 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Automatic Monitoring Social Dynamics During Big Incidences: A Case Study of COVID-19 in Bangladesh
Jan 24, 2021
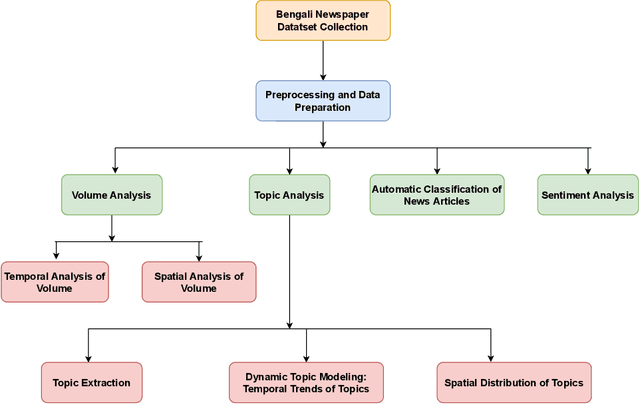
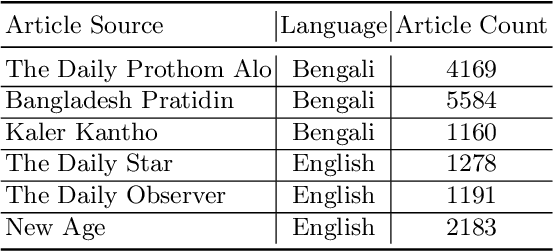
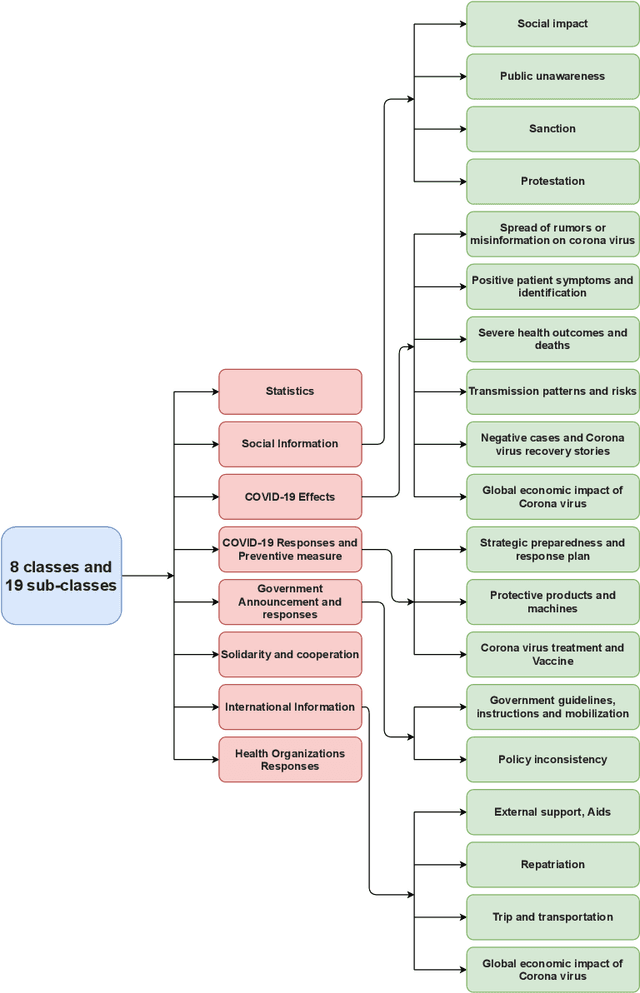
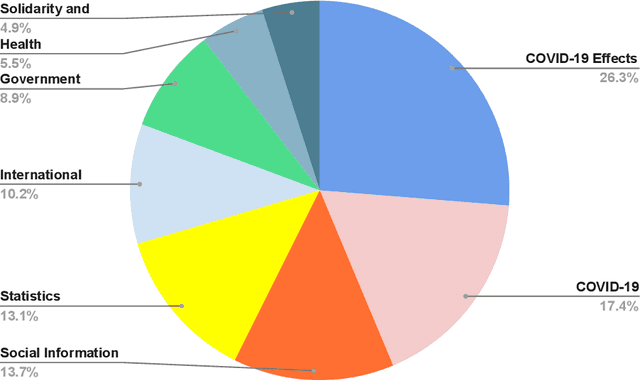
Newspapers are trustworthy media where people get the most reliable and credible information compared with other sources. On the other hand, social media often spread rumors and misleading news to get more traffic and attention. Careful characterization, evaluation, and interpretation of newspaper data can provide insight into intrigue and passionate social issues to monitor any big social incidence. This study analyzed a large set of spatio-temporal Bangladeshi newspaper data related to the COVID-19 pandemic. The methodology included volume analysis, topic analysis, automated classification, and sentiment analysis of news articles to get insight into the COVID-19 pandemic in different sectors and regions in Bangladesh over a period of time. This analysis will help the government and other organizations to figure out the challenges that have arisen in society due to this pandemic, what steps should be taken immediately and in the post-pandemic period, how the government and its allies can come together to address the crisis in the future, keeping these problems in mind.
Toward Real-World BCI: CCSPNet, A Compact Subject-Independent Motor Imagery Framework
Dec 25, 2020
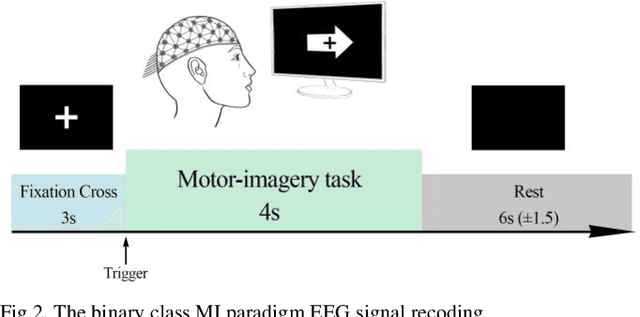
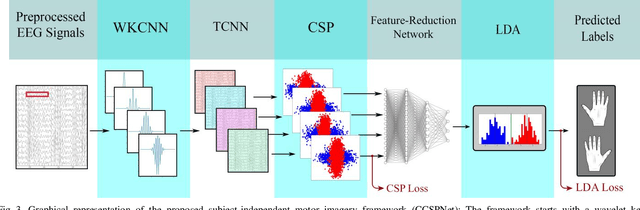
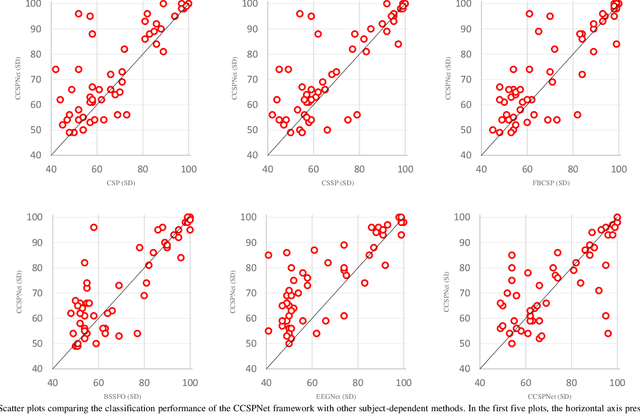
A conventional brain-computer interface (BCI) requires a complete data gathering, training, and calibration phase for each user before it can be used. This preliminary phase is time-consuming and should be done under the supervision of technical experts commonly in laboratories for the BCI to function properly. In recent years, a number of subject-independent (SI) BCIs have been developed. However, there are many problems preventing them from being used in real-world BCI applications. A lower accuracy than the subject-dependent (SD) approach and a relatively high run-time of models with a large number of model parameters are the most important ones. Therefore, a real-world BCI application would greatly benefit from a compact subject-independent BCI framework, ready to use immediately after the user puts it on, and suitable for low-power edge-computing and applications in the emerging area of internet of things (IoT). We propose a novel subject-independent BCI framework named CCSPNet (Convolutional Common Spatial Pattern Network) that is trained on the motor imagery (MI) paradigm of a large-scale EEG signals database consisting of 400 trials for every 54 subjects performing two-class hand-movement MI tasks. The proposed framework applies a wavelet kernel convolutional neural network (WKCNN) and a temporal convolutional neural network (TCNN) in order to represent and extract the diverse frequency behavior and spectral patterns of EEG signals. The convolutional layers outputs go through a CSP algorithm for class discrimination and spatial feature extraction. The number of CSP features is reduced by a dense neural network, and the final class label is determined by an LDA. The final SD and SI classification accuracies of the proposed framework match the best results obtained on the largest motor-imagery dataset present in the BCI literature, with 99.993 percent fewer model parameters.
OmniFair: A Declarative System for Model-Agnostic Group Fairness in Machine Learning
Mar 13, 2021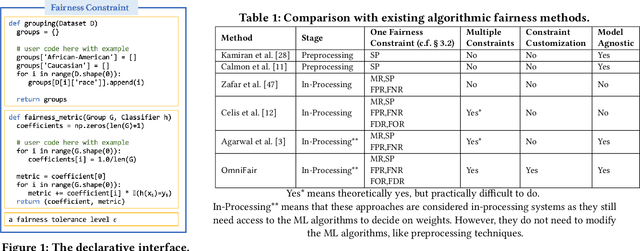
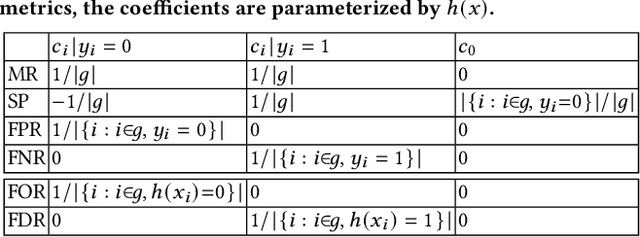
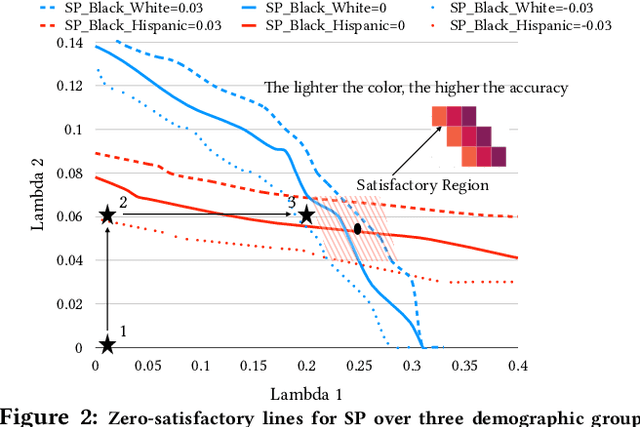

Machine learning (ML) is increasingly being used to make decisions in our society. ML models, however, can be unfair to certain demographic groups (e.g., African Americans or females) according to various fairness metrics. Existing techniques for producing fair ML models either are limited to the type of fairness constraints they can handle (e.g., preprocessing) or require nontrivial modifications to downstream ML training algorithms (e.g., in-processing). We propose a declarative system OmniFair for supporting group fairness in ML. OmniFair features a declarative interface for users to specify desired group fairness constraints and supports all commonly used group fairness notions, including statistical parity, equalized odds, and predictive parity. OmniFair is also model-agnostic in the sense that it does not require modifications to a chosen ML algorithm. OmniFair also supports enforcing multiple user declared fairness constraints simultaneously while most previous techniques cannot. The algorithms in OmniFair maximize model accuracy while meeting the specified fairness constraints, and their efficiency is optimized based on the theoretically provable monotonicity property regarding the trade-off between accuracy and fairness that is unique to our system. We conduct experiments on commonly used datasets that exhibit bias against minority groups in the fairness literature. We show that OmniFair is more versatile than existing algorithmic fairness approaches in terms of both supported fairness constraints and downstream ML models. OmniFair reduces the accuracy loss by up to $94.8\%$ compared with the second best method. OmniFair also achieves similar running time to preprocessing methods, and is up to $270\times$ faster than in-processing methods.
Image Compression with Encoder-Decoder Matched Semantic Segmentation
Jan 24, 2021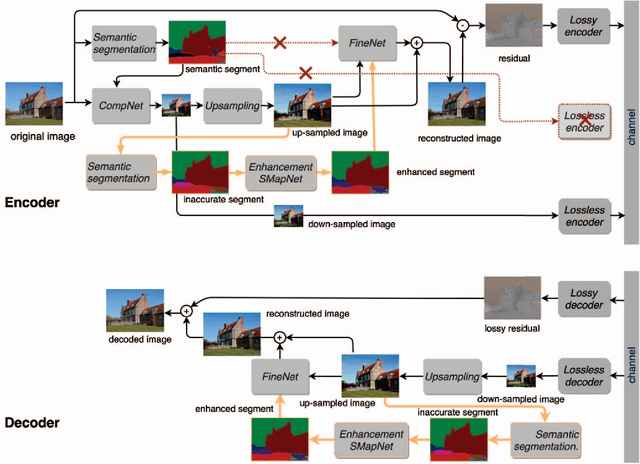

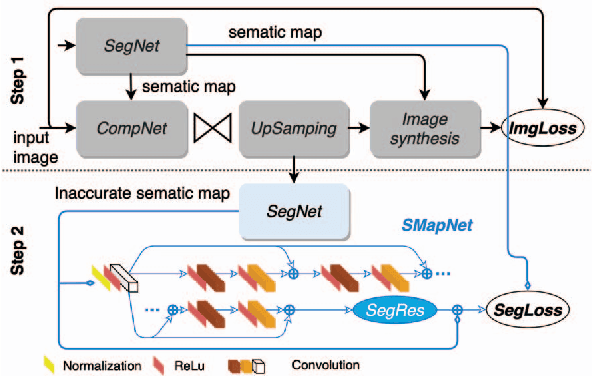
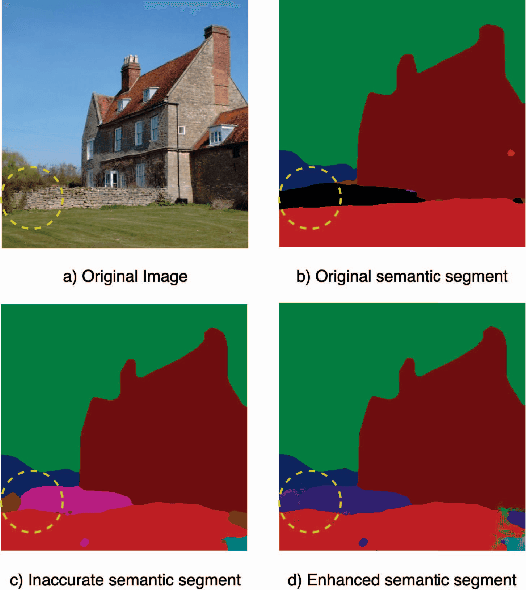
In recent years, layered image compression is demonstrated to be a promising direction, which encodes a compact representation of the input image and apply an up-sampling network to reconstruct the image. To further improve the quality of the reconstructed image, some works transmit the semantic segment together with the compressed image data. Consequently, the compression ratio is also decreased because extra bits are required for transmitting the semantic segment. To solve this problem, we propose a new layered image compression framework with encoder-decoder matched semantic segmentation (EDMS). And then, followed by the semantic segmentation, a special convolution neural network is used to enhance the inaccurate semantic segment. As a result, the accurate semantic segment can be obtained in the decoder without requiring extra bits. The experimental results show that the proposed EDMS framework can get up to 35.31% BD-rate reduction over the HEVC-based (BPG) codec, 5% bitrate, and 24% encoding time saving compare to the state-of-the-art semantic-based image codec.
FedEval: A Benchmark System with a Comprehensive Evaluation Model for Federated Learning
Nov 25, 2020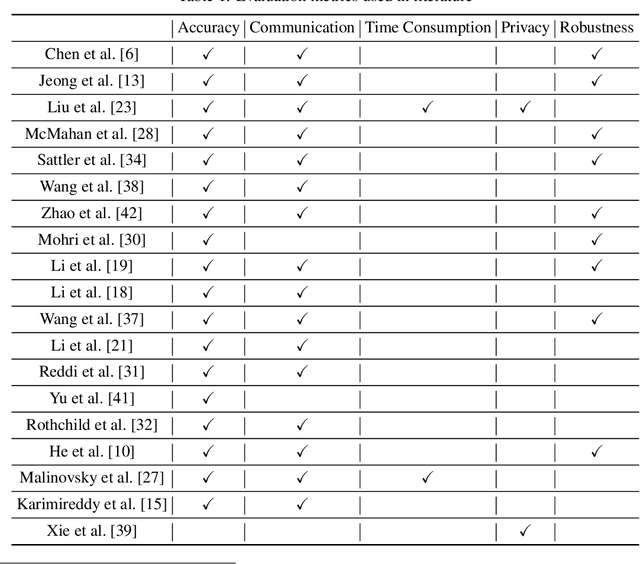

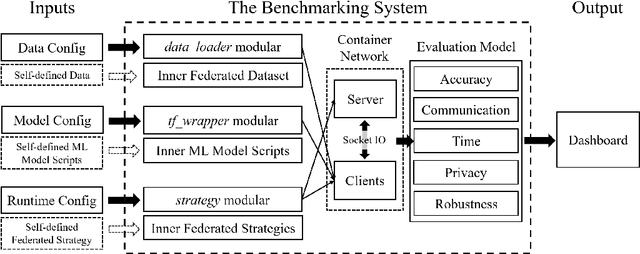
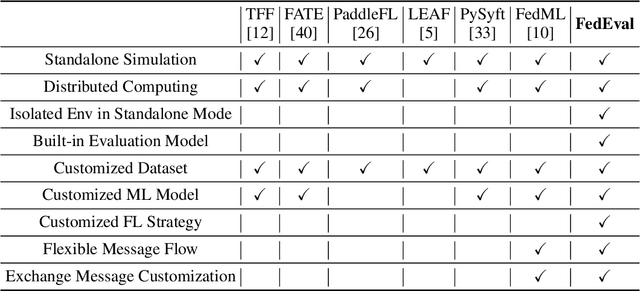
As an innovative solution for privacy-preserving machine learning (ML), federated learning (FL) is attracting much attention from research and industry areas. While new technologies proposed in the past few years do evolve the FL area, unfortunately, the evaluation results presented in these works fall short in integrity and are hardly comparable because of the inconsistent evaluation metrics and the lack of a common platform. In this paper, we propose a comprehensive evaluation framework for FL systems. Specifically, we first introduce the ACTPR model, which defines five metrics that cannot be excluded in FL evaluation, including Accuracy, Communication, Time efficiency, Privacy, and Robustness. Then we design and implement a benchmarking system called FedEval, which enables the systematic evaluation and comparison of existing works under consistent experimental conditions. We then provide an in-depth benchmarking study between the two most widely-used FL mechanisms, FedSGD and FedAvg. The benchmarking results show that FedSGD and FedAvg both have advantages and disadvantages under the ACTPR model. For example, FedSGD is barely influenced by the none independent and identically distributed (non-IID) data problem, but FedAvg suffers from a decline in accuracy of up to 9% in our experiments. On the other hand, FedAvg is more efficient than FedSGD regarding time consumption and communication. Lastly, we excavate a set of take-away conclusions, which are very helpful for researchers in the FL area.
Sample-Optimal PAC Learning of Halfspaces with Malicious Noise
Feb 11, 2021
We study efficient PAC learning of homogeneous halfspaces in $\mathbb{R}^d$ in the presence of malicious noise of Valiant~(1985). This is a challenging noise model and only until recently has near-optimal noise tolerance bound been established under the mild condition that the unlabeled data distribution is isotropic log-concave. However, it remains unsettled how to obtain the optimal sample complexity simultaneously. In this work, we present a new analysis for the algorithm of Awasthi et al.~(2017) and show that it essentially achieves the near-optimal sample complexity bound of $\tilde{O}(d)$, improving the best known result of $\tilde{O}(d^2)$. Our main ingredient is a novel incorporation of a Matrix Chernoff-type inequality to bound the spectrum of an empirical covariance matrix for well-behaved distributions, in conjunction with a careful exploration of the localization schemes of Awasthi et al.~(2017). We further extend the algorithm and analysis to the more general and stronger nasty noise model of Bshouty~et~al. (2002), showing that it is still possible to achieve near-optimal noise tolerance and sample complexity in polynomial time.
EventKG+BT: Generation of Interactive Biography Timelines from a Knowledge Graph
Dec 04, 2020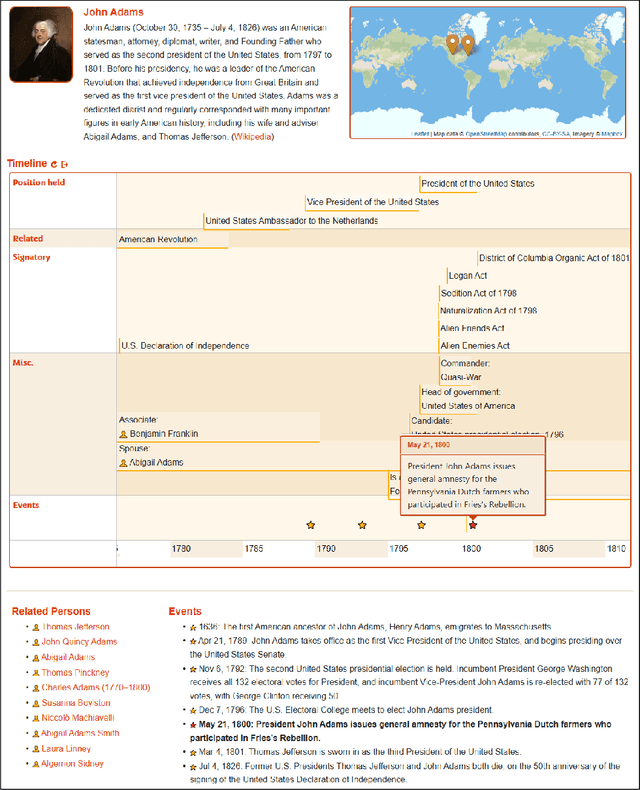
Research on notable accomplishments and important events in the life of people of public interest usually requires close reading of long encyclopedic or biographical sources, which is a tedious and time-consuming task. Whereas semantic reference sources, such as the EventKG knowledge graph, provide structured representations of relevant facts, they often include hundreds of events and temporal relations for particular entities. In this paper, we present EventKG+BT - a timeline generation system that creates concise and interactive spatio-temporal representations of biographies from a knowledge graph using distant supervision.
Technical Progress Analysis Using a Dynamic Topic Model for Technical Terms to Revise Patent Classification Codes
Dec 18, 2020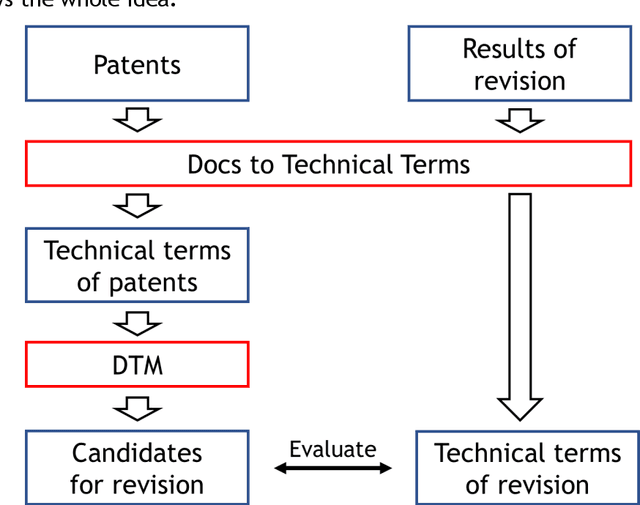
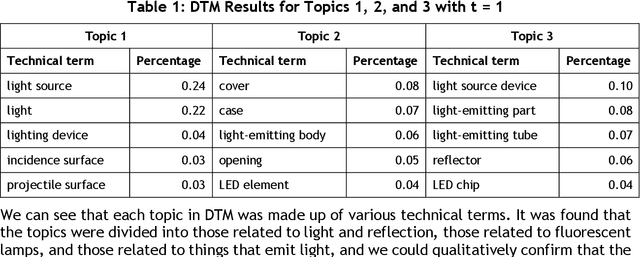
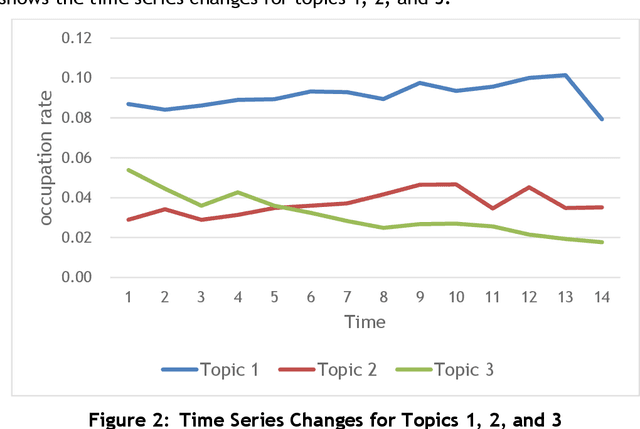
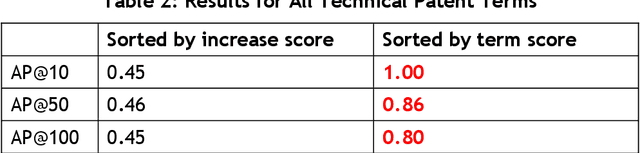
Japanese patents are assigned a patent classification code, FI (File Index), that is unique to Japan. FI is a subdivision of the IPC, an international patent classification code, that is related to Japanese technology. FIs are revised to keep up with technological developments. These revisions have already established more than 30,000 new FIs since 2006. However, these revisions require a lot of time and workload. Moreover, these revisions are not automated and are thus inefficient. Therefore, using machine learning to assist in the revision of patent classification codes (FI) will lead to improved accuracy and efficiency. This study analyzes patent documents from this new perspective of assisting in the revision of patent classification codes with machine learning. To analyze time-series changes in patents, we used the dynamic topic model (DTM), which is an extension of the latent Dirichlet allocation (LDA). Also, unlike English, the Japanese language requires morphological analysis. Patents contain many technical words that are not used in everyday life, so morphological analysis using a common dictionary is not sufficient. Therefore, we used a technique for extracting technical terms from text. After extracting technical terms, we applied them to DTM. In this study, we determined the technological progress of the lighting class F21 for 14 years and compared it with the actual revision of patent classification codes. In other words, we extracted technical terms from Japanese patents and applied DTM to determine the progress of Japanese technology. Then, we analyzed the results from the new perspective of revising patent classification codes with machine learning. As a result, it was found that those whose topics were on the rise were judged to be new technologies.
Genetic Improvement of Routing Protocols for Delay Tolerant Networks
Mar 12, 2021



Routing plays a fundamental role in network applications, but it is especially challenging in Delay Tolerant Networks (DTNs). These are a kind of mobile ad hoc networks made of e.g. (possibly, unmanned) vehicles and humans where, despite a lack of continuous connectivity, data must be transmitted while the network conditions change due to the nodes' mobility. In these contexts, routing is NP-hard and is usually solved by heuristic "store and forward" replication-based approaches, where multiple copies of the same message are moved and stored across nodes in the hope that at least one will reach its destination. Still, the existing routing protocols produce relatively low delivery probabilities. Here, we genetically improve two routing protocols widely adopted in DTNs, namely Epidemic and PRoPHET, in the attempt to optimize their delivery probability. First, we dissect them into their fundamental components, i.e., functionalities such as checking if a node can transfer data, or sending messages to all connections. Then, we apply Genetic Improvement (GI) to manipulate these components as terminal nodes of evolving trees. We apply this methodology, in silico, to six test cases of urban networks made of hundreds of nodes, and find that GI produces consistent gains in delivery probability in four cases. We then verify if this improvement entails a worsening of other relevant network metrics, such as latency and buffer time. Finally, we compare the logics of the best evolved protocols with those of the baseline protocols, and we discuss the generalizability of the results across test cases.
LUCIDGames: Online Unscented Inverse Dynamic Games for Adaptive Trajectory Prediction and Planning
Nov 16, 2020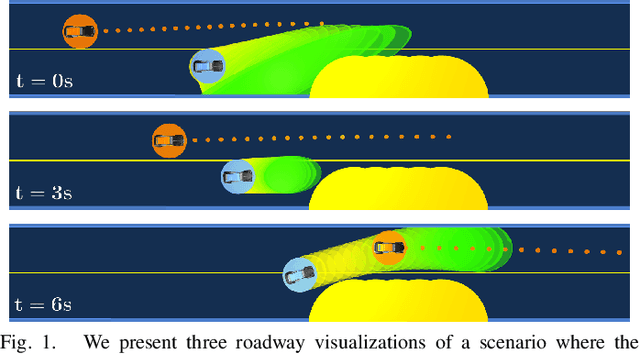
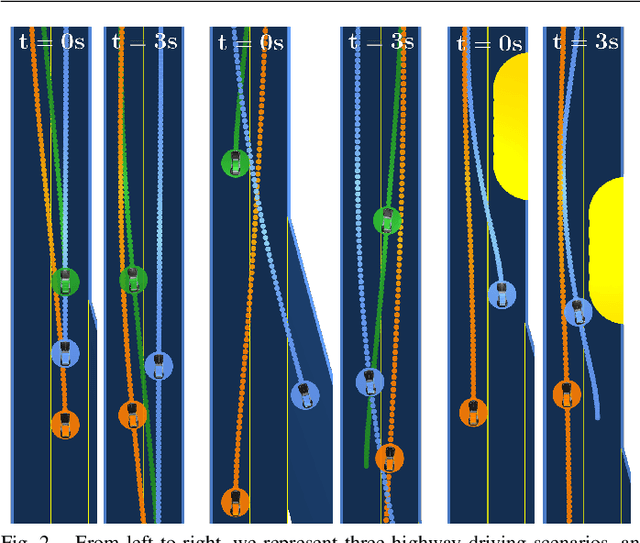
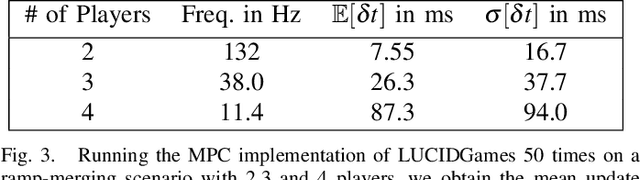
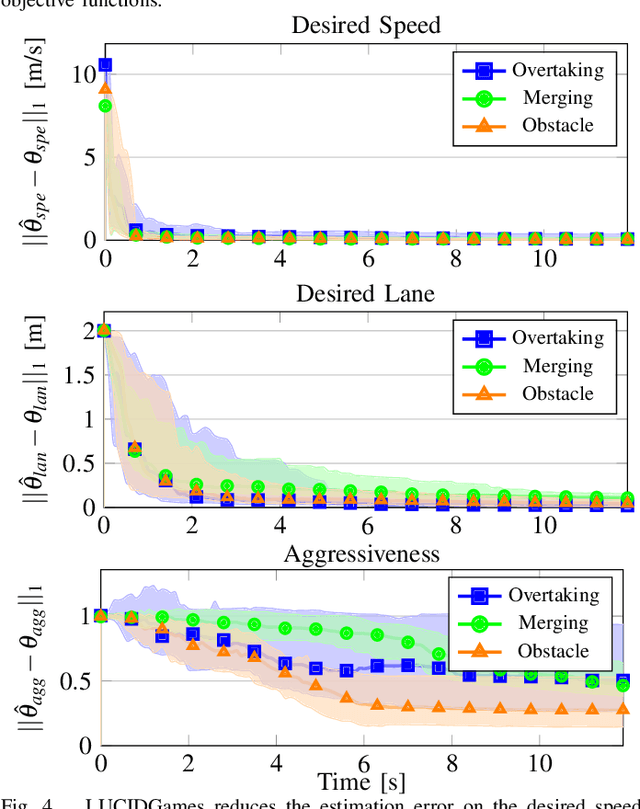
Existing game-theoretic planning methods assume that the robot knows the objective functions of the other agents a priori while, in practical scenarios, this is rarely the case. This paper introduces LUCIDGames, an inverse optimal control algorithm that is able to estimate the other agents' objective functions in real time, and incorporate those estimates online into a receding-horizon game-theoretic planner. LUCIDGames solves the inverse optimal control problem by recasting it in a recursive parameter-estimation framework. LUCIDGames uses an unscented Kalman filter (UKF) to iteratively update a Bayesian estimate of the other agents' cost function parameters, improving that estimate online as more data is gathered from the other agents' observed trajectories. The planner then takes account of the uncertainty in the Bayesian parameter estimates of other agents by planning a trajectory for the robot subject to uncertainty ellipse constraints. The algorithm assumes no explicit communication or coordination between the robot and the other agents in the environment. An MPC implementation of LUCIDGames demonstrates real-time performance on complex autonomous driving scenarios with an update frequency of 40 Hz. Empirical results demonstrate that LUCIDGames improves the robot's performance over existing game-theoretic and traditional MPC planning approaches. Our implementation of LUCIDGames is available at https://github.com/RoboticExplorationLab/LUCIDGames.jl.