 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TicketTalk: Toward human-level performance with end-to-end, transaction-based dialog systems
Dec 27, 2020
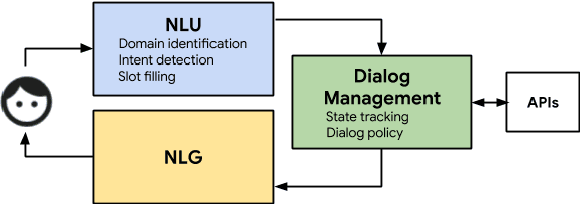
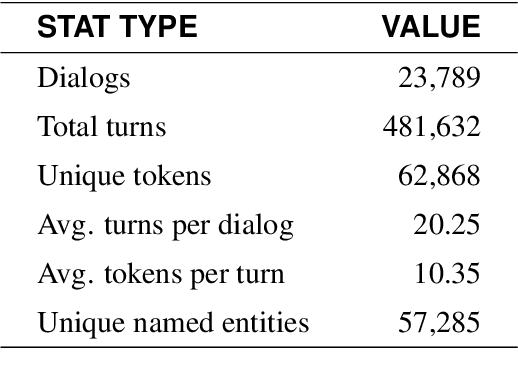

We present a data-driven, end-to-end approach to transaction-based dialog systems that performs at near-human levels in terms of verbal response quality and factual grounding accuracy. We show that two essential components of the system produce these results: a sufficiently large and diverse, in-domain labeled dataset, and a neural network-based, pre-trained model that generates both verbal responses and API call predictions. In terms of data, we introduce TicketTalk, a movie ticketing dialog dataset with 23,789 annotated conversations. The movie ticketing conversations range from completely open-ended and unrestricted to more structured, both in terms of their knowledge base, discourse features, and number of turns. In qualitative human evaluations, model-generated responses trained on just 10,000 TicketTalk dialogs were rated to "make sense" 86.5 percent of the time, almost the same as human responses in the same contexts. Our simple, API-focused annotation schema results in a much easier labeling task making it faster and more cost effective. It is also the key component for being able to predict API calls accurately. We handle factual grounding by incorporating API calls in the training data, allowing our model to learn which actions to take and when. Trained on the same 10,000-dialog set, the model's API call predictions were rated to be correct 93.9 percent of the time in our evaluations, surpassing the ratings for the corresponding human labels. We show how API prediction and response generation scores improve as the dataset size incrementally increases from 5000 to 21,000 dialogs. Our analysis also clearly illustrates the benefits of pre-training. We are publicly releasing the TicketTalk dataset with this paper to facilitate future work on transaction-based dialogs.
Fever Basketball: A Complex, Flexible, and Asynchronized Sports Game Environment for Multi-agent Reinforcement Learning
Dec 06, 2020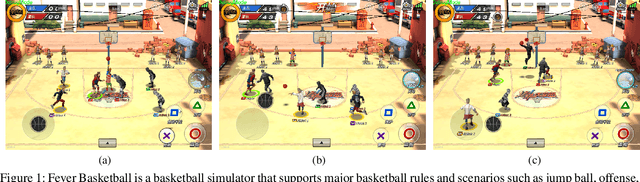
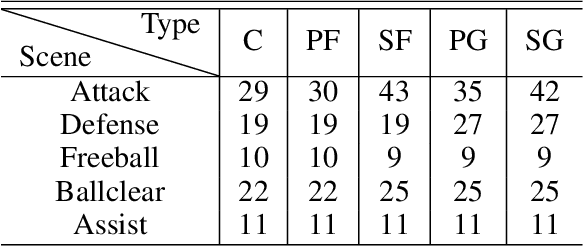
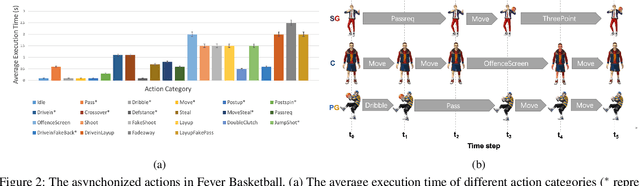
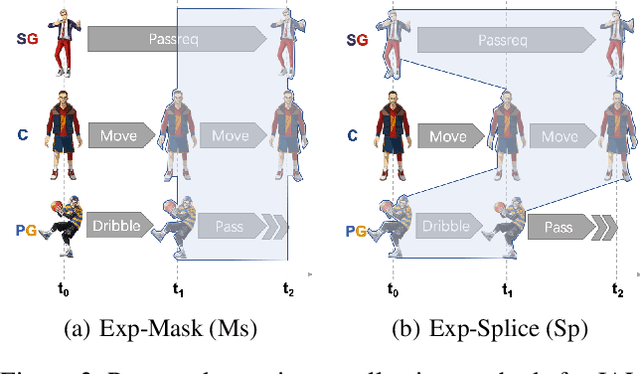
The development of deep reinforcement learning (DRL) has benefited from the emergency of a variety type of game environments where new challenging problems are proposed and new algorithms can be tested safely and quickly, such as Board games, RTS, FPS, and MOBA games. However, many existing environments lack complexity and flexibility and assume the actions are synchronously executed in multi-agent settings, which become less valuable. We introduce the Fever Basketball game, a novel reinforcement learning environment where agents are trained to play basketball game. It is a complex and challenging environment that supports multiple characters, multiple positions, and both the single-agent and multi-agent player control modes. In addition, to better simulate real-world basketball games, the execution time of actions differs among players, which makes Fever Basketball a novel asynchronized environment. We evaluate commonly used multi-agent algorithms of both independent learners and joint-action learners in three game scenarios with varying difficulties, and heuristically propose two baseline methods to diminish the extra non-stationarity brought by asynchronism in Fever Basketball Benchmarks. Besides, we propose an integrated curricula training (ICT) framework to better handle Fever Basketball problems, which includes several game-rule based cascading curricula learners and a coordination curricula switcher focusing on enhancing coordination within the team. The results show that the game remains challenging and can be used as a benchmark environment for studies like long-time horizon, sparse rewards, credit assignment, and non-stationarity, etc. in multi-agent settings.
Influence-Augmented Online Planning for Complex Environments
Oct 21, 2020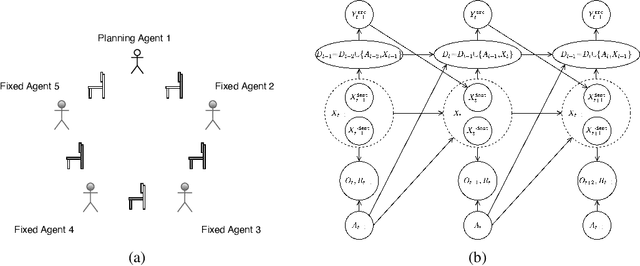
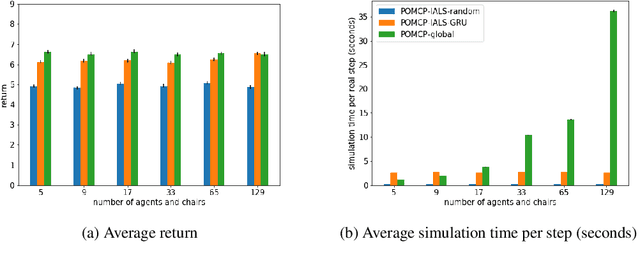

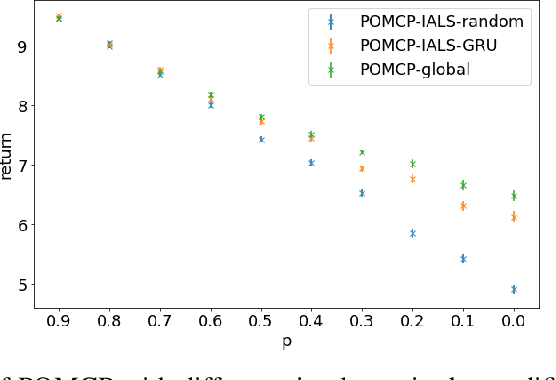
How can we plan efficiently in real time to control an agent in a complex environment that may involve many other agents? While existing sample-based planners have enjoyed empirical success in large POMDPs, their performance heavily relies on a fast simulator. However, real-world scenarios are complex in nature and their simulators are often computationally demanding, which severely limits the performance of online planners. In this work, we propose influence-augmented online planning, a principled method to transform a factored simulator of the entire environment into a local simulator that samples only the state variables that are most relevant to the observation and reward of the planning agent and captures the incoming influence from the rest of the environment using machine learning methods. Our main experimental results show that planning on this less accurate but much faster local simulator with POMCP leads to higher real-time planning performance than planning on the simulator that models the entire environment.
Multi-view Frequency LSTM: An Efficient Frontend for Automatic Speech Recognition
Jun 30, 2020Acoustic models in real-time speech recognition systems typically stack multiple unidirectional LSTM layers to process the acoustic frames over time. Performance improvements over vanilla LSTM architectures have been reported by prepending a stack of frequency-LSTM (FLSTM) layers to the time LSTM. These FLSTM layers can learn a more robust input feature to the time LSTM layers by modeling time-frequency correlations in the acoustic input signals. A drawback of FLSTM based architectures however is that they operate at a predefined, and tuned, window size and stride, referred to as 'view' in this paper. We present a simple and efficient modification by combining the outputs of multiple FLSTM stacks with different views, into a dimensionality reduced feature representation. The proposed multi-view FLSTM architecture allows to model a wider range of time-frequency correlations compared to an FLSTM model with single view. When trained on 50K hours of English far-field speech data with CTC loss followed by sMBR sequence training, we show that the multi-view FLSTM acoustic model provides relative Word Error Rate (WER) improvements of 3-7% for different speaker and acoustic environment scenarios over an optimized single FLSTM model, while retaining a similar computational footprint.
Unsupervised and self-adaptative techniques for cross-domain person re-identification
Mar 26, 2021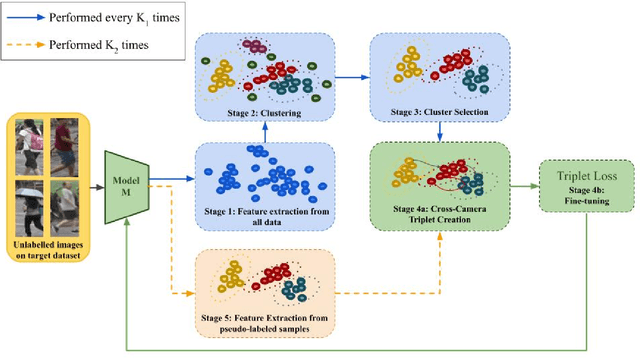
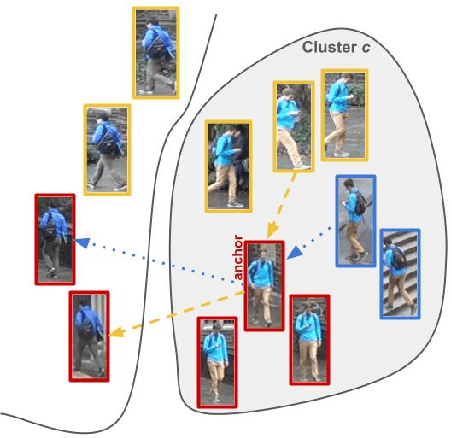
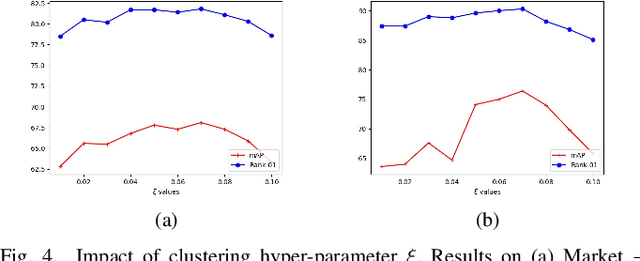
Person Re-Identification (ReID) across non-overlapping cameras is a challenging task and, for this reason, most works in the prior art rely on supervised feature learning from a labeled dataset to match the same person in different views. However, it demands the time-consuming task of labeling the acquired data, prohibiting its fast deployment, specially in forensic scenarios. Unsupervised Domain Adaptation (UDA) emerges as a promising alternative, as it performs feature-learning adaptation from a model trained on a source to a target domain without identity-label annotation. However, most UDA-based algorithms rely upon a complex loss function with several hyper-parameters, which hinders the generalization to different scenarios. Moreover, as UDA depends on the translation between domains, it is important to select the most reliable data from the unseen domain, thus avoiding error propagation caused by noisy examples on the target data -- an often overlooked problem. In this sense, we propose a novel UDA-based ReID method that optimizes a simple loss function with only one hyper-parameter and that takes advantage of triplets of samples created by a new offline strategy based on the diversity of cameras within a cluster. This new strategy adapts the model and also regularizes it, avoiding overfitting on the target domain. We also introduce a new self-ensembling strategy, in which weights from different iterations are aggregated to create a final model combining knowledge from distinct moments of the adaptation. For evaluation, we consider three well-known deep learning architectures and combine them for final decision-making. The proposed method does not use person re-ranking nor any label on the target domain, and outperforms the state of the art, with a much simpler setup, on the Market to Duke, the challenging Market1501 to MSMT17, and Duke to MSMT17 adaptation scenarios.
PuRe: Robust pupil detection for real-time pervasive eye tracking
Dec 24, 2017

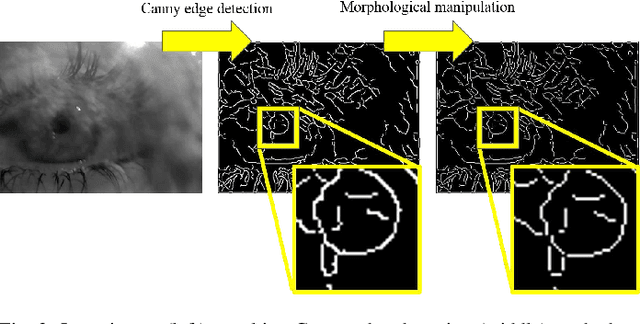
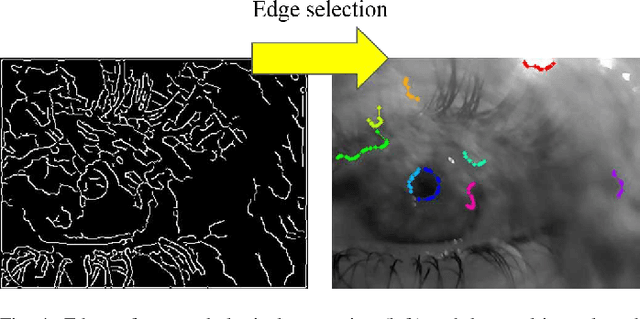
Real-time, accurate, and robust pupil detection is an essential prerequisite to enable pervasive eye-tracking and its applications -- e.g., gaze-based human computer interaction, health monitoring, foveated rendering, and advanced driver assistance. However, automated pupil detection has proved to be an intricate task in real-world scenarios due to a large mixture of challenges such as quickly changing illumination and occlusions. In this paper, we introduce the Pupil Reconstructor PuRe, a method for pupil detection in pervasive scenarios based on a novel edge segment selection and conditional segment combination schemes; the method also includes a confidence measure for the detected pupil. The proposed method was evaluated on over 316,000 images acquired with four distinct head-mounted eye tracking devices. Results show a pupil detection rate improvement of over 10 percentage points w.r.t. state-of-the-art algorithms in the two most challenging data sets (6.46 for all data sets), further pushing the envelope for pupil detection. Moreover, we advance the evaluation protocol of pupil detection algorithms by also considering eye images in which pupils are not present. In this aspect, PuRe improved precision and specificity w.r.t. state-of-the-art algorithms by 25.05 and 10.94 percentage points, respectively, demonstrating the meaningfulness of PuRe's confidence measure. PuRe operates in real-time for modern eye trackers (at 120 fps).
A systematic literature review on state-of-the-art deep learning methods for process prediction
Jan 26, 2021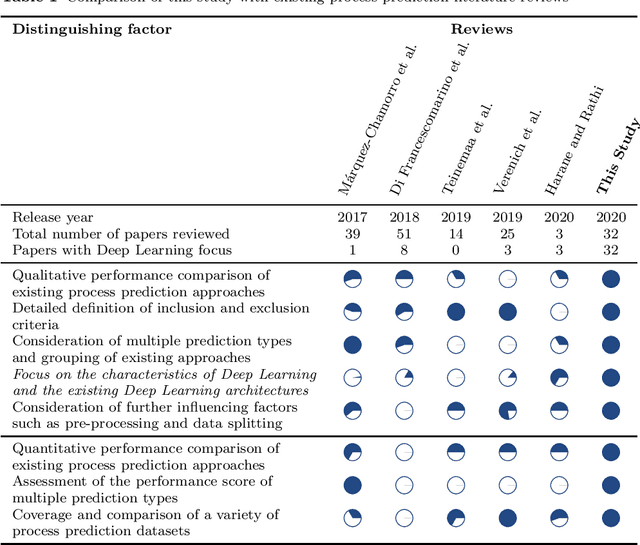
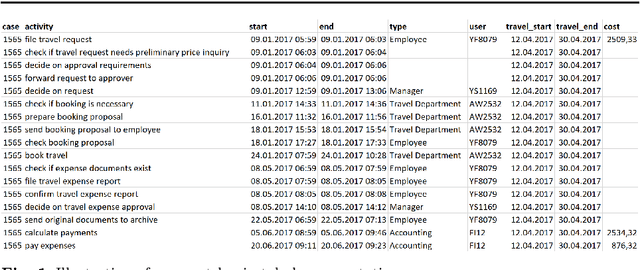
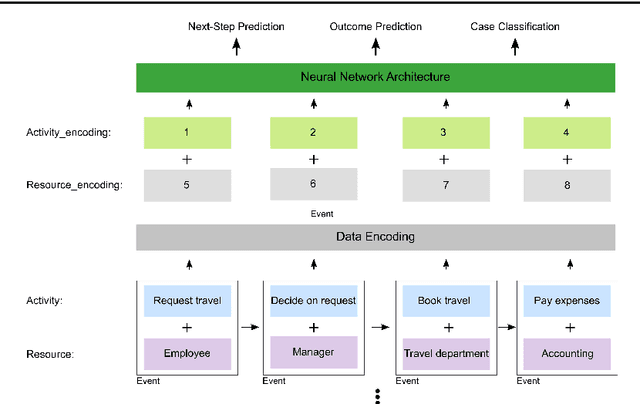
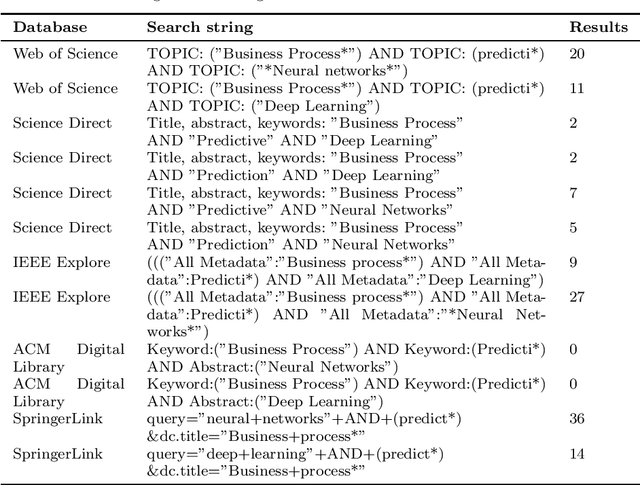
Process mining enables the reconstruction and evaluation of business processes based on digital traces in IT systems. An increasingly important technique in this context is process prediction. Given a sequence of events of an ongoing trace, process prediction allows forecasting upcoming events or performance measurements. In recent years, multiple process prediction approaches have been proposed, applying different data processing schemes and prediction algorithms. This study focuses on deep learning algorithms since they seem to outperform their machine learning alternatives consistently. Whilst having a common learning algorithm, they use different data preprocessing techniques, implement a variety of network topologies and focus on various goals such as outcome prediction, time prediction or control-flow prediction. Additionally, the set of log-data, evaluation metrics and baselines used by the authors diverge, making the results hard to compare. This paper attempts to synthesise the advantages and disadvantages of the procedural decisions in these approaches by conducting a systematic literature review.
Automatic Yara Rule Generation Using Biclustering
Sep 06, 2020
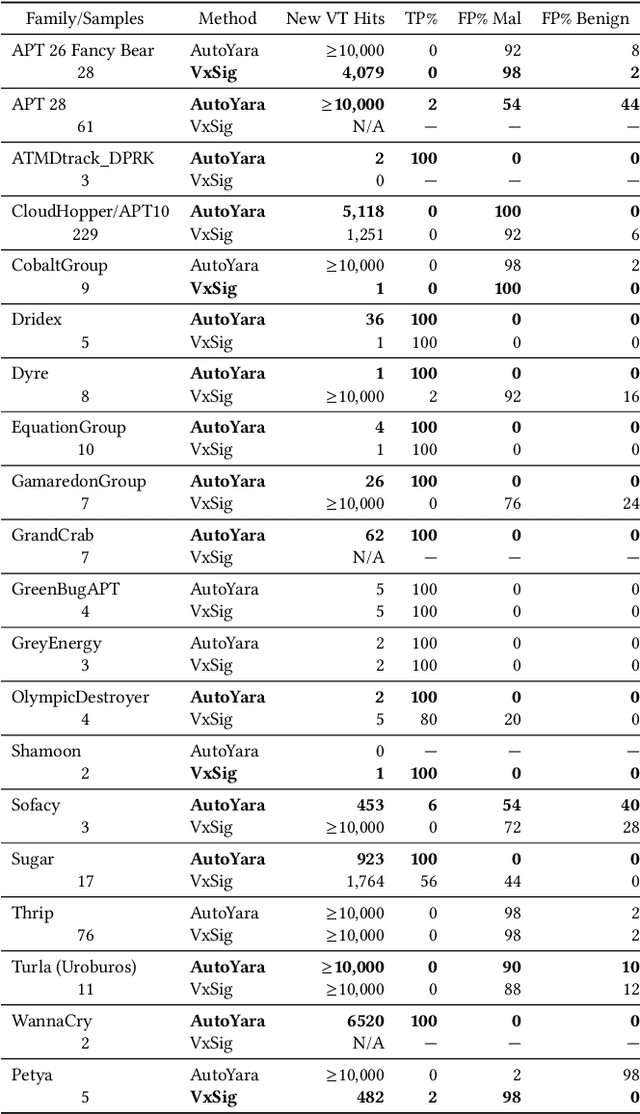
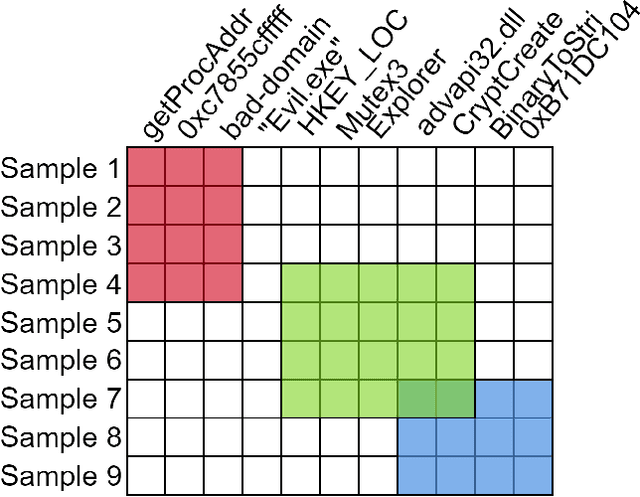
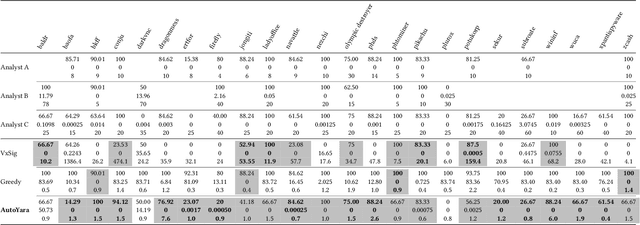
Yara rules are a ubiquitous tool among cybersecurity practitioners and analysts. Developing high-quality Yara rules to detect a malware family of interest can be labor- and time-intensive, even for expert users. Few tools exist and relatively little work has been done on how to automate the generation of Yara rules for specific families. In this paper, we leverage large n-grams ($n \geq 8$) combined with a new biclustering algorithm to construct simple Yara rules more effectively than currently available software. Our method, AutoYara, is fast, allowing for deployment on low-resource equipment for teams that deploy to remote networks. Our results demonstrate that AutoYara can help reduce analyst workload by producing rules with useful true-positive rates while maintaining low false-positive rates, sometimes matching or even outperforming human analysts. In addition, real-world testing by malware analysts indicates AutoYara could reduce analyst time spent constructing Yara rules by 44-86%, allowing them to spend their time on the more advanced malware that current tools can't handle. Code will be made available at https://github.com/NeuromorphicComputationResearchProgram .
Is preprocessing of text really worth your time for online comment classification?
Aug 29, 2018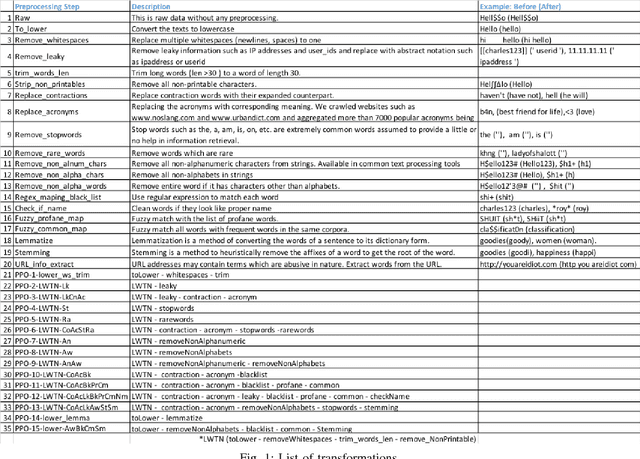
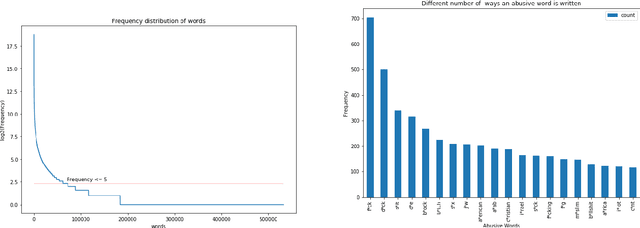
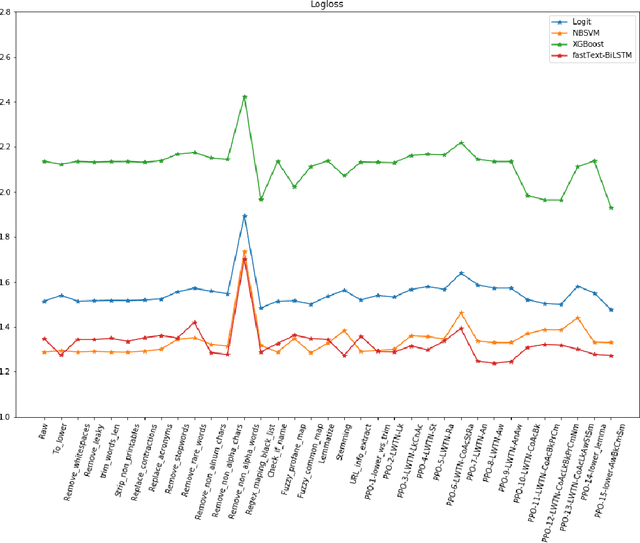
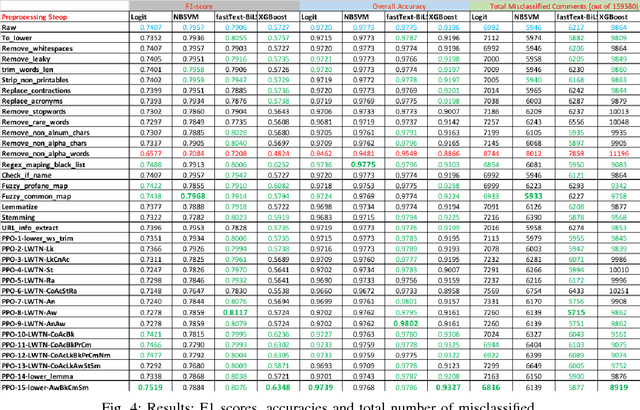
A large proportion of online comments present on public domains are constructive, however a significant proportion are toxic in nature. The comments contain lot of typos which increases the number of features manifold, making the ML model difficult to train. Considering the fact that the data scientists spend approximately 80% of their time in collecting, cleaning and organizing their data [1], we explored how much effort should we invest in the preprocessing (transformation) of raw comments before feeding it to the state-of-the-art classification models. With the help of four models on Jigsaw toxic comment classification data, we demonstrated that the training of model without any transformation produce relatively decent model. Applying even basic transformations, in some cases, lead to worse performance and should be applied with caution.
Data-driven learning of non-autonomous systems
Jun 02, 2020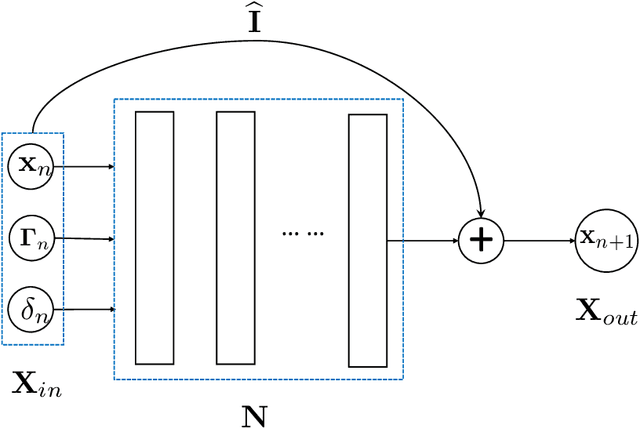
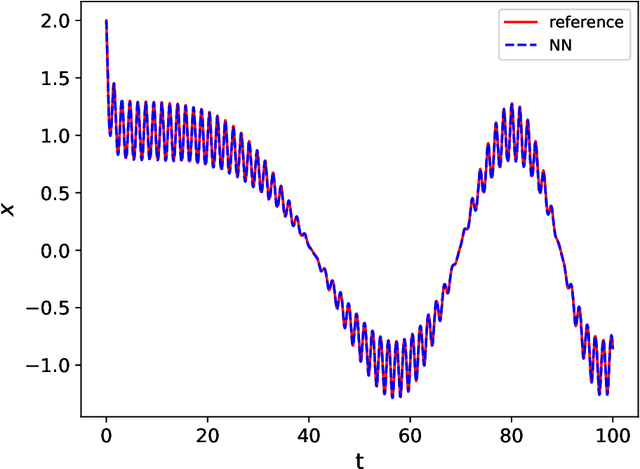
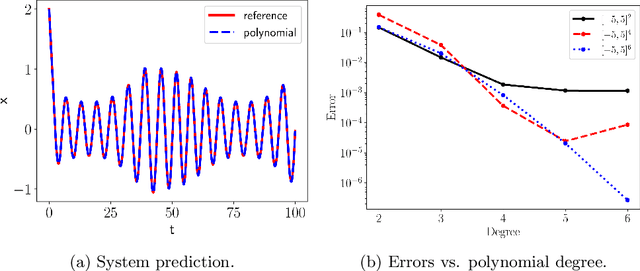
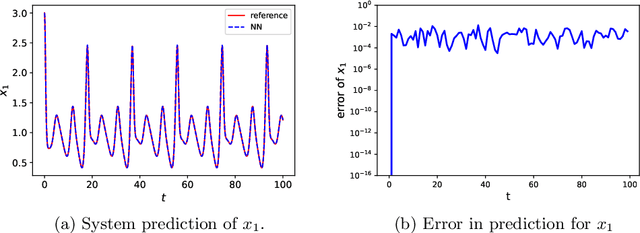
We present a numerical framework for recovering unknown non-autonomous dynamical systems with time-dependent inputs. To circumvent the difficulty presented by the non-autonomous nature of the system, our method transforms the solution state into piecewise integration of the system over a discrete set of time instances. The time-dependent inputs are then locally parameterized by using a proper model, for example, polynomial regression, in the pieces determined by the time instances. This transforms the original system into a piecewise parametric system that is locally time invariant. We then design a deep neural network structure to learn the local models. Once the network model is constructed, it can be iteratively used over time to conduct global system prediction. We provide theoretical analysis of our algorithm and present a number of numerical examples to demonstrate the effectiveness of the method.