 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAST: Mask-Guided Attention Mass Allocation for Training-Free Multi-Style Transfer
Apr 14, 2026Style transfer aims to render a content image with the visual characteristics of a reference style while preserving its underlying semantic layout and structural geometry. While recent diffusion-based models demonstrate strong stylization capabilities by leveraging powerful generative priors and controllable internal representations, they typically assume a single global style. Extending them to multi-style scenarios often leads to boundary artifacts, unstable stylization, and structural inconsistency due to interference between multiple style representations. To overcome these limitations, we propose MAST (Mask-Guided Attention Mass Allocation for Training-Free Multi-Style Transfer), a novel training-free framework that explicitly controls content-style interactions within the diffusion attention mechanism. To achieve artifact-free and structure-preserving stylization, MAST integrates four connected modules. First, Layout-preserving Query Anchoring prevents global layout collapse by firmly anchoring the semantic structure using content queries. Second, Logit-level Attention Mass Allocation deterministically distributes attention probability mass across spatial regions, seamlessly fusing multiple styles without boundary artifacts. Third, Sharpness-aware Temperature Scaling restores the attention sharpness degraded by multi-style expansion. Finally, Discrepancy-aware Detail Injection adaptively compensates for localized high-frequency detail losses by measuring structural discrepancies. Extensive experiments demonstrate that MAST effectively mitigates boundary artifacts and maintains structural consistency, preserving texture fidelity and spatial coherence even as the number of applied styles increases.
I2AM: Interpreting Image-to-Image Latent Diffusion Models via Attribution Maps
Jul 17, 2024



Large-scale diffusion models have made significant advancements in the field of image generation, especially through the use of cross-attention mechanisms that guide image formation based on textual descriptions. While the analysis of text-guided cross-attention in diffusion models has been extensively studied in recent years, its application in image-to-image diffusion models remains underexplored. This paper introduces the Image-to-Image Attribution Maps I2AM method, which aggregates patch-level cross-attention scores to enhance the interpretability of latent diffusion models across time steps, heads, and attention layers. I2AM facilitates detailed image-to-image attribution analysis, enabling observation of how diffusion models prioritize key features over time and head during the image generation process from reference images. Through extensive experiments, we first visualize the attribution maps of both generated and reference images, verifying that critical information from the reference image is effectively incorporated into the generated image, and vice versa. To further assess our understanding, we introduce a new evaluation metric tailored for reference-based image inpainting tasks. This metric, measuring the consistency between the attribution maps of generated and reference images, shows a strong correlation with established performance metrics for inpainting tasks, validating the potential use of I2AM in future research endeavors.
Text-to-Image Synthesis for Any Artistic Styles: Advancements in Personalized Artistic Image Generation via Subdivision and Dual Binding
Apr 08, 2024



Recent advancements in text-to-image models, such as Stable Diffusion, have demonstrated their ability to synthesize visual images through natural language prompts. One approach of personalizing text-to-image models, exemplified by DreamBooth, fine-tunes the pre-trained model by binding unique text identifiers with a few images of a specific subject. Although existing fine-tuning methods have demonstrated competence in rendering images according to the styles of famous painters, it is still challenging to learn to produce images encapsulating distinct art styles due to abstract and broad visual perceptions of stylistic attributes such as lines, shapes, textures, and colors. In this paper, we introduce a new method, Single-StyleForge, for personalization. It fine-tunes pre-trained text-to-image diffusion models to generate diverse images in specified styles from text prompts. By using around 15-20 images of the target style, the approach establishes a foundational binding of a unique token identifier with a broad range of the target style. It also utilizes auxiliary images to strengthen this binding, resulting in offering specific guidance on representing elements such as persons in a target style-consistent manner. In addition, we present ways to improve the quality of style and text-image alignment through a method called Multi-StyleForge, which inherits the strategy used in StyleForge and learns tokens in multiple. Experimental evaluation conducted on six distinct artistic styles demonstrates substantial improvements in both the quality of generated images and the perceptual fidelity metrics, such as FID, KID, and CLIP scores.
Bayesian Continual Learning via Spiking Neural Networks
Aug 29, 2022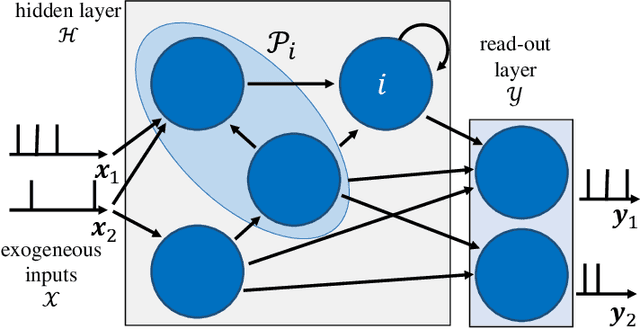
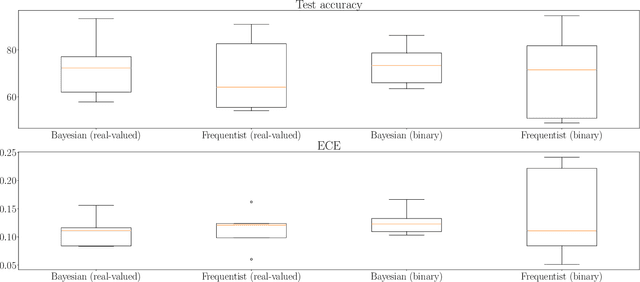
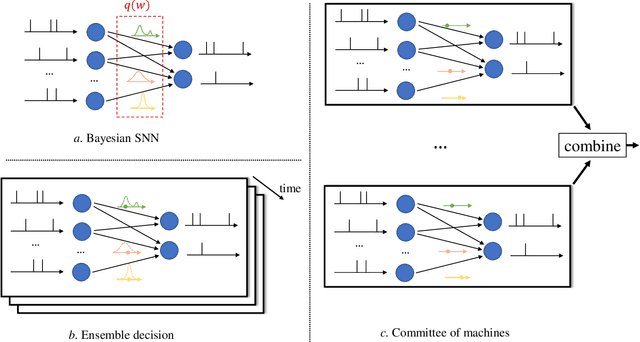
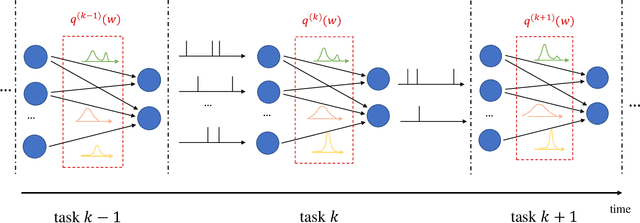
Among the main features of biological intelligence are energy efficiency, capacity for continual adaptation, and risk management via uncertainty quantification. Neuromorphic engineering has been thus far mostly driven by the goal of implementing energy-efficient machines that take inspiration from the time-based computing paradigm of biological brains. In this paper, we take steps towards the design of neuromorphic systems that are capable of adaptation to changing learning tasks, while producing well-calibrated uncertainty quantification estimates. To this end, we derive online learning rules for spiking neural networks (SNNs) within a Bayesian continual learning framework. In it, each synaptic weight is represented by parameters that quantify the current epistemic uncertainty resulting from prior knowledge and observed data. The proposed online rules update the distribution parameters in a streaming fashion as data are observed. We instantiate the proposed approach for both real-valued and binary synaptic weights. Experimental results using Intel's Lava platform show the merits of Bayesian over frequentist learning in terms of capacity for adaptation and uncertainty quantification.
Learning to Broadcast for Ultra-Reliable Communication with Differential Quality of Service via the Conditional Value at Risk
Dec 03, 2021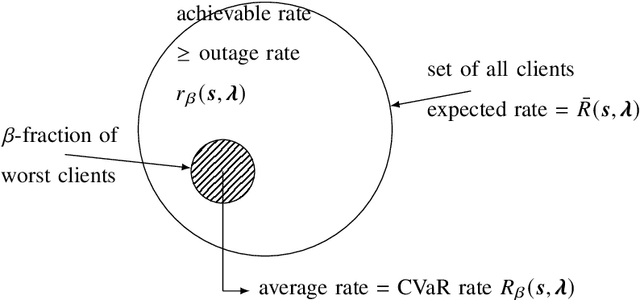
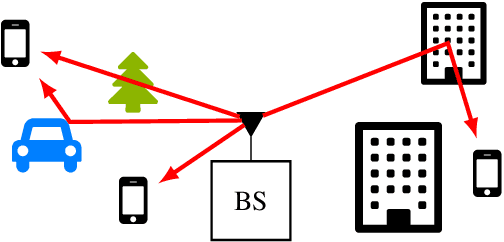
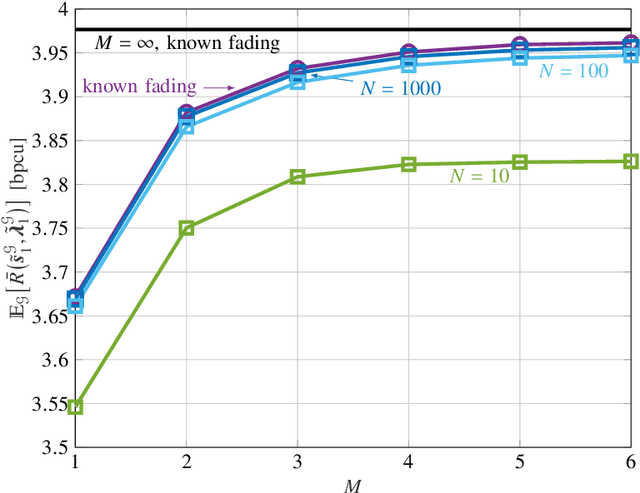
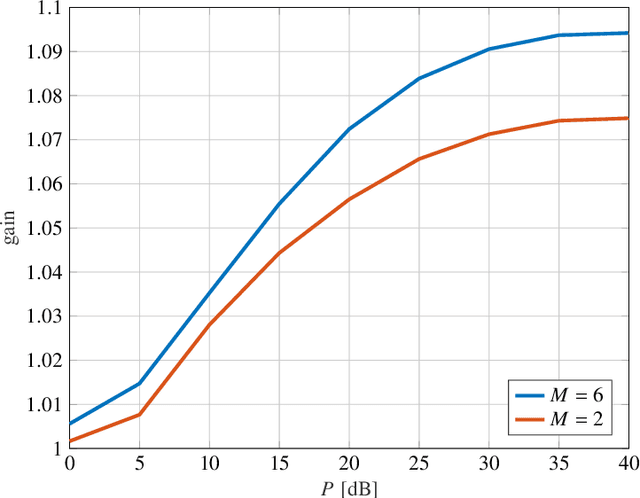
Broadcast/multicast communication systems are typically designed to optimize the outage rate criterion, which neglects the performance of the fraction of clients with the worst channel conditions. Targeting ultra-reliable communication scenarios, this paper takes a complementary approach by introducing the conditional value-at-risk (CVaR) rate as the expected rate of a worst-case fraction of clients. To support differential quality-of-service (QoS) levels in this class of clients, layered division multiplexing (LDM) is applied, which enables decoding at different rates. Focusing on a practical scenario in which the transmitter does not know the fading distribution, layer allocation is optimized based on a dataset sampled during deployment. The optimality gap caused by the availability of limited data is bounded via a generalization analysis, and the sample complexity is shown to increase as the designated fraction of worst-case clients decreases. Considering this theoretical result, meta-learning is introduced as a means to reduce sample complexity by leveraging data from previous deployments. Numerical experiments demonstrate that LDM improves spectral efficiency even for small datasets; that, for sufficiently large datasets, the proposed mirror-descent-based layer optimization scheme achieves a CVaR rate close to that achieved when the transmitter knows the fading distribution; and that meta-learning can significantly reduce data requirements.
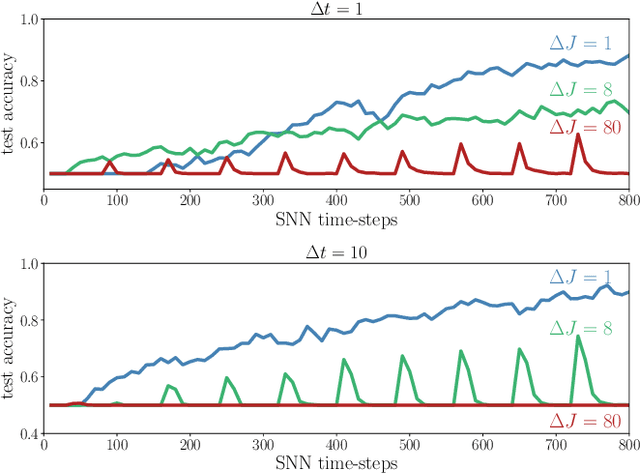
Learning to Time-Decode in Spiking Neural Networks Through the Information Bottleneck
Jun 02, 2021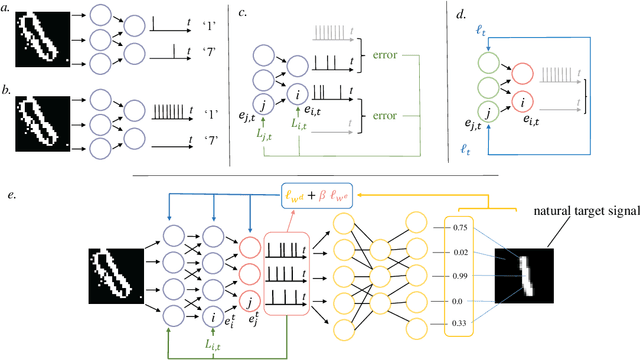

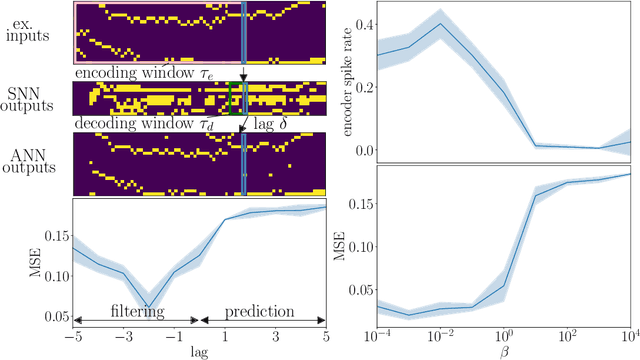
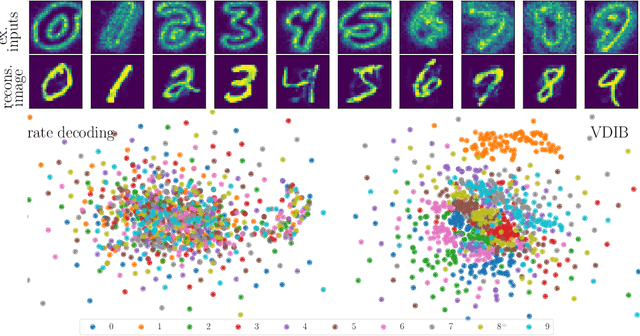
One of the key challenges in training Spiking Neural Networks (SNNs) is that target outputs typically come in the form of natural signals, such as labels for classification or images for generative models, and need to be encoded into spikes. This is done by handcrafting target spiking signals, which in turn implicitly fixes the mechanisms used to decode spikes into natural signals, e.g., rate decoding. The arbitrary choice of target signals and decoding rule generally impairs the capacity of the SNN to encode and process information in the timing of spikes. To address this problem, this work introduces a hybrid variational autoencoder architecture, consisting of an encoding SNN and a decoding Artificial Neural Network (ANN). The role of the decoding ANN is to learn how to best convert the spiking signals output by the SNN into the target natural signal. A novel end-to-end learning rule is introduced that optimizes a directed information bottleneck training criterion via surrogate gradients. We demonstrate the applicability of the technique in an experimental settings on various tasks, including real-life datasets.
Multi-Sample Online Learning for Spiking Neural Networks based on Generalized Expectation Maximization
Feb 05, 2021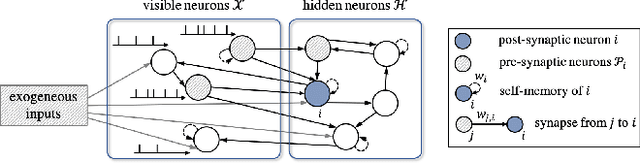
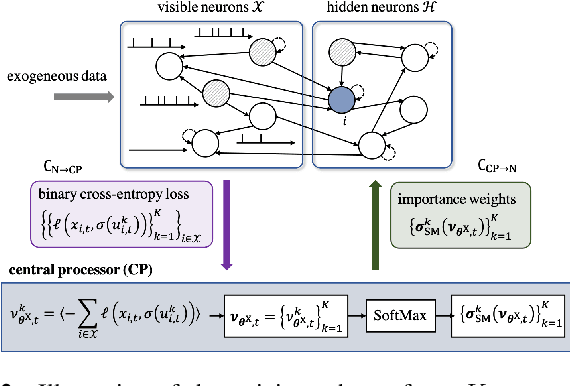
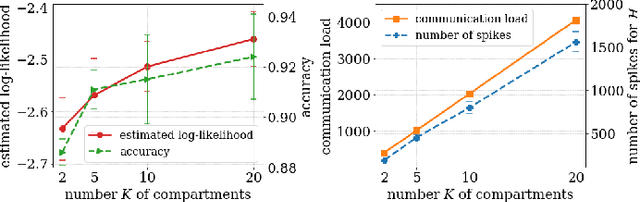
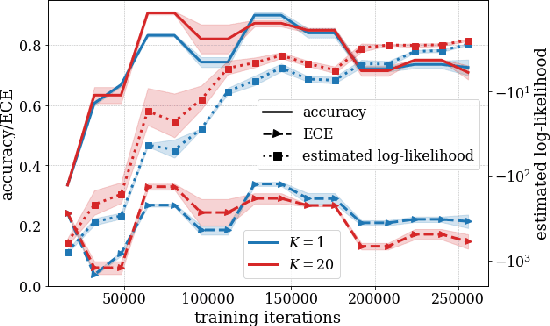
Spiking Neural Networks (SNNs) offer a novel computational paradigm that captures some of the efficiency of biological brains by processing through binary neural dynamic activations. Probabilistic SNN models are typically trained to maximize the likelihood of the desired outputs by using unbiased estimates of the log-likelihood gradients. While prior work used single-sample estimators obtained from a single run of the network, this paper proposes to leverage multiple compartments that sample independent spiking signals while sharing synaptic weights. The key idea is to use these signals to obtain more accurate statistical estimates of the log-likelihood training criterion, as well as of its gradient. The approach is based on generalized expectation-maximization (GEM), which optimizes a tighter approximation of the log-likelihood using importance sampling. The derived online learning algorithm implements a three-factor rule with global per-compartment learning signals. Experimental results on a classification task on the neuromorphic MNIST-DVS data set demonstrate significant improvements in terms of log-likelihood, accuracy, and calibration when increasing the number of compartments used for training and inference.
BiSNN: Training Spiking Neural Networks with Binary Weights via Bayesian Learning
Dec 15, 2020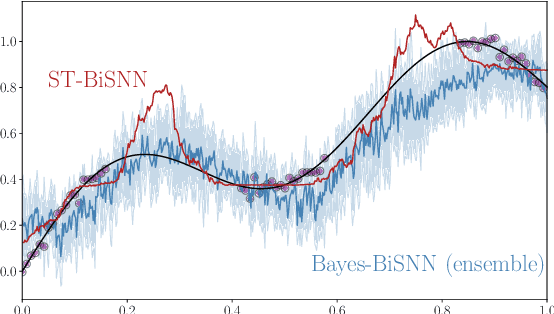

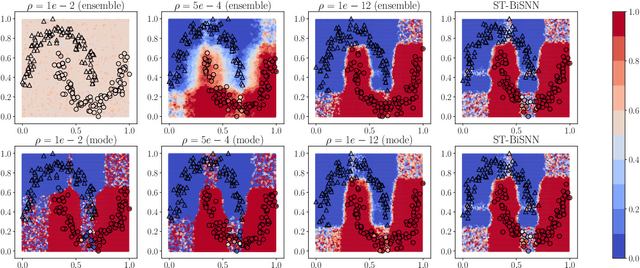

Artificial Neural Network (ANN)-based inference on battery-powered devices can be made more energy-efficient by restricting the synaptic weights to be binary, hence eliminating the need to perform multiplications. An alternative, emerging, approach relies on the use of Spiking Neural Networks (SNNs), biologically inspired, dynamic, event-driven models that enhance energy efficiency via the use of binary, sparse, activations. In this paper, an SNN model is introduced that combines the benefits of temporally sparse binary activations and of binary weights. Two learning rules are derived, the first based on the combination of straight-through and surrogate gradient techniques, and the second based on a Bayesian paradigm. Experiments validate the performance loss with respect to full-precision implementations, and demonstrate the advantage of the Bayesian paradigm in terms of accuracy and calibration.
Spiking Neural Networks -- Part III: Neuromorphic Communications
Oct 27, 2020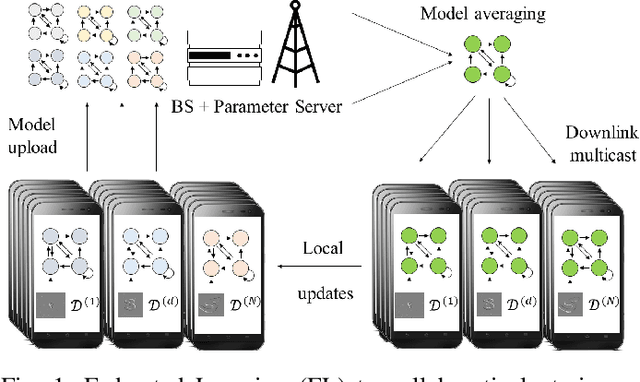
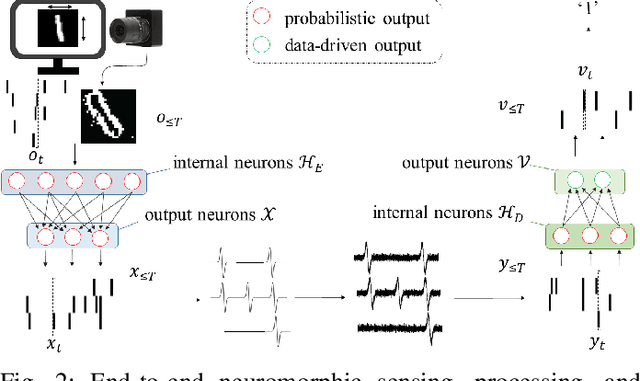
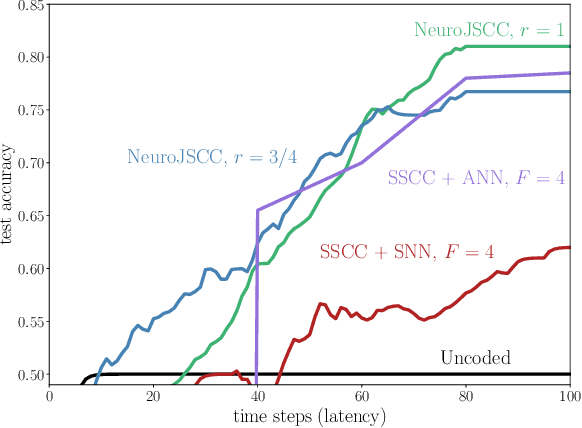
Synergies between wireless communications and artificial intelligence are increasingly motivating research at the intersection of the two fields. On the one hand, the presence of more and more wirelessly connected devices, each with its own data, is driving efforts to export advances in machine learning (ML) from high performance computing facilities, where information is stored and processed in a single location, to distributed, privacy-minded, processing at the end user. On the other hand, ML can address algorithm and model deficits in the optimization of communication protocols. However, implementing ML models for learning and inference on battery-powered devices that are connected via bandwidth-constrained channels remains challenging. This paper explores two ways in which Spiking Neural Networks (SNNs) can help address these open problems. First, we discuss federated learning for the distributed training of SNNs, and then describe the integration of neuromorphic sensing, SNNs, and impulse radio technologies for low-power remote inference.
Spiking Neural Networks -- Part II: Detecting Spatio-Temporal Patterns
Oct 27, 2020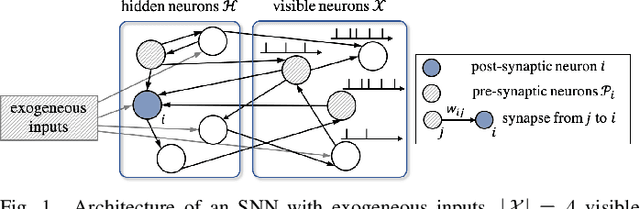
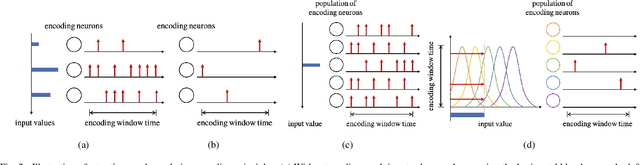
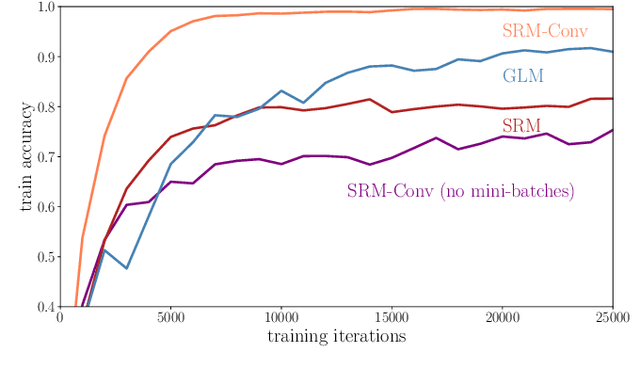
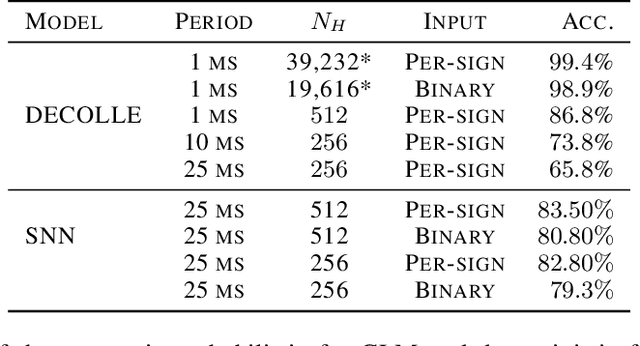
Inspired by the operation of biological brains, Spiking Neural Networks (SNNs) have the unique ability to detect information encoded in spatio-temporal patterns of spiking signals. Examples of data types requiring spatio-temporal processing include logs of time stamps, e.g., of tweets, and outputs of neural prostheses and neuromorphic sensors. In this paper, the second of a series of three review papers on SNNs, we first review models and training algorithms for the dominant approach that considers SNNs as a Recurrent Neural Network (RNN) and adapt learning rules based on backpropagation through time to the requirements of SNNs. In order to tackle the non-differentiability of the spiking mechanism, state-of-the-art solutions use surrogate gradients that approximate the threshold activation function with a differentiable function. Then, we describe an alternative approach that relies on probabilistic models for spiking neurons, allowing the derivation of local learning rules via stochastic estimates of the gradient. Finally, experiments are provided for neuromorphic data sets, yielding insights on accuracy and convergence under different SNN models.