 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Risk Aware and Multi-Objective Decision Making with Distributional Monte Carlo Tree Search
Feb 01, 2021
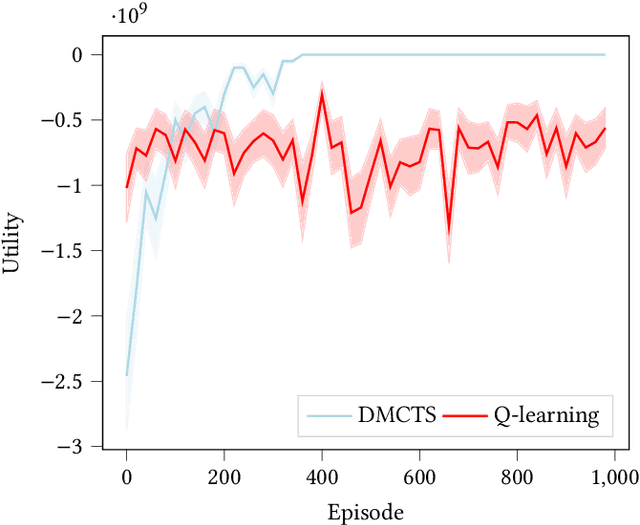
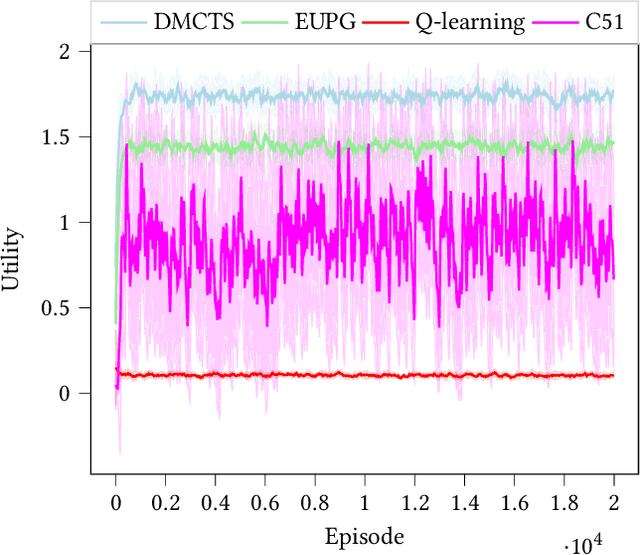
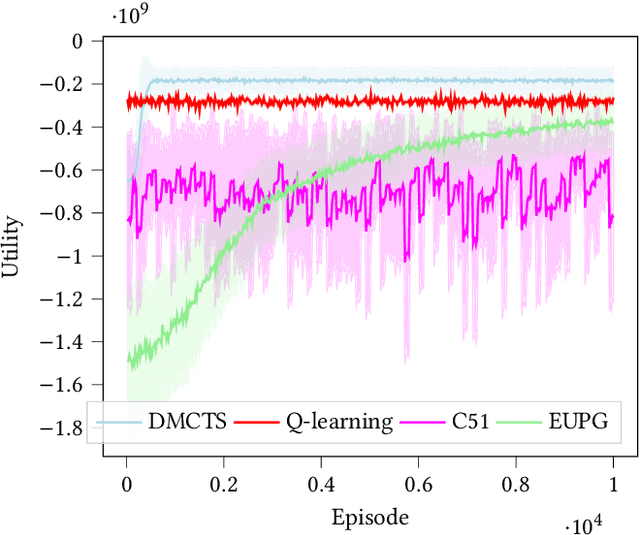
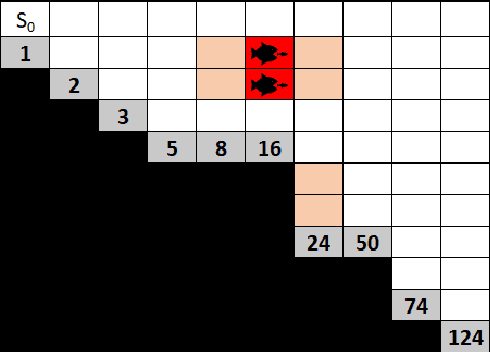
In many risk-aware and multi-objective reinforcement learning settings, the utility of the user is derived from the single execution of a policy. In these settings, making decisions based on the average future returns is not suitable. For example, in a medical setting a patient may only have one opportunity to treat their illness. When making a decision, just the expected return -- known in reinforcement learning as the value -- cannot account for the potential range of adverse or positive outcomes a decision may have. Our key insight is that we should use the distribution over expected future returns differently to represent the critical information that the agent requires at decision time. In this paper, we propose Distributional Monte Carlo Tree Search, an algorithm that learns a posterior distribution over the utility of the different possible returns attainable from individual policy executions, resulting in good policies for both risk-aware and multi-objective settings. Moreover, our algorithm outperforms the state-of-the-art in multi-objective reinforcement learning for the expected utility of the returns.
Hide-and-Seek Privacy Challenge
Jul 23, 2020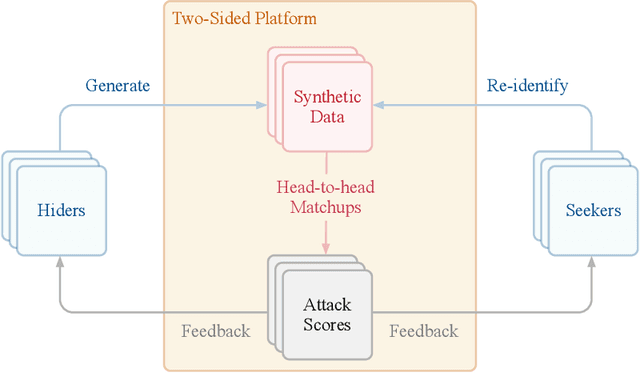
The clinical time-series setting poses a unique combination of challenges to data modeling and sharing. Due to the high dimensionality of clinical time series, adequate de-identification to preserve privacy while retaining data utility is difficult to achieve using common de-identification techniques. An innovative approach to this problem is synthetic data generation. From a technical perspective, a good generative model for time-series data should preserve temporal dynamics, in the sense that new sequences respect the original relationships between high-dimensional variables across time. From the privacy perspective, the model should prevent patient re-identification by limiting vulnerability to membership inference attacks. The NeurIPS 2020 Hide-and-Seek Privacy Challenge is a novel two-tracked competition to simultaneously accelerate progress in tackling both problems. In our head-to-head format, participants in the synthetic data generation track (i.e. "hiders") and the patient re-identification track (i.e. "seekers") are directly pitted against each other by way of a new, high-quality intensive care time-series dataset: the AmsterdamUMCdb dataset. Ultimately, we seek to advance generative techniques for dense and high-dimensional temporal data streams that are (1) clinically meaningful in terms of fidelity and predictivity, as well as (2) capable of minimizing membership privacy risks in terms of the concrete notion of patient re-identification.
Semantic video segmentation for autonomous driving
Oct 28, 2020

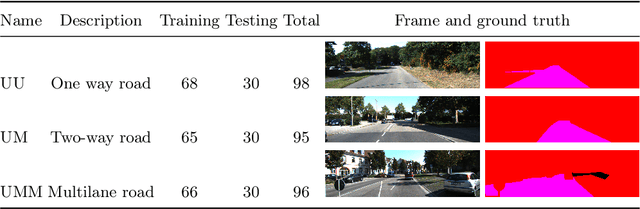
We aim to solve semantic video segmentation in autonomous driving, namely road detection in real time video, using techniques discussed in (Shelhamer et al., 2016a). While fully convolutional network gives good result, we show that the speed can be halved while preserving the accuracy. The test dataset being used is KITTI, which consists of real footage from Germany's streets.
A Deep Learning Bidirectional Temporal Tracking Algorithm for Automated Blood Cell Counting from Non-invasive Capillaroscopy Videos
Dec 09, 2020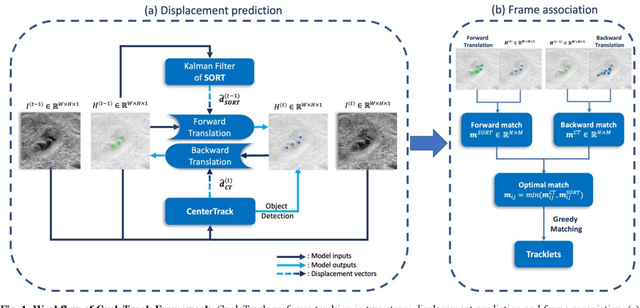
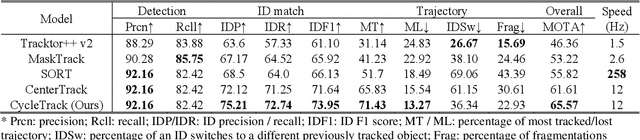
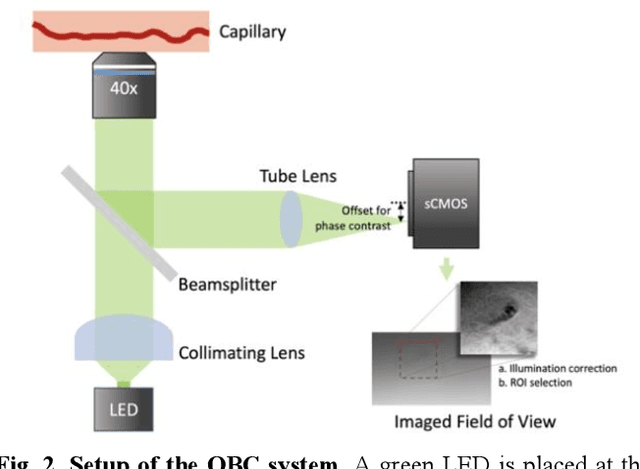
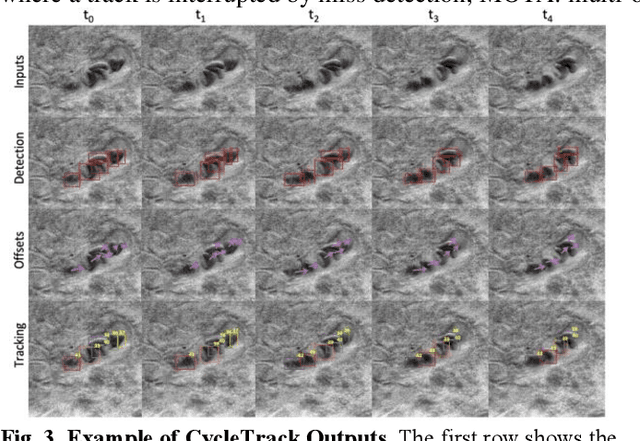
Oblique back-illumination capillaroscopy has recently been introduced as a method for high-quality, non-invasive blood cell imaging in human capillaries. To make this technique practical for clinical blood cell counting, solutions for automatic processing of acquired videos are needed. Here, we take the first step towards this goal, by introducing a deep learning multi-cell tracking model, named CycleTrack, which achieves accurate blood cell counting from capillaroscopic videos. CycleTrack combines two simple online tracking models, SORT and CenterTrack, and is tailored to features of capillary blood cell flow. Blood cells are tracked by displacement vectors in two opposing temporal directions (forward- and backward-tracking) between consecutive frames. This approach yields accurate tracking despite rapidly moving and deforming blood cells. The proposed model outperforms other baseline trackers, achieving 65.57% Multiple Object Tracking Accuracy and 73.95% ID F1 score on test videos. Compared to manual blood cell counting, CycleTrack achieves 96.58 $\pm$ 2.43% cell counting accuracy among 8 test videos with 1000 frames each compared to 93.45% and 77.02% accuracy for independent CenterTrack and SORT almost without additional time expense. It takes 800s to track and count approximately 8000 blood cells from 9,600 frames captured in a typical one-minute video. Moreover, the blood cell velocity measured by CycleTrack demonstrates a consistent, pulsatile pattern within the physiological range of heart rate. Lastly, we discuss future improvements for the CycleTrack framework, which would enable clinical translation of the oblique back-illumination microscope towards a real-time and non-invasive point-of-care blood cell counting and analyzing technology.
The Impact of Multiple Parallel Phrase Suggestions on Email Input and Composition Behaviour of Native and Non-Native English Writers
Jan 22, 2021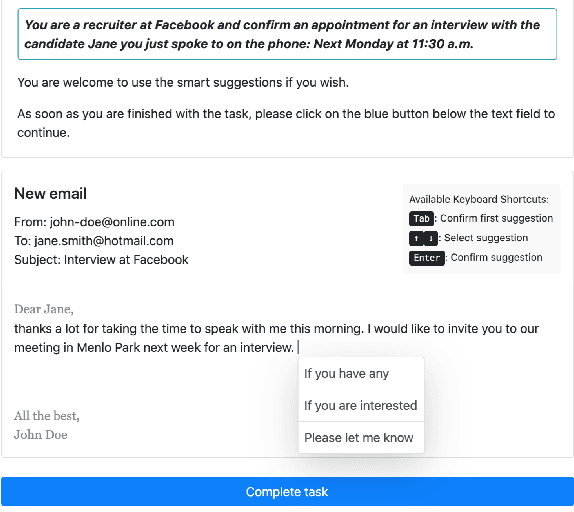

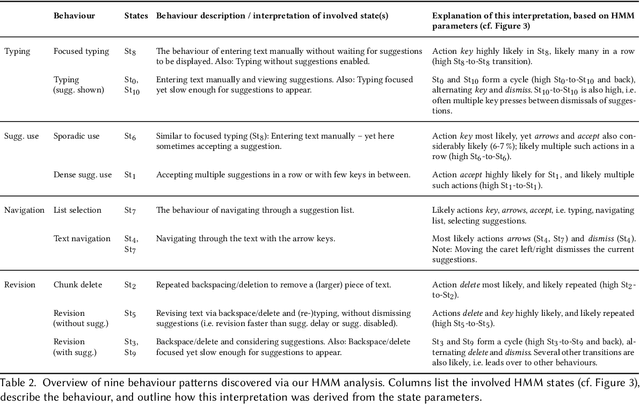

We present an in-depth analysis of the impact of multi-word suggestion choices from a neural language model on user behaviour regarding input and text composition in email writing. Our study for the first time compares different numbers of parallel suggestions, and use by native and non-native English writers, to explore a trade-off of "efficiency vs ideation", emerging from recent literature. We built a text editor prototype with a neural language model (GPT-2), refined in a prestudy with 30 people. In an online study (N=156), people composed emails in four conditions (0/1/3/6 parallel suggestions). Our results reveal (1) benefits for ideation, and costs for efficiency, when suggesting multiple phrases; (2) that non-native speakers benefit more from more suggestions; and (3) further insights into behaviour patterns. We discuss implications for research, the design of interactive suggestion systems, and the vision of supporting writers with AI instead of replacing them.
Many-to-One Distribution Learning and K-Nearest Neighbor Smoothing for Thoracic Disease Identification
Feb 26, 2021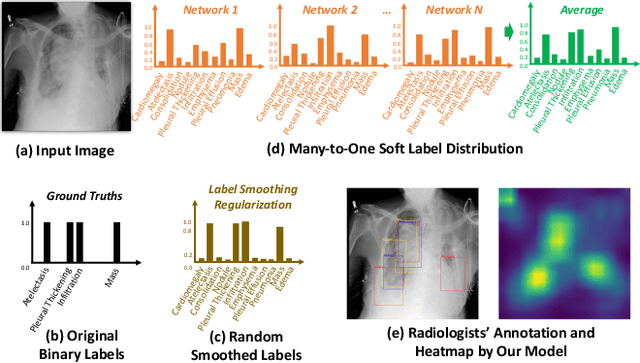

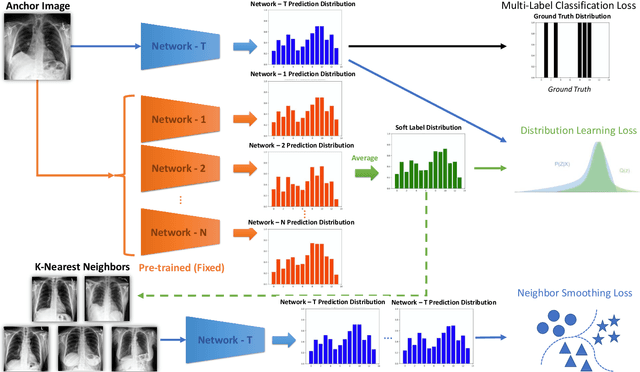
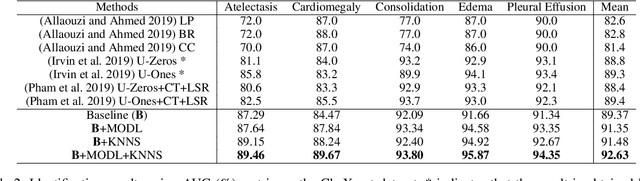
Chest X-rays are an important and accessible clinical imaging tool for the detection of many thoracic diseases. Over the past decade, deep learning, with a focus on the convolutional neural network (CNN), has become the most powerful computer-aided diagnosis technology for improving disease identification performance. However, training an effective and robust deep CNN usually requires a large amount of data with high annotation quality. For chest X-ray imaging, annotating large-scale data requires professional domain knowledge and is time-consuming. Thus, existing public chest X-ray datasets usually adopt language pattern based methods to automatically mine labels from reports. However, this results in label uncertainty and inconsistency. In this paper, we propose many-to-one distribution learning (MODL) and K-nearest neighbor smoothing (KNNS) methods from two perspectives to improve a single model's disease identification performance, rather than focusing on an ensemble of models. MODL integrates multiple models to obtain a soft label distribution for optimizing the single target model, which can reduce the effects of original label uncertainty. Moreover, KNNS aims to enhance the robustness of the target model to provide consistent predictions on images with similar medical findings. Extensive experiments on the public NIH Chest X-ray and CheXpert datasets show that our model achieves consistent improvements over the state-of-the-art methods.
Inferred vs traditional personality assessment: are we predicting the same thing?
Mar 17, 2021
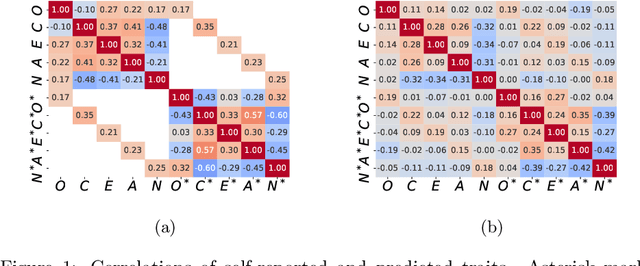
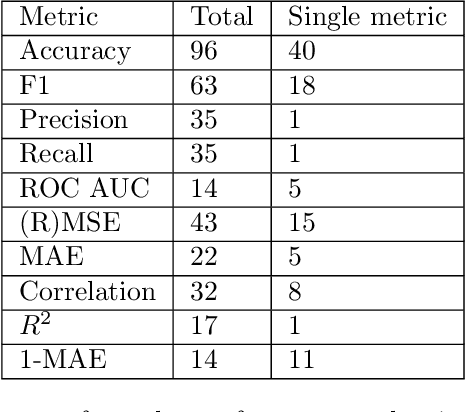
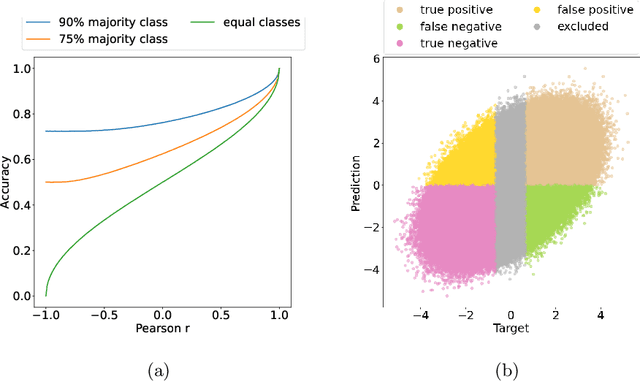
Machine learning methods are widely used by researchers to predict psychological characteristics from digital records. To find out whether automatic personality estimates retain the properties of the original traits, we reviewed 220 recent articles. First, we put together the predictive quality estimates from a subset of the studies which declare separation of training, validation, and testing phases, which is critical for ensuring the correctness of quality estimates in machine learning. Only 20% of the reviewed papers met this criterion. To compare the reported quality estimates, we converted them to approximate Pearson correlations. The credible upper limits for correlations between predicted and self-reported personality traits vary in a range between 0.42 and 0.48, depending on the specific trait. The achieved values are substantially below the correlations between traits measured with distinct self-report questionnaires. This suggests that we cannot readily interpret personality predictions as estimates of the original traits or expect predicted personality traits to reproduce known relationships with life outcomes regularly. Next, we complement quality estimates evaluation with evidence on psychometric properties of predicted traits. The few existing results suggest that predicted traits are less stable with time and have lower effective dimensionality than self-reported personality. The predictive text-based models perform substantially worse outside their training domains but stay above a random baseline. The evidence on the relationships between predicted traits and external variables is mixed. Predictive features are difficult to use for validation, due to the lack of prior hypotheses. Thus, predicted personality traits fail to retain important properties of the original characteristics. This calls for the cautious use and targeted validation of the predictive models.
ProLab: perceptually uniform projective colour coordinate system
Jan 11, 2021
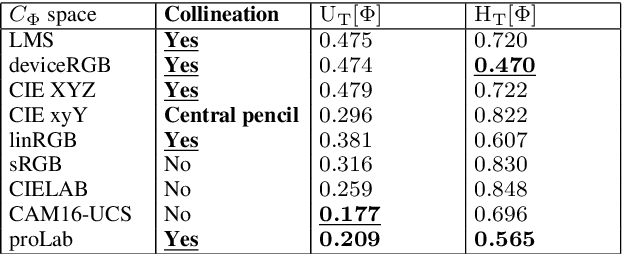
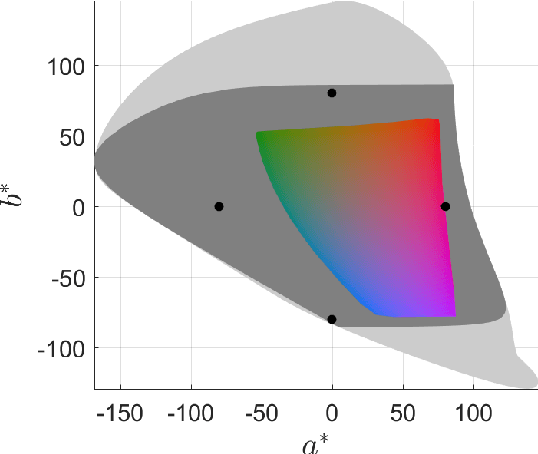

In this work, we propose proLab: a new colour coordinate system derived as a 3D projective transformation of CIE XYZ. We show that proLab is far ahead of the widely used CIELAB coordinate system (though inferior to the modern CAM16-UCS) according to perceptual uniformity evaluated by the STRESS metric in reference to the CIEDE2000 colour difference formula. At the same time, angular errors of chromaticity estimation that are standard for linear colour spaces can also be used in proLab since projective transformations preserve the linearity of manifolds. Unlike in linear spaces, angular errors for different hues are normalized according to human colour discrimination thresholds within proLab. We also demonstrate that shot noise in proLab is more homoscedastic than in CAM16-UCS or other standard colour spaces. This makes proLab a convenient coordinate system in which to perform linear colour analysis.
Spiking Neural Networks -- Part II: Detecting Spatio-Temporal Patterns
Oct 27, 2020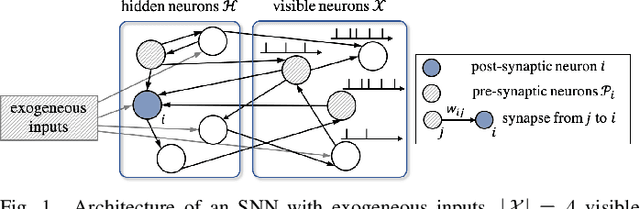
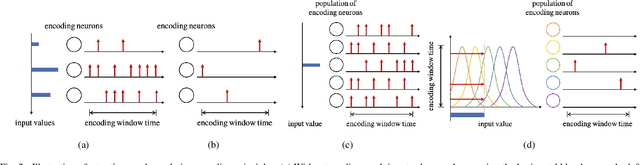
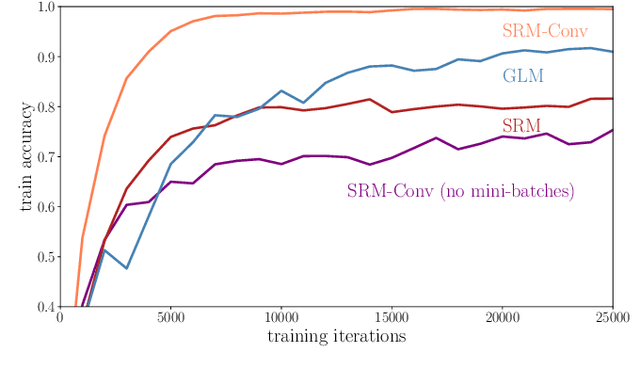
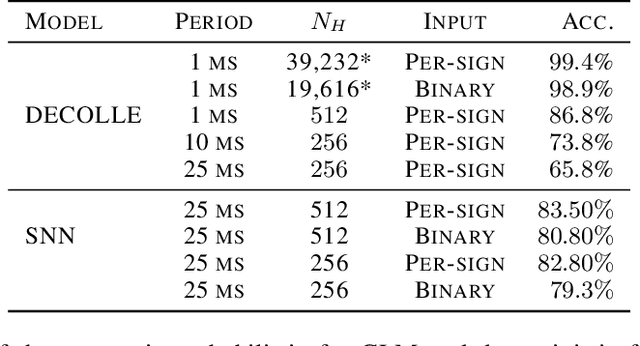
Inspired by the operation of biological brains, Spiking Neural Networks (SNNs) have the unique ability to detect information encoded in spatio-temporal patterns of spiking signals. Examples of data types requiring spatio-temporal processing include logs of time stamps, e.g., of tweets, and outputs of neural prostheses and neuromorphic sensors. In this paper, the second of a series of three review papers on SNNs, we first review models and training algorithms for the dominant approach that considers SNNs as a Recurrent Neural Network (RNN) and adapt learning rules based on backpropagation through time to the requirements of SNNs. In order to tackle the non-differentiability of the spiking mechanism, state-of-the-art solutions use surrogate gradients that approximate the threshold activation function with a differentiable function. Then, we describe an alternative approach that relies on probabilistic models for spiking neurons, allowing the derivation of local learning rules via stochastic estimates of the gradient. Finally, experiments are provided for neuromorphic data sets, yielding insights on accuracy and convergence under different SNN models.
Cybersecurity Threats in Connected and Automated Vehicles based Federated Learning Systems
Feb 26, 2021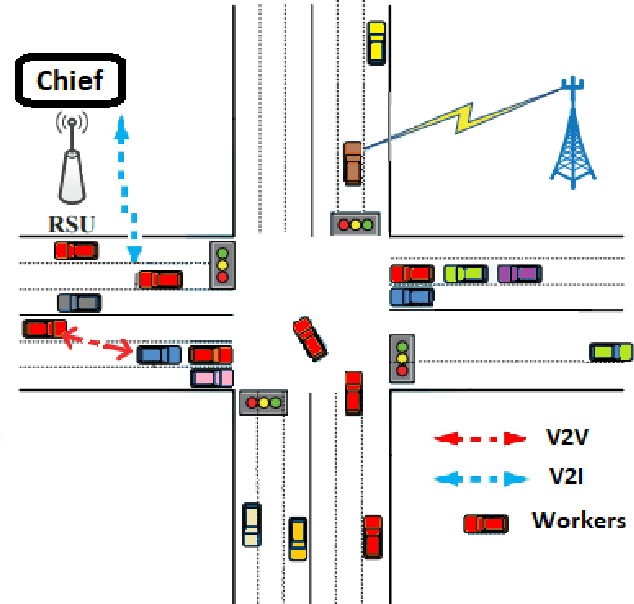
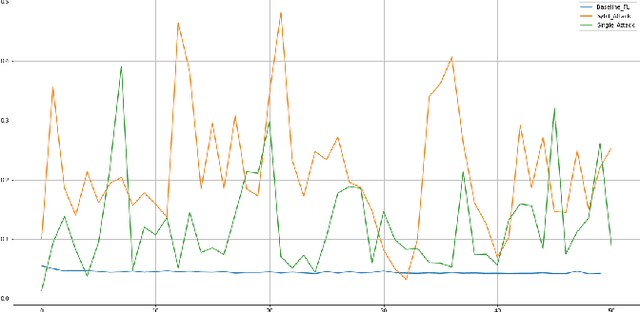
Federated learning (FL) is a machine learning technique that aims at training an algorithm across decentralized entities holding their local data private. Wireless mobile networks allow users to communicate with other fixed or mobile users. The road traffic network represents an infrastructure-based configuration of a wireless mobile network where the Connected and Automated Vehicles (CAV) represent the communicating entities. Applying FL in a wireless mobile network setting gives rise to a new threat in the mobile environment that is very different from the traditional fixed networks. The threat is due to the intrinsic characteristics of the wireless medium and is caused by the characteristics of the vehicular networks such as high node-mobility and rapidly changing topology. Most cyber defense techniques depend on highly reliable and connected networks. This paper explores falsified information attacks, which target the FL process that is ongoing at the RSU. We identified a number of attack strategies conducted by the malicious CAVs to disrupt the training of the global model in vehicular networks. We show that the attacks were able to increase the convergence time and decrease the accuracy the model. We demonstrate that our attacks bypass FL defense strategies in their primary form and highlight the need for novel poisoning resilience defense mechanisms in the wireless mobile setting of the future road networks.