 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
xERTE: Explainable Reasoning on Temporal Knowledge Graphs for Forecasting Future Links
Jan 18, 2021
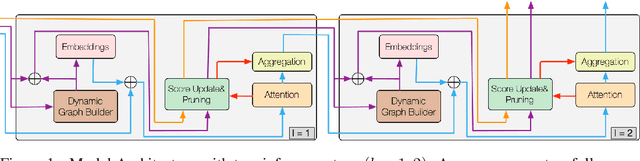
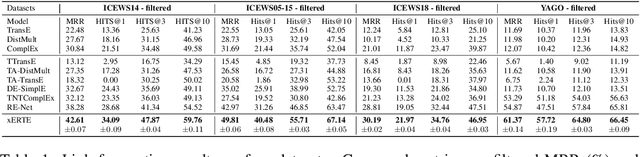
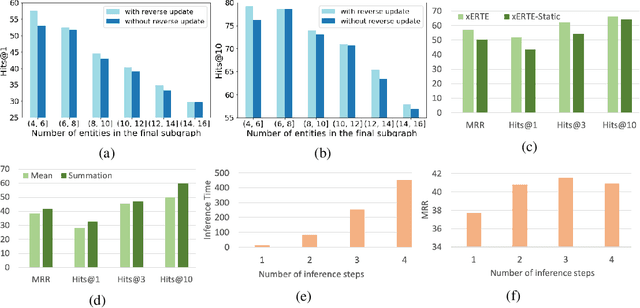
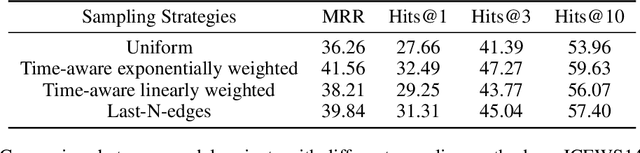
Interest has been rising lately towards modeling time-evolving knowledge graphs (KGs). Recently, graph representation learning approaches have become the dominant paradigm for link prediction on temporal KGs. However, the embedding-based approaches largely operate in a black-box fashion, lacking the ability to judge the results' reliability. This paper provides a future link forecasting framework that reasons over query-relevant subgraphs of temporal KGs and jointly models the graph structures and the temporal context information. Especially, we propose a temporal relational attention mechanism and a novel reverse representation update scheme to guide the extraction of an enclosing subgraph around the query. The subgraph is expanded by an iterative sampling of temporal neighbors and attention propagation. As a result, our approach provides human-understandable arguments for the prediction. We evaluate our model on four benchmark temporal knowledge graphs for the link forecasting task. While being more explainable, our model also obtains a relative improvement of up to 17.7 $\%$ on MRR compared to the previous best KG forecasting methods. We also conduct a survey with 53 respondents, and the results show that the reasoning arguments extracted by the model for link forecasting are aligned with human understanding.
The Effect of Class Definitions on the Transferability of Adversarial Attacks Against Forensic CNNs
Jan 26, 2021
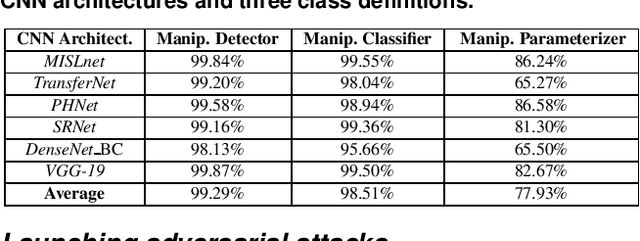
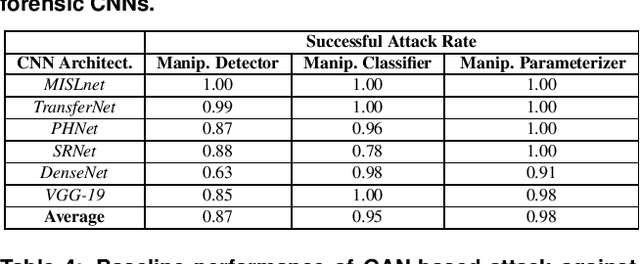
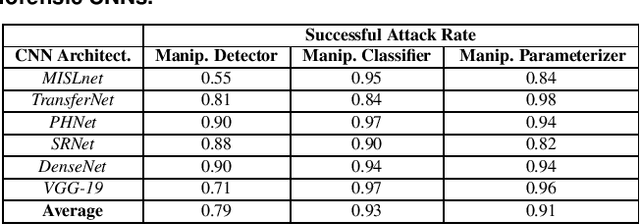
In recent years, convolutional neural networks (CNNs) have been widely used by researchers to perform forensic tasks such as image tampering detection. At the same time, adversarial attacks have been developed that are capable of fooling CNN-based classifiers. Understanding the transferability of adversarial attacks, i.e. an attacks ability to attack a different CNN than the one it was trained against, has important implications for designing CNNs that are resistant to attacks. While attacks on object recognition CNNs are believed to be transferrable, recent work by Barni et al. has shown that attacks on forensic CNNs have difficulty transferring to other CNN architectures or CNNs trained using different datasets. In this paper, we demonstrate that adversarial attacks on forensic CNNs are even less transferrable than previously thought even between virtually identical CNN architectures! We show that several common adversarial attacks against CNNs trained to identify image manipulation fail to transfer to CNNs whose only difference is in the class definitions (i.e. the same CNN architectures trained using the same data). We note that all formulations of class definitions contain the unaltered class. This has important implications for the future design of forensic CNNs that are robust to adversarial and anti-forensic attacks.
Augmenting Neural Differential Equations to Model Unknown Dynamical Systems with Incomplete State Information
Aug 22, 2020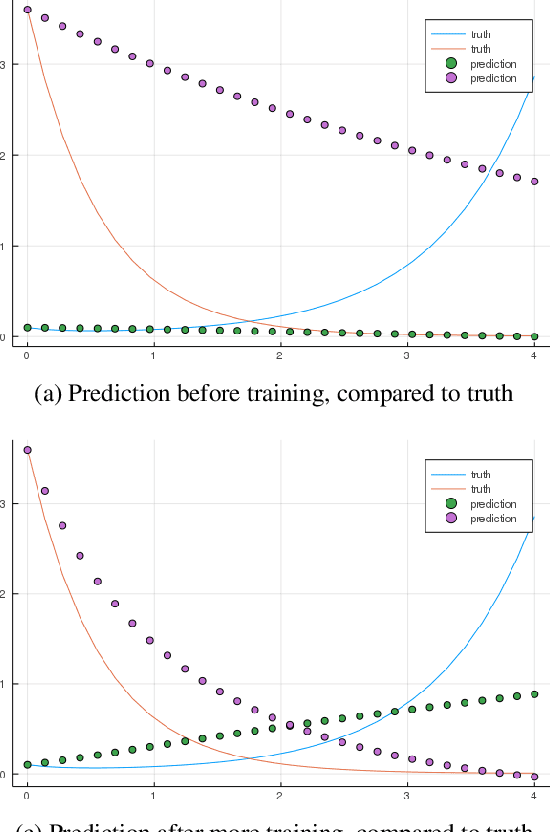
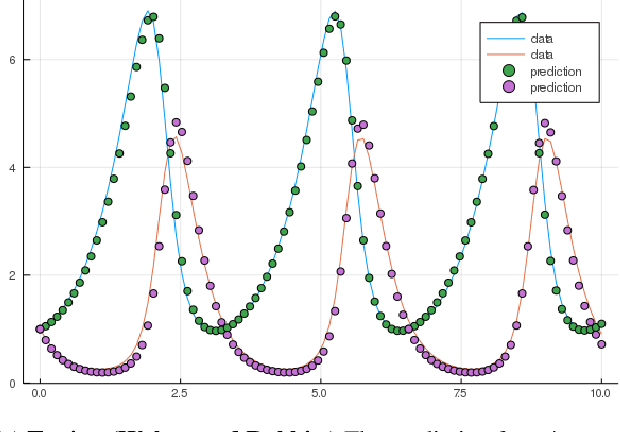
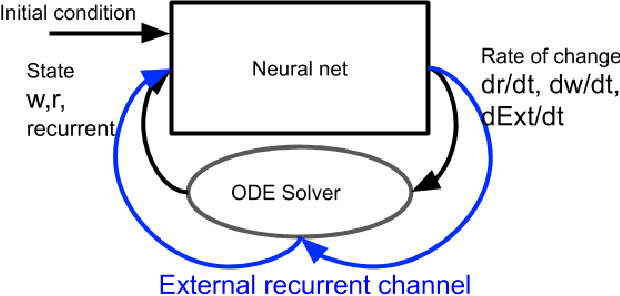
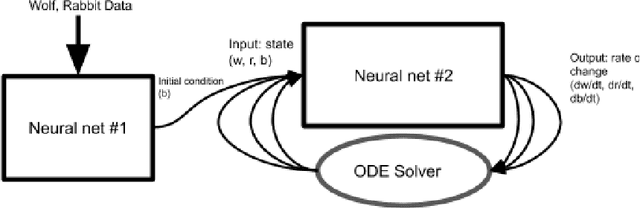
Neural Ordinary Differential Equations replace the right-hand side of a conventional ODE with a neural net, which by virtue of the universal approximation theorem, can be trained to the representation of any function. When we do not know the function itself, but have state trajectories (time evolution) of the ODE system we can still train the neural net to learn the representation of the underlying but unknown ODE. However if the state of the system is incompletely known then the right-hand side of the ODE cannot be calculated. The derivatives to propagate the system are unavailable. We show that a specially augmented Neural ODE can learn the system when given incomplete state information. As a worked example we apply neural ODEs to the Lotka-Voltera problem of 3 species, rabbits, wolves, and bears. We show that even when the data for the bear time series is removed the remaining time series of the rabbits and wolves is sufficient to learn the dynamical system despite the missing the incomplete state information. This is surprising since a conventional ODE system cannot output the correct derivatives without the full state as the input. We implement augmented neural ODEs and differential equation solvers in the julia programming language.
SCA-Net: A Self-Correcting Two-Layer Autoencoder for Hyper-spectral Unmixing
Feb 10, 2021
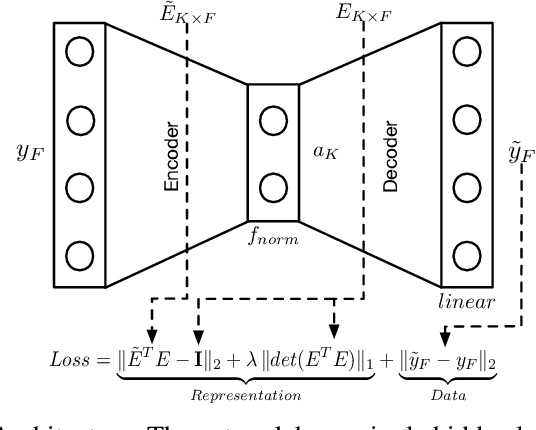
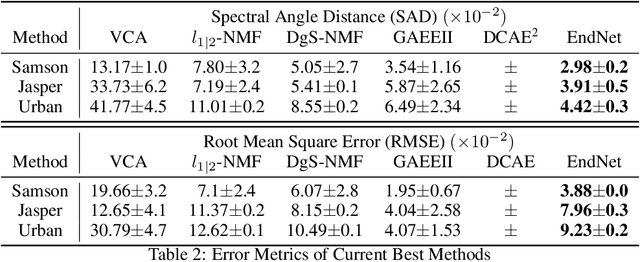
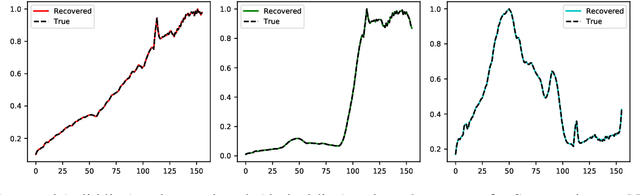
Linear Mixture Model for hyperspectral datasets involves separating a mixed pixel as a linear combination of its constituent endmembers and corresponding fractional abundances. Both optimization and neural methods have attempted to tackle this problem, with the current state of the art results achieved by neural models on benchmark datasets. However, our review of these neural models show that these networks are severely over-parameterized and consequently the invariant endmember spectra extracted as decoder weights has a high variance over multiple runs. All of these approaches require substantial post-processing to satisfy LMM constraints. Furthermore, they also require an exact specification of the number of endmembers and specialized initialization of weights from other algorithms like VCA. Our work shows for the first time that a two-layer autoencoder (SCA-Net), with $2FK$ parameters ($F$ features, $K$ endmembers), achieves error metrics that are scales apart ($10^{-5})$ from previously reported values $(10^{-2})$. SCA-Net converges to this low error solution starting from a random initialization of weights. We also show that SCA-Net, based upon a bi-orthogonal representation, performs a self-correction when the the number of endmembers are over-specified. We show that our network formulation extracts a low-rank representation that is bounded below by a tail-energy and can be computationally verified. Our numerical experiments on Samson, Jasper, and Urban datasets demonstrate that SCA-Net outperforms previously reported error metrics for all the cases while being robust to noise and outliers.
Factorization of Fact-Checks for Low Resource Indian Languages
Feb 23, 2021
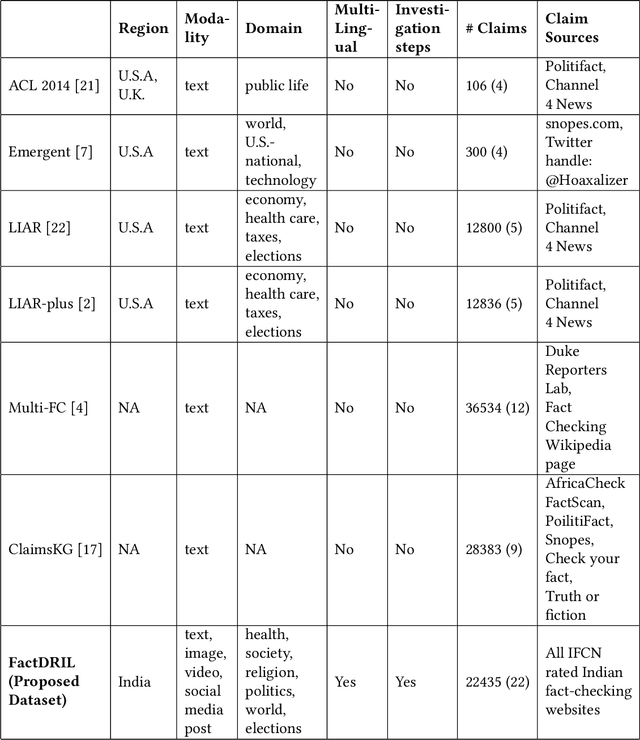

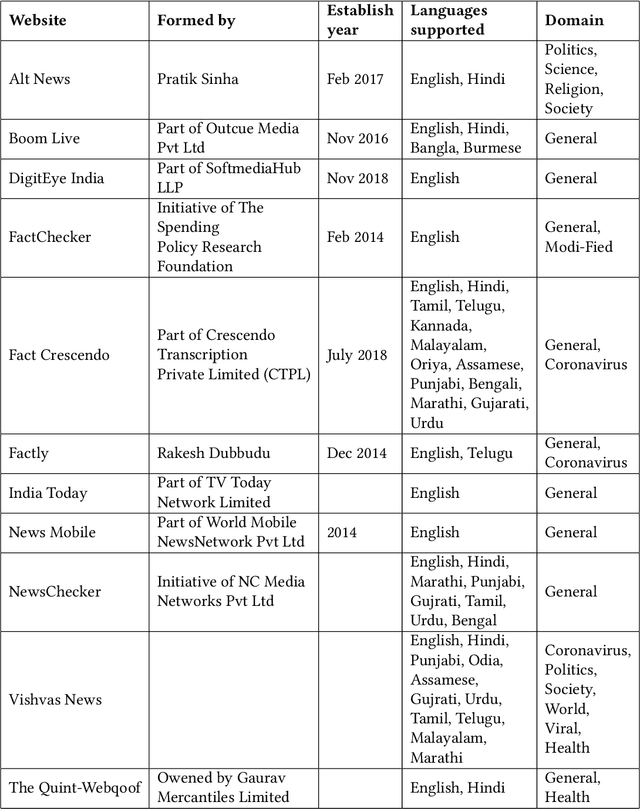
The advancement in technology and accessibility of internet to each individual is revolutionizing the real time information. The liberty to express your thoughts without passing through any credibility check is leading to dissemination of fake content in the ecosystem. It can have disastrous effects on both individuals and society as a whole. The amplification of fake news is becoming rampant in India too. Debunked information often gets republished with a replacement description, claiming it to depict some different incidence. To curb such fabricated stories, it is necessary to investigate such deduplicates and false claims made in public. The majority of studies on automatic fact-checking and fake news detection is restricted to English only. But for a country like India where only 10% of the literate population speak English, role of regional languages in spreading falsity cannot be undermined. In this paper, we introduce FactDRIL: the first large scale multilingual Fact-checking Dataset for Regional Indian Languages. We collect an exhaustive dataset across 7 months covering 11 low-resource languages. Our propose dataset consists of 9,058 samples belonging to English, 5,155 samples to Hindi and remaining 8,222 samples are distributed across various regional languages, i.e. Bangla, Marathi, Malayalam, Telugu, Tamil, Oriya, Assamese, Punjabi, Urdu, Sinhala and Burmese. We also present the detailed characterization of three M's (multi-lingual, multi-media, multi-domain) in the FactDRIL accompanied with the complete list of other varied attributes making it a unique dataset to study. Lastly, we present some potential use cases of the dataset. We expect this dataset will be a valuable resource and serve as a starting point to fight proliferation of fake news in low resource languages.
A Style-Aware Content Loss for Real-time HD Style Transfer
Jul 28, 2018


Recently, style transfer has received a lot of attention. While much of this research has aimed at speeding up processing, the approaches are still lacking from a principled, art historical standpoint: a style is more than just a single image or an artist, but previous work is limited to only a single instance of a style or shows no benefit from more images. Moreover, previous work has relied on a direct comparison of art in the domain of RGB images or on CNNs pre-trained on ImageNet, which requires millions of labeled object bounding boxes and can introduce an extra bias, since it has been assembled without artistic consideration. To circumvent these issues, we propose a style-aware content loss, which is trained jointly with a deep encoder-decoder network for real-time, high-resolution stylization of images and videos. We propose a quantitative measure for evaluating the quality of a stylized image and also have art historians rank patches from our approach against those from previous work. These and our qualitative results ranging from small image patches to megapixel stylistic images and videos show that our approach better captures the subtle nature in which a style affects content.
Enhash: A Fast Streaming Algorithm For Concept Drift Detection
Nov 07, 2020

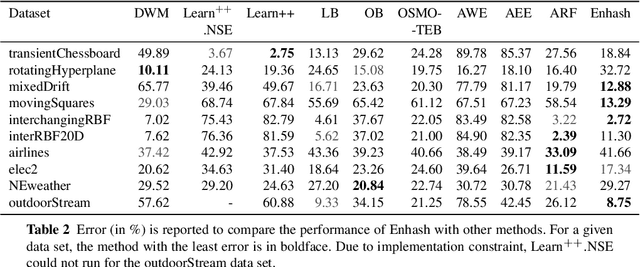
We propose Enhash, a fast ensemble learner that detects \textit{concept drift} in a data stream. A stream may consist of abrupt, gradual, virtual, or recurring events, or a mixture of various types of drift. Enhash employs projection hash to insert an incoming sample. We show empirically that the proposed method has competitive performance to existing ensemble learners in much lesser time. Also, Enhash has moderate resource requirements. Experiments relevant to performance comparison were performed on 6 artificial and 4 real data sets consisting of various types of drifts.
Evolution of Small Cell from 4G to 6G: Past, Present, and Future
Dec 29, 2020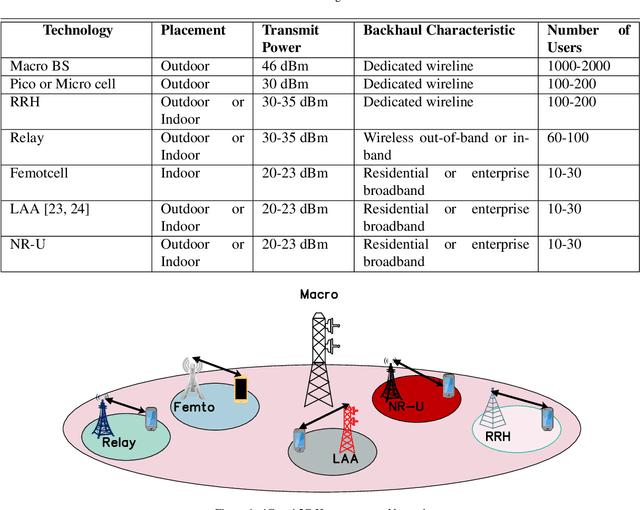

To boost the capacity of the cellular system, the operators have started to reuse the same licensed spectrum by deploying 4G LTE small cells (Femto Cells) in the past. But in time, these small cell licensed spectrum is not sufficient to satisfy future applications like augmented reality (AR)and virtual reality (VR). Hence, cellular operators look for alternate unlicensed spectrum in Wi-Fi 5 GHz band, later 3GPP named as LTE Licensed Assisted Access (LAA). The recent and current rollout of LAA deployments (in developed nations like the US) provides an opportunity to understand coexistence profound ground truth. This paper discusses a high-level overview of my past, present, and future research works in the direction of small cell benefits. In the future, we shift the focus onto the latest unlicensed band: 6 GHz, where the latest Wi-Fi version, 802.11ax, will coexist with the latest cellular technology, 5G New Radio(NR) in unlicensed
The Diabetic Buddy: A Diet Regulator andTracking System for Diabetics
Jan 08, 2021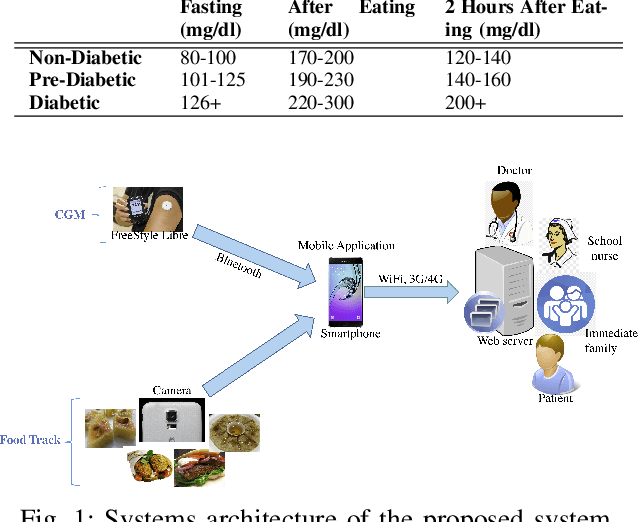
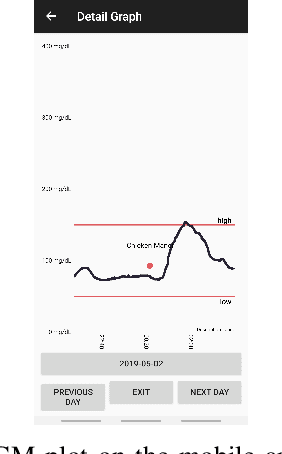
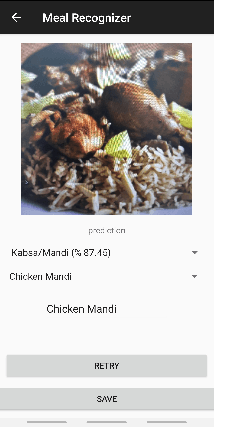
The prevalence of Diabetes mellitus (DM) in the Middle East is exceptionally high as compared to the rest of the world. In fact, the prevalence of diabetes in the Middle East is 17-20%, which is well above the global average of 8-9%. Research has shown that food intake has strong connections with the blood glucose levels of a patient. In this regard, there is a need to build automatic tools to monitor the blood glucose levels of diabetics and their daily food intake. This paper presents an automatic way of tracking continuous glucose and food intake of diabetics using off-the-shelf sensors and machine learning, respectively. Our system not only helps diabetics to track their daily food intake but also assists doctors to analyze the impact of the food in-take on blood glucose in real-time. For food recognition, we collected a large-scale Middle-Eastern food dataset and proposed a fusion-based framework incorporating several existing pre-trained deep models for Middle-Eastern food recognition.
GEBT: Drawing Early-Bird Tickets in Graph Convolutional Network Training
Mar 01, 2021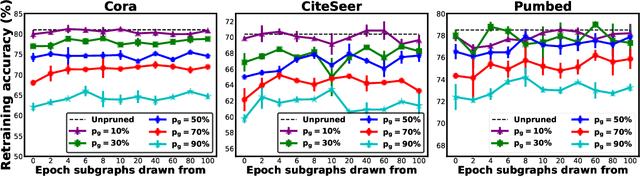
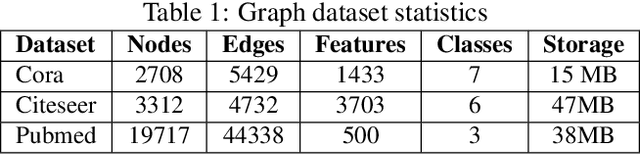
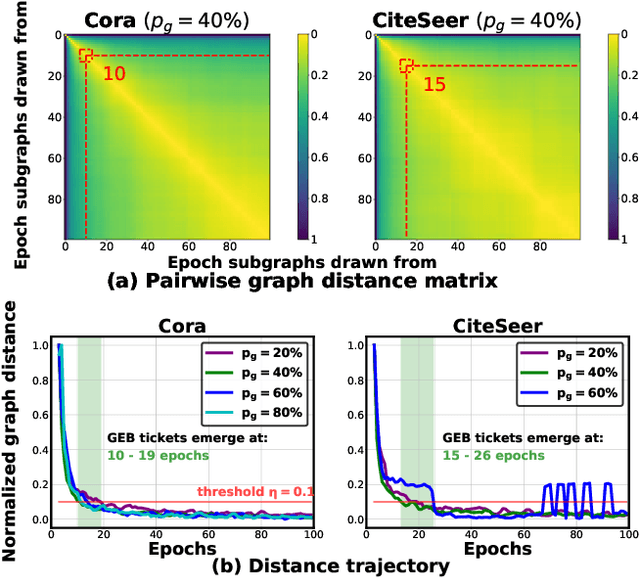
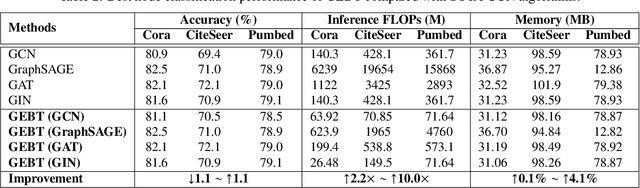
Graph Convolutional Networks (GCNs) have emerged as the state-of-the-art deep learning model for representation learning on graphs. However, it remains notoriously challenging to train and inference GCNs over large graph datasets, limiting their application to large real-world graphs and hindering the exploration of deeper and more sophisticated GCN graphs. This is because as the graph size grows, the sheer number of node features and the large adjacency matrix can easily explode the required memory and data movements. To tackle the aforementioned challenge, we explore the possibility of drawing lottery tickets when sparsifying GCN graphs, i.e., subgraphs that largely shrink the adjacency matrix yet are capable of achieving accuracy comparable to or even better than their corresponding full graphs. Specifically, we for the first time discover the existence of graph early-bird (GEB) tickets that emerge at the very early stage when sparsifying GCN graphs, and propose a simple yet effective detector to automatically identify the emergence of such GEB tickets. Furthermore, we develop a generic efficient GCN training framework dubbed GEBT that can significantly boost the efficiency of GCN training by (1) drawing joint early-bird tickets between the GCN graphs and models and (2) enabling simultaneously sparsifying both GCN graphs and models, paving the way for training and inferencing large GCN graphs to handle real-world graph datasets. Experiments on various GCN models and datasets consistently validate our GEB finding and the effectiveness of our GEBT, e.g., our GEBT achieves up to 80.2% ~ 85.6% and 84.6% ~ 87.5% savings of GCN training and inference costs while leading to a comparable or even better accuracy as compared to state-of-the-art methods. Code available at https://github.com/RICE-EIC/GEBT