 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescribing image focused in cognitive and visual details for visually impaired people: An approach to generating inclusive paragraphs
Feb 15, 2022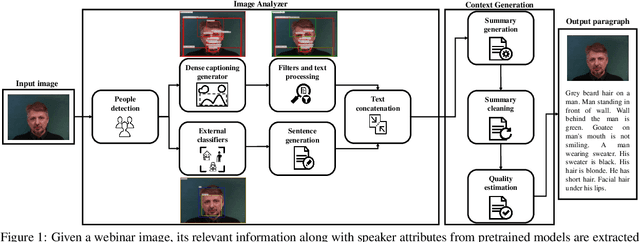

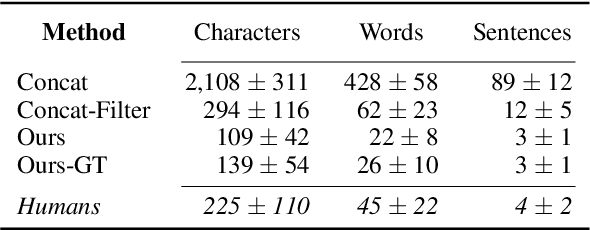

Several services for people with visual disabilities have emerged recently due to achievements in Assistive Technologies and Artificial Intelligence areas. Despite the growth in assistive systems availability, there is a lack of services that support specific tasks, such as understanding the image context presented in online content, e.g., webinars. Image captioning techniques and their variants are limited as Assistive Technologies as they do not match the needs of visually impaired people when generating specific descriptions. We propose an approach for generating context of webinar images combining a dense captioning technique with a set of filters, to fit the captions in our domain, and a language model for the abstractive summary task. The results demonstrated that we can produce descriptions with higher interpretability and focused on the relevant information for that group of people by combining image analysis methods and neural language models.
A Sparse Sampling-based framework for Semantic Fast-Forward of First-Person Videos
Sep 21, 2020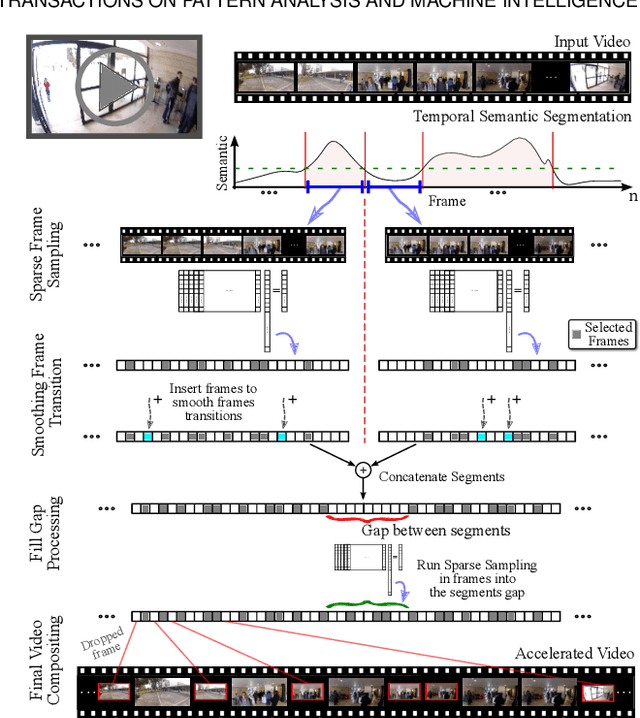
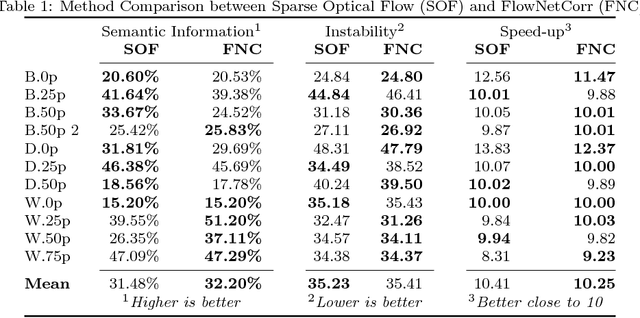
Technological advances in sensors have paved the way for digital cameras to become increasingly ubiquitous, which, in turn, led to the popularity of the self-recording culture. As a result, the amount of visual data on the Internet is moving in the opposite direction of the available time and patience of the users. Thus, most of the uploaded videos are doomed to be forgotten and unwatched stashed away in some computer folder or website. In this paper, we address the problem of creating smooth fast-forward videos without losing the relevant content. We present a new adaptive frame selection formulated as a weighted minimum reconstruction problem. Using a smoothing frame transition and filling visual gaps between segments, our approach accelerates first-person videos emphasizing the relevant segments and avoids visual discontinuities. Experiments conducted on controlled videos and also on an unconstrained dataset of First-Person Videos (FPVs) show that, when creating fast-forward videos, our method is able to retain as much relevant information and smoothness as the state-of-the-art techniques, but in less processing time.
A gaze driven fast-forward method for first-person videos
Jun 10, 2020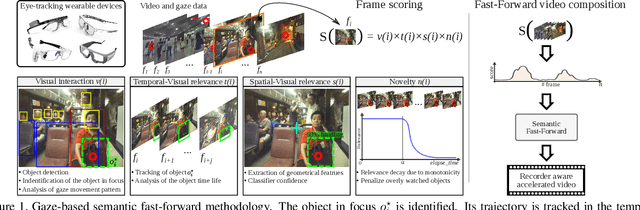
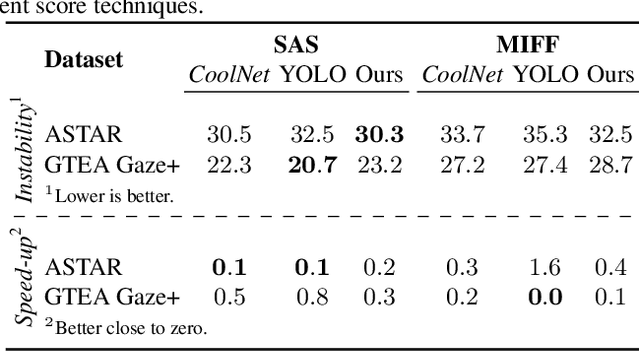
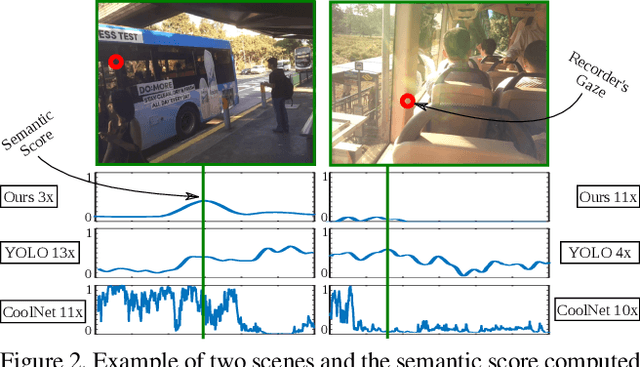
The growing data sharing and life-logging cultures are driving an unprecedented increase in the amount of unedited First-Person Videos. In this paper, we address the problem of accessing relevant information in First-Person Videos by creating an accelerated version of the input video and emphasizing the important moments to the recorder. Our method is based on an attention model driven by gaze and visual scene analysis that provides a semantic score of each frame of the input video. We performed several experimental evaluations on publicly available First-Person Videos datasets. The results show that our methodology can fast-forward videos emphasizing moments when the recorder visually interact with scene components while not including monotonous clips.
A Weighted Sparse Sampling and Smoothing Frame Transition Approach for Semantic Fast-Forward First-Person Videos
Mar 13, 2018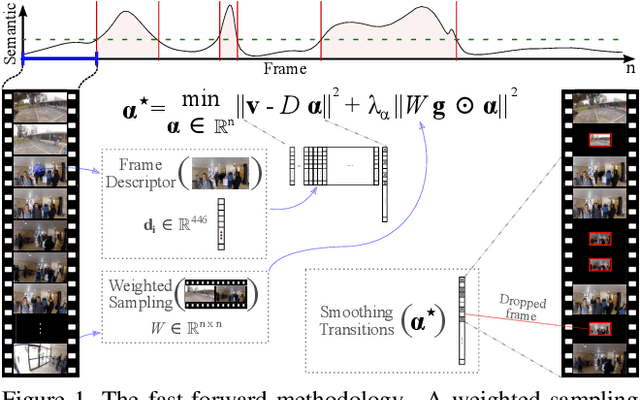
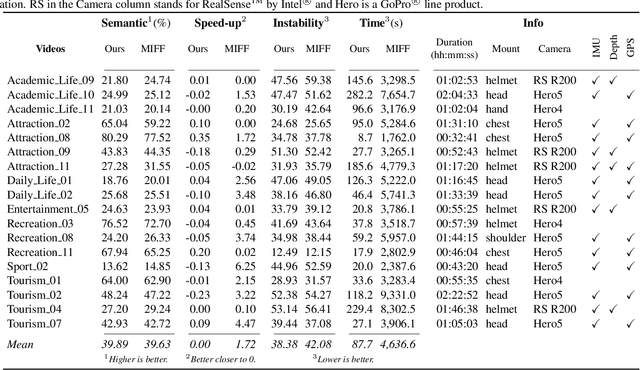
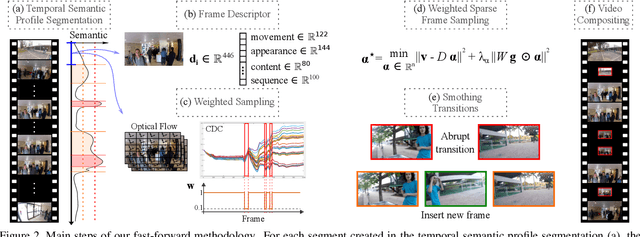

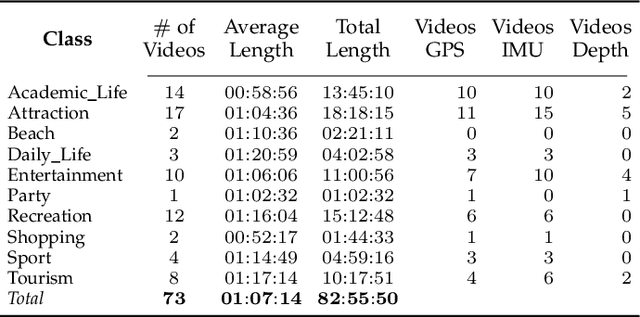
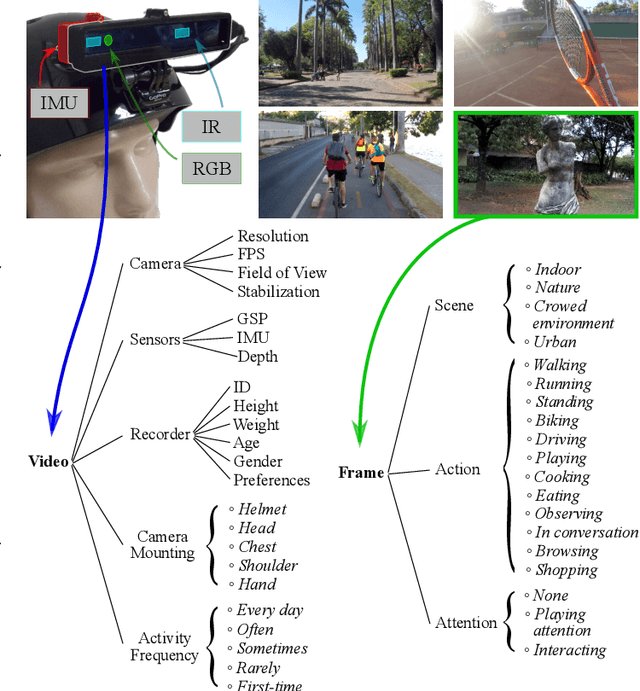
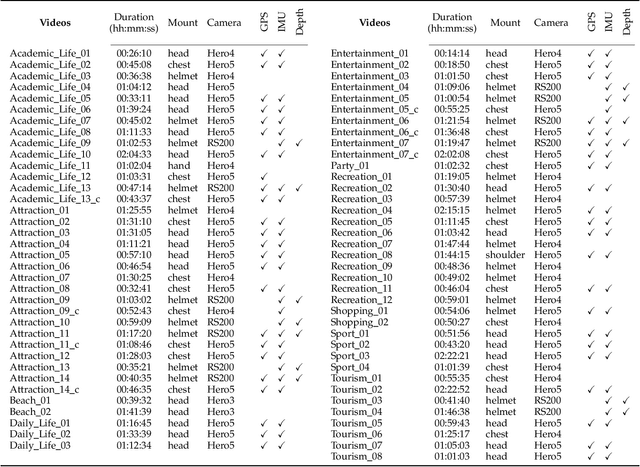
Thanks to the advances in the technology of low-cost digital cameras and the popularity of the self-recording culture, the amount of visual data on the Internet is going to the opposite side of the available time and patience of the users. Thus, most of the uploaded videos are doomed to be forgotten and unwatched in a computer folder or website. In this work, we address the problem of creating smooth fast-forward videos without losing the relevant content. We present a new adaptive frame selection formulated as a weighted minimum reconstruction problem, which combined with a smoothing frame transition method accelerates first-person videos emphasizing the relevant segments and avoids visual discontinuities. The experiments show that our method is able to fast-forward videos to retain as much relevant information and smoothness as the state-of-the-art techniques in less time. We also present a new 80-hour multimodal (RGB-D, IMU, and GPS) dataset of first-person videos with annotations for recorder profile, frame scene, activities, interaction, and attention.
Making a long story short: A Multi-Importance fast-forwarding egocentric videos with the emphasis on relevant objects
Mar 07, 2018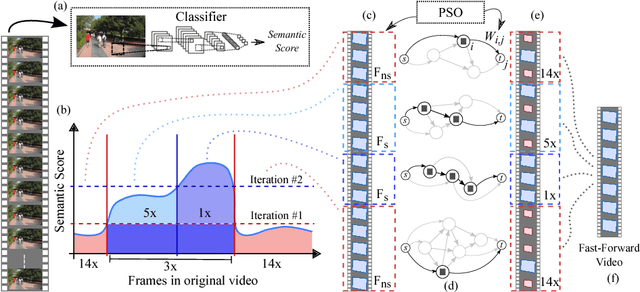

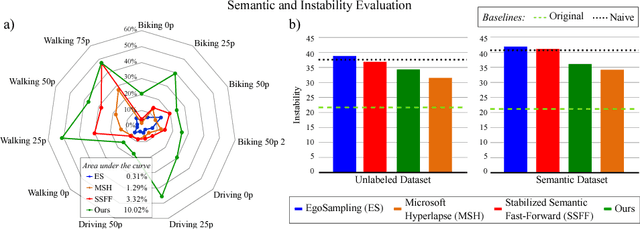
The emergence of low-cost high-quality personal wearable cameras combined with the increasing storage capacity of video-sharing websites have evoked a growing interest in first-person videos, since most videos are composed of long-running unedited streams which are usually tedious and unpleasant to watch. State-of-the-art semantic fast-forward methods currently face the challenge of providing an adequate balance between smoothness in visual flow and the emphasis on the relevant parts. In this work, we present the Multi-Importance Fast-Forward (MIFF), a fully automatic methodology to fast-forward egocentric videos facing these challenges. The dilemma of defining what is the semantic information of a video is addressed by a learning process based on the preferences of the user. Results show that the proposed method keeps over $3$ times more semantic content than the state-of-the-art fast-forward. Finally, we discuss the need of a particular video stabilization technique for fast-forward egocentric videos.
Towards Semantic Fast-Forward and Stabilized Egocentric Videos
Aug 16, 2017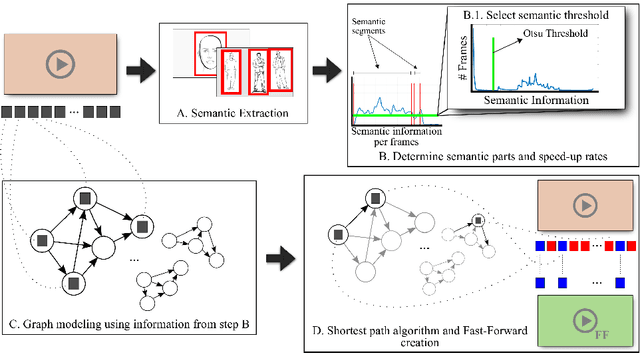
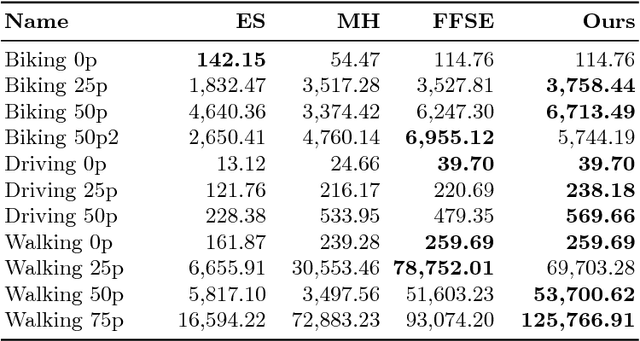
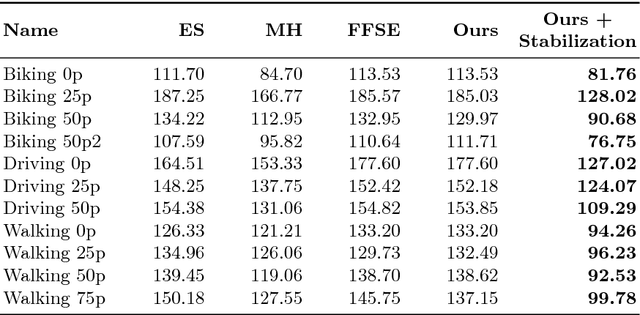
The emergence of low-cost personal mobiles devices and wearable cameras and the increasing storage capacity of video-sharing websites have pushed forward a growing interest towards first-person videos. Since most of the recorded videos compose long-running streams with unedited content, they are tedious and unpleasant to watch. The fast-forward state-of-the-art methods are facing challenges of balancing the smoothness of the video and the emphasis in the relevant frames given a speed-up rate. In this work, we present a methodology capable of summarizing and stabilizing egocentric videos by extracting the semantic information from the frames. This paper also describes a dataset collection with several semantically labeled videos and introduces a new smoothness evaluation metric for egocentric videos that is used to test our method.
Fast-Forward Video Based on Semantic Extraction
Aug 16, 2017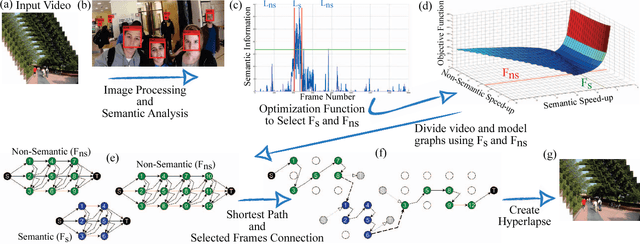
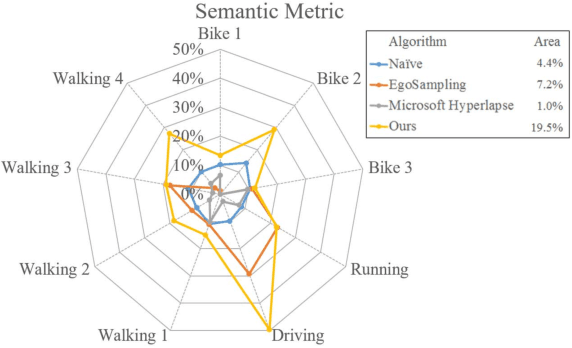
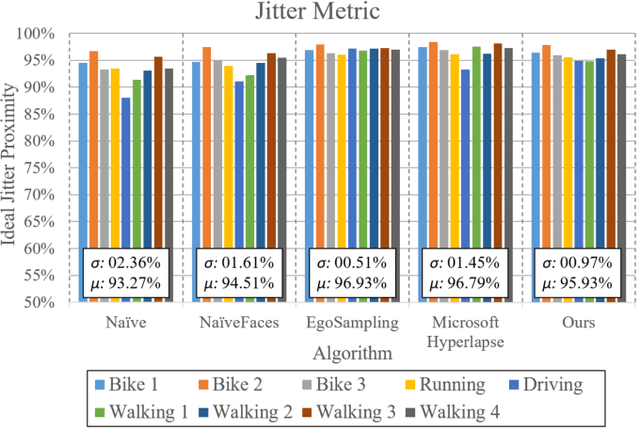
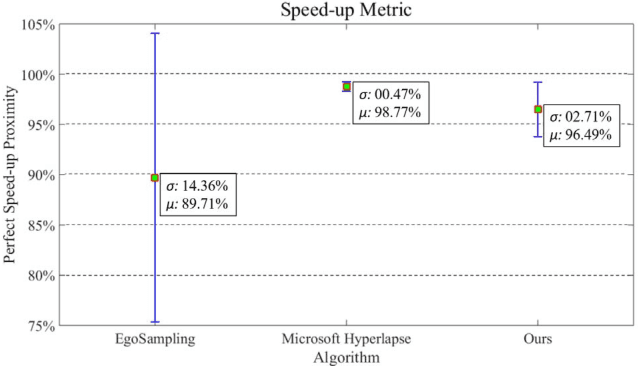
Thanks to the low operational cost and large storage capacity of smartphones and wearable devices, people are recording many hours of daily activities, sport actions and home videos. These videos, also known as egocentric videos, are generally long-running streams with unedited content, which make them boring and visually unpalatable, bringing up the challenge to make egocentric videos more appealing. In this work we propose a novel methodology to compose the new fast-forward video by selecting frames based on semantic information extracted from images. The experiments show that our approach outperforms the state-of-the-art as far as semantic information is concerned and that it is also able to produce videos that are more pleasant to be watched.