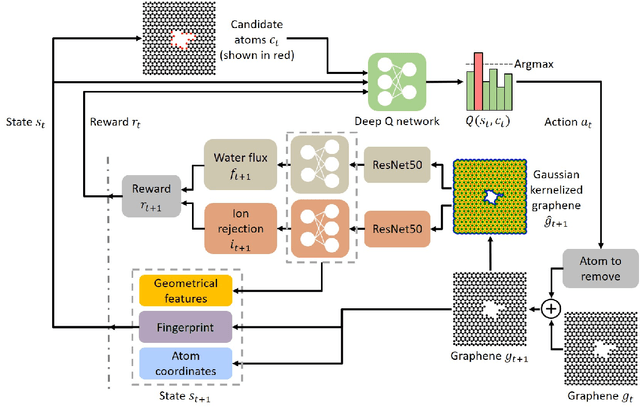
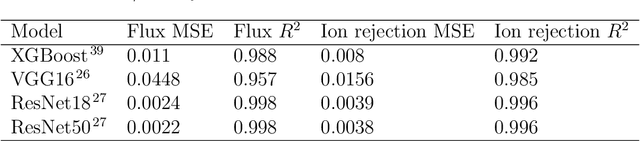
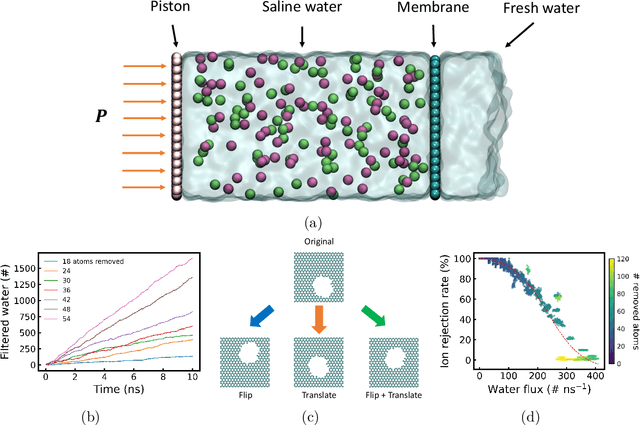
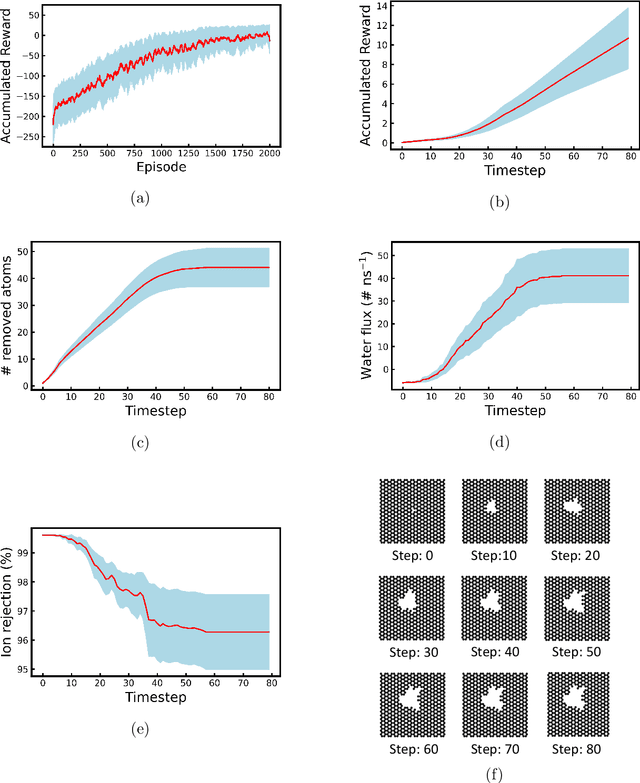
Two-dimensional nanomaterials, such as graphene, have been extensively studied because of their outstanding physical properties. Structure and geometry optimization of nanopores on such materials is beneficial for their performances in real-world engineering applications, like water desalination. However, the optimization process often involves very large number of experiments or simulations which are expensive and time-consuming. In this work, we propose a graphene nanopore optimization framework via the combination of deep reinforcement learning (DRL) and convolutional neural network (CNN) for efficient water desalination. The DRL agent controls the growth of nanopore by determining the atom to be removed at each timestep, while the CNN predicts the performance of nanoporus graphene for water desalination: the water flux and ion rejection at a certain external pressure. With the synchronous feedback from CNN-accelerated desalination performance prediction, our DRL agent can optimize the nanoporous graphene efficiently in an online manner. Molecular dynamics (MD) simulations on promising DRL-designed graphene nanopores show that they have higher water flux while maintaining rival ion rejection rate compared to the normal circular nanopores. Semi-oval shape with rough edges geometry of DRL-designed pores is found to be the key factor for their high water desalination performance. Ultimately, this study shows that DRL can be a powerful tool for material design.