 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Tighter Bounds on the Log Marginal Likelihood of Gaussian Process Regression Using Conjugate Gradients
Feb 16, 2021
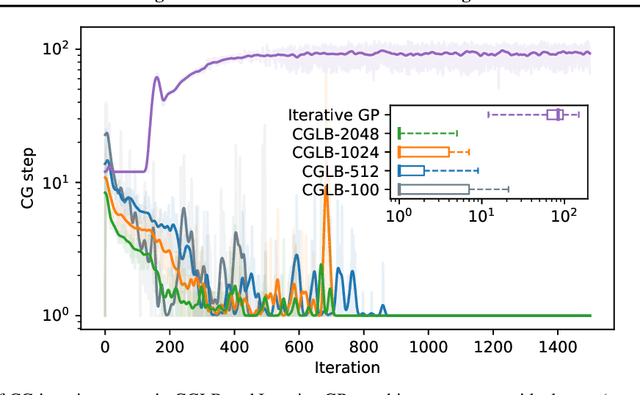
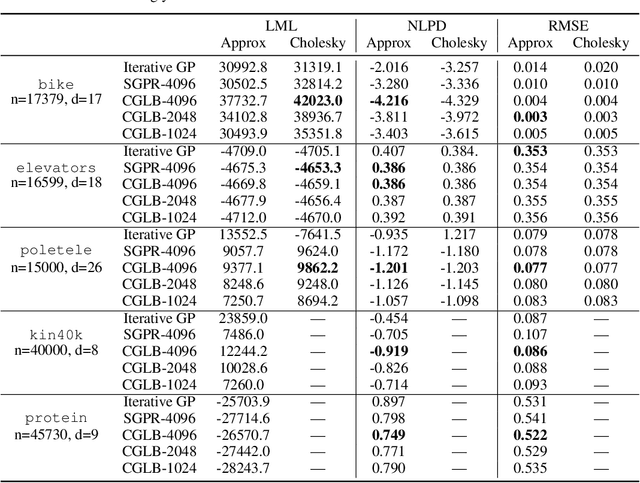
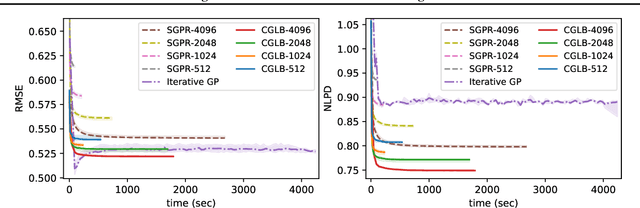
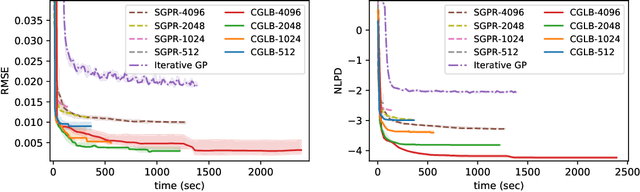
We propose a lower bound on the log marginal likelihood of Gaussian process regression models that can be computed without matrix factorisation of the full kernel matrix. We show that approximate maximum likelihood learning of model parameters by maximising our lower bound retains many of the sparse variational approach benefits while reducing the bias introduced into parameter learning. The basis of our bound is a more careful analysis of the log-determinant term appearing in the log marginal likelihood, as well as using the method of conjugate gradients to derive tight lower bounds on the term involving a quadratic form. Our approach is a step forward in unifying methods relying on lower bound maximisation (e.g. variational methods) and iterative approaches based on conjugate gradients for training Gaussian processes. In experiments, we show improved predictive performance with our model for a comparable amount of training time compared to other conjugate gradient based approaches.
Power Systems Transient Stability Indices: Hierarchical Clustering Based Detection of Coherent Groups Of Generators
Feb 26, 2021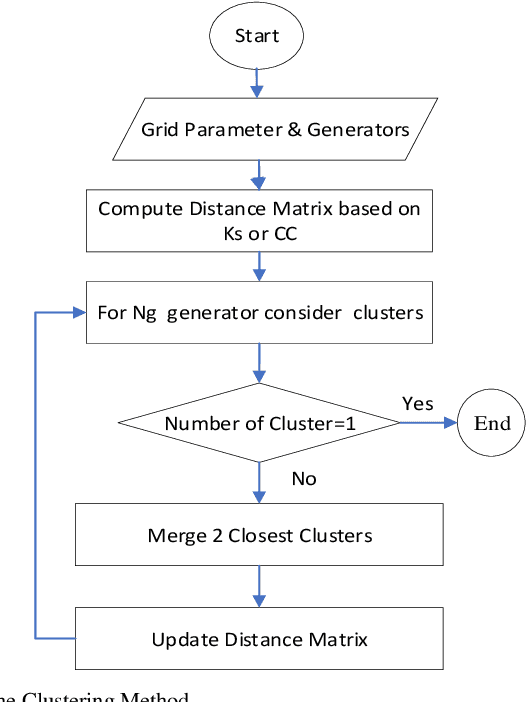

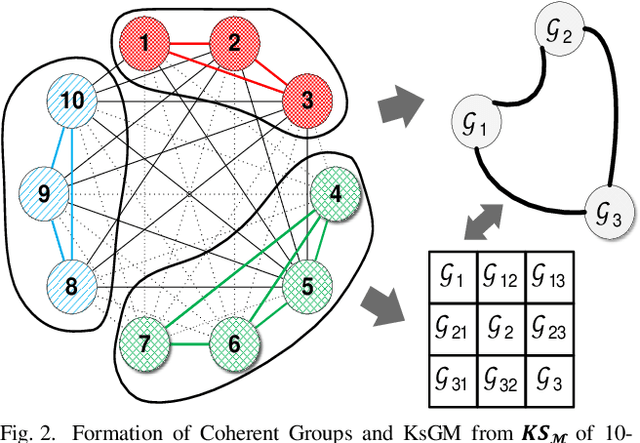
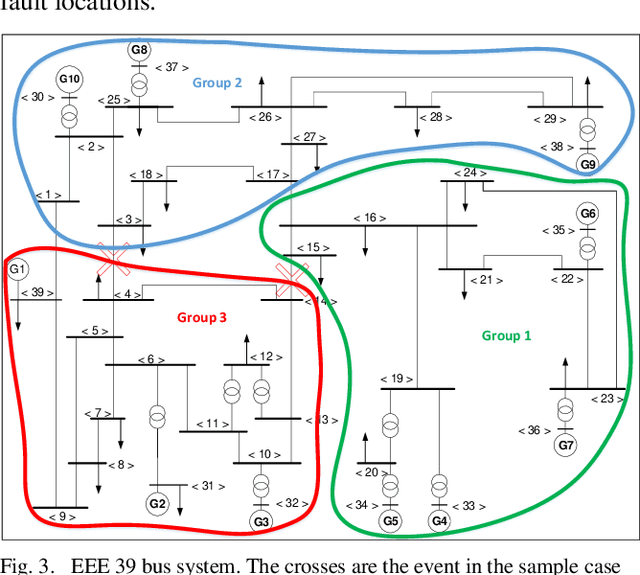
Coherent groups of generators, i.e., machines with perfectly correlated rotor angles, play an important role in power system stability analysis. This paper introduces a real-time methodology based on hierarchical clustering techniques for discovering the degree of coherency among generators using the synchronization coefficient and the correlation coefficient of the generators' rotor angle as the coherency index. Furthermore, the Power Transient Stability Indices (PTSI) were employed to examine the versatile response of the power system. The method uses power systems transients Stability indices, i.e., power Connectivity Factor (CF) index which presents coherently strong generators within the groups, the power Separation Factor (SF) index which unveils to the extent that the generators in different groups tend to swing against the other groups in the event of a disturbance, and the overall system separation index which demonstrates the overall system separation status (CF/SF). The approach is assessed on an IEEE-39 test system with a fully dynamic model. The simulation results presented in this paper demonstrate the efficiency of the proposed approach.
NCH Sleep DataBank: A Large Collection of Real-world Pediatric Sleep Studies
Feb 26, 2021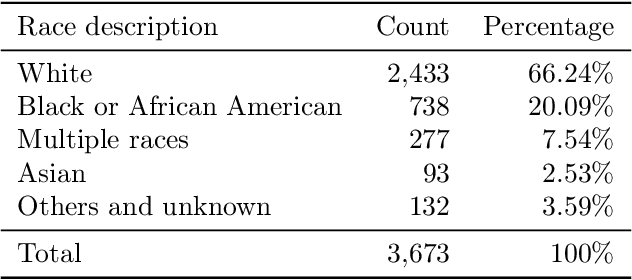
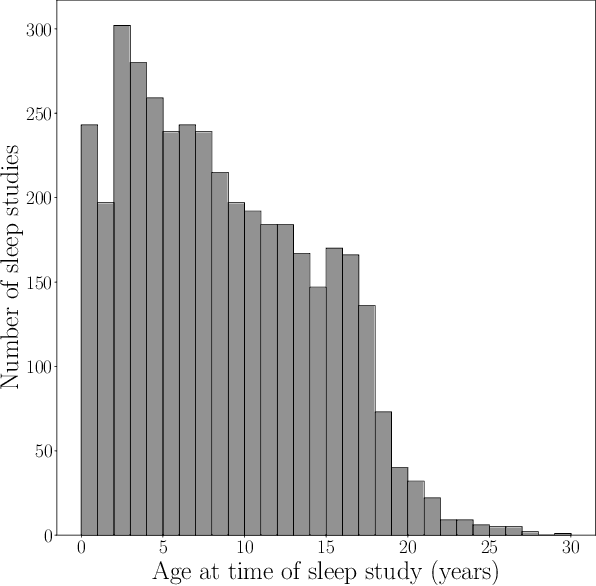
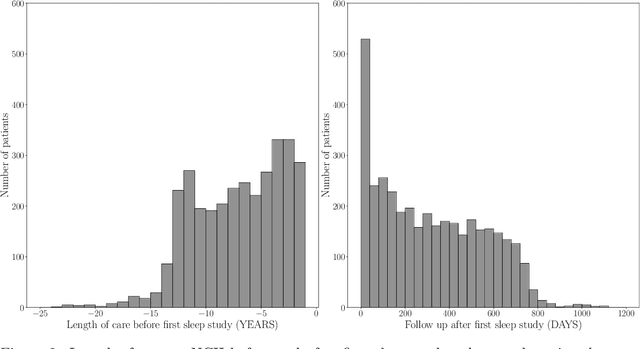
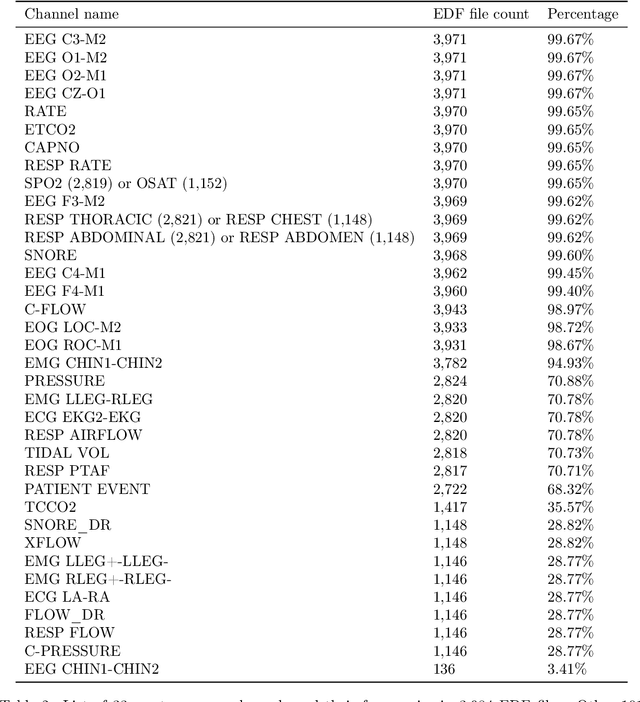
Despite being crucial to health and quality of life, sleep -- especially pediatric sleep -- is not yet well understood. This is exacerbated by lack of access to sufficient pediatric sleep data with clinical annotation. In order to accelerate research on pediatric sleep and its connection to health, we create the Nationwide Children's Hospital (NCH) Sleep DataBank and publish it at the National Sleep Research Resource (NSRR), which is a large sleep data common with physiological data, clinical data, and tools for analyses. The NCH Sleep DataBank consists of 3,984 polysomnography studies and over 5.6 million clinical observations on 3,673 unique patients between 2017 and 2019 at NCH. The novelties of this dataset include: 1) large-scale sleep dataset suitable for discovering new insights via data mining, 2) explicit focus on pediatric patients, 3) gathered in a real-world clinical setting, and 4) the accompanying rich set of clinical data. The NCH Sleep DataBank is a valuable resource for advancing automatic sleep scoring and real-time sleep disorder prediction, among many other potential scientific discoveries.
Pruning neural networks: is it time to nip it in the bud?
Oct 10, 2018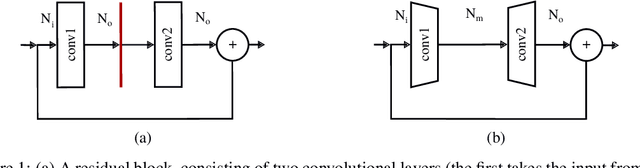
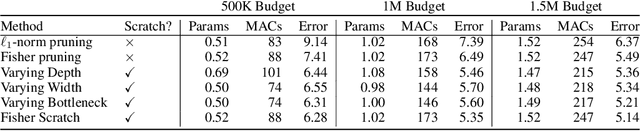
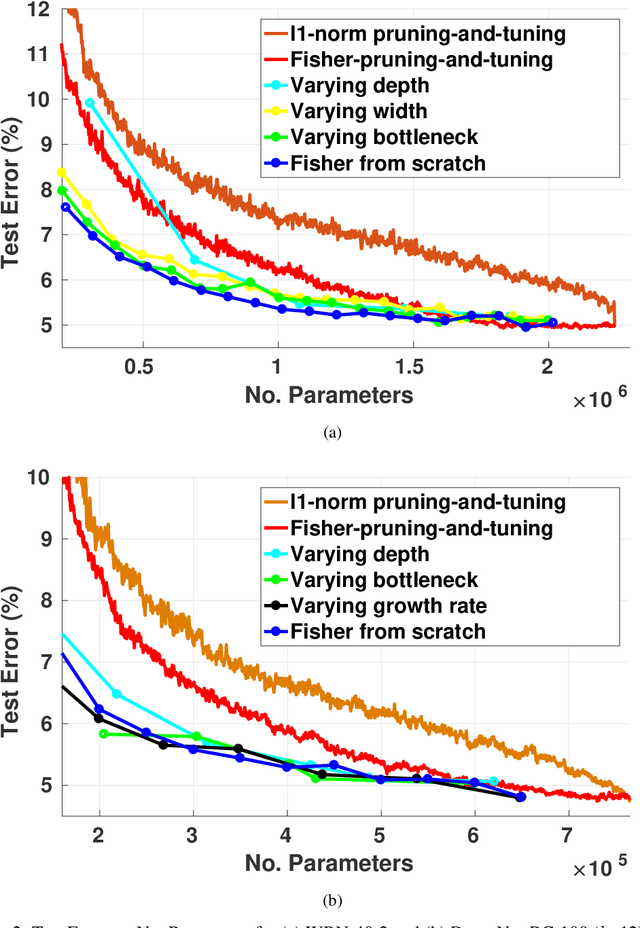
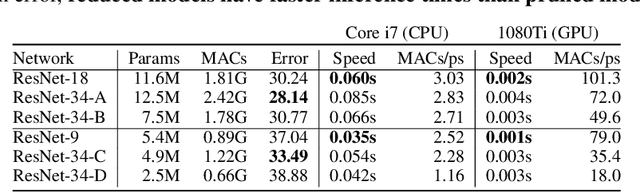
Pruning is a popular technique for compressing a neural network: a large pre-trained network is fine-tuned while connections are successively removed. However, the value of pruning has largely evaded scrutiny. In this extended abstract, we examine residual networks obtained through Fisher-pruning and make two interesting observations. First, when time-constrained, it is better to train a simple, smaller network from scratch than prune a large network. Second, it is the architectures obtained through the pruning process --- not the learnt weights ---that prove valuable. Such architectures are powerful when trained from scratch. Furthermore, these architectures are easy to approximate without any further pruning: we can prune once and obtain a family of new, scalable network architectures for different memory requirements.
Improving Zero-Shot Entity Retrieval through Effective Dense Representations
Mar 06, 2021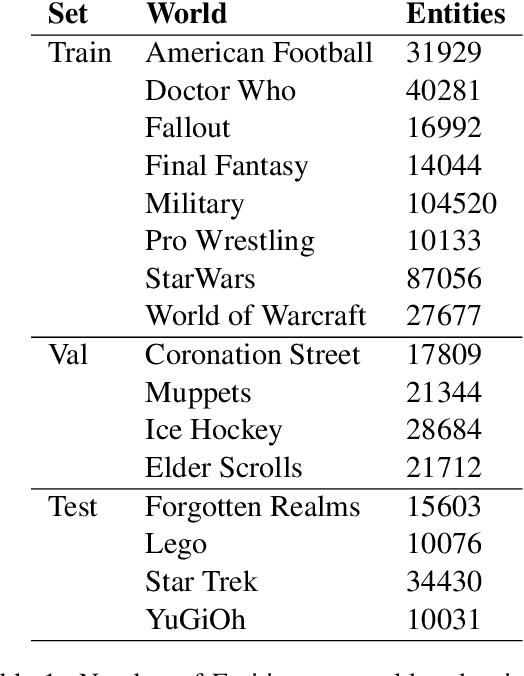
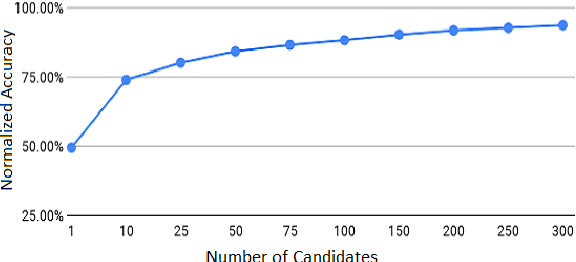
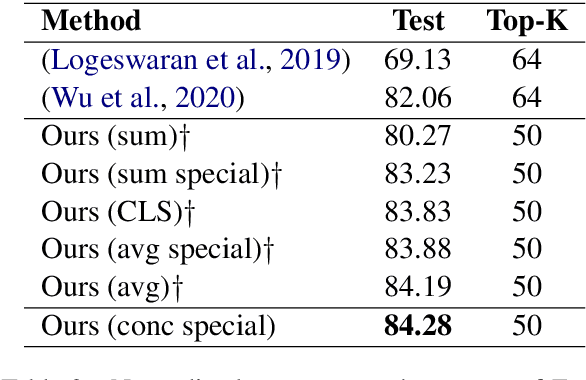
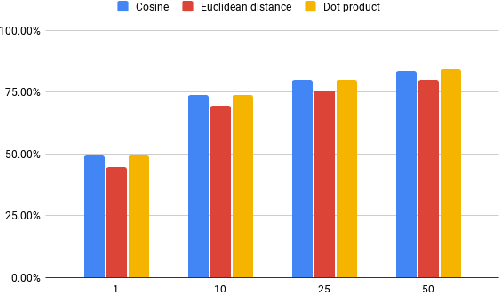
Entity Linking (EL) seeks to align entity mentions in text to entries in a knowledge-base and is usually comprised of two phases: candidate generation and candidate ranking. While most methods focus on the latter, it is the candidate generation phase that sets an upper bound to both time and accuracy performance of the overall EL system. This work's contribution is a significant improvement in candidate generation which thus raises the performance threshold for EL, by generating candidates that include the gold entity in the least candidate set (top-K). We propose a simple approach that efficiently embeds mention-entity pairs in dense space through a BERT-based bi-encoder. Specifically, we extend (Wu et al., 2020) by introducing a new pooling function and incorporating entity type side-information. We achieve a new state-of-the-art 84.28% accuracy on top-50 candidates on the Zeshel dataset, compared to the previous 82.06% on the top-64 of (Wu et al., 2020). We report the results from extensive experimentation using our proposed model on both seen and unseen entity datasets. Our results suggest that our method could be a useful complement to existing EL approaches.
Deep Learning for Real-time Gravitational Wave Detection and Parameter Estimation with LIGO Data
Dec 11, 2017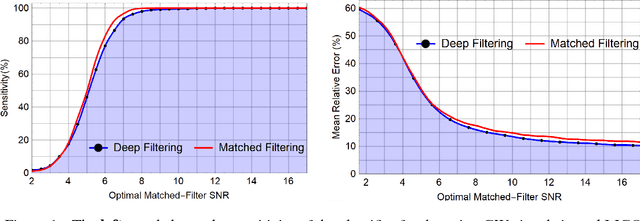
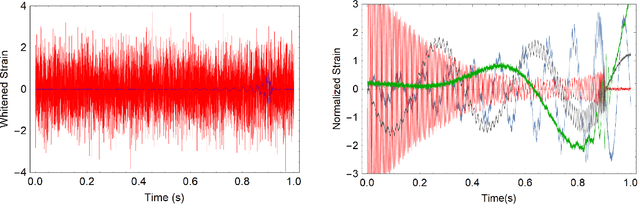
The recent Nobel-prize-winning detections of gravitational waves from merging black holes and the subsequent detection of the collision of two neutron stars in coincidence with electromagnetic observations have inaugurated a new era of multimessenger astrophysics. To enhance the scope of this emergent science, we proposed the use of deep convolutional neural networks for the detection and characterization of gravitational wave signals in real-time. This method, Deep Filtering, was initially demonstrated using simulated LIGO noise. In this article, we present the extension of Deep Filtering using real data from the first observing run of LIGO, for both detection and parameter estimation of gravitational waves from binary black hole mergers with continuous data streams from multiple LIGO detectors. We show for the first time that machine learning can detect and estimate the true parameters of a real GW event observed by LIGO. Our comparisons show that Deep Filtering is far more computationally efficient than matched-filtering, while retaining similar sensitivity and lower errors, allowing real-time processing of weak time-series signals in non-stationary non-Gaussian noise, with minimal resources, and also enables the detection of new classes of gravitational wave sources that may go unnoticed with existing detection algorithms. This approach is uniquely suited to enable coincident detection campaigns of gravitational waves and their multimessenger counterparts in real-time.
Real-Time Quality Assessment of Pediatric MRI via Semi-Supervised Deep Nonlocal Residual Neural Networks
Apr 07, 2019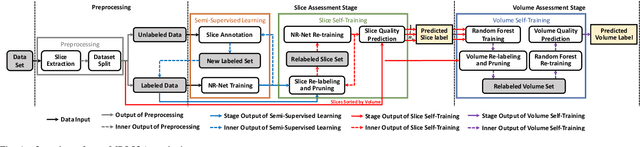
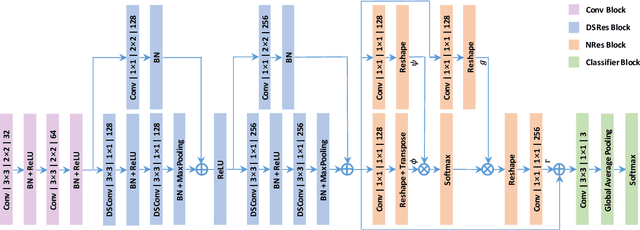
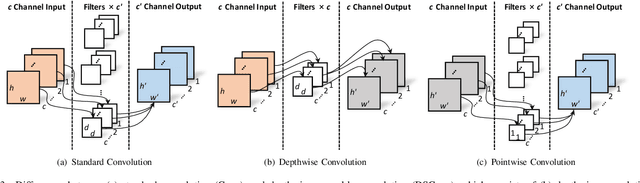
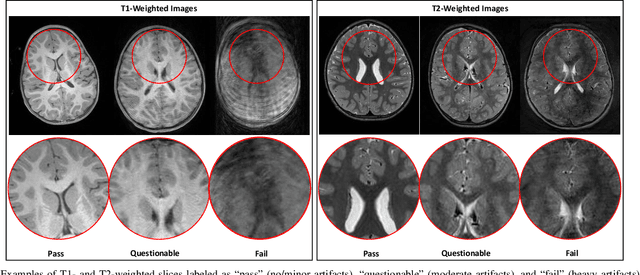
In this paper, we introduce an image quality assessment (IQA) method for pediatric T1- and T2-weighted MR images. IQA is first performed slice-wise using a nonlocal residual neural network (NR-Net) and then volume-wise by agglomerating the slice QA results using random forest. Our method requires only a small amount of quality-annotated images for training and is designed to be robust to annotation noise that might occur due to rater errors and the inevitable mix of good and bad slices in an image volume. Using a small set of quality-assessed images, we pre-train NR-Net to annotate each image slice with an initial quality rating (i.e., pass, questionable, fail), which we then refine by semi-supervised learning and iterative self-training. Experimental results demonstrate that our method, trained using only samples of modest size, exhibit great generalizability, capable of real-time (milliseconds per volume) large-scale IQA with near-perfect accuracy.
Interpretable Visualization and Higher-Order Dimension Reduction for ECoG Data
Dec 12, 2020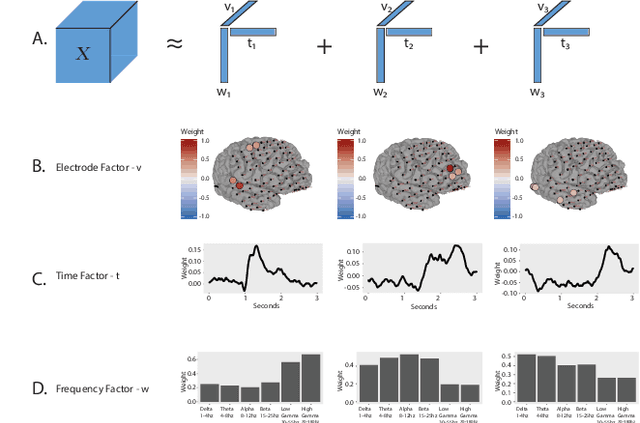
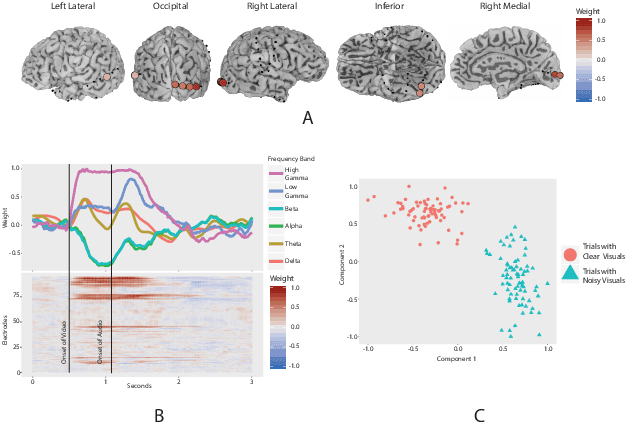
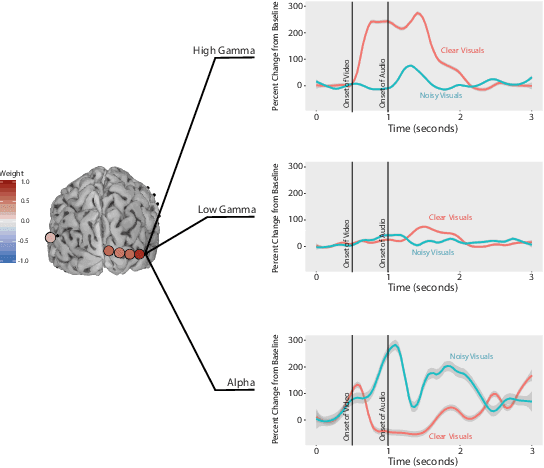
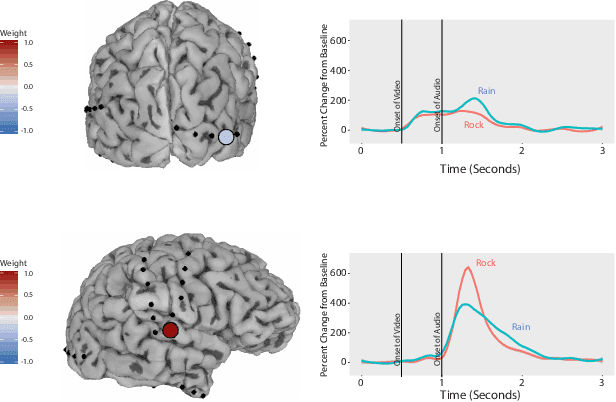
ElectroCOrticoGraphy (ECoG) technology measures electrical activity in the human brain via electrodes placed directly on the cortical surface during neurosurgery. Through its capability to record activity at a fast temporal resolution, ECoG experiments have allowed scientists to better understand how the human brain processes speech. By its nature, ECoG data is difficult for neuroscientists to directly interpret for two major reasons. Firstly, ECoG data tends to be large in size, as each individual experiment yields data up to several gigabytes. Secondly, ECoG data has a complex, higher-order nature. After signal processing, this type of data may be organized as a 4-way tensor with dimensions representing trials, electrodes, frequency, and time. In this paper, we develop an interpretable dimension reduction approach called Regularized Higher Order Principal Components Analysis, as well as an extension to Regularized Higher Order Partial Least Squares, that allows neuroscientists to explore and visualize ECoG data. Our approach employs a sparse and functional Candecomp-Parafac (CP) decomposition that incorporates sparsity to select relevant electrodes and frequency bands, as well as smoothness over time and frequency, yielding directly interpretable factors. We demonstrate the performance and interpretability of our method with an ECoG case study on audio and visual processing of human speech.
Siamese Labels Auxiliary Network(SiLaNet)
Mar 06, 2021
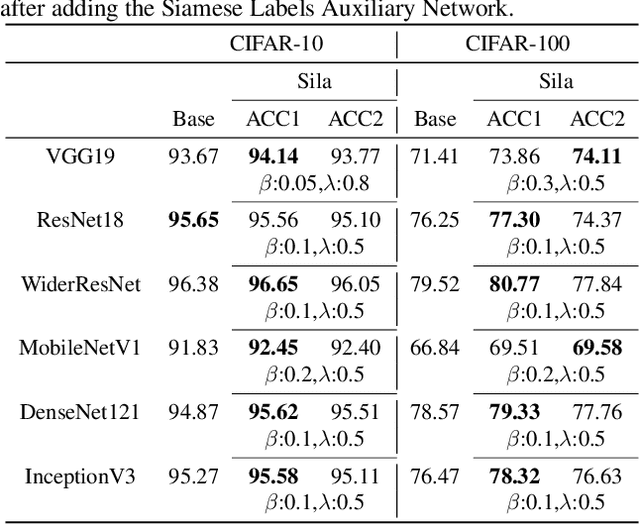
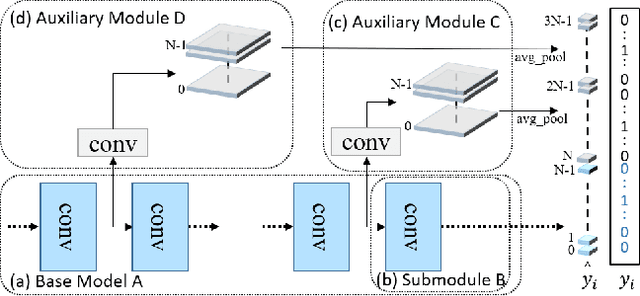
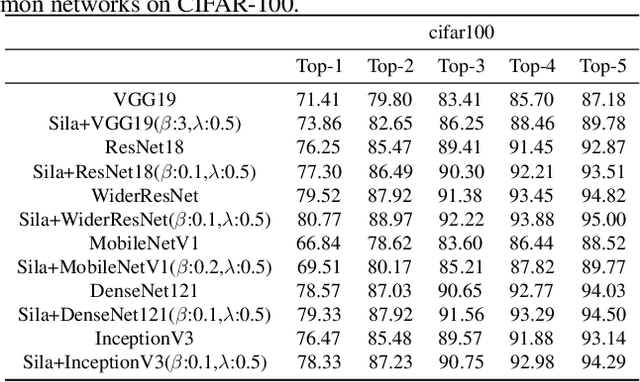
Auxiliary information attracts more and more attention in the area of machine learning. Attempts so far to include such auxiliary information in state-of-the-art learning process have often been based on simply appending these auxiliary features to the data level or feature level. In this paper, we intend to propose a novel training method with new options and architectures. Siamese labels, which were used in the training phase as auxiliary modules. While in the testing phase, the auxiliary module should be removed. Siamese label module makes it easier to train and improves the performance in testing process. In general, the main contributions can be summarized as, 1) Siamese Labels are firstly proposed as auxiliary information to improve the learning efficiency; 2) We establish a new architecture, Siamese Labels Auxiliary Network (SilaNet), which is to assist the training of the model; 3) Siamese Labels Auxiliary Network is applied to compress the model parameters by 50% and ensure the high accuracy at the same time. For the purpose of comparison, we tested the network on CIFAR-10 and CIFAR100 using some common models. The proposed SilaNet performs excellent efficiency both on the accuracy and robustness.
Uncertainty-Wizard: Fast and User-Friendly Neural Network Uncertainty Quantification
Dec 29, 2020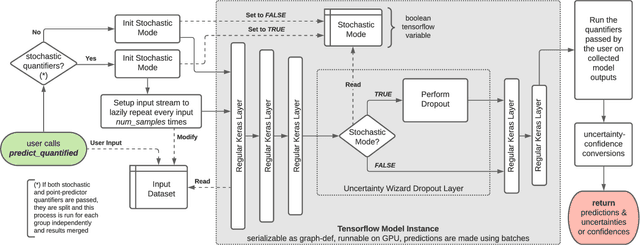
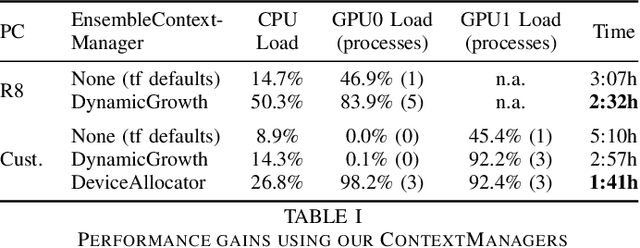
Uncertainty and confidence have been shown to be useful metrics in a wide variety of techniques proposed for deep learning testing, including test data selection and system supervision. We present uncertainty-wizard, a tool that allows to quantify such uncertainty and confidence in artificial neural networks. It is built on top of the industry-leading tensorflow.keras deep learning API and it provides a near-transparent and easy to understand interface. At the same time, it includes major performance optimizations that have been evaluated in several software testing use-cases on a common benchmark.